-
-
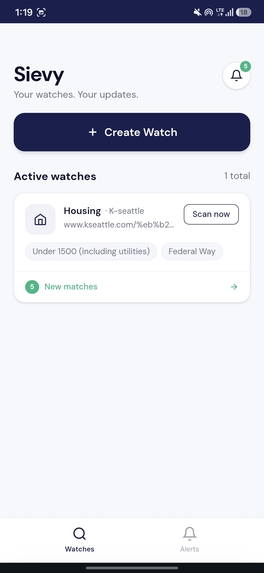
Watch List with new alerts
-
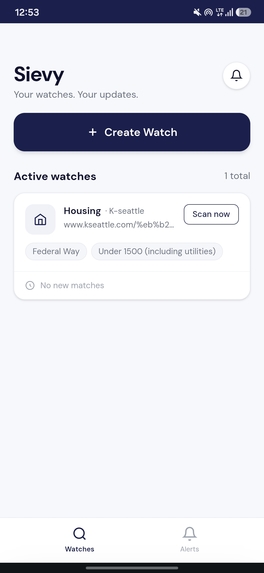
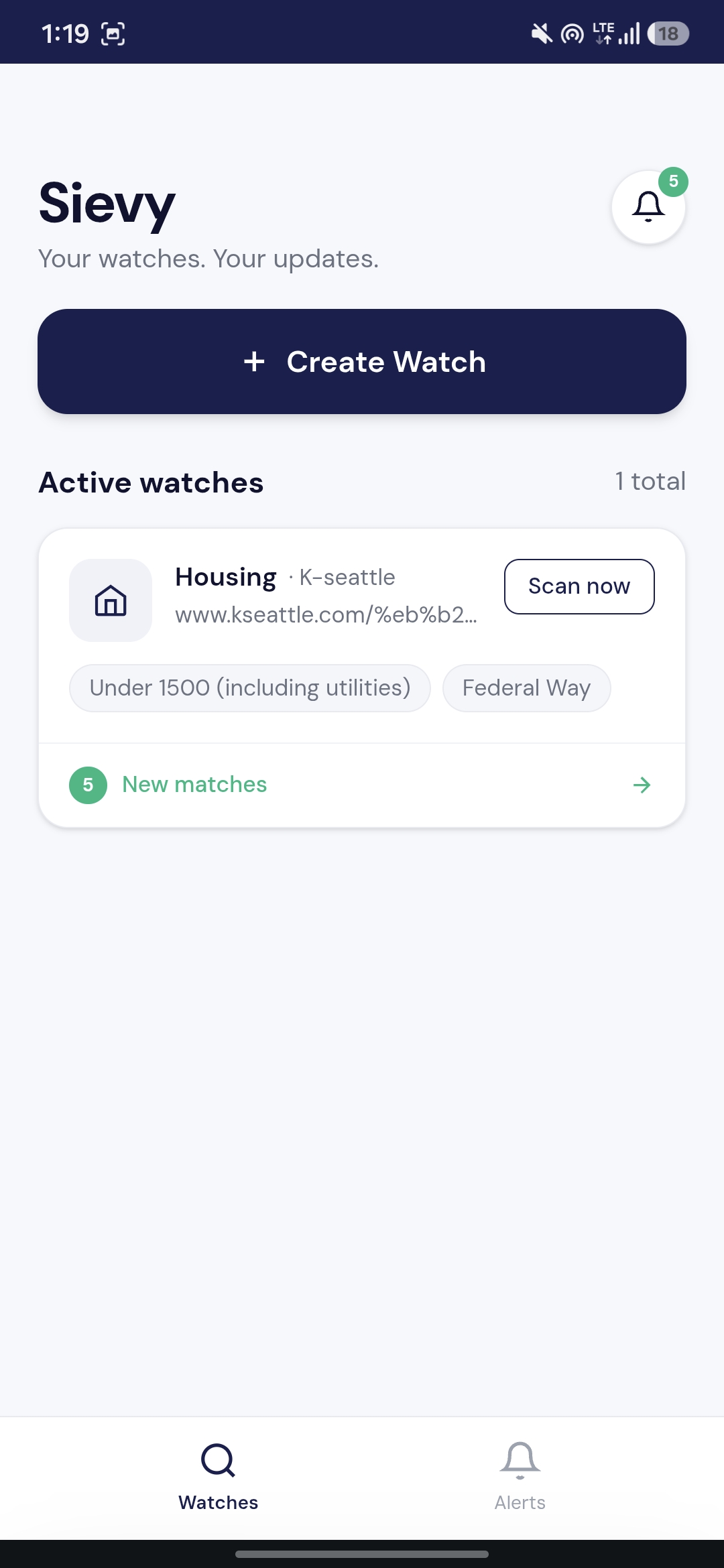
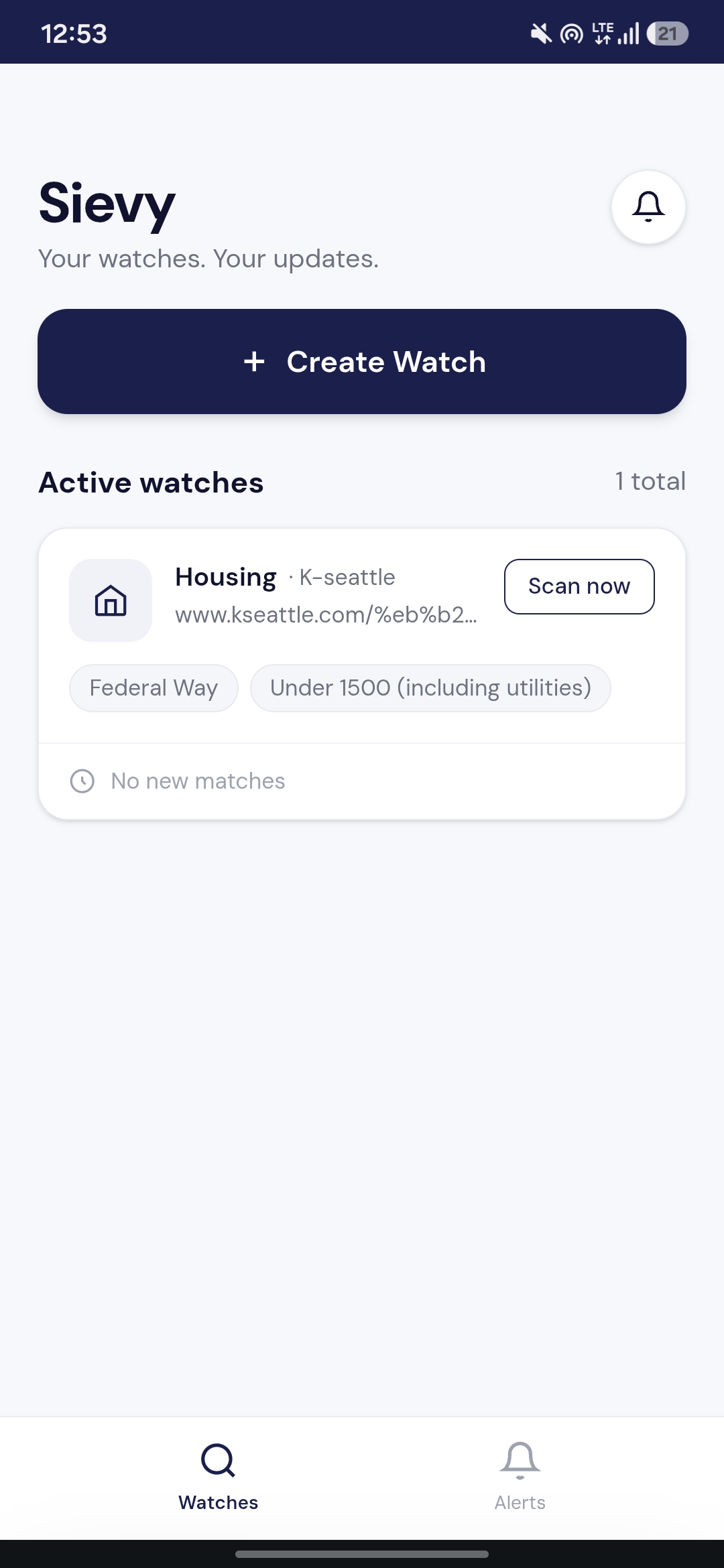
Watch List
-
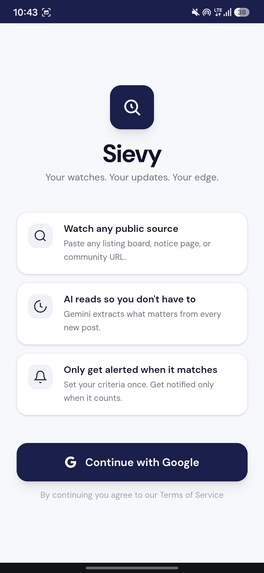
Onboarding
-
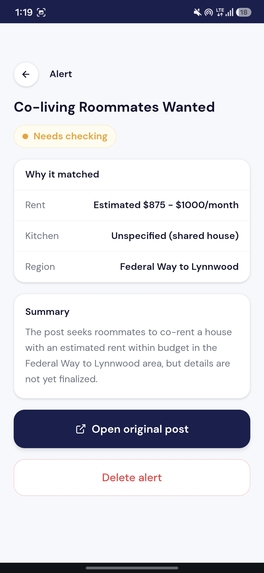
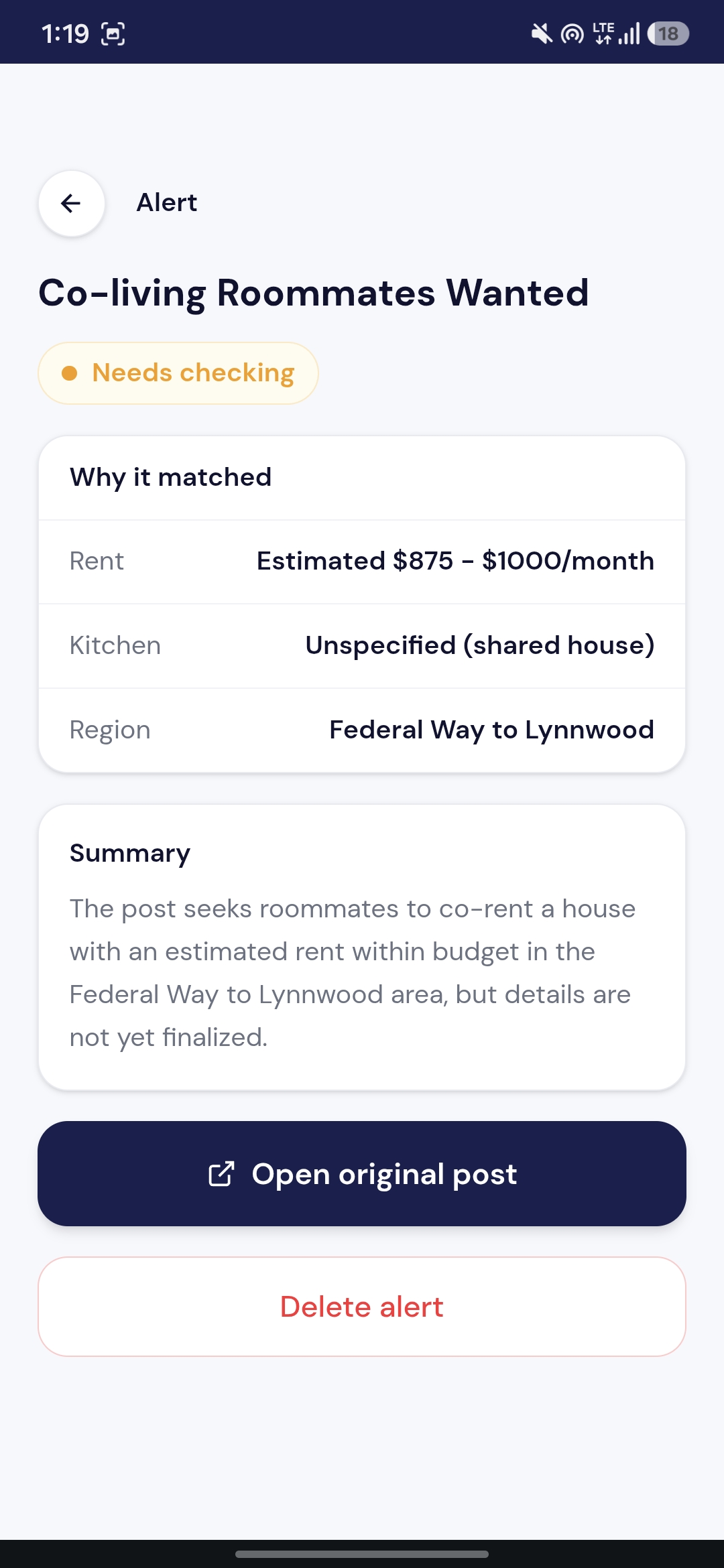
Alerts Details
-
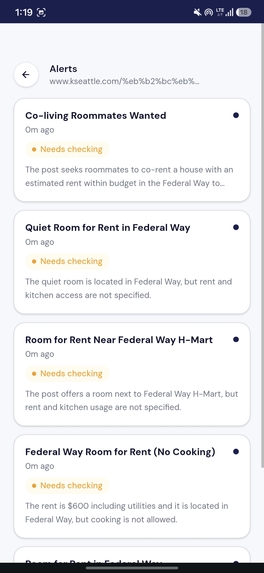
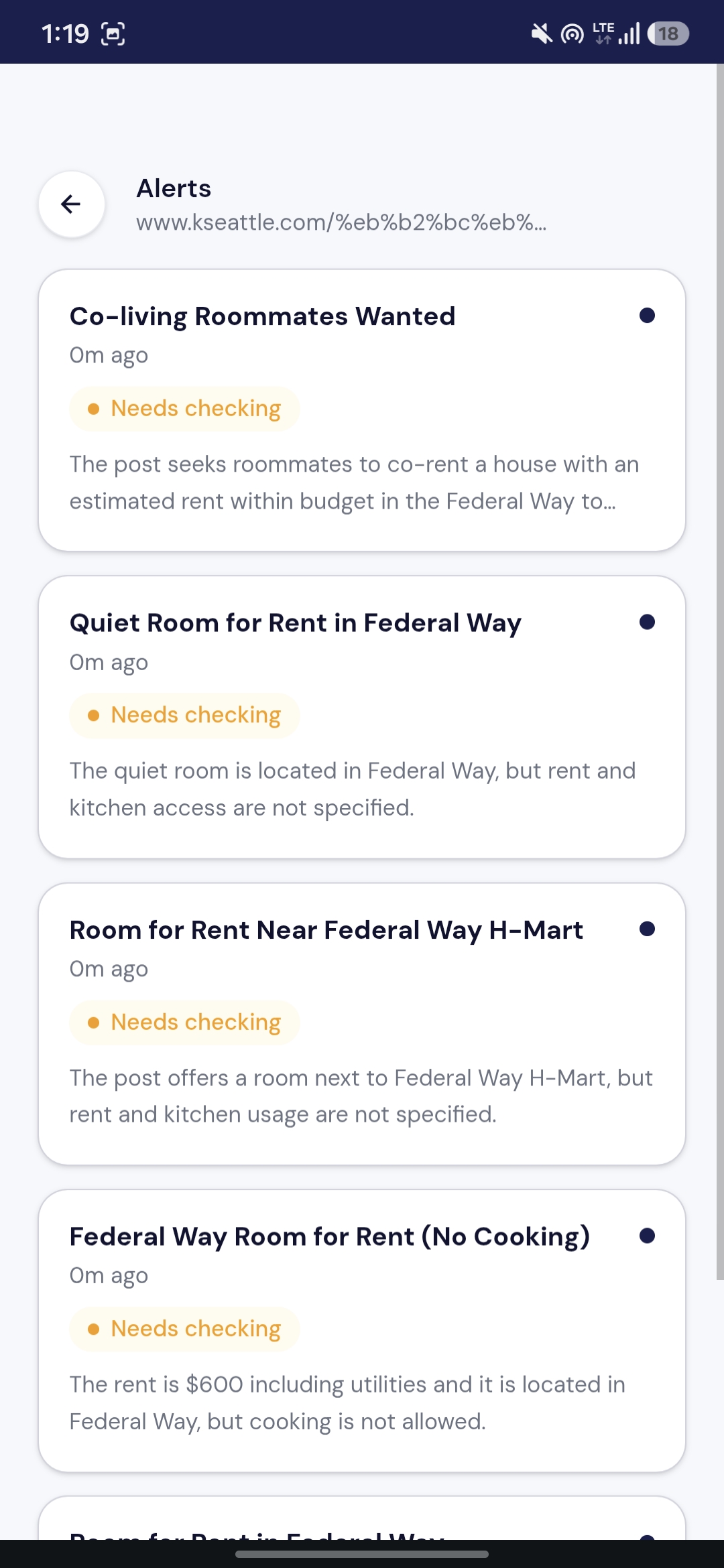
Alert List
Inspiration
As a university student, I check the same pages every single day. Academic notices. Scholarship deadlines. Local events. Internship listings. Community boards. Most of these sites have no notification system. You either check manually or you miss it. The problem is not that people can't search. It's that they can't keep checking every site, every day.
What it does
Sievy is a source-bound AI alert filter. You give it a URL and describe what you're looking for in plain language. It does the rest — automatically, every hour.
- Create a Watch — paste any public listing page URL, pick a category, and describe your criteria in natural language
- Sievy detects the feed — Gemini identifies how individual post URLs are structured on that page and saves the current posts as a baseline
- Automatic hourly scanning — every hour, Sievy fetches new posts since the last baseline, scrapes each one with Firecrawl, and indexes the content in Elasticsearch using ELSER semantic embeddings
- A Gemini agent judges each post — using Elastic Agent Builder MCP, it runs a semantic search against the indexed posts, then judges each result against your criteria
- You get an alert — only when something actually matches, with extracted fields, a one-line summary, and a direct link to the original post
You set it once. Sievy watches while you sleep.
How we built it
Backend: Python 3.13 + FastAPI + Google ADK
The scan pipeline runs in two phases. First, asyncio.gather parallelizes Firecrawl scraping across all new posts and indexes each one into Elasticsearch Cloud Serverless with semantic_text field type, which triggers ELSER sparse vector embedding automatically on index — no separate embedding pipeline, no external model call. Then a Gemini Flash agent uses the Elastic Agent Builder MCP to search and judge.
Scans run automatically every hour via APScheduler inside the FastAPI process on Cloud Run.
Search & Indexing: Elasticsearch Cloud Serverless + ELSER
This is the core of what makes Sievy different from a keyword alert tool.
When a new post is scraped, its body is stored in Elasticsearch with the semantic_text field type. Elastic Cloud automatically runs ELSER (Elastic Learned Sparse Encoder) on index — generating sparse vector representations of the content without any external model deployment, embedding API call, or preprocessing step. Every post is semantically indexed the moment it is stored.
MCP: Elastic Agent Builder MCP as the agent's only search interface
This is where the architecture becomes interesting. The Gemini agent does not read all indexed posts. It does not loop through documents or run its own filtering logic. Instead, it calls the Elastic Agent Builder MCP — Elastic's production-ready MCP server exposed natively via Kibana — with a search query. Only the documents that Elasticsearch returns are ever seen by the model.
The agent constructs the most appropriate query based on the criteria language:
semanticquery for natural language and cross-language criteria (Korean "페더럴웨이" correctly matches English "Federal Way" through ELSER's learned semantic space)matchquery when criteria contains specific literal values that must appear exactlyboolwithshouldwhen criteria combines both types
Elasticsearch handles all the heavy lifting: semantic ranking, filtering by watch_id and post_id, and returning only the relevant subset. The Gemini agent then reads only those results and makes a judgment call — worth_checking, needs_checking, or ignore — for each one.
This means Gemini never sees irrelevant content. The number of LLM inference calls scales with the number of matches, not the number of posts scanned. MCP is not just a convenience layer here — it is the boundary that keeps the agent focused and efficient. The agent's search capability is also fully composable: the same MCP toolset could be extended or swapped without changing any agent logic.
Frontend: React 18 + TypeScript + Vite + Tailwind CSS v4, deployed as a mobile-first PWA on Vercel
Infrastructure: Cloud Run (backend) + Vercel (frontend) + Firestore + Firebase Auth
Challenges we ran into
URL pattern detection across arbitrary sites — Different listing pages structure their post URLs in completely different ways: query parameters, path slugs, base36 IDs, UTM parameters. We built a hybrid approach: Gemini classifies the URL structure once at watch creation time, and subsequent scans use rule-based matching with no LLM call needed.
Elastic MCP authentication — The deprecated Docker MCP image had persistent 401 errors caused by Docker Compose env_file variables not expanding in the environment section. Switching to the Kibana Agent Builder MCP endpoint resolved this entirely.
Cross-language semantic search — Users write criteria in their native language while post content is often in English. ELSER's semantic space bridges this gap without any translation step.
Post ID collisions on date-based URLs — Sites like University of Washington news use URLs like /news/2026/06/08/some-title/. Extracting only the day number as a post ID caused deduplication failures across dates. Fixed by detecting YYYY/MM/DD path patterns and hashing the full dated path segment instead.
Accomplishments that we're proud of
- A fully working end-to-end pipeline: URL → pattern detection → baseline → hourly scan → semantic search → alert, deployed and running in production
- Cross-language semantic matching that works out of the box with no translation infrastructure
- A clean mobile-first PWA that feels like a native app
- Verified support for a range of real-world sites with very different URL structures
What we learned
- How ELSER works and why
semantic_textis a fundamentally different approach from keyword search - How MCP connects an LLM agent to external tools in a standardized way, and why that boundary matters for efficiency
- How Google ADK manages multi-step tool use without manual loop management
- That the biggest engineering challenge in a scraping-based product is not AI — it's reliably identifying individual post URLs across arbitrary site structures
What's next
- User-defined scan intervals — let users choose their own scan frequency per watch (every hour, every 6 hours, daily) instead of the current fixed 1-hour schedule
- Web Push notifications — OS-level alerts when new matches are found, even with the app closed
- More site support — currently verified on MyBallard, Devpost, MLH, K-Seattle, UW News, and Keimyung University; expanding to Meetup, Eventbrite, and more university portals
- Scan history and analytics — track which sources produce matches and how often
Built With
- cloud-run
- elastic-agent-builder-mcp
- elasticsearch
- elser
- fastapi
- firebase-auth
- firecrawl
- firestore
- gemini
- gemini-flash
- google-adk
- python
- react
- tailwind-css
- typescript
- vercel
- vite

Log in or sign up for Devpost to join the conversation.