-
-
-
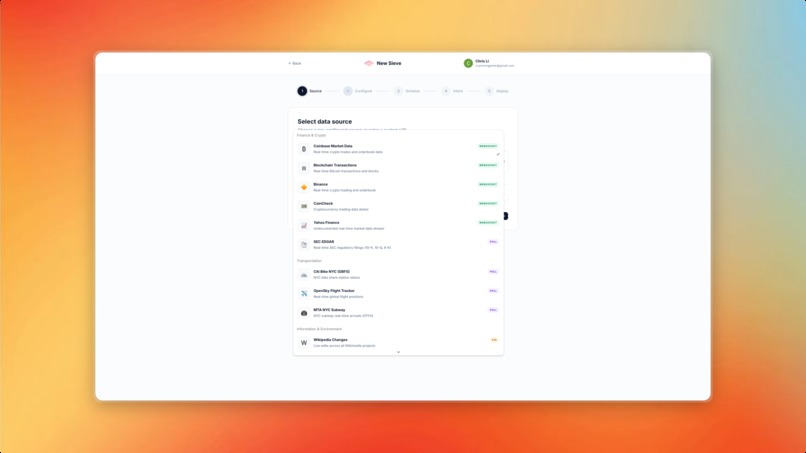
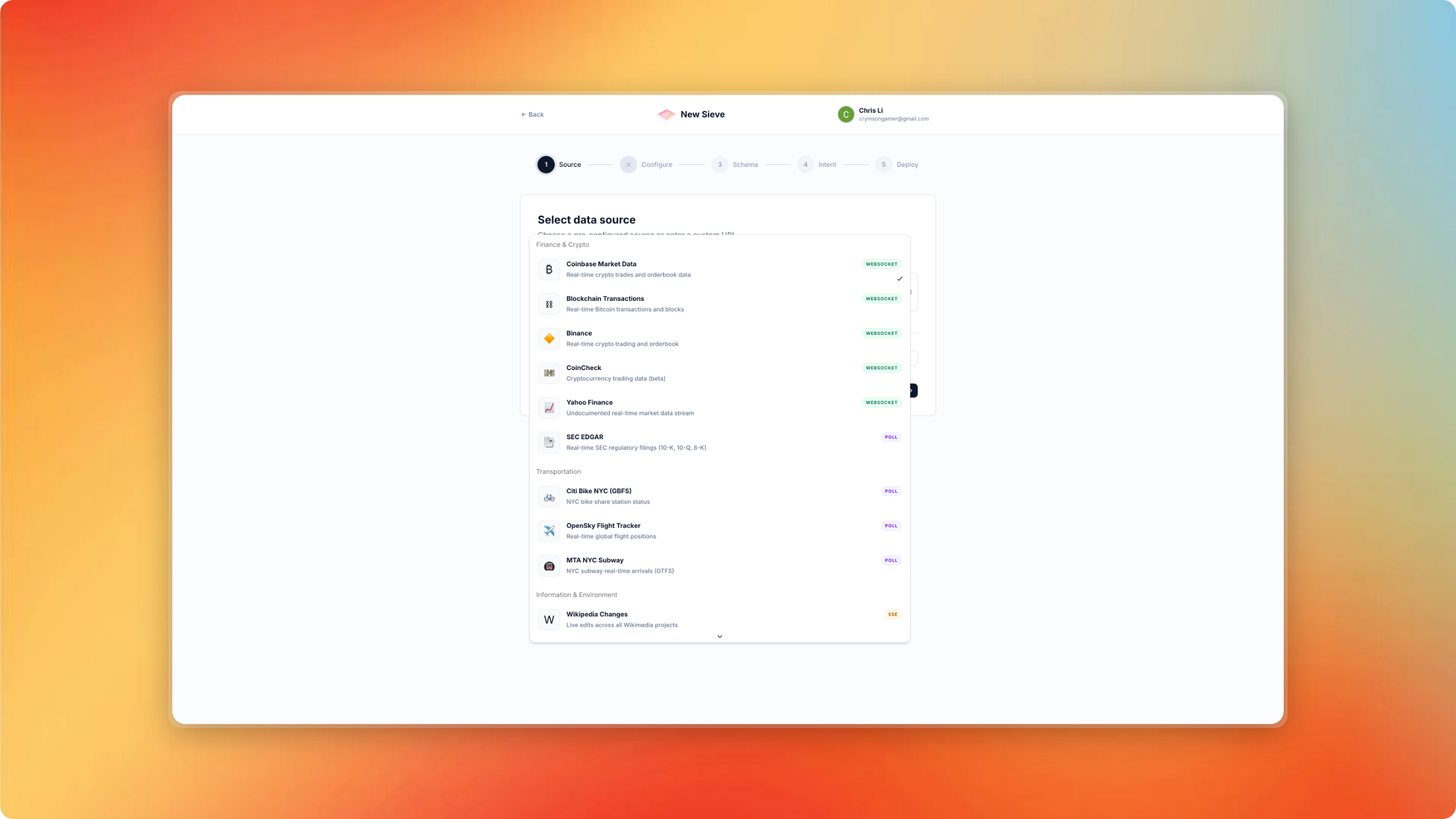
Add or choose a preconfigured data source
-
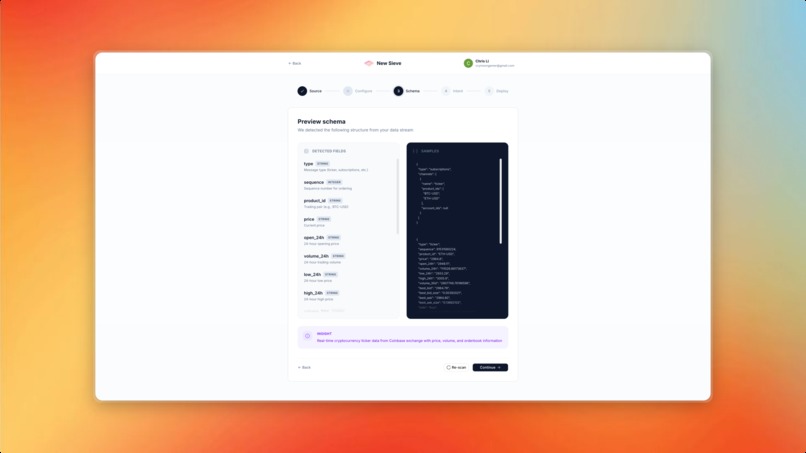
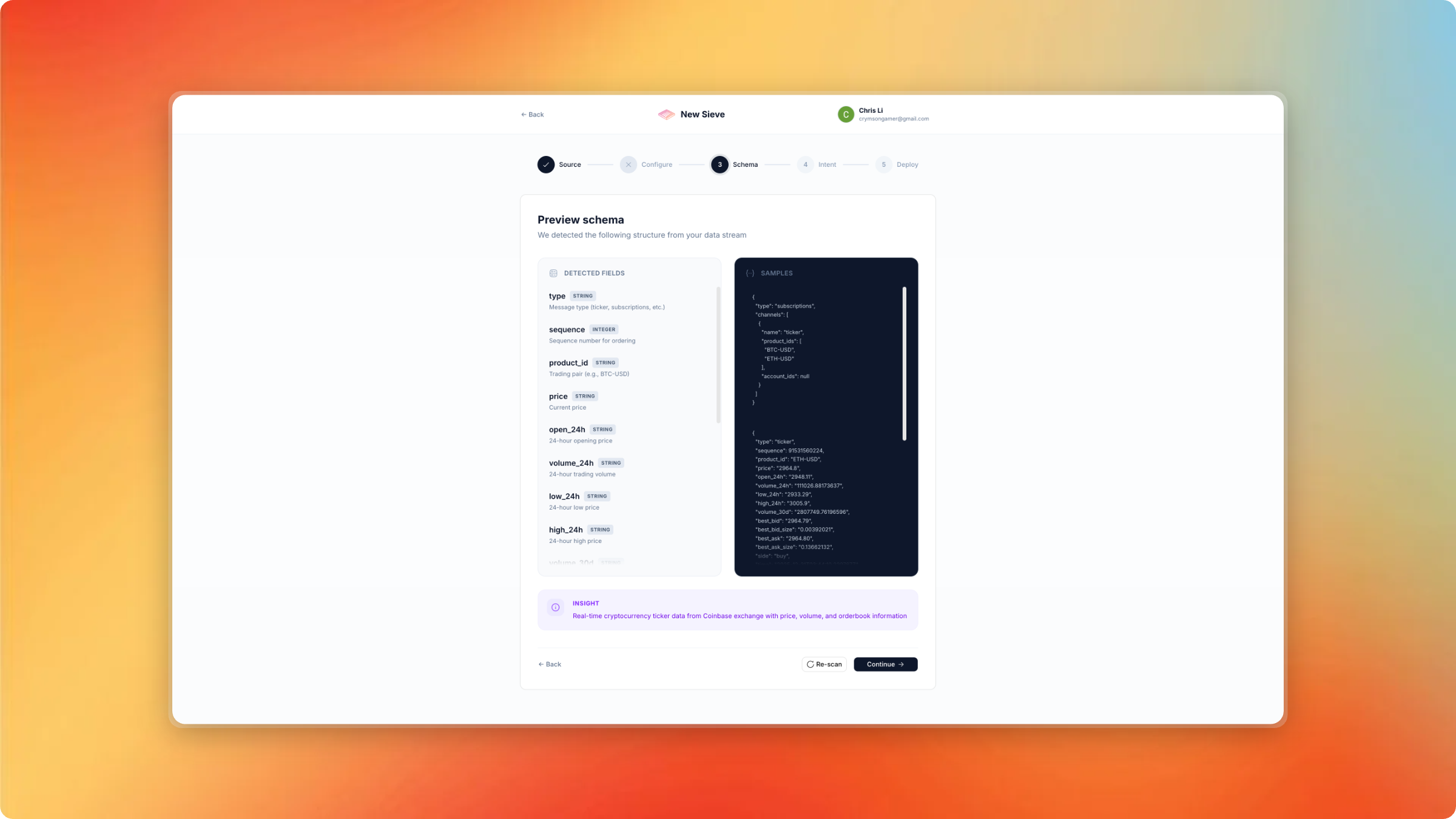
Infer the schema of the source
-
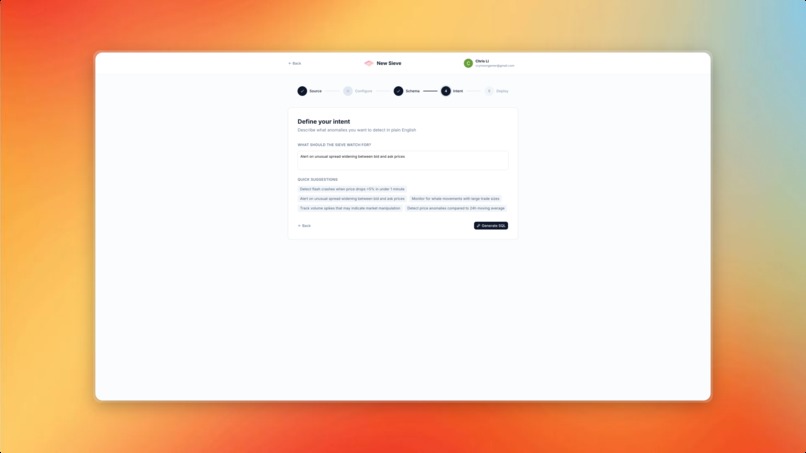
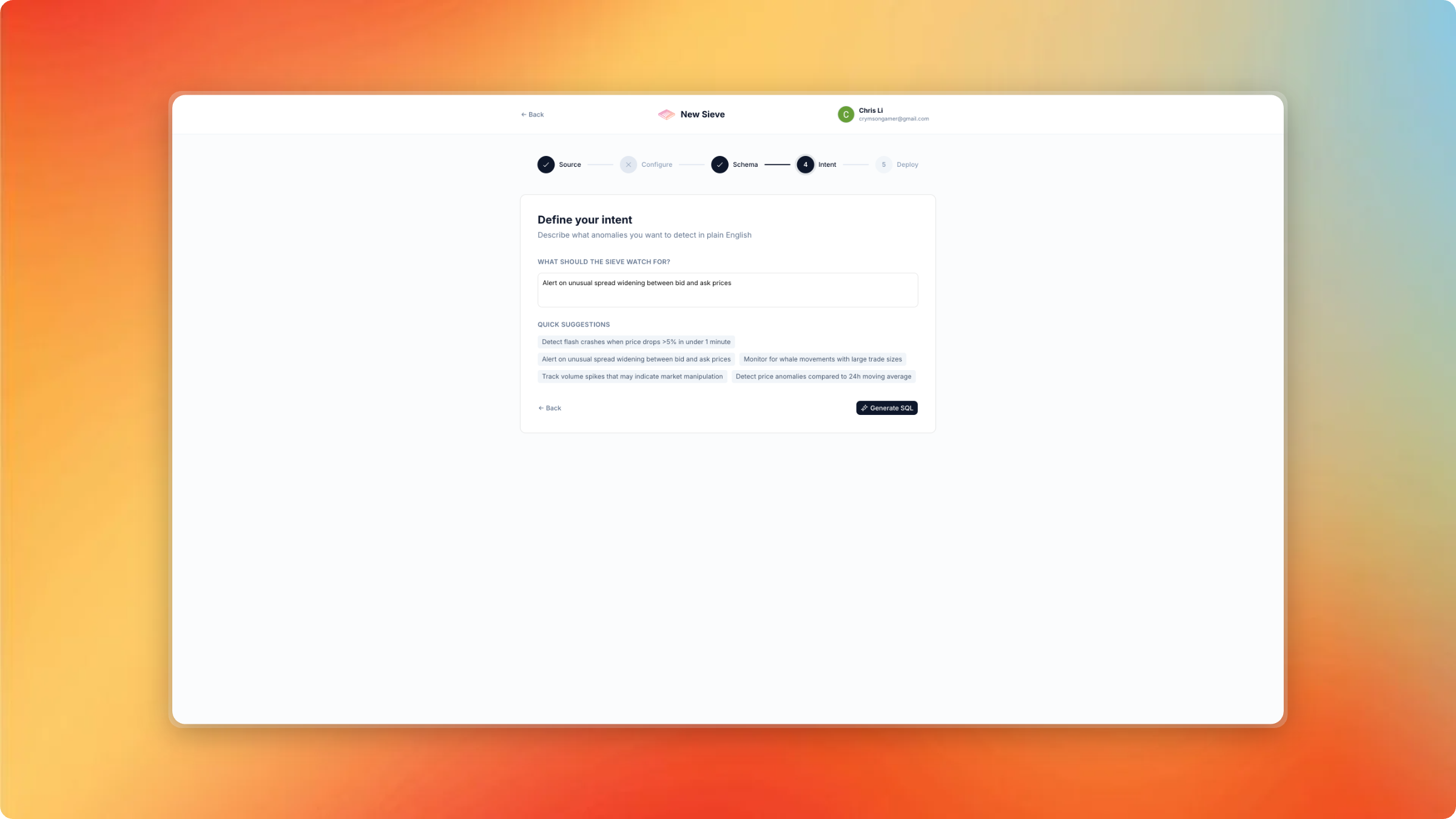
Define your intent
-
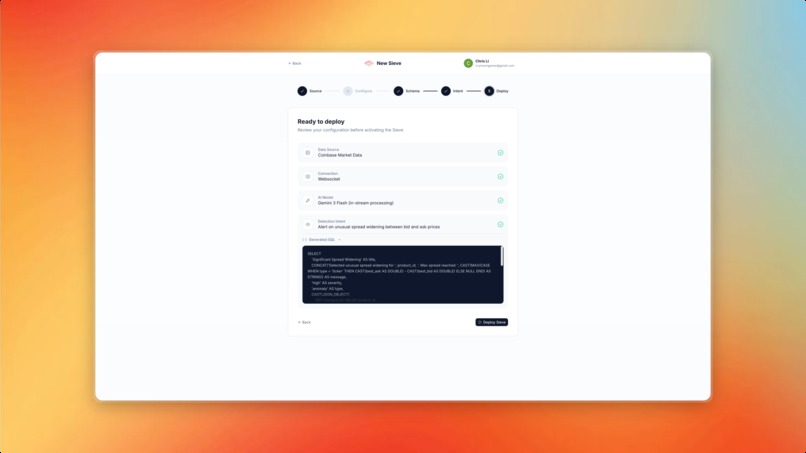
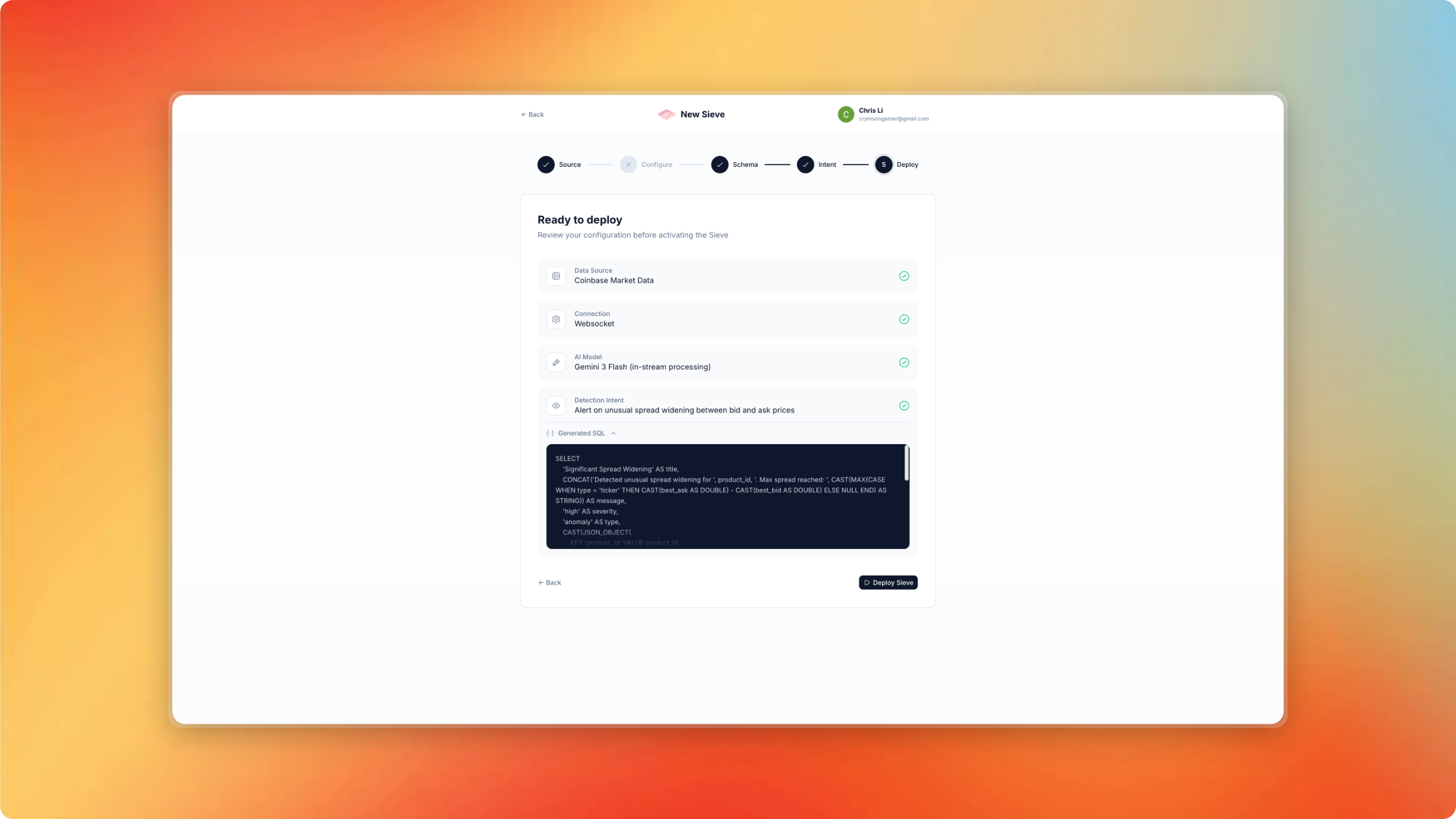
Generate Flink SQL
-
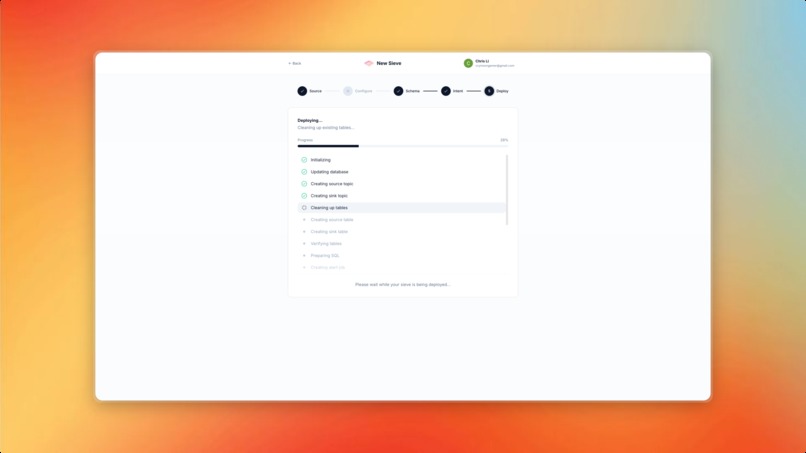
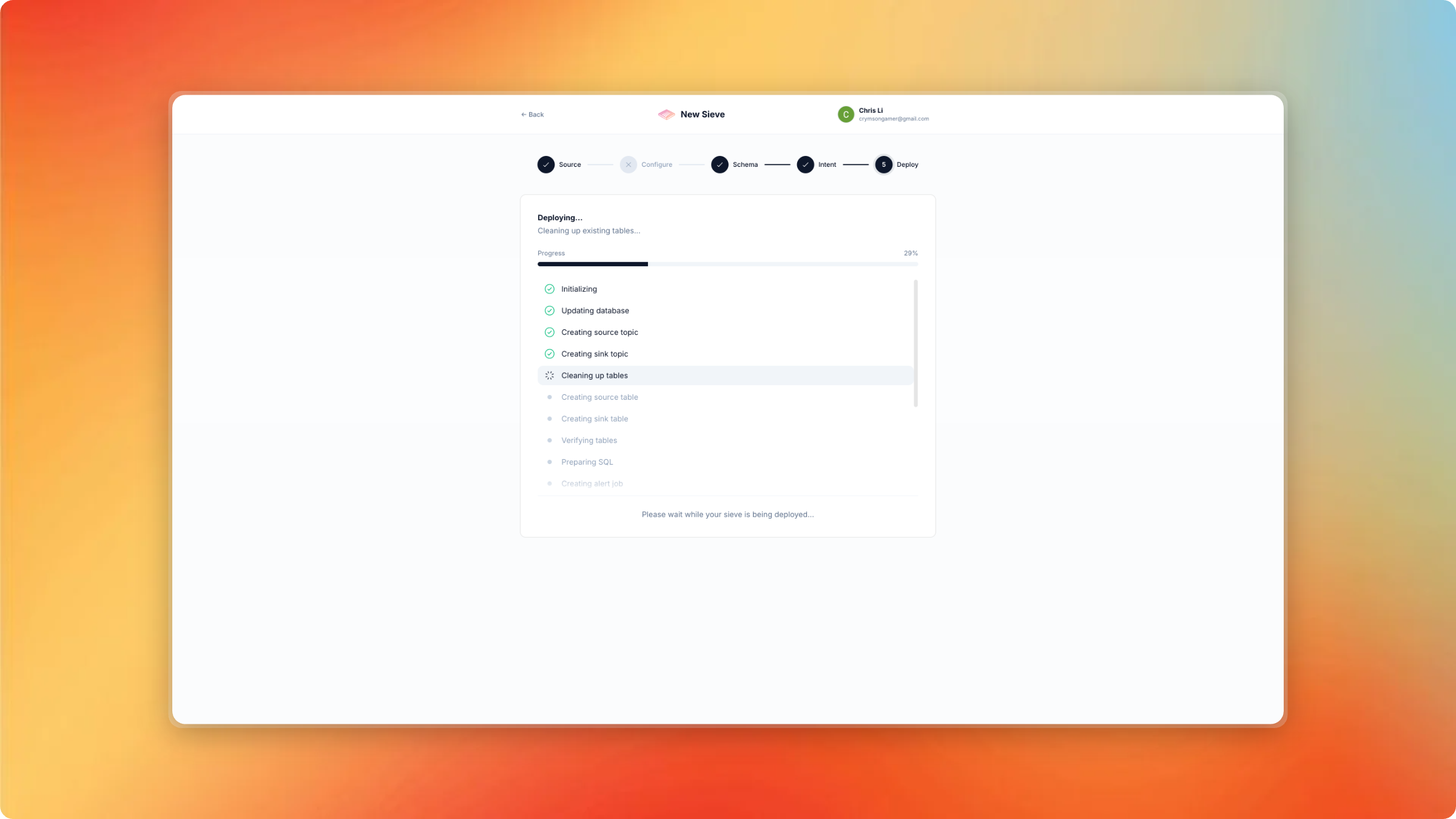
Deploy your Sieve
-
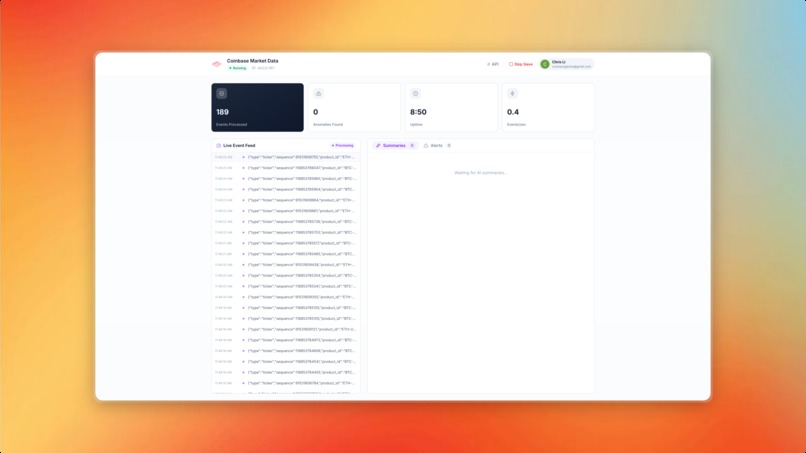
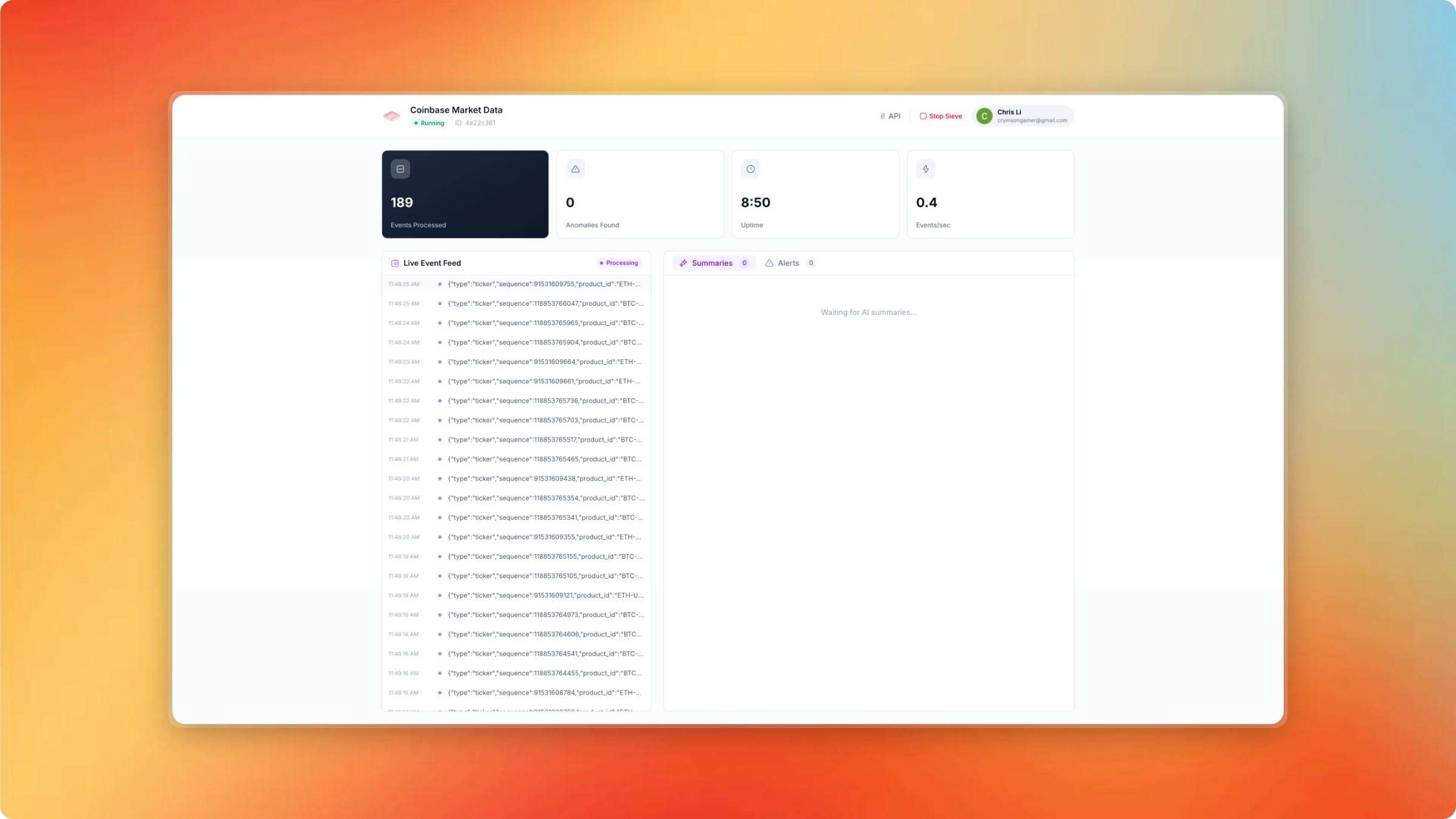
Watch for any alerts or summaries in real-time
Inspiration
I wanted to make a tool that made it easy for users to extract actionable insights from real-time data streams. Whether it's monitoring crypto prices for trading opportunities, tracking flight delays, or watching for SEC filings — the tools either require deep technical expertise in stream processing (Kafka, Flink, SQL) or they're expensive enterprise solutions out of reach for individual developers and small teams.
I wanted to democratize real-time data intelligence by letting anyone describe what they're looking for in plain English and have a system automatically monitor live data streams and alert them when something interesting happens.
What it does
Sieve is a real-time data monitoring platform that turns natural language into intelligent alerts. Users can:
- Connect to 17+ preconfigured data sources — crypto exchanges (Coinbase, Binance), flight trackers (OpenSky), transit systems (MTA Subway, Citi Bike), financial data (SEC EDGAR, Yahoo Finance), social feeds (Bluesky, Wikipedia), and more
- Describe what they want to monitor in plain English — "Alert me when Bitcoin price drops more than 5% in 10 minutes" or "Notify me when a flight from JFK is delayed by over an hour"
- Receive real-time alerts — Sieve automatically generates production-grade Flink SQL, deploys it to a streaming infrastructure, and pushes alerts via WebSocket/SSE
- Get AI-powered summaries — Time-windowed summaries of streaming data provide context and trends
The platform also exposes public SSE endpoints, making it easy to embed real-time alerts into any application or dashboard.
How I built it
Backend Architecture:
- NestJS with a dual-mode single codebase — the same code runs as either an API server (port 1888) or a Worker (port 1889) based on an environment variable
- PostgreSQL (Neon) for persistent storage with Drizzle ORM for type-safe queries
- Redis (Upstash) for distributed coordination between workers using SETNX-based locking
- Apache Kafka + Flink (Confluent Cloud) for enterprise-grade stream processing
- Google Gemini AI for natural language to Flink SQL generation with automatic validation and retry
Frontend:
- Next.js 16 with React 19 and Tailwind CSS 4
- Zustand for state management
- Socket.io for real-time WebSocket connections
- Framer Motion for smooth animations
Key Technical Patterns:
- Pluggable adapter pattern for data sources (WebSocket, SSE, HTTP polling)
- Distributed worker coordination with heartbeat-based failover
- Message batching
- AI SQL generation with Flink validation loop
- Public SSE streaming endpoints for easy integration
Challenges I ran into
Distributed Coordination — Getting multiple workers to coordinate without stepping on each other was tricky. I solved it with Redis SETNX locks, 60-second TTLs, heartbeats every 10 seconds, and an orphan scanner that reclaims dead connections.
Schema Inference — Every data source has a different schema. I built automatic schema inference that samples live data and generates JSON schemas, but handling nested objects, arrays, and inconsistent fields required careful edge-case handling.
AI-Generated SQL Validation — Gemini doesn't always generate valid Flink SQL on the first try. I implemented a retry loop that feeds validation errors back to the AI, dramatically improving success rates. It also took a lot of trial and error to craft the right prompt to in order to get the right output.
Graceful Reconnection — WebSocket sources frequently disconnect. I implemented exponential backoff with jitter to prevent thundering herd problems when sources come back online.
Cost Optimization — Stream processing infrastructure is expensive. I tried to keep costs low for the MVP but I easily accrued pretty high costs for what I thought was pretty low usage.
Accomplishments that I'm proud of
- 17+ preconfigured data sources covering finance, transportation, social, and security domains: all working out of the box
- Natural language to production SQL: users don't need to know Flink SQL to create sophisticated stream processing queries
- Horizontally scalable architecture: add workers with zero code changes, Redis handles coordination automatically
- Public streaming API: anyone can embed real-time alerts with a simple SSE connection
What I learned
- Redis is incredibly versatile: I used it for distributed locking, pub/sub coordination, message deduplication, and connection heartbeats
- Single codebase, multiple modes: running API and Worker from the same code with an environment flag simplifies deployment and maintenance
- Stream processing is hard: windowing, watermarks, late-arriving data, and exactly-once semantics have decades of research behind them for good reason
What's next for Sieve
- More data sources: Discord, Slack, GitHub webhooks, IoT sensors, custom webhooks
- Alert actions: Send to Slack, trigger webhooks, execute trades via API
- Collaborative sieves: Share and remix alert configurations with other users
- Historical replay: Backtest alert logic against historical data before deploying
NOTE: The web application is no longer usable due to cost constraints. You can still view the application at the URL provided but will not be fully functional due to Confluent resources being turned off.
Built With
- confluent
- drizzleorm
- gemini
- kafka
- nestjs
- nextjs
- postgresql
- redis
- typescript

Log in or sign up for Devpost to join the conversation.