


Inspiration
We wanted to build a better way for pharmaceutical companies to find new molecules for assay experimentation because drug discovery is a time-consuming and expensive process. We are inspired mainly by the SIDER database, which provides drug~side effect frequencies for about ~1000 small molecules. We believe in the near future more data will cause this burgeoning field to develop rapidly.
http://sideeffects.embl.de/ (SIDER website)
https://arxiv.org/pdf/1703.00564.pdf (SIDER dataset paper)
What it does
- Molecular similarity analysis based on molecular graph structure
- Drug side effect predictions
- Compile drug-gene interactions
- Drug-review sentiment analysis for experimental pharmacology
- Create synthetic latent structures from most molecules
How we built it
We used a pre-trained autoencoder on the molecular structures of 200K molecules. The molecular structures were encoded by "SMILES" strings, which describes atoms and bonds in the molecule. This SMILES representation was converted into a graph representation and the graph representation was then autoencoded. The result of the variational autoencoder is a latent, embedded representation for any new molecule (size 56). We tested out the variational autoencoder by computing similarity for known FDA-approved drugs using the latent space of these molecules. We used a denoising autoencoder for dimension reduction and visual analysis of the latent space along with tSNE and PCA. We trained and stacked a variational autoencoder inside the original pre-trained autoencoder for simplifying creation of synthetic molecules.
Next, we used the latent representation to predict drug side effects, utilizing the SIDER database. We tried random forest and logistic regression type models; this was a multi-label classification problem since there were 3000+ side effects in total.
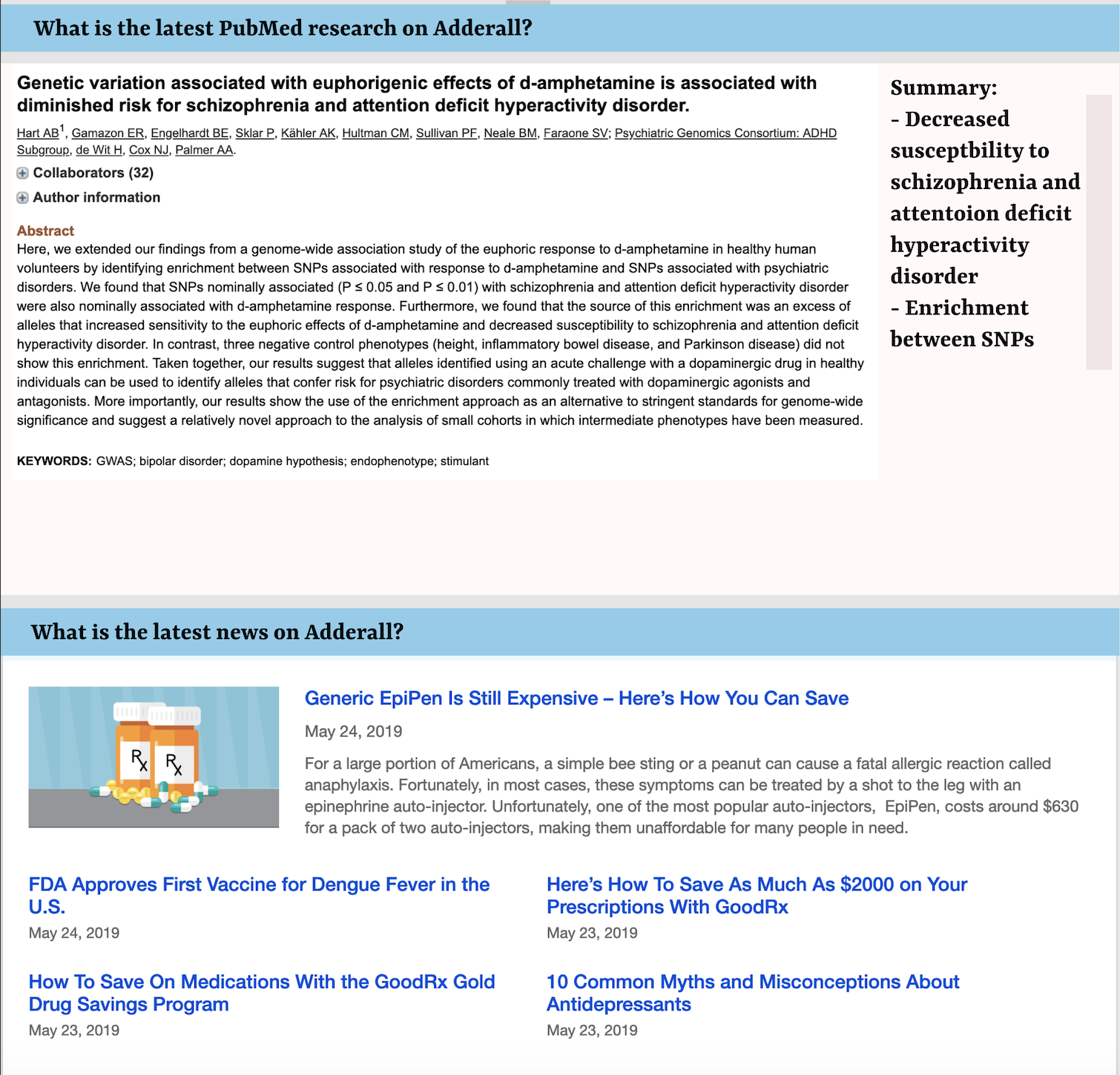
The second part of this project involved Natural Language Processing. Given a query molecule, we first find the most similar FDA approved drug. Next, we scraped PubMed articles for the latest research articles on the drug. We used NLP techniques and domain knowledge-based word lists to analyze the abstracts of these articles to mine drug-gene interactions and drug-drug interactions. For example, a drug may cause the up-regulation of a particular gene. Last but not least, we used a database of 200,000+ drug reviews to perform sentiment analysis, in order to present a list of "Pros" and "Cons" of the given drug.
Challenges we ran into
The main challenge we ran into was the lack of data in the SIDER database for side effect prediction. SIDER only included about 900 usable molecules. As a result, training side effect predictors using deep learning was challenging. To baseline our deep model performance, we trained a random forest on the latent vector representation that our autoencoder returned and drug~side effect pairs and evaluated on a validation set with Hamming loss. We then trained a logistic regression model and multilayer perceptron on the same datasets, but ultimately chose to not use those models as the random forest proved to be more effective. However, we believe this to be due to the scarcity of data (# of trainable parameters >> # of train examples) and not the lack of representational power of the latent vectors, because the deep models did improve in validation set Hamming loss performance. Another problem was the skewness of the data given the large amount of side-effects. We overcame this problem by oversampling and changing the loss function of the machine learning model to handle class imbalance.
Accomplishments that we're proud of
1) Successfully trained a variational autoencoder on molecular structure to produce meaningful latent vector representations of molecules and validated on FDA approved drugs to verify similarity analysis performance.
2) Successfully trained a good side-effect predictor (F1-score = 0.6), capable of predicting side effects for any new molecule.
3) Successfully built a framework to scrape and mine PubMed articles given a query drug, to extract drug-gene interactions as well as drug-drug interactions.
4) Implemented sentiment analysis and text summarization for drug reviews, in order to show "Pros" and "Cons" of a given query drug.
What we learned
We mainly gained a lot of experience in training autoencoders and harnessing the power of deep learning. We experimented with various compression levels and learnt the trickiness of optimizing the hyperparameters of the model. We also learnt how to deal with small, imbalanced datasets (SIDER). We also gained experience with NLP algorithms for text summarization, sentiment analysis, and keyword matching.
What's next for PharmaAggregator
We want to build PharmaAggregator into a full-fledged website and pitch the idea to real pharma companies to see if they would be interested in using our product. We believe that our product is capable of saving pharma companies a lot of money, by expediting the drug discovery process.

Log in or sign up for Devpost to join the conversation.