-
-
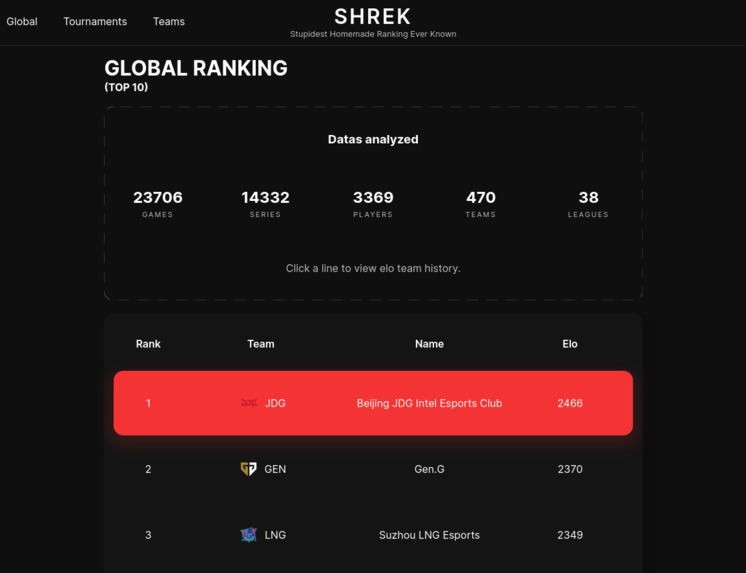
Top 3 teams of our ranking at the end of August
-
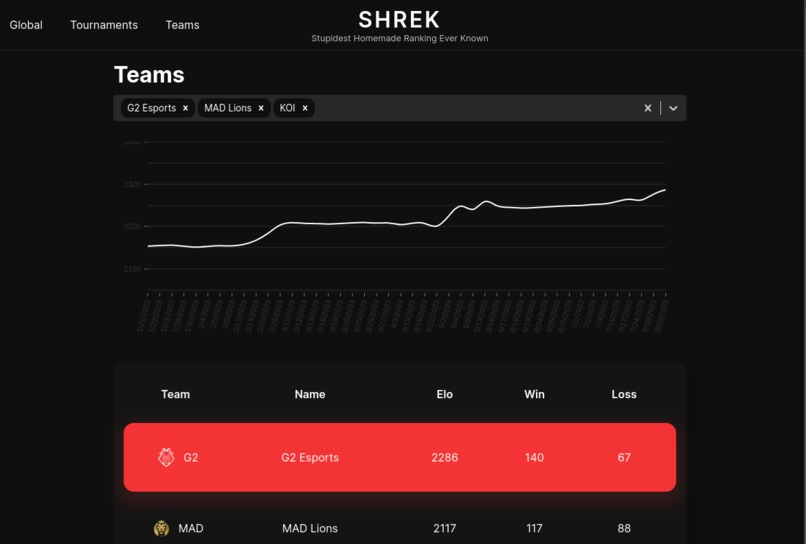
Evolution of the rating of G2 for the last 12 months
-
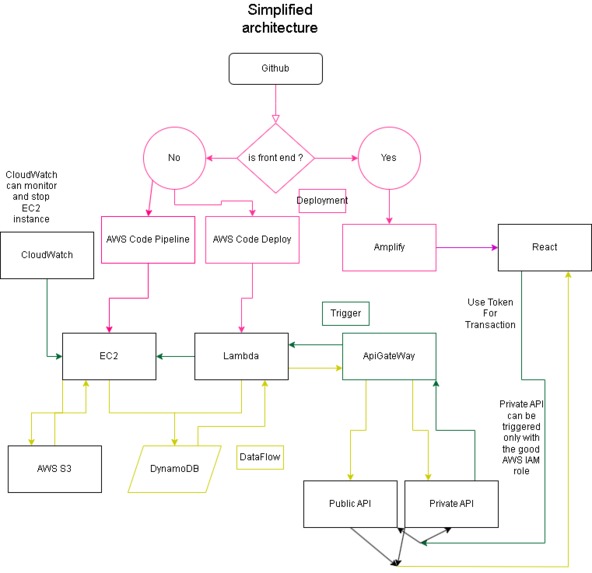


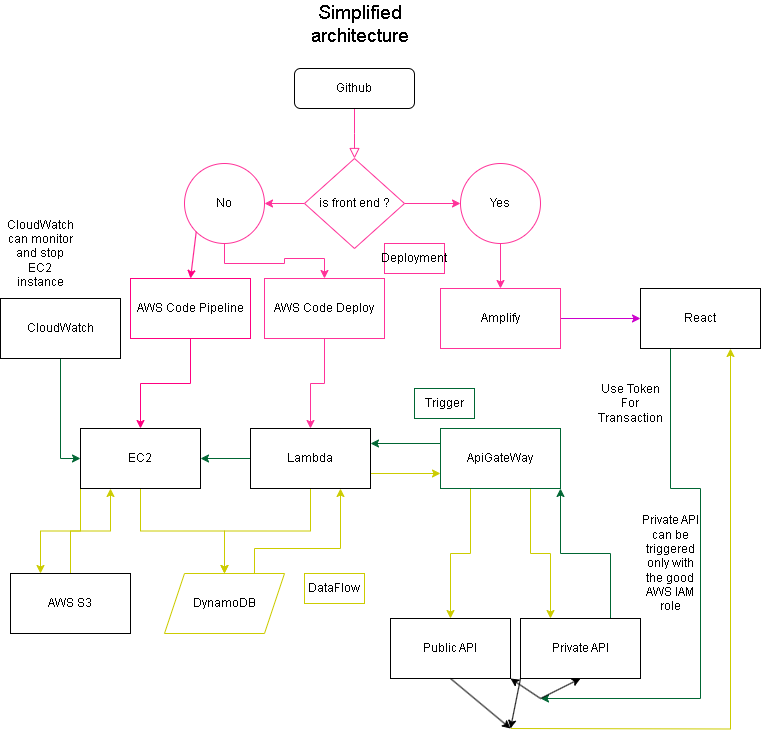
Outline
You'll find two parts to this description, the first part is about the ranking system, the second part is about the tools that we used to build our project.
Ranking system
This part has been written using Markdown formatting. If it does not render correctly, it is available here.
Preamble
Ranking system have been studied for a while, so we wanted to avoid reinventing the wheel. Instead, we took 2 well-studied solutions and adapted them to the specificities of the professional League of Legends scene:
Elo rating system, created in 1960 and notably used in Chess:
- it has been extensively studied and tested in real life situations (Chess, Football, Tennis, Go, Backgammon, Magic: The Gathering, Baseball, etc.);
- it can struggle with team games as it is initally designed for solo games.
TrueSkill system, created in 2007 and used in many Xbox games:
- it includes elements that handle the specificity of a team game;
- it is meant to be paired with a matchmaking system, and can struggle when the players always play with the same teammates.
Each system has their pros and cons and after implementing both systems, we ended up using the elo system as our base solution with adaptations to handle its weaknesses.
Base Elo rating System
The basis of the Elo rating system is a simple statistical model: for each game, in chronological order,
- we estimate the expected performance $P_e$ of each team, using their current rating;
- we evaluate the observed performance $P_o$ of each team, using the game data;
- we evaluate the importance $K$ that the match should have in our model, ranging from 5 to 40;
- we update the rating of each team by confronting what we expected to what we observed, using the following formula: $$rating_{new} = rating_{old} + K \cdot (P_o - P_e)$$
Different adaptations
The League of Legends pro scene has its own specificities when compared to other playgrounds for the Elo rating system. Because of that, we had to adapt the original system.
Team volatility
In professional play, as opposed to Solo Queue, the performance of the different members of a team cannot necessarily be separated. Most decisions are made as a team, and the performance of one team member can be sacrificed if it means increasing the chances of winning. That is why we do not try to evaluate the personal contribution of each player (also, we believe that such a player rating would be bound to be either irrelevent or non portable between patches and regions).
However, in chess for example, the composition of a team does not change over time as a team is just one player. In League of Legends, it is not the case, and we must account for these changes.
To address that, we added two adaptations:
- rating repartition: the actual rating of a team is reparted between its six members (the esports organization itself, and the five players). Half of the rating belongs to the org itself (JDG, G2, GenG, C9, etc.), while the remaining half is equally reparted among the five players.
- team convergence: after a few months of playing together, it becomes hard to separate the performance of the different players: they win together and lose together. The rating system should reflect that, which is why the rating updates are reparted among the members of a team in such a way that their ratings should converge.
With these changes, we can make make relevent guesses as to the new rating of the teams after their compositions change each year.
The specific implementation for this part can be found in the file rankingssystem.py with the class PlayerEloSystem.
Strength of Win (performance evaluation)
In order to run our elo system, we need to be able to evaluate the performance of a team in a given game. As said previously, we do not try to evaluate the individual performance of the players, but still we inspect the content of the game. Our evaluation of a performance is a weighed combination of:
- the outcome of the game (weighed 90%): for a given game, the winning team gets an outcome performance of 1, and the losing team gets an outcome performance of 0;
- the control over the game (weighed 10%): for a given game, each team gets a control performance related to how much relative experience and golds lead it had over the course of the game. This metric seemed relevent and objective as it is now part of the design the game with the inclusion of the Objective Bounty System.
The specific implementation for this part can be found in the file games.py with the function goalavg(game).
Regional strength
A key element of the pro scene, that is a current element of interest with the 2023 World Championship, is the relative strength of each region. One of the problem of the original elo rating system is that it ranks well teams that often play against each other, but can be inacurate when comparing teams that don't face often.
Note that for this matter, we consider inter-league competitions such as the EMEA masters with the same logic as the World Championship or the MSI.
To still have an accurate representation of the relative regional strength, we added 3 elements to the elo rating system:
- importance of matches: we increase the importance $K$ of inter-regional matches, to reflect the fact that teams playing at international competitions do not only represent themselves, but also all the teams of their region;
- historic data mockup: we play back the first years of data provided (2020-2021) to mockup the data that we are currently missing (2013-2019). By doing so, we allow for better comparison between the different regions, as we start with an already balanced state;
- cold start: when a player or a structure plays their very first game, its starting rating will be the average of the current ratings in the league it is playing. We do so to avoid completely nullifying the regional strength evaluation that has already been built.
Closed pools
As just stated, the elo rating system can be inacurate when comparing teams that don't face often. It actually completely fails when comparing teams that belong to different connected components of the ecosystem (e.g., the ERL system in Europe and the NACL system in North America).
Because of that, we included in our API an endpoint /clusters that gives a list of the different clusters. For the global ranking, we only consider teams that can access to the World Championship and MSI.
Limitations and Future work
More data (older and newer)
We are currently facing two limitations that share the same solution:
- the data only starts in 2020, which might hurt our evaluation of the regional strength. Our current Band-Aid fix is to replay the first years of competition (2020-2021).
- the data stops around mid august 2023, which means that we cannot have recent information (e.g., we do not have the latest data about teams competing at the World Championship).
Having a direct access to the game data (complete or partial) would solve both these problems. However, in case it was not possible, we have already started investigating leaguepedia's API for accessing the data related to competitive League of Legends games.
The Vietnamese anomaly
You can notice in our rankings that the VCS teams are lower than expected (when compared to LJL teams or to their current outstanding performance at the World Championship). VCS teams were heavily impacted by Covid restrictions, and as a result are missing from more than half of the provided data. Because of that, our system seems to fail at evaluating the performance of VCS as a region.
We did not provide a Band-Aid fix for this as we hope it should be solved by the use of older data.
Application
We see three main applications to our rating system, and plan on implementing the first two, while the third is not up to us:
- provide a better and faster understanding of the ecosystem, especially when approaching major events such as MSI or the World Championship.
- using the ratings to estimate the probability for different scenarios in complex settings such as a regular season, a group stage, or a Swiss-system tournament.
- a Swiss-system tournament has been included in the new World Championship. It is well-known that the quality of a Swiss-system tournament can greatly be increased using a complete seeding of the teams, by reducing the impact of randomness. A rating system could be used for such a seeding.
Tooling
This report has been written using Markdown formatting. If it does not render correctly, it is available here.
Preface
We decided to fully embrace the contest challenge and leverage as many AWS technologies as possible instead of staying within our comfort zone. This hackathon marks our very first experience with AWS services. We decided to continue with the project post-competition, and will explain later on what we will change in our "reset" of the architecture after the contest.
Listing:
Non-AWS Service:
- Github
AWS Services
- CloudWatch
- EC2 (Elastic Compute Cloud)
- AWS CodePipeline
- AWS CodeDeploy
- Amplify
- Lambda
- API Gateway
- S3 (Simple Storage Service)
- DynamoDB (Not implemented due to time constraints, will replace JSON files in the final project)
- IAM
- AWS Step Function
- AWS Budget
Technology Choices
Github
We chose to use Github as a hosting platform for version control and source code management. We did not use AWS Commit, as we are accustomed to this tool, and AWS tools interface very well with Github.
AWS CloudWatch
AWS CloudWatch is a monitoring and management service that provides data and actionable insights for AWS resources and applications. We use it to collect and track metrics, to collect and monitor log files, to set alarms, and to automatically react to changes in your AWS environment. We use it extensively to track error codes from lambdas and from the API Gateway.
EC2 (Elastic Compute Cloud)
EC2 provides resizable compute capacity in the cloud. It's used to host our data algorithms, allowing quick scaling based on workload needs, thus ensuring flexibility, security, and reliability. Our usage is mainly aimed at processing provided files, taking advantage of substantial computing power. We have a global cost control strategy, and in this regard, EC2 is used only when we have computational needs.
AWS CodePipeline
We use AWS CodePipeline to automate delivery pipelines, allowing a quick and reliable process for updating our data scripts on EC2. We have disabled delivery automation, as EC2 sometimes runs for several hours and we were afraid of side effects if we launched the pipeline during a script run. To simplify pipeline usage for individuals who can't access the AWS console (knowledge, security, etc...), the pipeline is activatable by a secure API call.
AWS CodeDeploy
We use AWS CodeDeploy to automate the deployment of our python lambdas upon a push on main.
Amplify
AWS Amplify simplifies application development by providing a set of tools and services that help with hosting; we use it for deployment and hosting of our front-end application.
Lambda
AWS Lambda allows us to run functions without provisioning or managing servers. We can run code for virtually any type of application or backend service, with automatic scaling. We do not use -and will not use- servers for this project; lambdas allow us to perform all the interactions that our micro-services would normally have done, such as retrieving the top 10 teams.
Step Function
We use Step Function very lightly. We needed, via an API call, to be able to start an EC2 instance, and when it was fully started, launch a script for elo calculation.
API Gateway
We use API Gateway to create, deploy, and manage APIs. We use it to serve the results of our lambdas to the front-end, but also as a tool for people developing, through private routes, for example to start the EC2 and launch a script, start the pipeline, or search for files on our S3. The usage might be diverted from its initially intended use by Amazon, but it allows us to have usage of other AWS services by people not having competence on these services.
S3 (Simple Storage Service)
Amazon S3 is used for object storage. We chose it for its durability, availability, security, and performance. S3 also allows us to optimize costs and organize resources according to our specific needs. We are also currently using it as a makeshift database. Indeed, we did not have time to implement DynamoDB, and we are currently storing the results of our computation algorithms as JSON files on S3. A mount point has been made using s3fs-fuse between S3 and EC2 to quickly access our documents from anywhere.
DynamoDB
Although not yet implemented, DynamoDB is planned to replace the currently used JSON files. It's a NoSQL database that offers fast performance and scaling. We plan to use it to improve data flexibility and management.
IAM
IAM (Identity and Access Management) is essential for managing access to AWS resources securely. We use it to control user access, assigning them specific roles and permissions, and also managing roles and policies of our different services, thus ensuring proper security and resource management.
AWS Budgets
AWS Budgets gives us the ability to set custom budgets to monitor our AWS costs and usage. We can create budgets to track costs associated with specific AWS services, accounts, or tags. AWS Budgets also alerts us when we exceed our predefined cost and usage thresholds. Using AWS Budgets helps us better manage our financial resources while continuing to optimize performance and operational efficiency. Interestingly, we had overestimated the cost of a t4g and underestimated the consumption of a c6g; the automatic email really helped us to modify the EC2 instance type.
Future
Technology
AWS Cognito
We did not have time to look into AWS Cognito, but it could be used in our serverless approach to manage identity, authentication, and authorization for our future users, with options for multi-factor authentication, integrations with third-party identity providers, and easy customization of user flows.
Machine Learning and Artificial Intelligence
We are also interested in exploring AWS services related to machine learning and artificial intelligence, such as AWS SageMaker and AWS Comprehend. This would allow us, for instance, to make result predictions, performance analysis, fine-tune and optimize Elo calculations by taking into account more variables. It won't be our priority, but we keep it as an idea.
Cost and Performance Optimization
We will also work on cost and performance optimization. By exploring and adopting additional AWS best practices, tools, and technologies, we aim to make our architecture more efficient and economical.
Conclusion
AWS was a real surprise for us. Although complex, the setup was easier than what we had heard from our surroundings. We particularly appreciated the possibility of going serverless for our application, and being able to control our costs effectively, paying only for what we use, which allows us, for the same cost, to have much more than what we could have through a server renter, as well as the simplicity of setting up tools such as pipelines.
Built With
- amazon-budget
- amazon-cloudwatch
- amazon-ec2
- amplify
- api-gateway
- codedeploy
- codepipeline
- github
- iam
- lambda
- postman
- python
- react
- s3
- stepfunction
- terraform






Log in or sign up for Devpost to join the conversation.