Inspiration
Investing is an art, not a science. In global money flow markets dictated by growth and value investing, individuals often look at a myriad of non-financial news updates beyond financial analytics of a company on issues including management, innovation, and expansion to guide decision-making. But, not all investors have the same principles or styles even when looking at similar firms: thus, while generic updates can be found by the Google Engine or NASDAQ, there exists a deep information asymmetry since it is difficult to find tailored relevant news that truly affect a specific individual's cognitive processes. Thus, we were inspired to build a full-stack application that displays news reports to an investor and which, based on user feedback (relevant/not relevant), continuously 'learns' investor's style to better present relevant articles about a firm to aid investing activities.
What it does
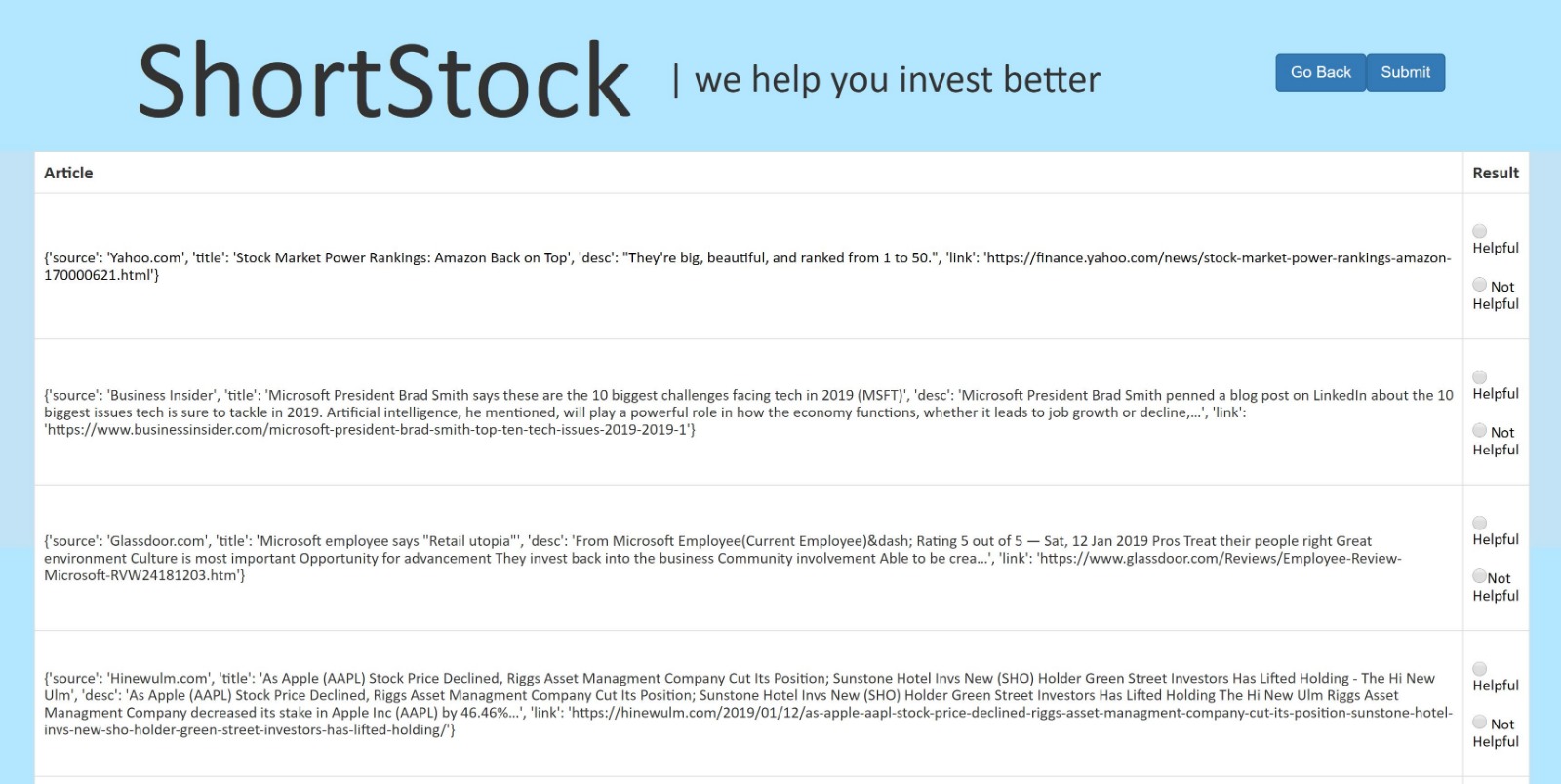
ShortStock essentially creates a customized news feed of investing-relevant developments surrounding a company to best support an individual investor. Its web interface takes a company ticker as input and passes it through Google News API to find recent articles. The code help scrape news reports into lists of important phrases, then compared to a keyword database to find most relevant tags/categories for each article. These tags are subsequently inputted into our machine learning algorithm which uses previous data sets to determine whether the investor is likely to find the article relevant (and hence must be displayed) or not. Quick summaries and URLs of the relevant chosen articles are then based back to the investor on the webpage. Each article is accompanied by radio buttons for the investor to determine helpful/ not helpful which then updates the ML algorithm's training set for more optimized future results.
How we built it
The application first renders an interface webpage built on Bootstrap (HTML, CSS) to take the ticker input. Control in the program is passed to a central flask code (running on a local flask server) that receives data by POST. Using modules in file structure, the code calls Google News API and runs article URLs through BeautifulSoup and Diffbot Article API to find the aforementioned list of main phrases. Our database handling downloads keyword dictionary by SQL and then uses a matching algorithm in O(n2) to compare each phrase to the entire dictionary. The frequency-of-occurence for each tag determines the final relevant category for the article, which the flask server then passes to our ML neural network. Using multi-layer perceptron that trains using backpropagation and LBFGS, we use the Cross-Entropy loss function and in-built regularization functions to create a 'usefulness matrix' of binary values. The output of relevance binaries is then mapped to the article list to dump our relevant reports onto, and render, the final HTML page. The user's submission of "helpful"/"not helpful" on the final page passes control back to the Flask server to run SQL queries that add said new entries to the the investor's specific training dataset on the database for future use.
Challenges we ran into
While our code functioned effectively as individual components (database management, algorithm design, API and front-end), integrating them into a full stack with the flask interface turned out to be our singular defining problem through the hackathon. There were often inconsistencies across the data types and models that were used, making the internal transfer of control and information difficult. This integration issues were exasperated by difference in versions of softwares as well as difference in syntax across the programming languages combined in the stack. Furthermore, we also experienced issues in adjusting the dimensionality of our neural network input and the time complexity of our relevance algorithm (we had to restrict our articles to 7 to ensure manageable speed).
Accomplishments that we're proud of
Over the entire duration of our hackathon, we were proud of having addressed our integration issues in achieving an efficient flow of control across the program stack for seamless input and data transfer. We are also proud of having learnt, implemented and debugged an entire new language - Flask - over the course of just this hackathon since it was an integral part of our project. Moreover, we achieved seamless remote database hosting to form the backbone of our entire interface.
What we learned
The hackathon was a elementally transformative experience for us as developers, exposing us to APIs, technologies, tools, mentors and valuable professional networks for knowledge acquisition. Through extremely helpful as well as supportive mentors, we learnt how to ideate, develop and maintain a full stack. We also learnt the idea of "extension development" i.e. building projects on the backs of existing releases, documentations and frameworks. Moreover, this event helped us develop key soft skills including tenacity, perseverance, work ethic, diligence and team work that are not only integral to our eventual transition to co-op and the work space but also to our evolution as more skilled and dependable programmers.
What's next for ShortStock
Our project currently stands at the very crucible of development - while we conceptualized a simple executive version of our idea, we recognize that there exist significant avenues for improvement. Firstly, we would improve run-time complexity of our major algorithms, including ML, API reading and web-scraping in order to accommodate more articles into a manageable time frame. We would also use a larger training set for our neural network to improve predictive accuracy, along with support for multiple tags for each article (such that information can belong at the very intersections of a matrix than simply categories). Lastly, higher front-end functionality could be implemented, through JavaScript (React.JS) to create a more intuitive and expressive GUI to enhance user experience.
Built With
- api
- beautiful-soup
- bootstrap
- css
- diffbot-article
- flask
- google-news-api
- html
- machine-learning
- neural-networks
- phpmyadmin
- python
- sql








Log in or sign up for Devpost to join the conversation.