-
-

-

Try out front end data visualization!
-
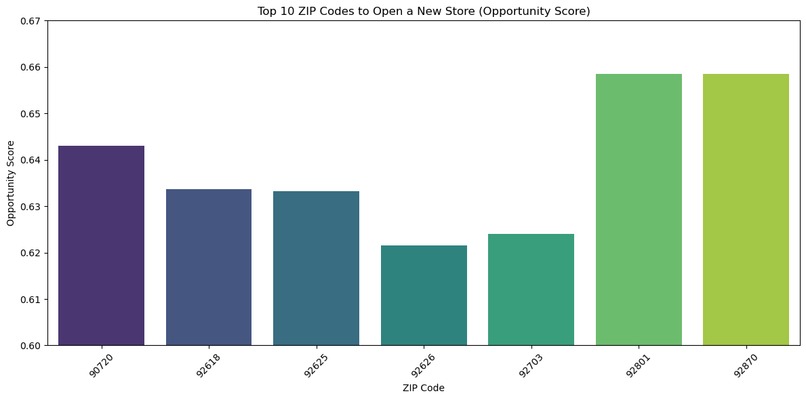
-
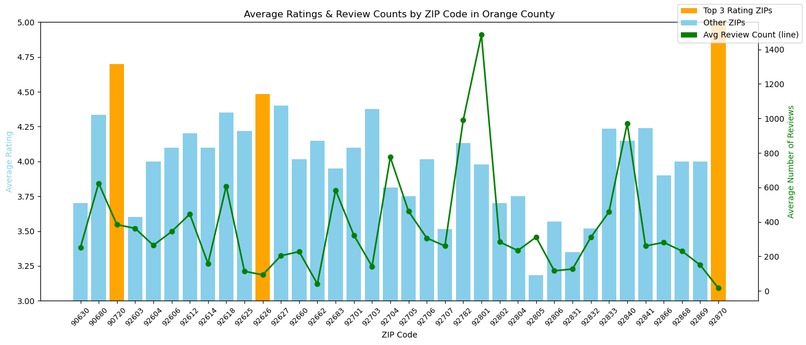
-
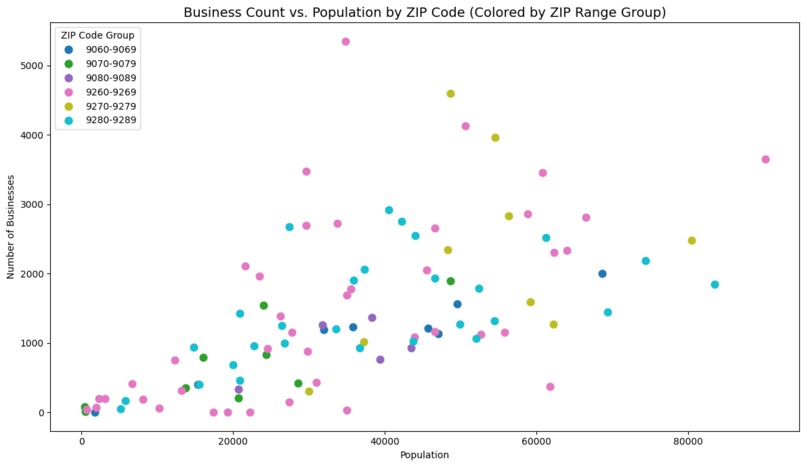
Orange County population and business


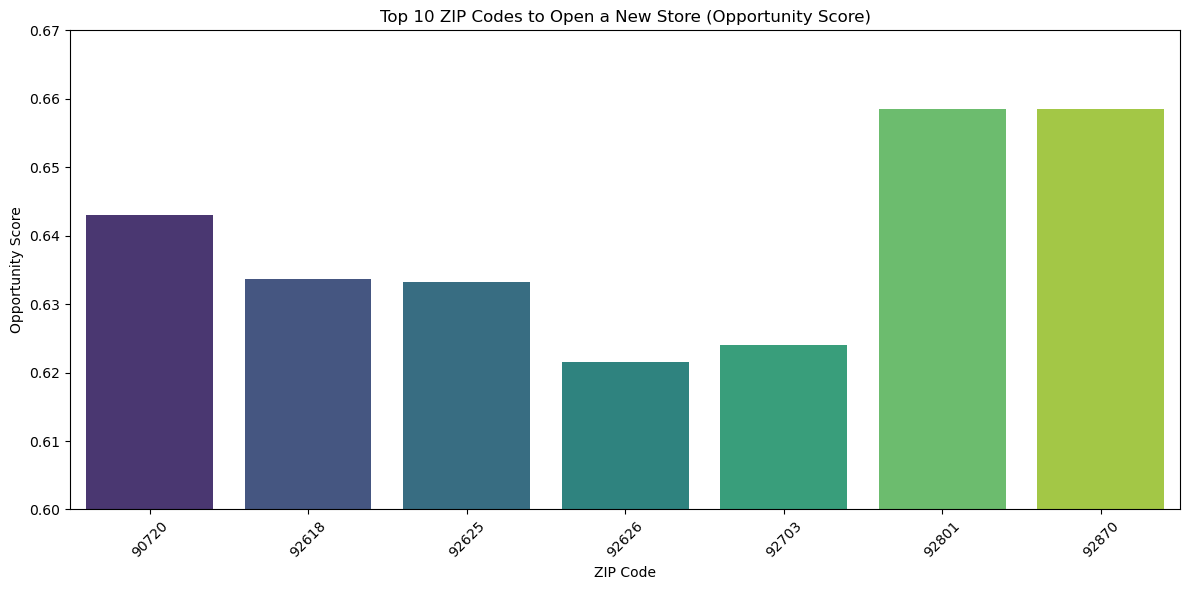
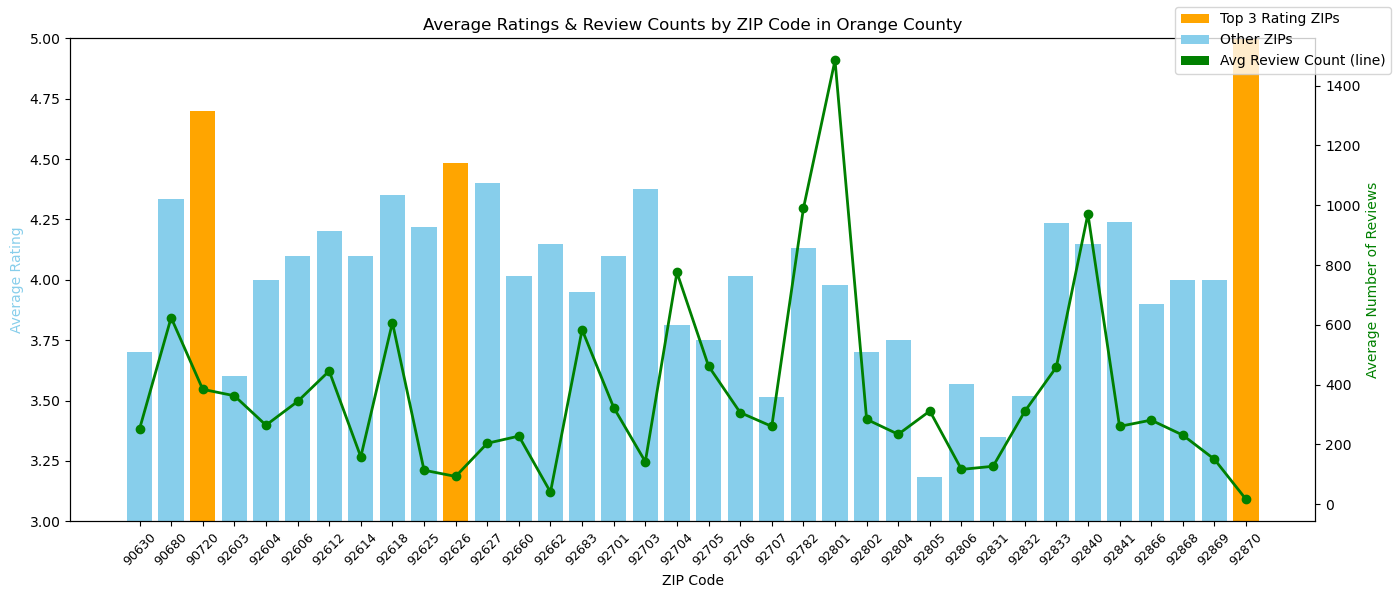
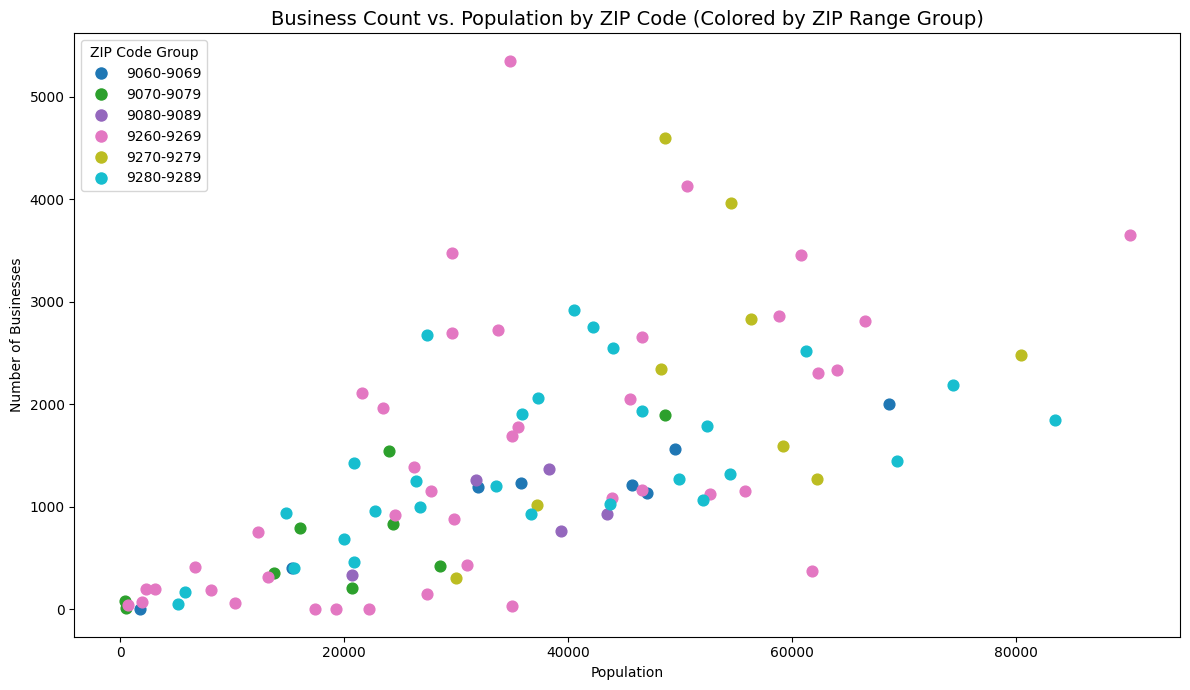
Inspiration
We were inspired by the real-world challenge of helping new businesses choose the best locations to open. With so much public data available—like demographics, income levels, and crime rates—we wanted to create a tool that leverages this data to uncover ideal ZIP codes for setting up shop in Orange County.
What it does
ShopWhere analyzes ZIP code–level data to cluster areas based on key metrics like population, income, education, and crime. Users can quickly identify regions that fit their target business profiles (e.g., safe areas with high income and education for boutique fitness centers). It also processes business review data to highlight local customer sentiment and demand.
How we built it
Our project followed these major steps:
Step1: Data Collection:We gathered Zillow Home Value Index (ZHVI) time-series data per ZIP code. We used the ATTOM API to fetch neighborhood-level features, such as demographics, income, crime, climate, and disaster risk. We scraped and cleaned business ratings and categories from public sources (e.g., Google Places).
Step2: Data Processing & Feature Engineering: We aggregated long-term housing trends (mean, median, growth %, standard deviation).We cleaned and transformed categorical fields like types into a primary_category for modeling. We merged all community metrics into one comprehensive dataset, aligned by ZIP code.
Step3: Modeling: We trained a Random Forest Regressor to predict a store’s average rating based on:Community metrics, ZIP code, Primary business category. We used SHAP for model interpretability and feature importance visualization.
Step4: Recommendation Engine: Given a new store's category (e.g., cafe, bubble_tea, grocery_store), the model suggests the top ZIP codes where similar stores are likely to succeed.Ratings are predicted for each ZIP using trained features + one-hot encoded categories.
Challenges we ran into
- The
typesfield in business data was stored as a literal string (e.g.,'["store", "point_of_interest"]'). Initially, indexing gave wrong results like individual characters. We fixed it usingast.literal_eval()to convert the strings into real Python lists. - Choosing the number of clusters (
k) was non-trivial—we used the elbow method to find a balance. - Data from different sources had different formats and required careful cleaning and merging.
Accomplishments that we're proud of
- Successfully converted messy strings into usable Python objects and cleaned the dataset end-to-end.
- Developed a working clustering model to categorize ZIP codes based on multiple factors.
- Integrated and visualized business review data in conjunction with demographic clustering.
What we learned
- How to handle stringified lists in Pandas using
ast.literal_eval(). - How to use unsupervised learning techniques like K-Means in a geospatial and business context.
- The importance of feature scaling before clustering for better accuracy.
What's next for ShopWhere
- Integrate real-time data such as housing prices and rental availability via APIs.
- Build a user-facing dashboard or web app to allow businesses to input their criteria and get recommendations.
- Incorporate more sophisticated clustering or density-based methods (e.g., DBSCAN) for better ZIP code grouping.
- Include a scorecard system that ranks areas based on customizable business preferences.











Log in or sign up for Devpost to join the conversation.