-
-
Gemini_derict
-
Login_page
-
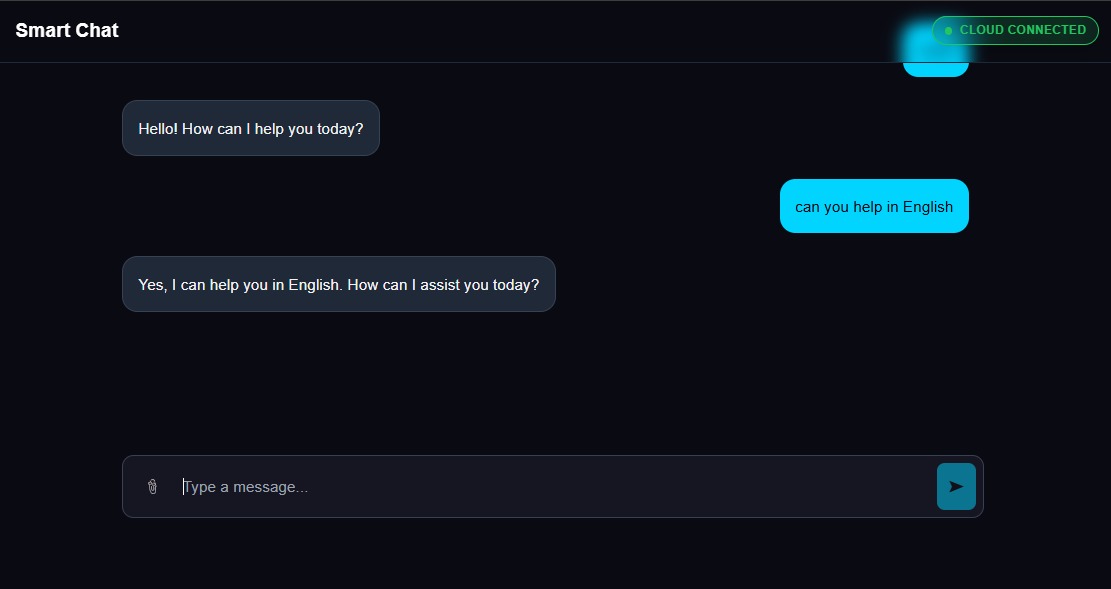
Chat_Box
-
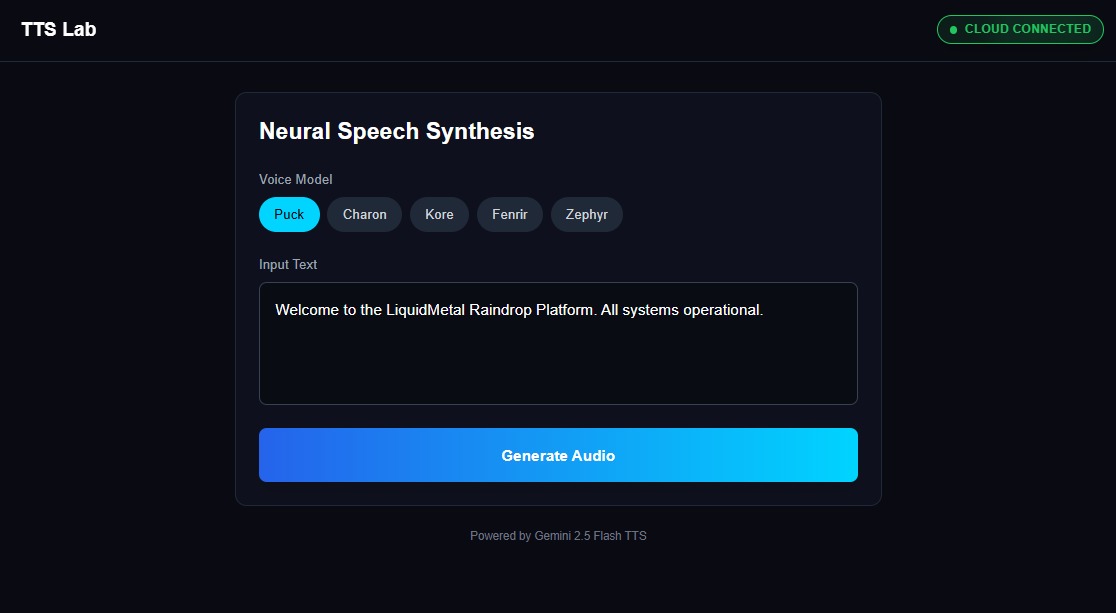
TTS_Lab
-
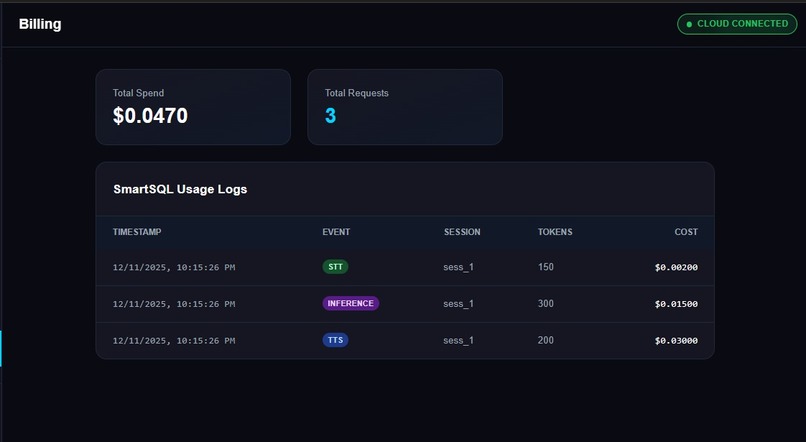
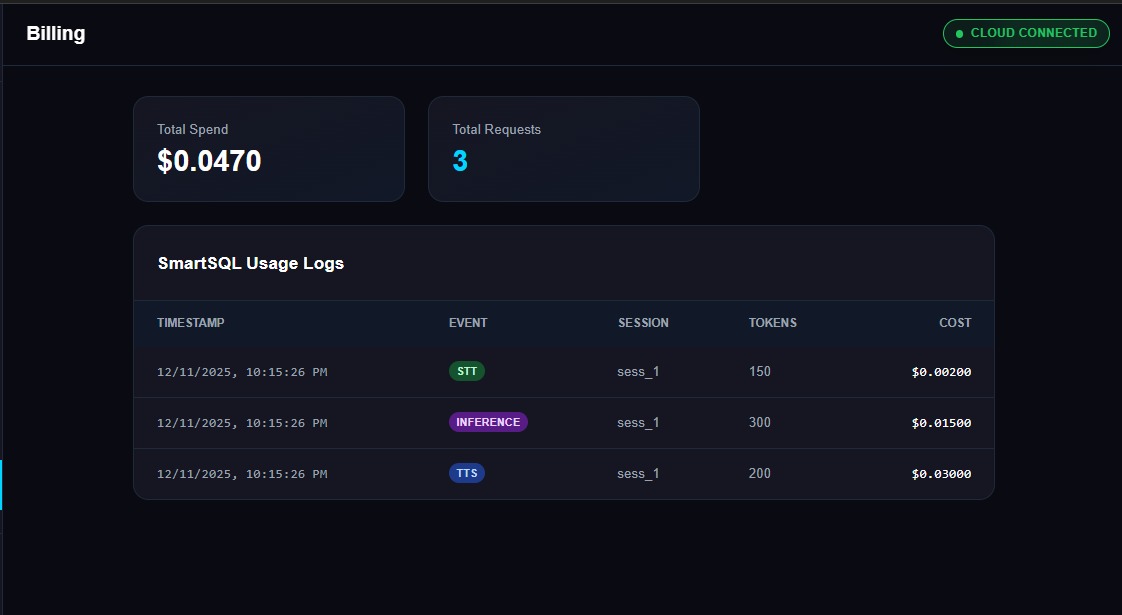
Billing
-
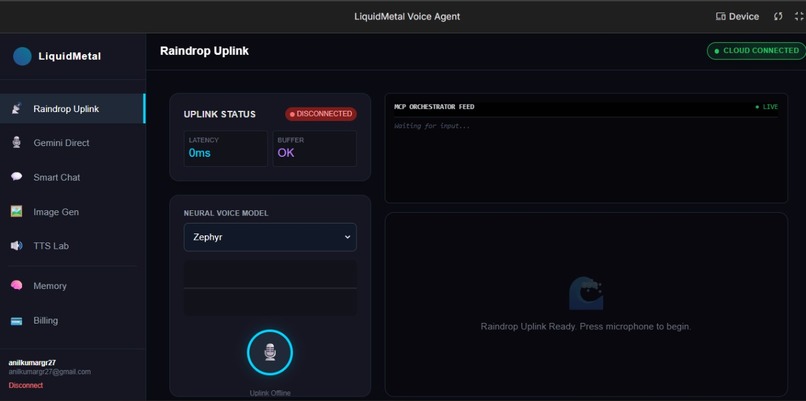
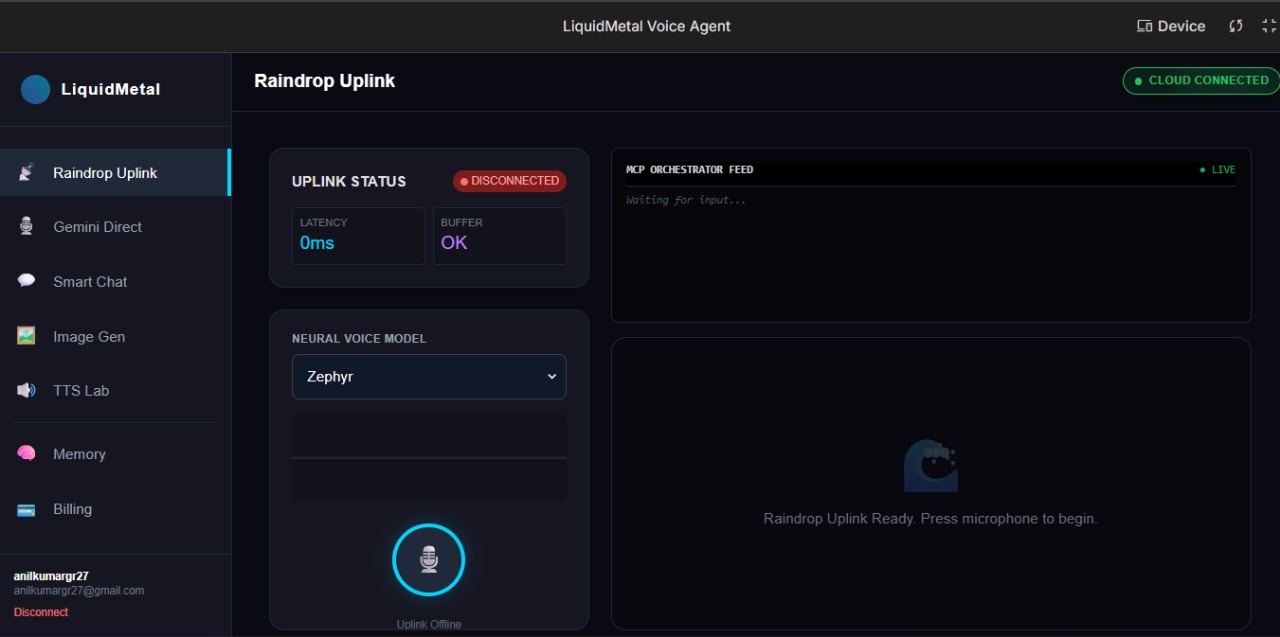
Rain_Drop
About the Project -LiquidMetal Voice Agent
Inspiration
Voice assistants today feel sluggish, forgetful, and shallow. I wanted to build something that behaves like real intelligent infrastructure, not a toy demo. The Raindrop Platform offered the perfect foundation to attempt a real-time, low-latency voice agent with persistent memory and reasoning.
The question that inspired the project was simple: Can a small hackathon project act like a production-grade voice intelligence system?
LiquidMetal Voice Agent is my answer.
What it does
LiquidMetal Voice Agent delivers real-time conversational intelligence, including:
- Streaming STT → reasoning → streaming TTS
- Persistent SmartMemory for long-term context
- Natural voice output powered by ElevenLabs
- Intent detection and NLU using Vultr inference
- Document-aware reasoning through SmartBuckets
- Fast, low-latency voice interaction that feels human
- Session tracking, usage logging, and production-ready backend behavior
At a high level, the processing pipeline looks like:
User Audio → STT → NLU → LLM Reasoning → TTS → Audio Stream User Audio→STT→NLU→LLM Reasoning→TTS→Audio Stream
It doesn’t just respond it remembers, reasons, and adapts in real time.
How we built it
The system is built using the core components of LiquidMetal’s Raindrop Platform:
- SmartInference for routing STT, NLU, reasoning, and TTS
- SmartMemory for both short-term and long-term context
- SmartBuckets for audio storage, transcripts, and embeddings
- SmartSQL for usage logs and analytics
- ElevenLabs for high-quality, low-latency speech synthesis
- Vultr inference for intent detection, entity extraction, and reranking
- A WebSocket-based client for real-time audio streaming
The system’s reasoning pipeline is expressed mathematically as:
**𝑓 ( 𝑥
)
TTS ( LLM ( NLU ( STT ( 𝑥 ) ) , Memory ) ) f(x)=TTS(LLM(NLU(STT(x)),Memory))**
Everything is modular, latency-optimized, and behaves like real AI infrastructure.
Challenges we ran into
1. Latency Management
Keeping the full round-trip voice loop fast required tuning:
- audio chunk sizes
- inference timing
- memory retrieval frequency
- TTS streaming cadence
2. Memory Coherence
Too much memory made the agent unfocused
- Too little made it dumb
- Embedding-based retrieval + SmartMemory summarization fixed this.
3. Asynchronous Orchestration
Integrating STT, NLU, reasoning, memory, and TTS — all running asynchronously — required careful pipeline engineering.
4. Production Constraints Under Hackathon Time
Authentication, retries, logging, and error handling were necessary to prevent a flaky system.
Accomplishments that we're proud of
- Achieving ultra-low latency voice interaction that feels natural.
- Implementing persistent conversational memory that meaningfully affects responses.
- Building a pipeline that behaves like real AI infrastructure, not a basic script.
- Successfully integrating Raindrop + ElevenLabs + Vultr into a unified, smooth workflow.
- Shipping something that is actually deployable, not just demo material.
What we learned
- How to design complete end-to-end voice pipelines under strict latency requirements.
- How Raindrop’s SmartComponents work together as an orchestration engine.
- How ElevenLabs’ streaming TTS behaves and how to optimize for low latency.
- How Vultr inference improves NLU accuracy, entity extraction, and reranking.
- How embedding-based memory improves coherence over naive context storage.
- Why thinking like a distributed systems engineer matters even in hackathons.
What’s next for LiquidMetal Voice Agent
- Adding agent-style planning and multi-step task execution.
- Expanding SmartMemory into multi-session, multi-user memory graphs.
- Integrating real-time function calling for external APIs.
- Adding structured analytics dashboards for conversation insights. -Building a standalone mobile app using WebRTC for even lower latency.
- Experimenting with voice cloning and personalized agent identities.
Built With
- audioapi
- github
- llm
- mcp
- node.js
- react
- smartbuckets
- smartinference
- smartmemory
- smartsql
- text-to-speech
- typescript
- vscode
- websockets





Log in or sign up for Devpost to join the conversation.