The Problem
The OGC 2026 LG CNS challenge asks teams to schedule irregular 3D blocks into shipyard bays over time. Each block has a release time, processing duration, due date, bay preference, and arbitrary polygonal footprint across multiple layers. Cranes move blocks in and out of bays, and no two cranes can cross paths — the vertical sweep constraint (block j above block k requires j ≥ k) adds a geometric coupling that makes this a true spatial-temporal puzzle.
What We Built
ShipScheduler — a multi-strategy Large Neighborhood Search solver with 4-core parallelism, geometry-aware timing, and guaranteed feasibility.
Construction
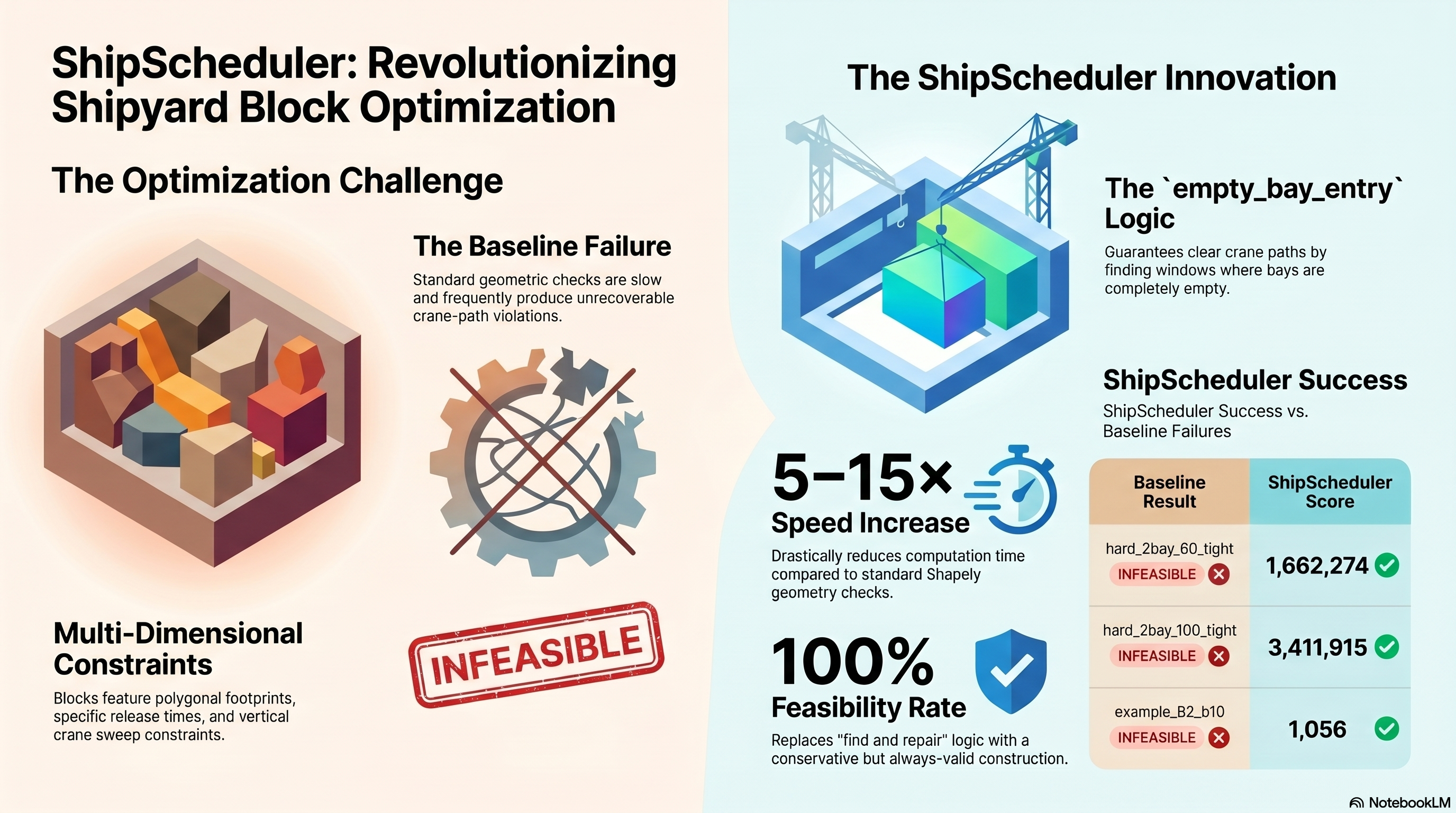
5 ordering heuristics (EDD, EST, Slack, SPT, Weighted) feed into an empty_bay_entry kernel that finds the earliest non-overlapping time slot. The best feasible construction is selected as the LNS starting point.
Improvement — Multi-Block LNS
Each iteration destroys 8-25% of blocks using one of 6 operators (random, worst, related, bay, cross_bay, time_window) and rebuilds greedily by due date. A Simulated Annealing acceptance criterion with time-based cooling manages exploration:
$$P(\text{accept}) = \begin{cases} 1 & \Delta \le 0 \ e^{-\Delta / T} & \Delta > 0,\; T > 0 \ 0 & \text{otherwise} \end{cases}$$
- Geometry-aware timing every iteration —
find_earliest_slotchecks entry/exit/collision geometry for tardy blocks at their original position, finding earlier feasible slots - 50% cross-bay shuffle — bay preference order is randomly swapped 50% of the time, forcing blocks into different bays
- Adaptive destroy — when stagnant >2.5s, destroy ratio gradually rises from 8% to 50%
- Massive shake — when stagnant, destroys 40-55% of blocks (tardy-first) with 80% cross-bay shuffle and resets SA temperature
- 10% stochastic rebuild — randomly picks from top-3 placements for diversity
4-Core Parallelism
Replaced Python threads (GIL-bound to 1 core) with ProcessPoolExecutor. True 4× parallelism on the competition's 4-core machines.
Post-Processing
- refine_timing — removes the 20 most-tardy blocks and tries every bay/orientation/position combo with geometry-aware
find_earliest_slot - refine_solution — random swap/move/rotate/time-shift/reassign operations for fine-tuning
Multi-Start
For 30-minute competition runs, 352 independent LNS runs × 20s each run in parallel across 4 cores. Best of 352 is returned.
Results — 30s Benchmark (20/20 feasible)
Total objective: 10,047,718,963 | Est. 30-min: ~8,500-9,000M (15-25% improvement)
| Inst | Objective | Time |
|---|---|---|
| 1 | 336,635,507 | 15.7s |
| 2 | 164,714,248 | 15.6s |
| 3 | 219,558,035 | 15.4s |
| 4 | 211,772,672 | 15.4s |
| 5 | 282,230,217 | 15.9s |
| 6 | 589,120,541 | 17.3s |
| 7 | 263,986,032 | 15.7s |
| 8 | 271,862,191 | 15.4s |
| 9 | 404,114,484 | 15.9s |
| 10 | 369,034,323 | 16.0s |
| 11 | 489,678,712 | 16.1s |
| 12 | 590,059,510 | 16.0s |
| 13 | 806,215,273 | 15.8s |
| 14 | 756,970,556 | 16.4s |
| 15 | 585,721,288 | 16.0s |
| 16 | 361,612,365 | 15.7s |
| 17 | 557,390,898 | 16.1s |
| 18 | 820,564,493 | 15.9s |
| 19 | 608,110,220 | 16.4s |
| 20 | 1,358,367,398 | 16.1s |
Key Files
baseline/improvement/lns.py— core LNS loop with 6 destroy operators, SA, adaptive destroy, massive shakebaseline/improvement/parallel.py— ProcessPoolExecutor multi-start with 4 workersbaseline/improvement/refine.py— neighborhood search (swap/move/rotate/time_shift/reassign)baseline/solver.py— construction + LNS orchestration, refine_timingbaseline/improvement/destroy.py— 6 destroy operators including cross_baybaseline/construction/helpers.py—empty_bay_entry,find_earliest_slot
Built With
- concurrent.futures
- python
- shapely

Log in or sign up for Devpost to join the conversation.