-
-
 GIF
GIF
Video Demo: Watch ShiftSync's serverless pipeline intake, parse, and use AI to map messy CSVs seamlessly in real-time
-
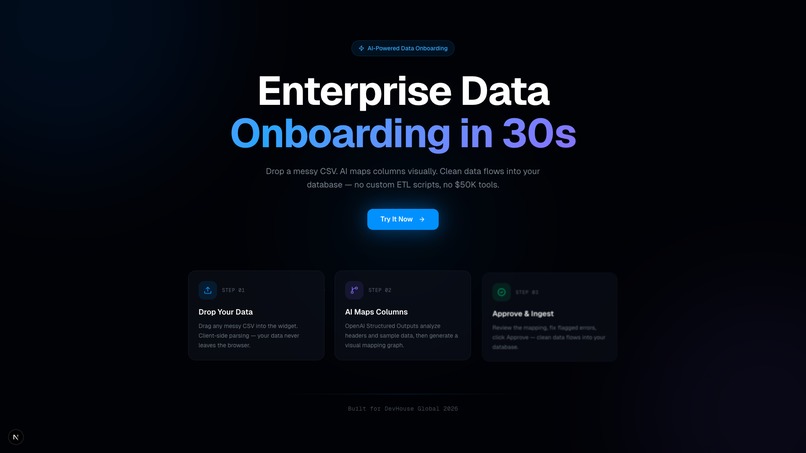
ShiftSync revolutionizes enterprise data onboarding, cutting the schema-mapping process down to under 30 seconds
-
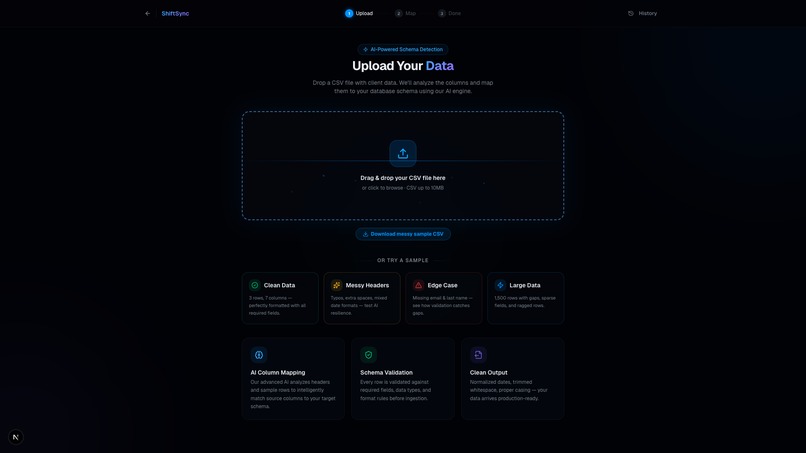
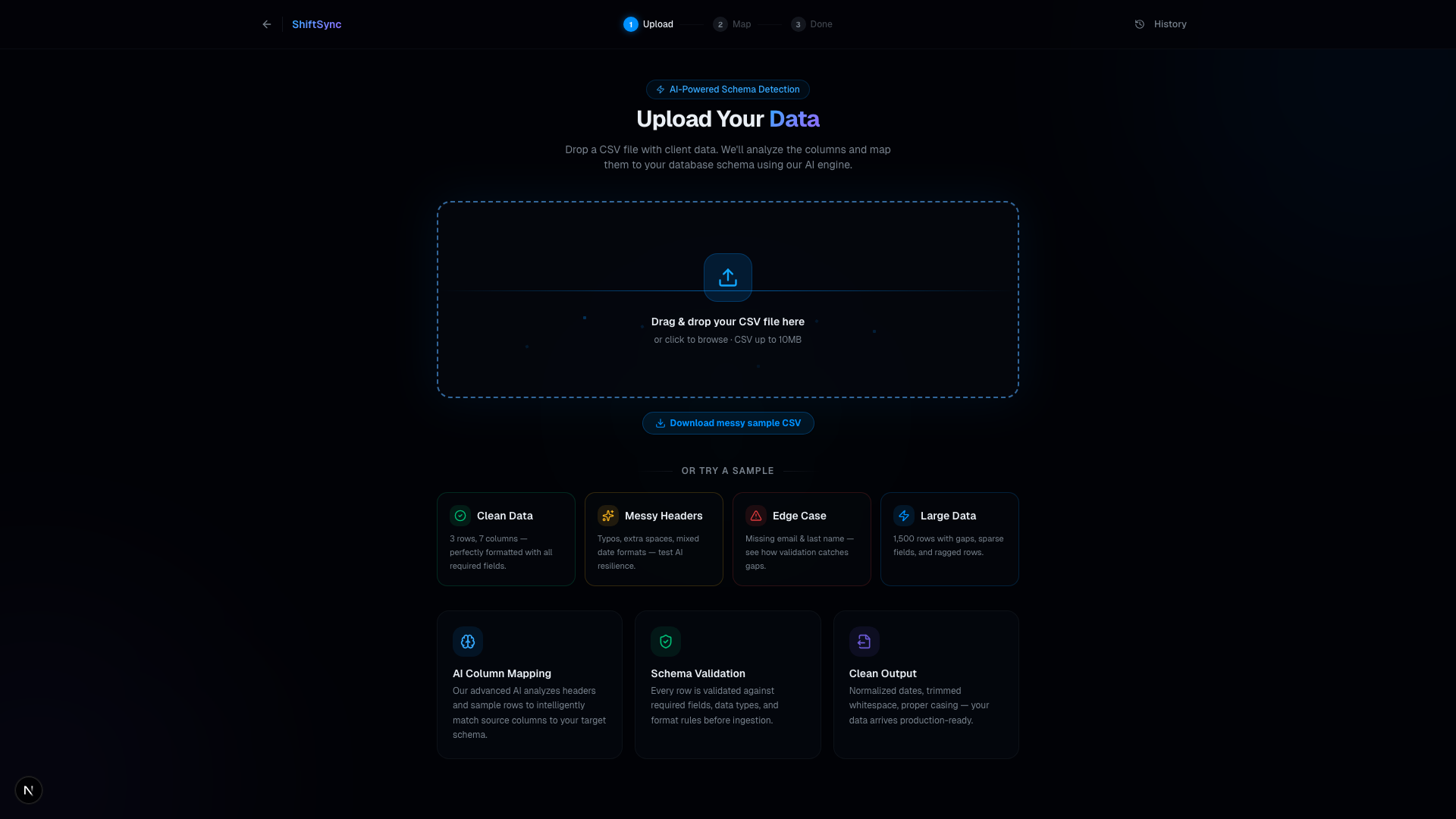
Upload UI: Effortlessly drag and drop messy CSV files with lightning-fast, secure client-side parsing
-
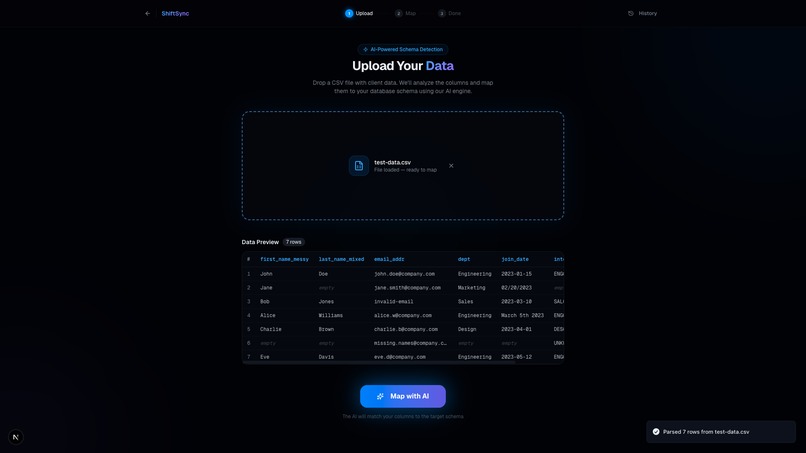
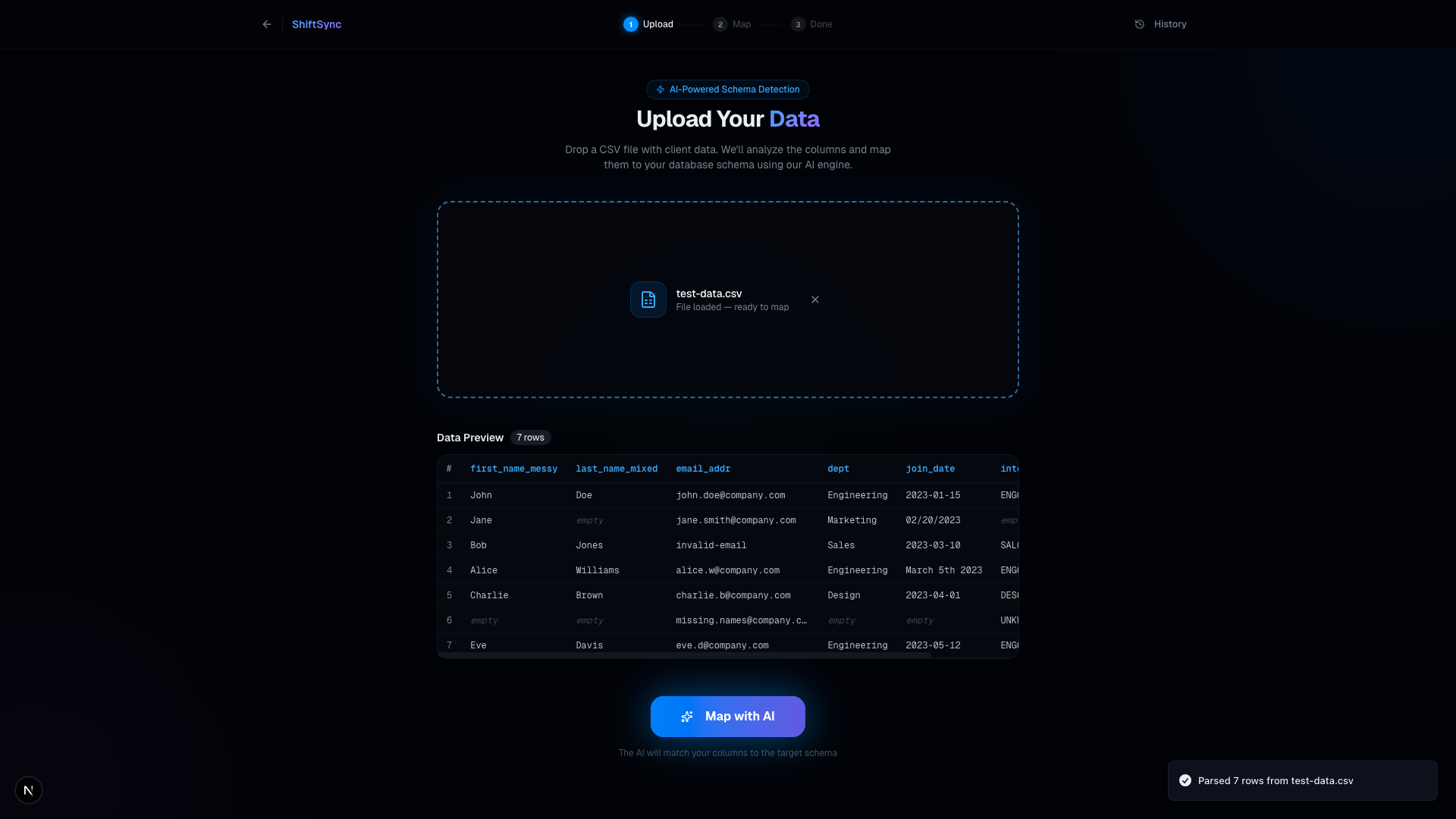
Data Preview: Instantly preview and visually validate your unstructured data before the AI gets to work
-
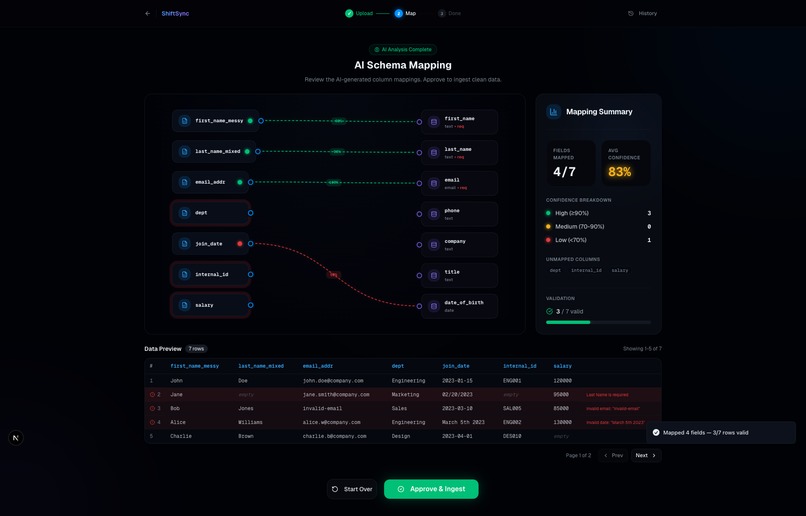
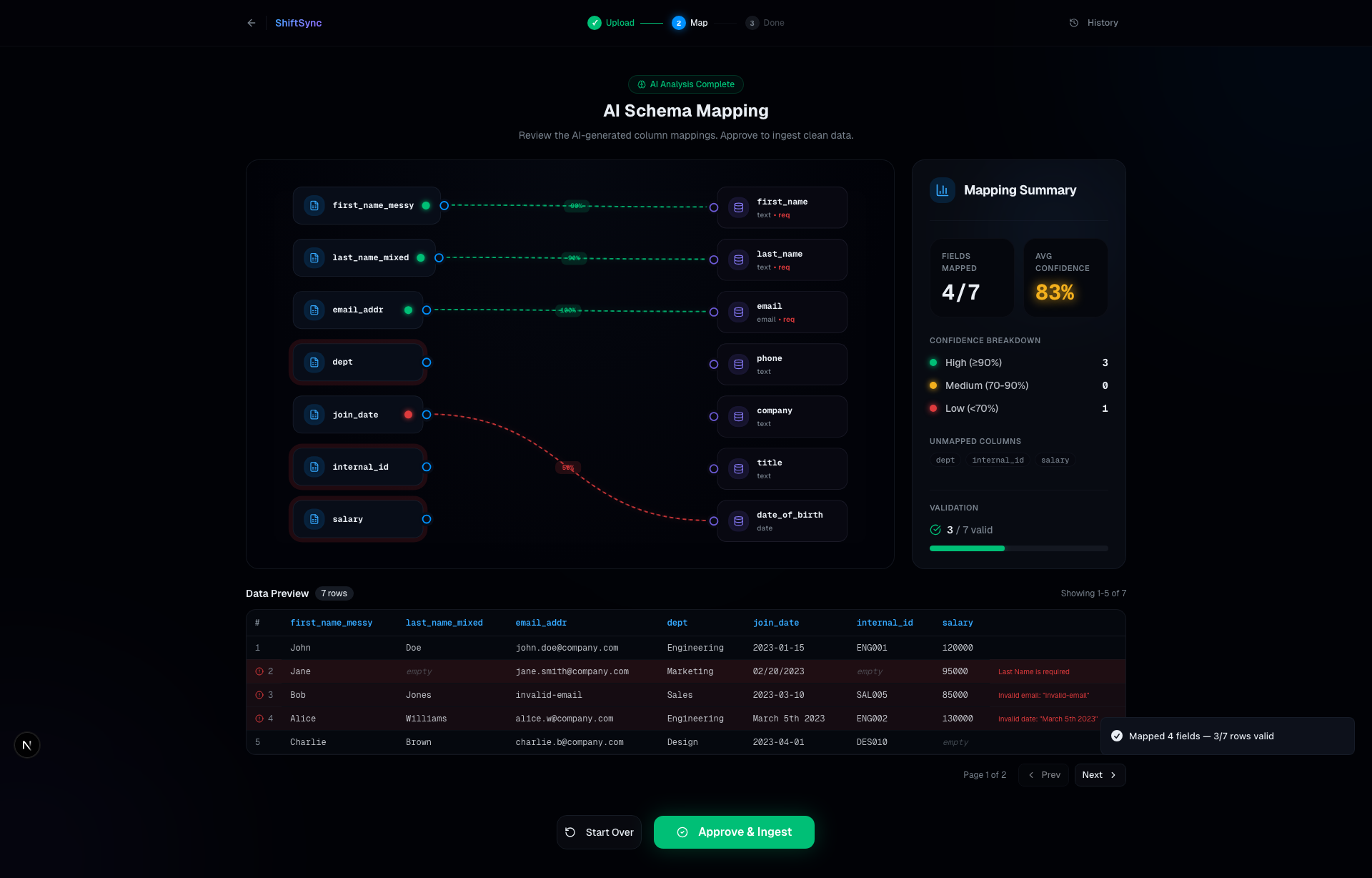
AI Mapping Graph: Interactive React Flow canvas where GPT-4o automatically maps disorganized headers to your strict target schema
-
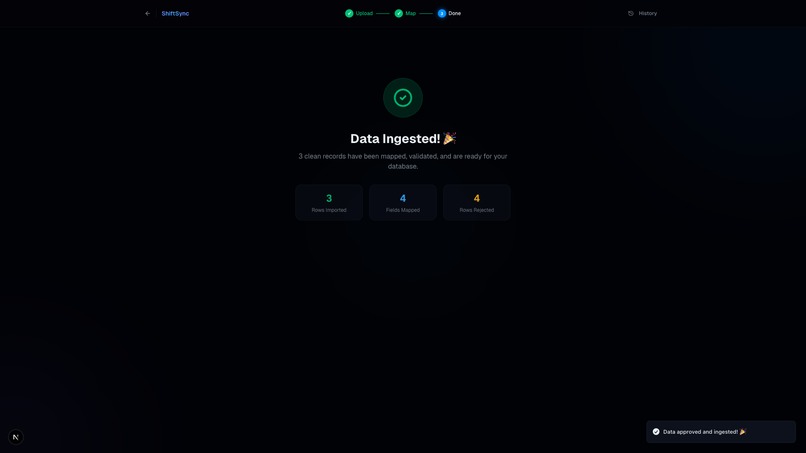
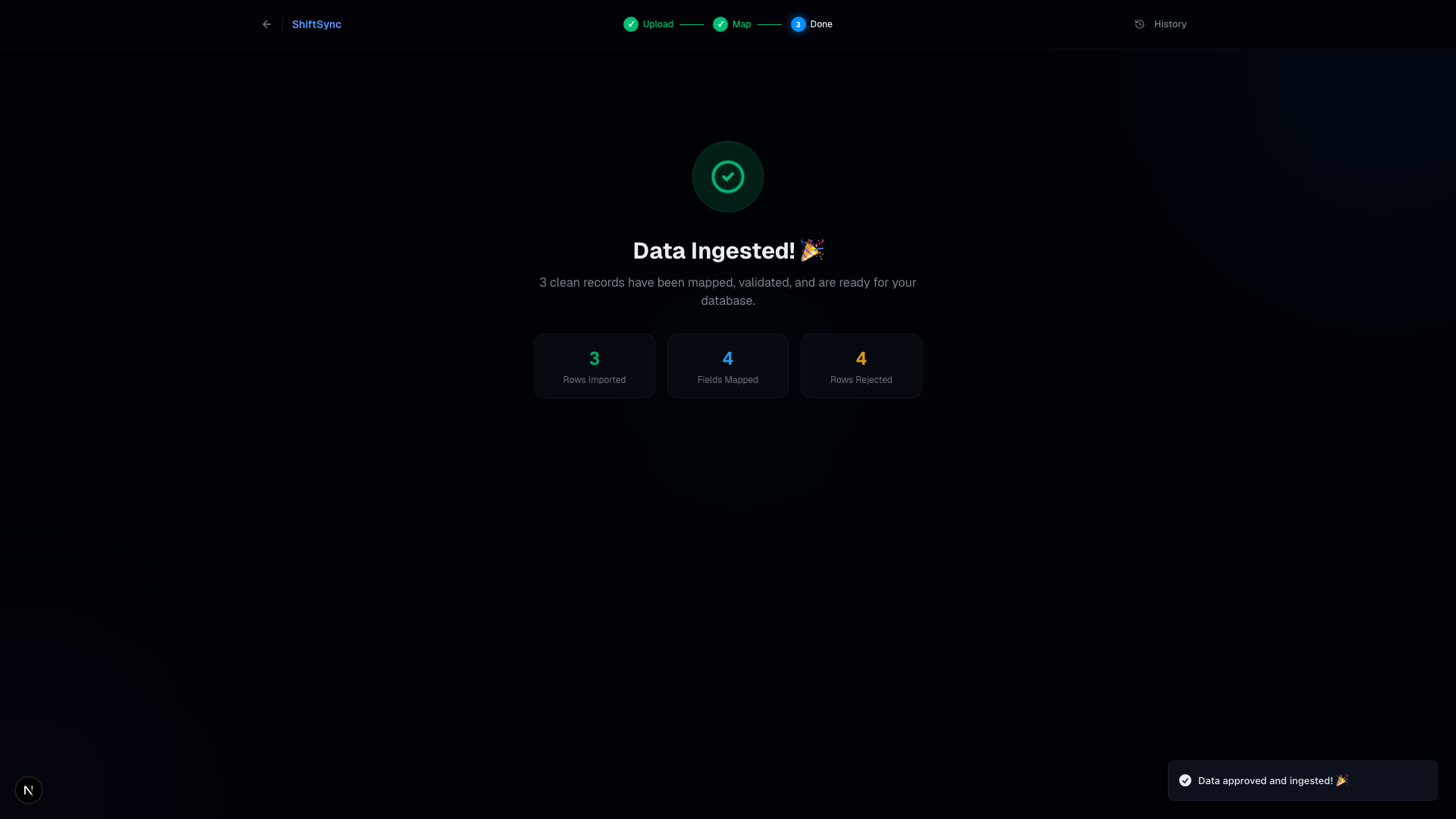
Success Screen: Sync Complete! Your harmonized, strictly-mapped data is ready for instantaneous database insertion


Inspiration
Data ingestion is notoriously difficult. Every client, vendor, and department sends data in different formats, with different headers, and mixed data types. Developers spend hours writing fragile parsing scripts for every new data source. We wanted to automate this tedious process by combining lightning-fast drag-and-drop file parsing, an interactive node-based UX, and the intelligence of Large Language Models to handle schema mapping instantly.
What it does
ShiftSync allows anyone to drag and drop a messy CSV file, parses the data instantly inside their browser, and then uses OpenAI (GPT-4o) to automatically map the disorganized CSV headers to a strict target database schema. Any ambiguous or unmapped columns are sent to an interactive mapping graph built with React Flow, allowing developers to visually debug and manually re-map columns before ingestion. It includes robust row validation to discard corrupt data effortlessly.
How we built it
- Framework: Next.js 15 (App Router)
- Styling & UI: Tailwind CSS (v4), Framer Motion, and custom glassmorphism components
- AI Integration: OpenAI API (
gpt-4o-2024-08-06) leveraging Structured Outputs (Zod) for deterministic mapping - Graph Visualization: React Flow
- Parsing & Validation: PapaParse (client-side chunked parsing) and Zod (schema validation)
Challenges we ran into
- Building a responsive node-graph where visual elements adapt perfectly alongside fluid flexbox layouts.
- Structuring LLM prompts to consistently return deterministic schema mappings instead of conversational text.
- Managing client-side parsing without blocking the main event thread, ensuring the glowing animations remain buttery smooth.
Accomplishments that we're proud of
- The seamless, highly aesthetic "glassmorphism" UI which integrates incredibly complex React Flow nodes into a seamless user experience.
- Moving the burden of schema matching from manual regex and scripting to instantaneous AI matching.
- Achieving a completely serverless architecture that doesn't store sensitive PII user data anywhere during the mapping process.
What we learned
- How to efficiently chunk and parse large datasets entirely on the client, minimizing memory bottlenecks.
- How to constrain LLMs strictly using Zod schemas to ensure AI output matches an expected code structure perfectly.
- Deepened our knowledge of building interactive node-based canvases with React Flow while keeping performance high.
What's next for ShiftSync
- Supporting custom target schemas input by users (e.g., uploading a
schema.prismafile directly). - Real-time data transformation nodes (e.g., a node that splits full names into first/last name).
- Connectors to push mapping pipelines directly to Postgres, Snowflake, or Supabase.
Built With
- framer-motion
- gpt-4o
- next.js
- openai-api
- papaparse
- react
- react-flow
- tailwind-css
- zod

Log in or sign up for Devpost to join the conversation.