-
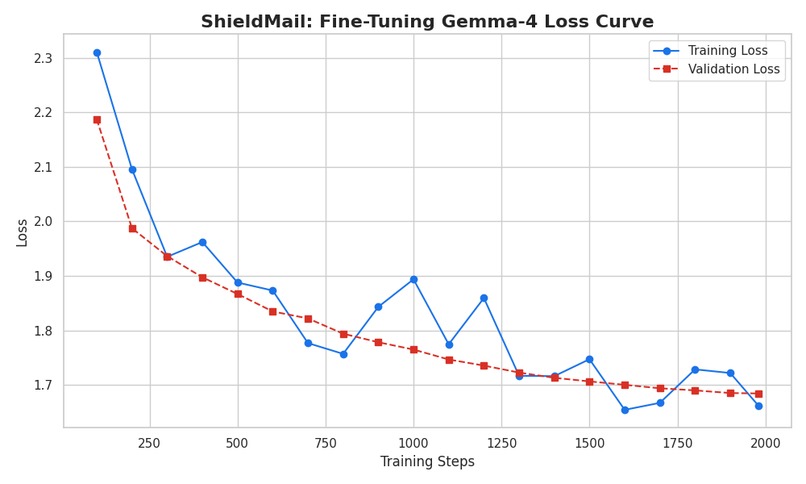
Gemma 4 e4b Training and Validation Loss Curves on Phishing/Scam Dataset
-
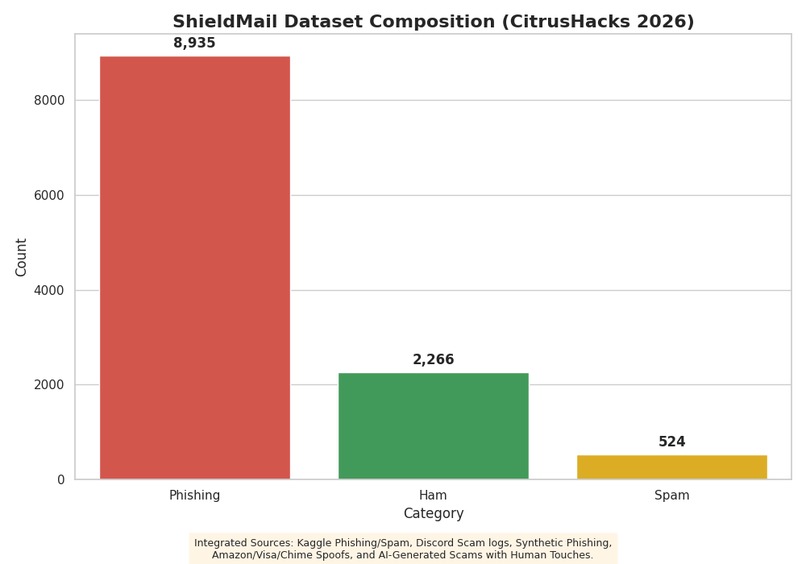
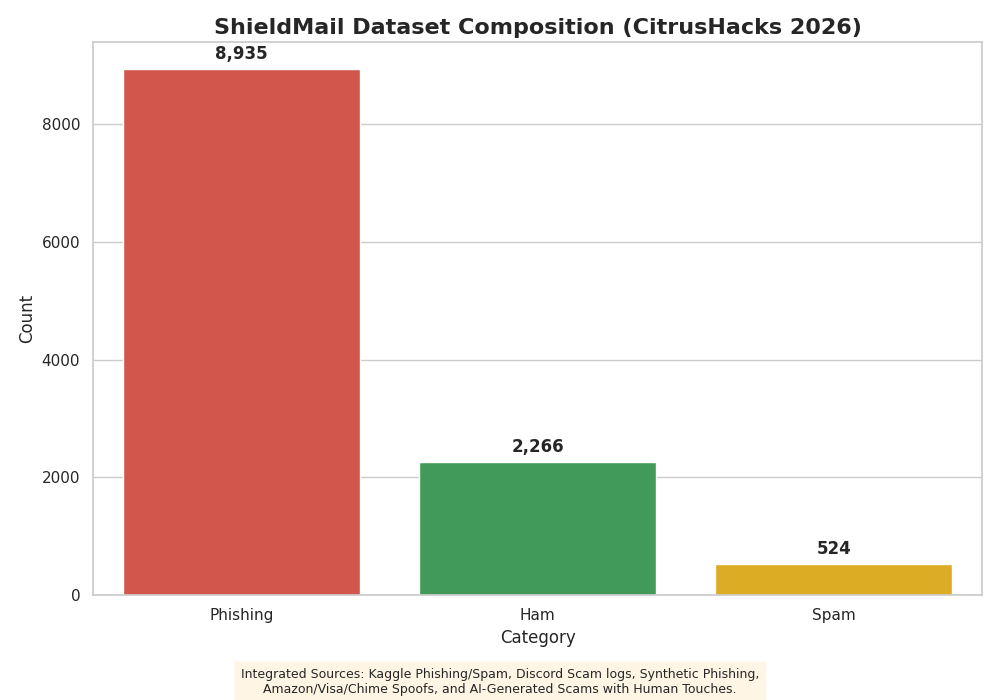
Gemma 4 e4b Spam vs Phishing vs Legit (Ham) Dataset Fine Tuning Distribution
-
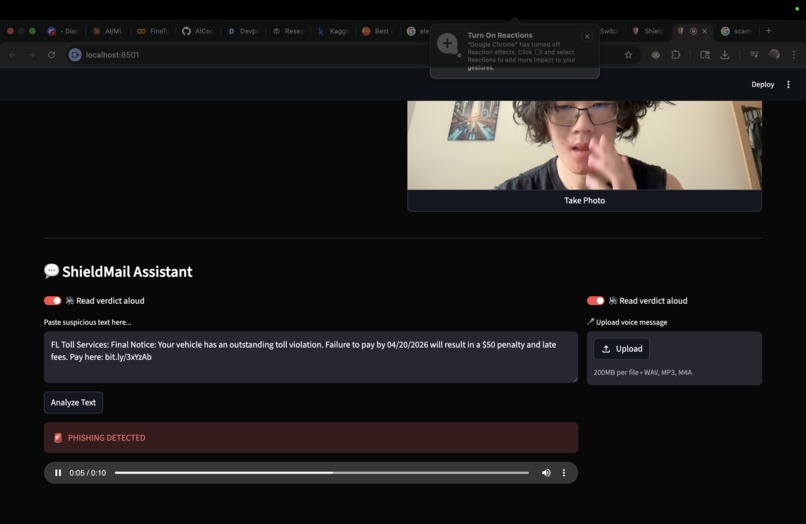
Inspiration
Scammers now use LLMs to write flawless phishing emails and clone voices indistinguishable from real people. Existing spam filters are static rule systems. I wanted to fight AI-generated scams with a fine-tuned model that actually understands manipulation tactics — not just keyword matching.
What it does
ShieldMail detects phishing, spam, and synthetic voice impersonation across three modalities:
- Gmail — scans your inbox in real time, classifies each email with a fine-tuned local model
- Camera/screenshots — snap any suspicious content, Gemini multimodal vision classifies it with a CV2 gradient overlay
- Voice — uploads audio through a two-layer detector: SynthID watermark check via Gemini + Wav2Vec2 acoustic artifact detection
- ElevenLabs: Voices Over its Phishing To Help Prevent the User from Falling for the Scam
How we built it
Fine-tuned Gemma 4 E4B via LoRA (r=16, alpha=32) on a custom 11,700-sample corpus: real phishing from the 250k Spam/Ham/Phish dataset, Discord phishing messages, and synthetic AI-generated scams across 8 categories ((Amazon delivery, Visa/financial, Chime/CashApp/Apple Pay, IRS/government, crypto/Coinbase, romance scams, CEO fraud/executive impersonation, and human-refined AI phishing) generated specifically to represent 2026-era LLM phishing patterns. Trained on Colab H100 with Unsloth, exported to Q4_K_M GGUF, served locally via Ollama. Gmail API handles inbox scanning. Gemini 3 Flash handles visual multimodal classification. Voice layer combines Gemini SynthID detection with Hemgg/Deepfake-audio-detection for acoustic artifact analysis. Streamlit ties everything together in a single-file dashboard.
Challenges we ran into
GGUF export corrupted mid-transfer from Google Drive — solved by exporting to local Colab disk first before copying. Dataset had natural class imbalance so weighted heavily toward phishing examples (~8k phishing vs ~2.7k ham) to optimize recall over precision for a detector use case. Building multimodal pipeline solo in under 24 hours while also doing dataset construction, fine-tuning, and frontend.
Accomplishments that we're proud of
The fine-tuned model runs entirely on a MacBook with no cloud inference — every email classification stays on device. The voice layer correctly identified a Google TTS sample as synthetic via SynthID. The Gmail live demo catches real phishing emails from my actual inbox.
What we learned
LoRA fine-tuning on domain-specific data meaningfully outperforms prompting a general model for classification tasks. Dataset quality matters more than size — the synthetic 2026-era phishing examples improved performance on modern AI-written scams that older datasets miss entirely.
What's next for ShieldMail
Real-time voice call interception. C2PA provenance verification for media. Expansion to iMessage and WhatsApp surfaces. iPhone Overlay

Log in or sign up for Devpost to join the conversation.