-
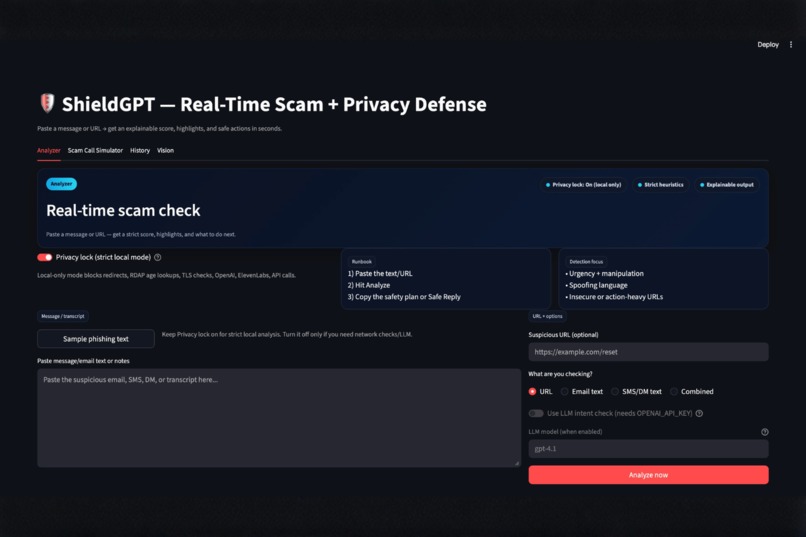
User Interface at start
-
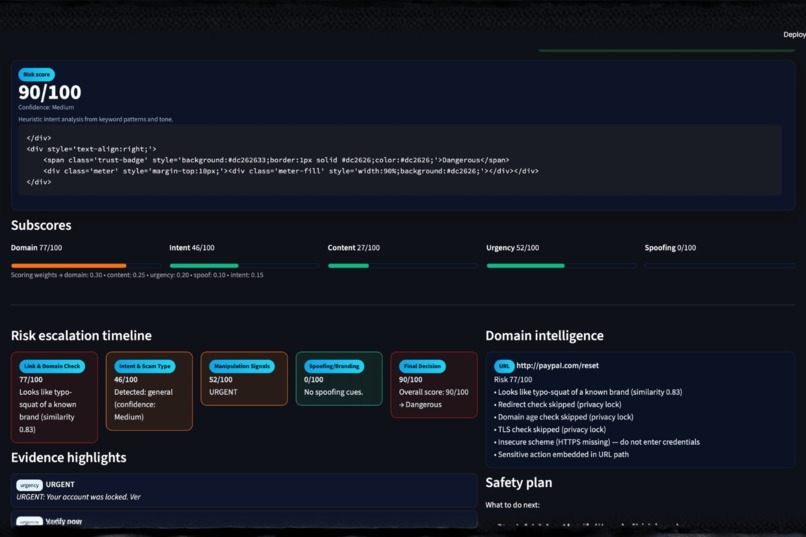
Scoring at action
-
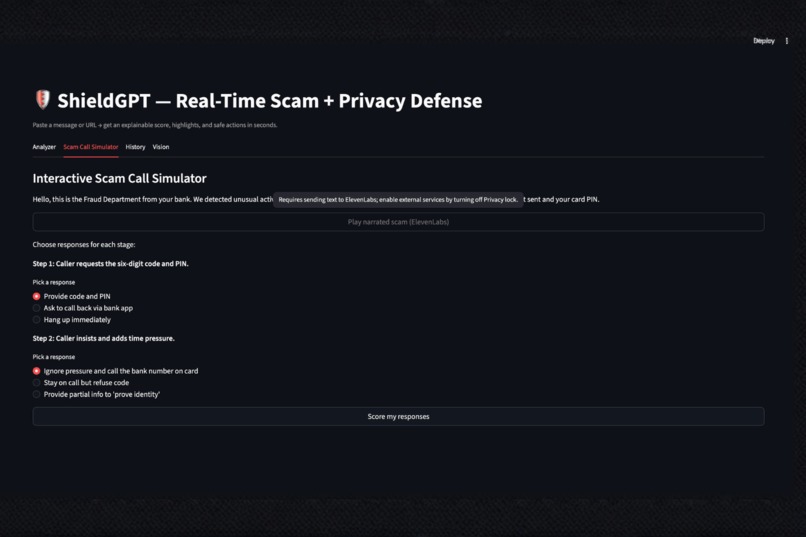
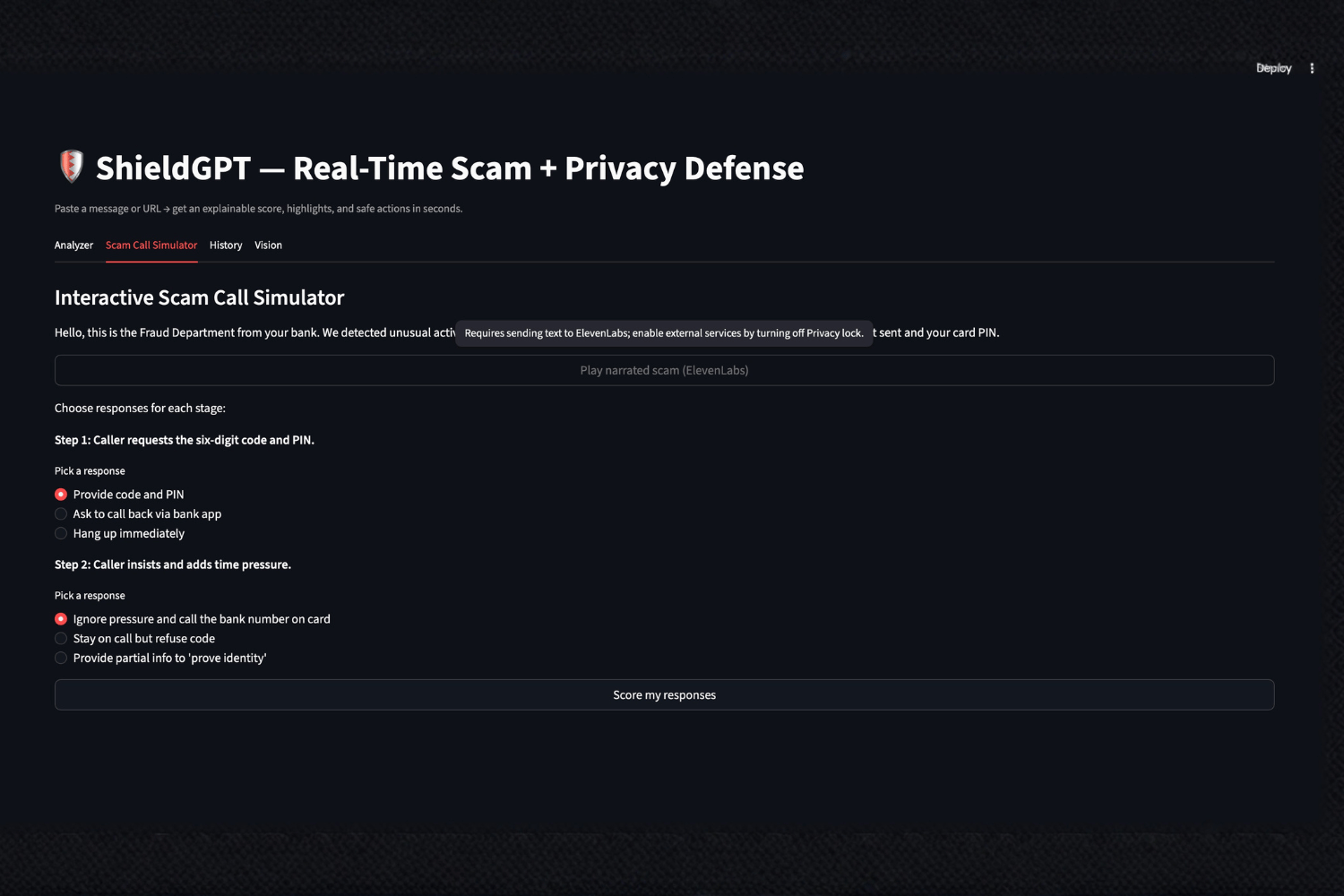
Scam Call Simulator
Inspiration
Scams today don’t look like scams. They rely on urgency, authority, and psychological pressure rather than obvious red flags. Most tools either block content without explanation or rely on black-box AI decisions.
I wanted to build a system that helps users understand why something is risky, not just be warned about it.
What it does
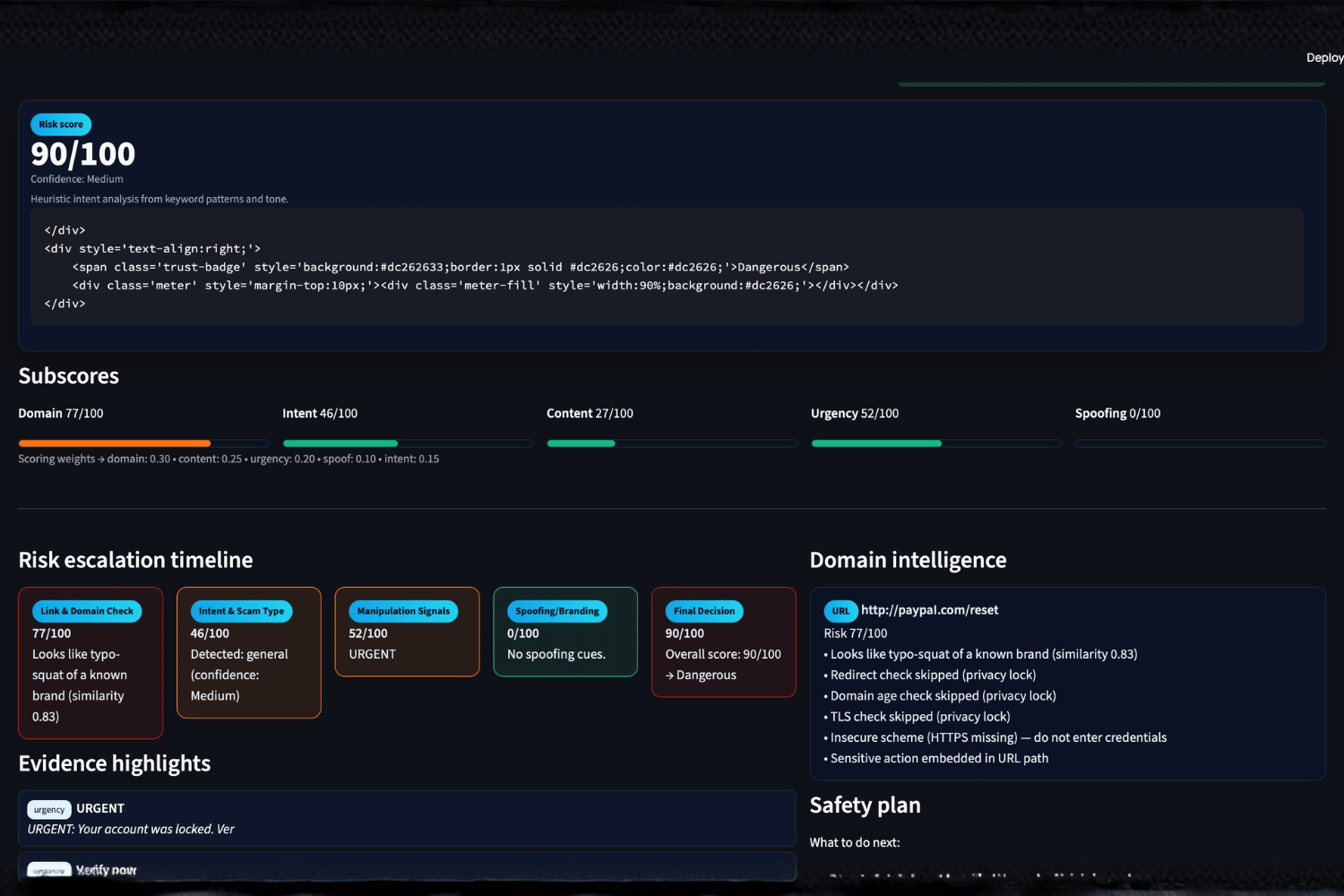
ShieldGPT is an explainable, privacy-first AI system that analyzes links and messages for phishing and social-engineering risk.
Instead of a single opaque verdict, it:
- Generates a 0–100 risk score with transparent subscores
- Highlights the exact phrases and signals that triggered risk
- Shows a visual timeline of how risk accumulates
- Provides a Safety Plan and safe reply templates
- Includes a Scam Call Simulator to train users under pressure
The goal is education and prevention, not just detection.
How it’s built
ShieldGPT uses a hybrid approach:
- A deterministic rule engine for domain intelligence and manipulation patterns
- An optional LLM layer for intent analysis and explanation
- A weighted risk aggregator to avoid black-box scoring
- A Streamlit frontend and FastAPI backend for clarity and structure
Privacy & ethics
ShieldGPT is local-first by default. With Privacy Lock enabled, all analysis runs locally and no user data is sent externally unless explicitly enabled.
This design prioritizes transparency, user control, and trust.
Challenges & learnings
Balancing accuracy, explainability, and privacy was the biggest challenge. This project reinforced that responsible AI isn’t just about performance—it’s about clarity, trust, and empowering users to make informed decisions.

Log in or sign up for Devpost to join the conversation.