-
Home page
-
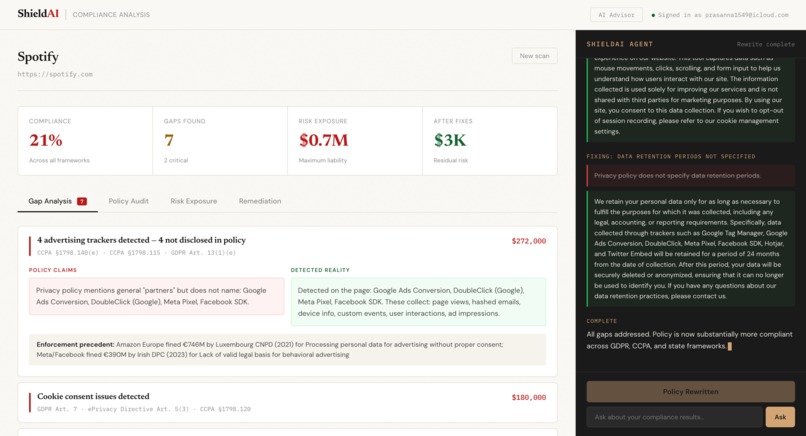
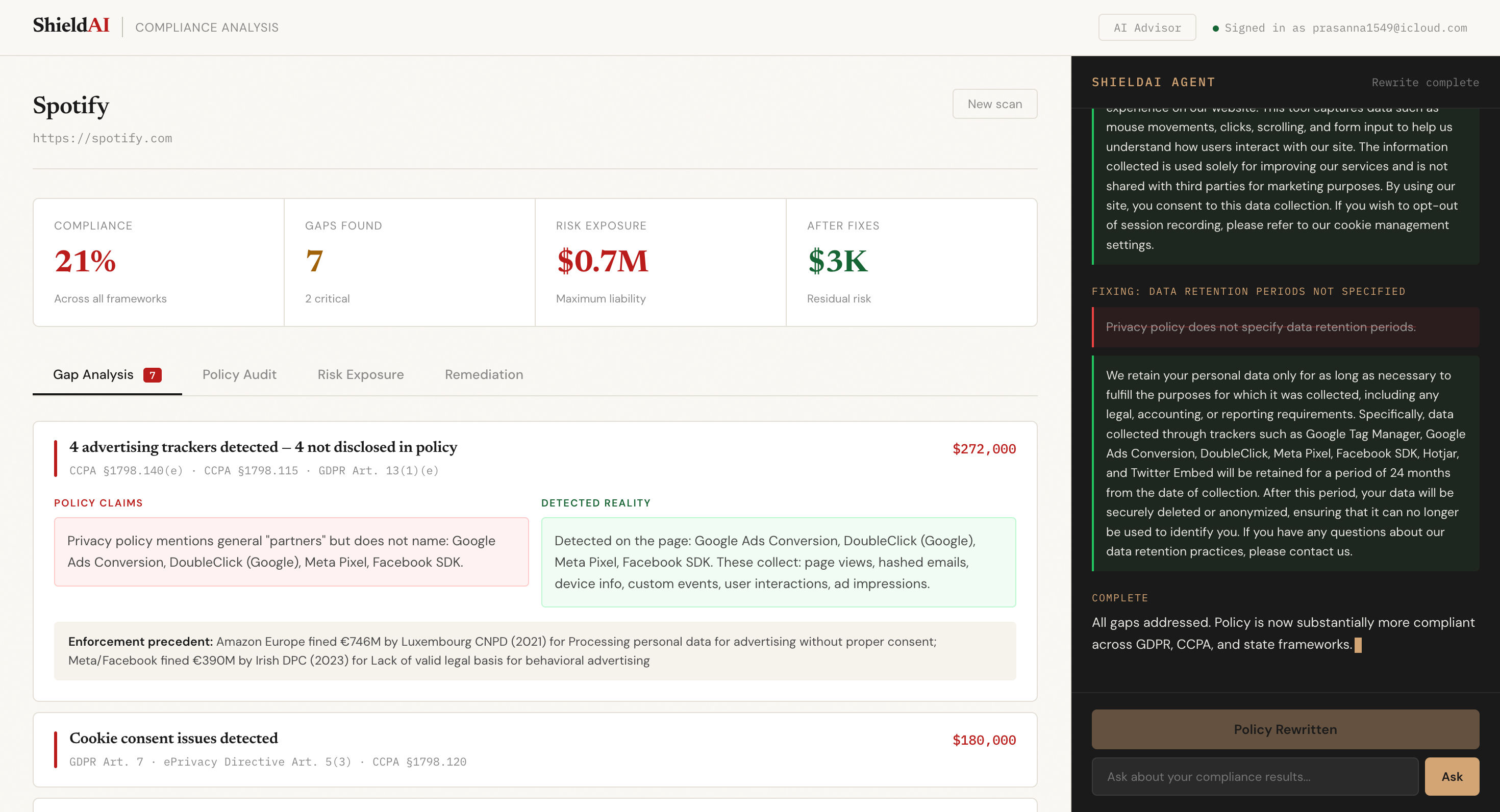
Privacy policy analysis, and rewritten policy using AI agent
-
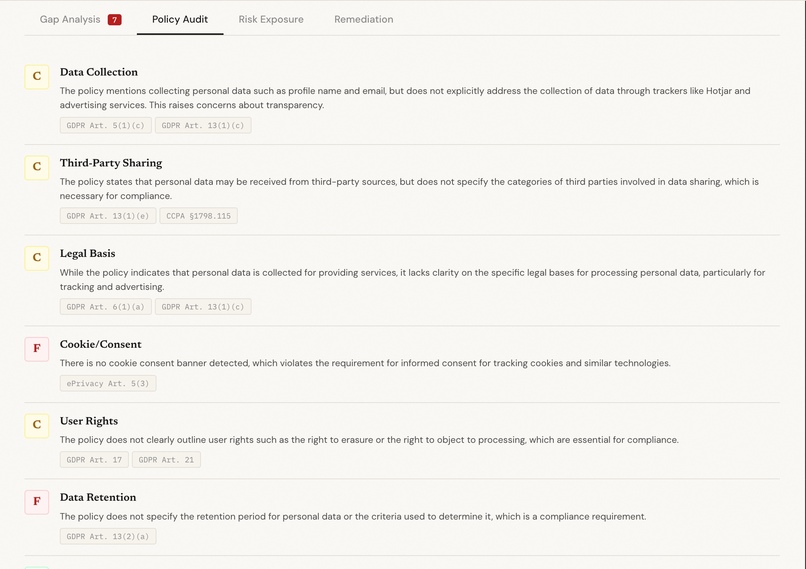
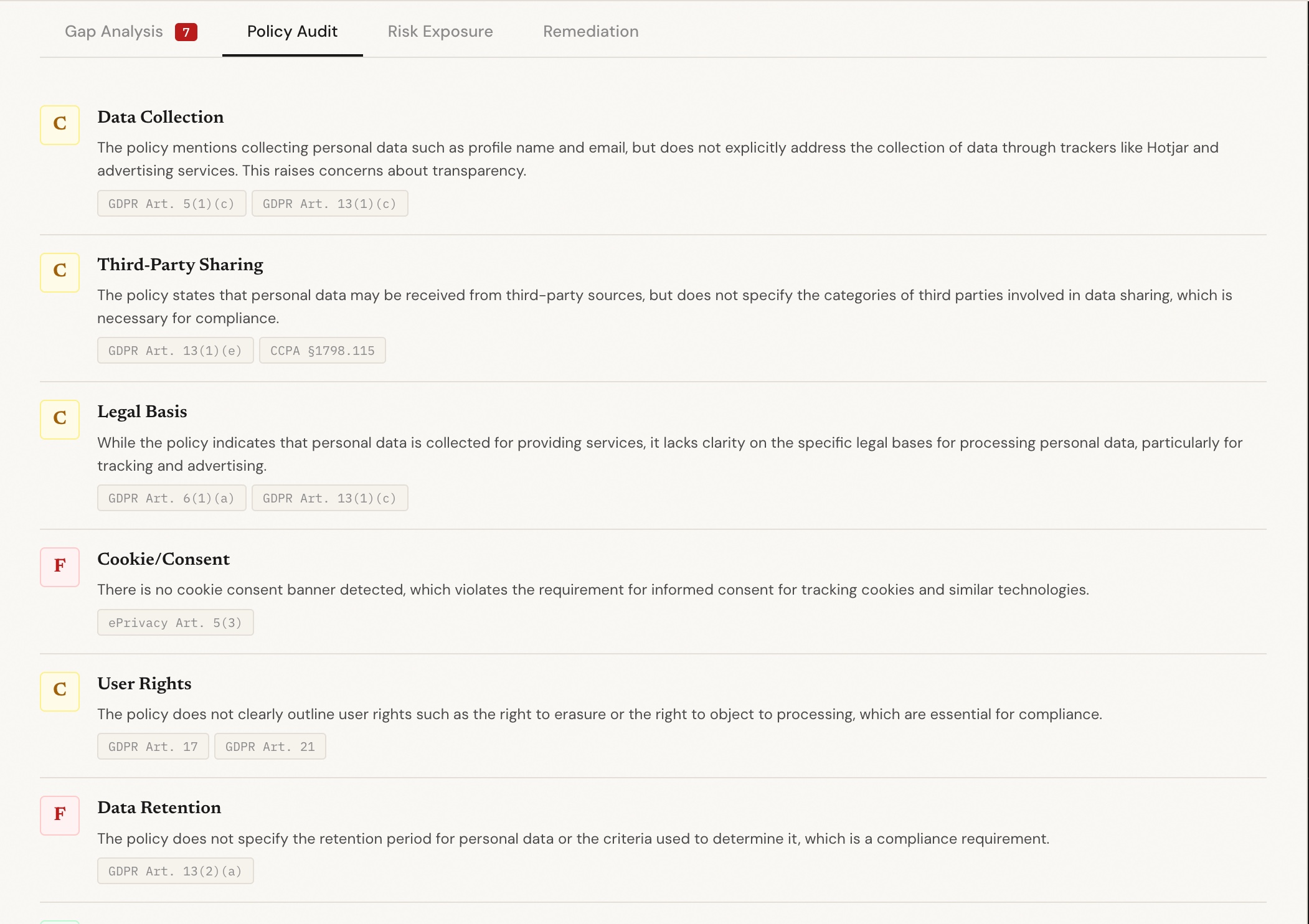
Policy Audit tab
-
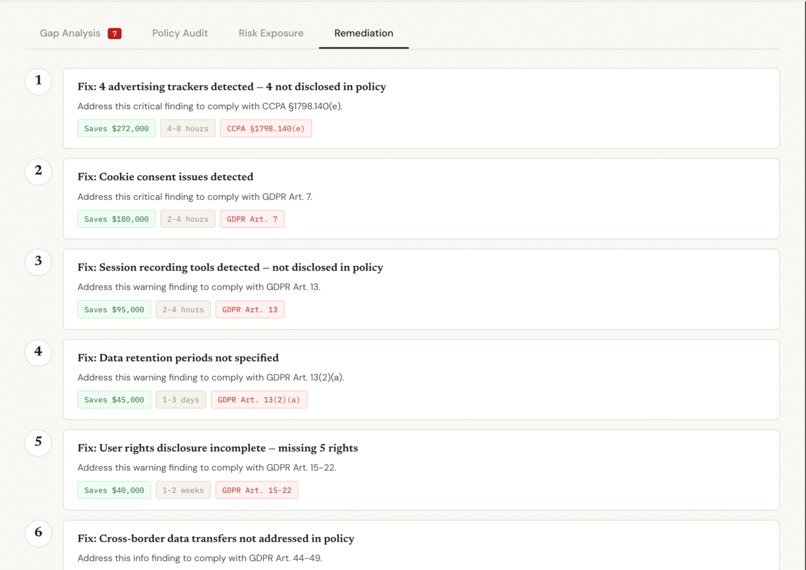
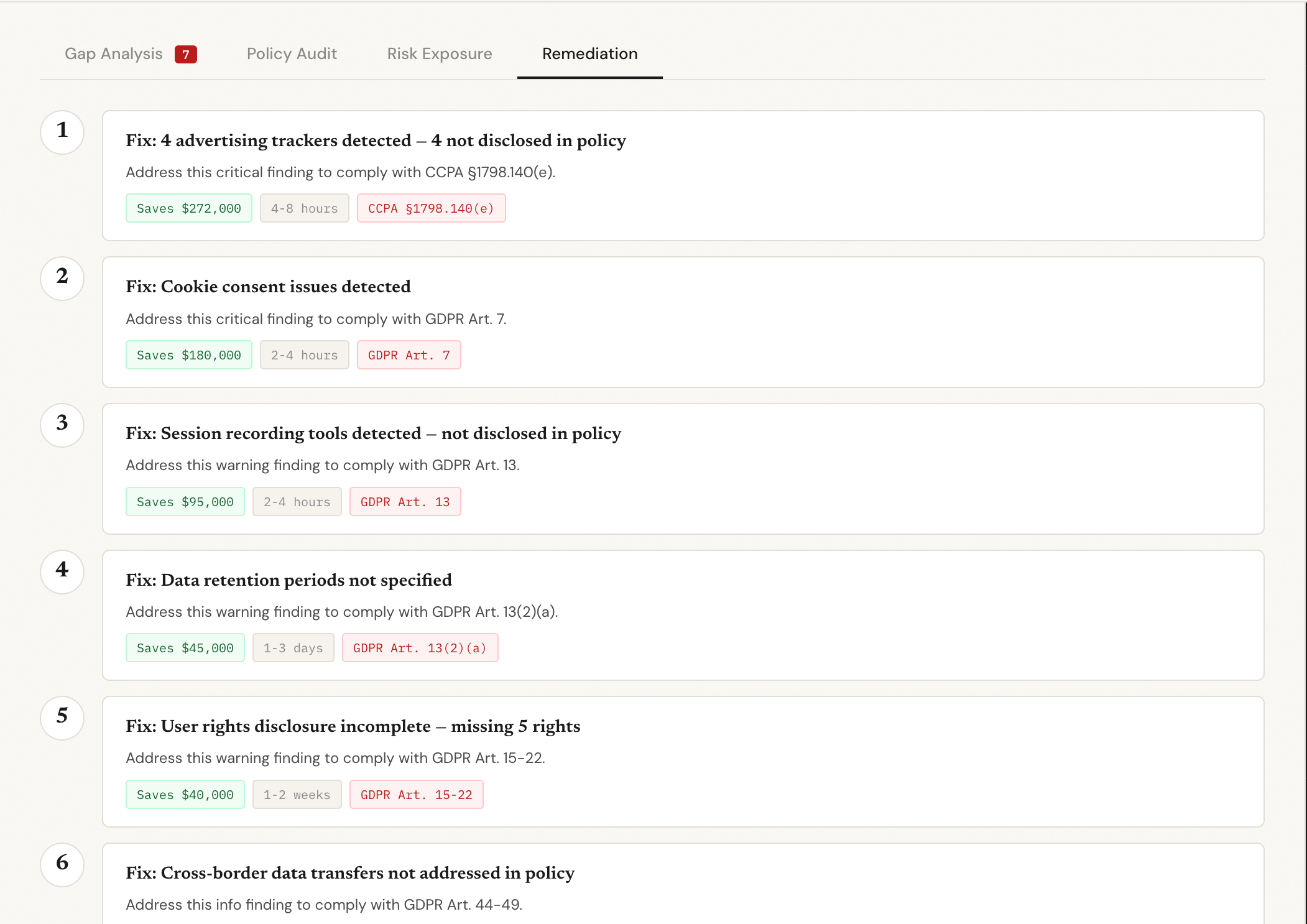
Remediation tab
-
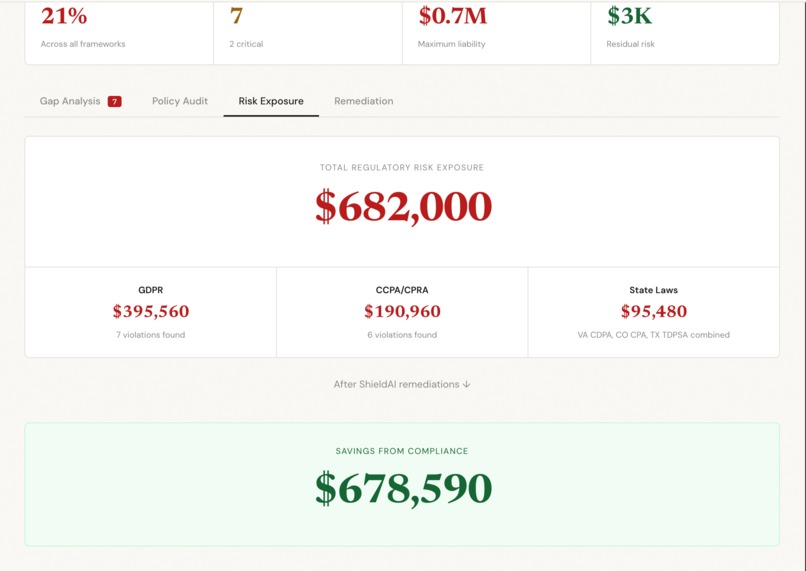
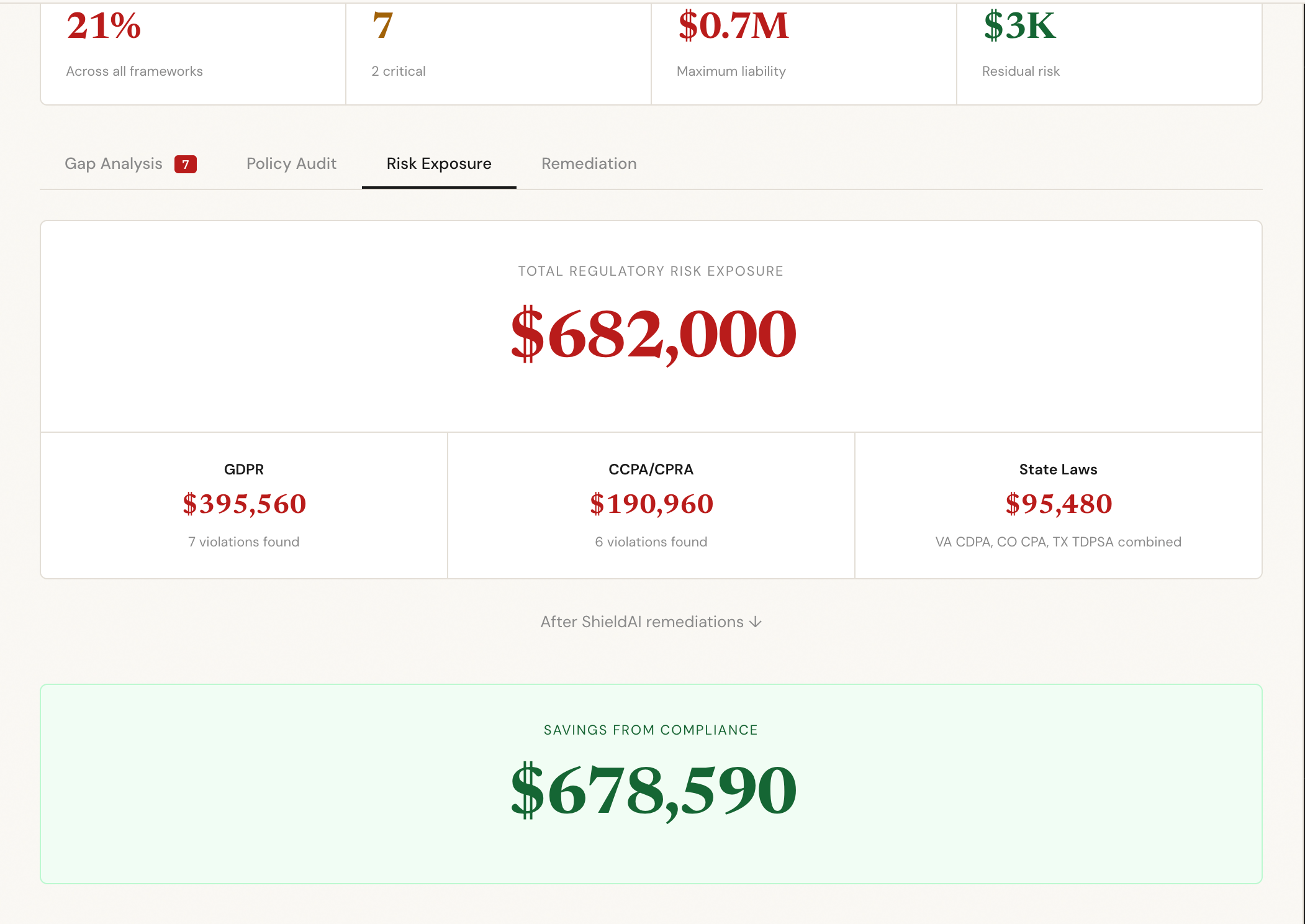
Risk exposure estimation tab
ShieldAI: Closing the Gap Between Privacy Policies and Reality
Inspiration
As part of privacy compliance research at Clemson University, we spent time studying how organizations actually handle personal data versus what their legal documents claim. One pattern kept coming up: the fines weren't happening because companies were malicious — they happened because legal wrote a policy, engineering shipped trackers, and nobody ever checked if they matched.
The scale of this problem is real:
- Meta: $1.3 billion GDPR fine (2023)
- Amazon: $887 million GDPR fine (2021)
- TikTok: €345 million for children's privacy violations (2023)
Under GDPR, maximum fine exposure scales with revenue:
$$E_{GDPR} = \min\left(0.04 \times R_{annual},\ \sum_{i=1}^{n} F_i\right)$$
Under CCPA, fines are uncapped per violation:
$$E_{CCPA} = \sum_{i=1}^{n} f_i \cdot v_i, \quad f_i \in {\$2{,}500,\ \$7{,}500}$$
Our research made one thing clear — this is a solvable problem. The data already exists in the page source, the policy text, and the network requests. We built the tool that connects them.
What it does
ShieldAI crawls any website, detects every third-party tracker and cookie, finds the privacy policy, and cross-references what the site actually does against what the policy claims. It surfaces compliance gaps with specific regulatory citations, real enforcement precedents, and calculated fine exposure. It then rewrites the non-compliant clauses using AI and lets you chat with a compliance advisor about the results.
How we built it
Backend: Python + FastAPI, fully async. The crawler uses httpx and BeautifulSoup with four-layer tracker detection — HTML content, script src attributes, inline JavaScript function calls (fbq(, gtag(, ttq.), and tracking pixels. It also crawls login and signup pages separately since trackers often only appear there.
The gap analyzer runs entirely deterministically before any AI is involved:
$$\text{Gap}_i = \mathbb{1}\left[\text{detected}_i = 1\right] \cap \mathbb{1}\left[\text{disclosed}_i = 0\right]$$
A gap only exists if we detected the behavior AND the policy doesn't disclose it. No false positives, every finding is defensible.
GPT-4o-mini then receives the detected evidence and actual policy text, grades each section, explains each gap, and generates replacement clauses — constrained to only cite regulations from a verified list so it can't hallucinate legal references.
Auth: Auth0. Frontend: Vanilla HTML/CSS/JS.
Challenges we ran into
API keys. Our first OpenAI key had exhausted its quota. We swapped to Gemini, which turned out to have a free-tier limit of zero requests. We spent time debugging what we thought was a code problem — it was a billing problem. Eventually got a funded key and got it working.
Merge conflicts. Multiple people pushing to the same repo under time pressure, especially as we cycled through AI providers and everyone was touching ai_rewriter.py. We solved it by designating one person as integration lead who owned all merges, while everyone else worked on isolated files.
Scraping privacy policies. Many are JavaScript-rendered, behind auth, or redirect to homepages. We built a two-pass approach: scan the page for privacy links first, then brute-force 20+ common paths (/privacy, /privacy-policy, /legal/privacy, etc.) and verify the content actually contains policy-related text before accepting it.
Accomplishments that we're proud of
The gap analyzer never flags a violation without evidence on both sides. That constraint — built from our research background — is what makes the output trustworthy rather than just alarming. When ShieldAI says something is a violation, it can show exactly what it detected and exactly what the policy says (or doesn't say).
We also got a live, fully functional tool working end-to-end: crawl a real website, detect real trackers, pull real policy text, run real AI analysis, return real results. No mocked data anywhere in the demo.
What we learned
During a firechat at the hackathon, we spoke with the CEO of ThreatCaptain, who told us the core idea has genuine startup potential — that the gap between what privacy policies say and what products actually do is a real, unsolved problem at scale, and that with the right direction and go-to-market, this could become a real company.
That conversation reframed how we think about what we built. The problem is large, enforcement is accelerating, and the existing tools either cost too much, require too much manual work, or don't go deep enough technically.
What's next for ShieldAI
Weeks 1–4: Database backend, scan history, user dashboards.
Weeks 5–8: Continuous monitoring — scheduled scans with alerts when behavior changes (new tracker added, policy updated).
Weeks 9–12: Legal workflow integrations. Compliance reports formatted for regulatory submissions.
Weeks 13–16: Enterprise tier — bulk scanning for law firms, API access for developers building compliance into CI/CD pipelines.
There are 33 million businesses subject to CCPA in the US. GDPR covers 500 million EU residents. Privacy enforcement actions have increased 168% since 2021. The fines are real, they're growing, and the tools to prevent them haven't kept up.
Built With
Python · FastAPI · OpenAI GPT-4o-mini · BeautifulSoup · httpx · Auth0 · HTML/CSS/JS
Built With
- auth0
- beautifulsoup4
- css
- fastapi
- gpt-4o-mini
- html
- httpx
- javascript
- openai
- pmpython
- python-dotenv
- uvicorn


Log in or sign up for Devpost to join the conversation.