



🐻 Sherlock Combs 🍯
✨ Inspiration
Massive investigative document dumps — court filings, legal records, leaked archives — are incredibly hard to explore manually. We wanted to build something that helps journalists, researchers, and curious investigators quickly answer questions like:
- Who keeps showing up across documents?
- When did certain connections first appear?
- What evidence actually supports these relationships?
Inspired by powerful link-analysis tools (think Palantir-style investigation boards), we created a lightweight, evidence-first version that’s accessible, transparent, and built for discovery.
🚀 What It Does
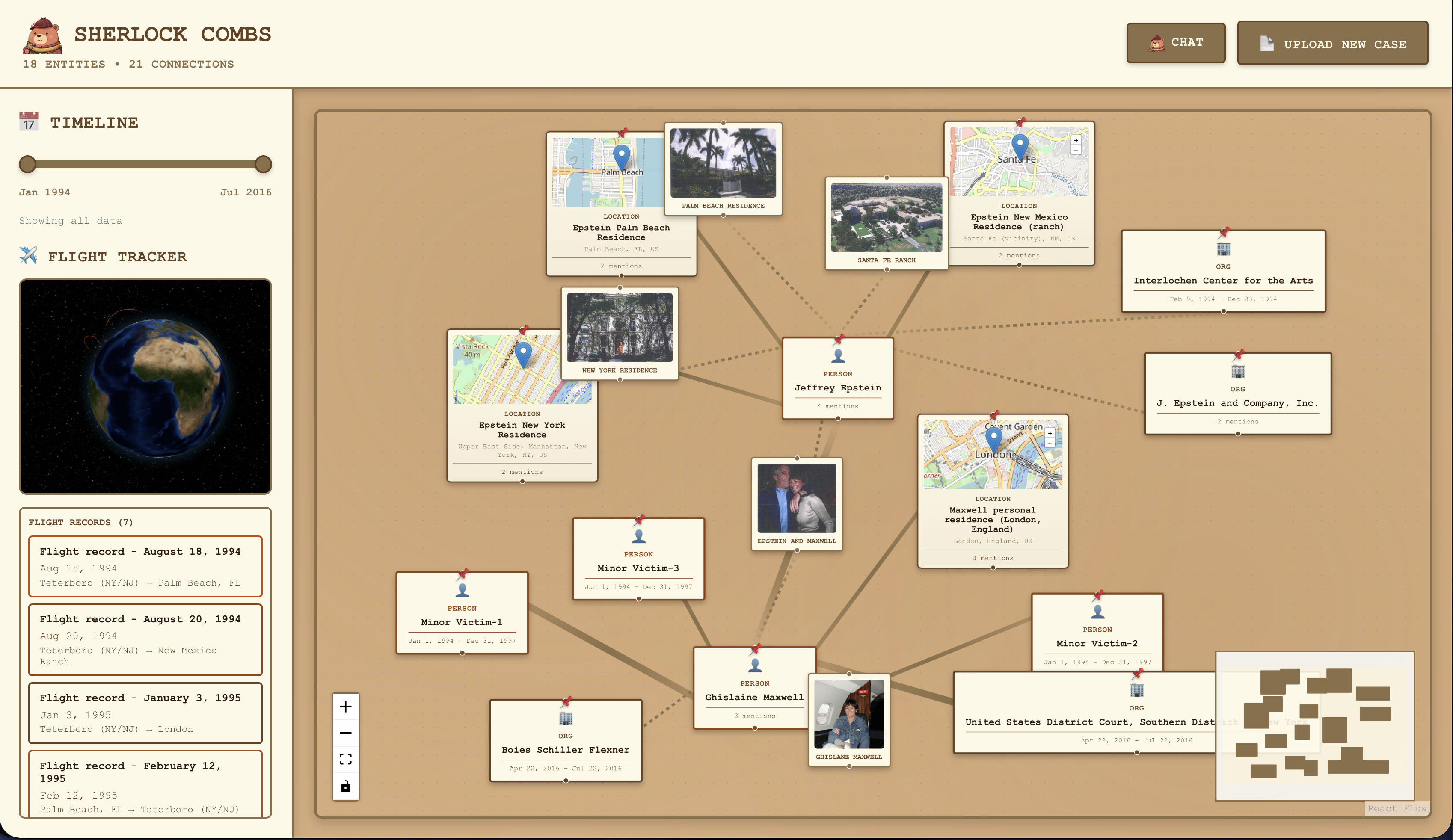
Sherlock Combs transforms messy, unstructured document collections into an interactive, timeline-driven detective board.
Upload a set of PDFs, and it automatically:
- Extracts people, organizations, locations, and dates
- Builds an evolving relationship graph backed by real evidence
- Lets you scrub through time to watch connections form and change
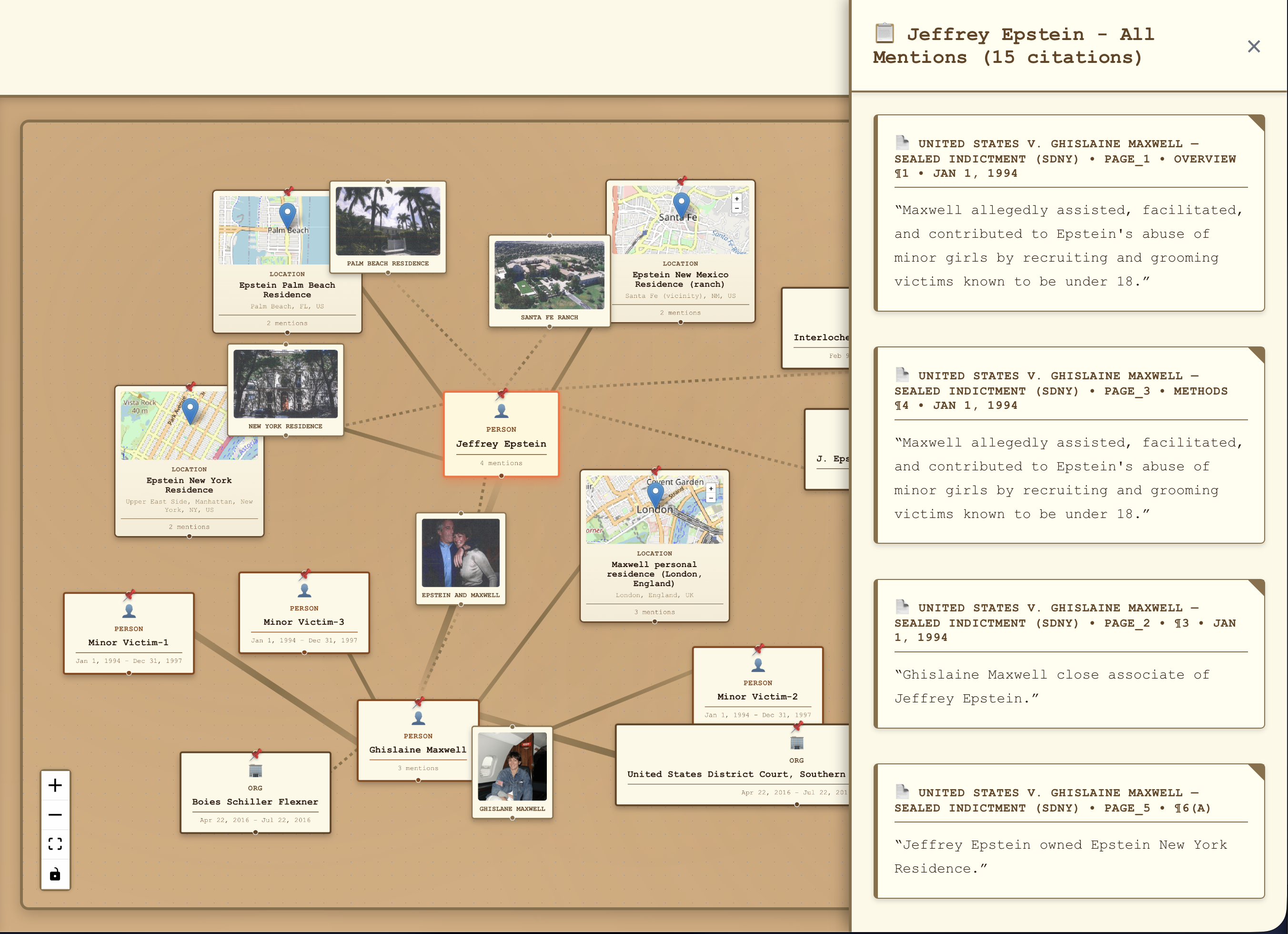
- Shows the exact source snippet behind every single link
No black-box accusations — just grounded, traceable document intelligence.
🛠️ How We Built It
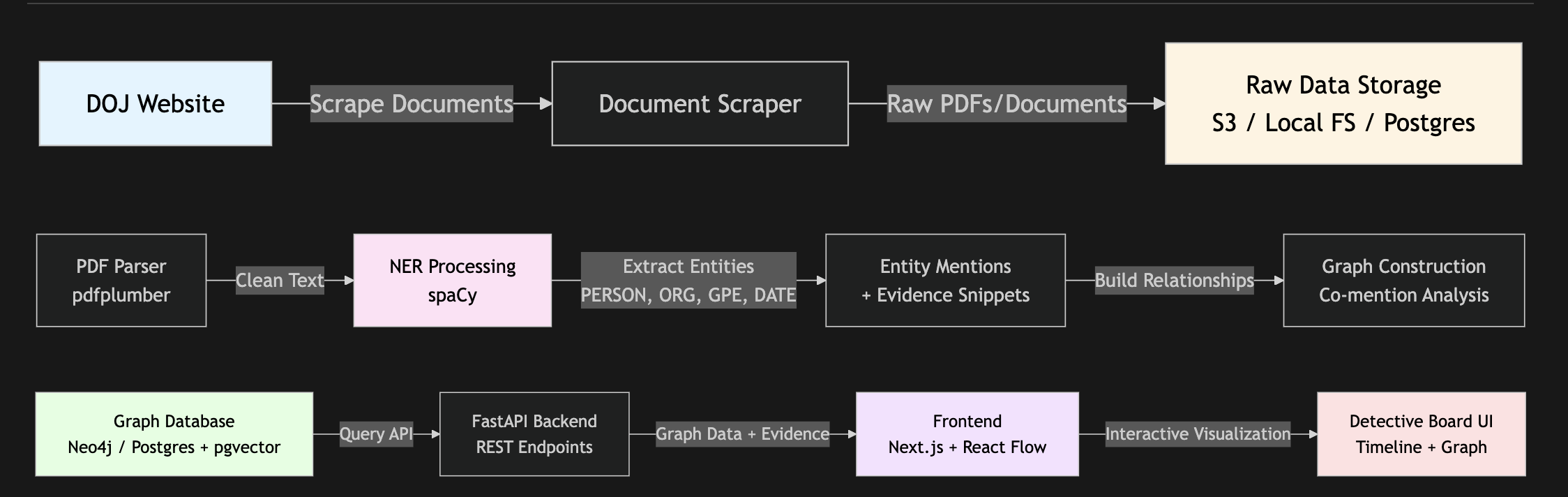
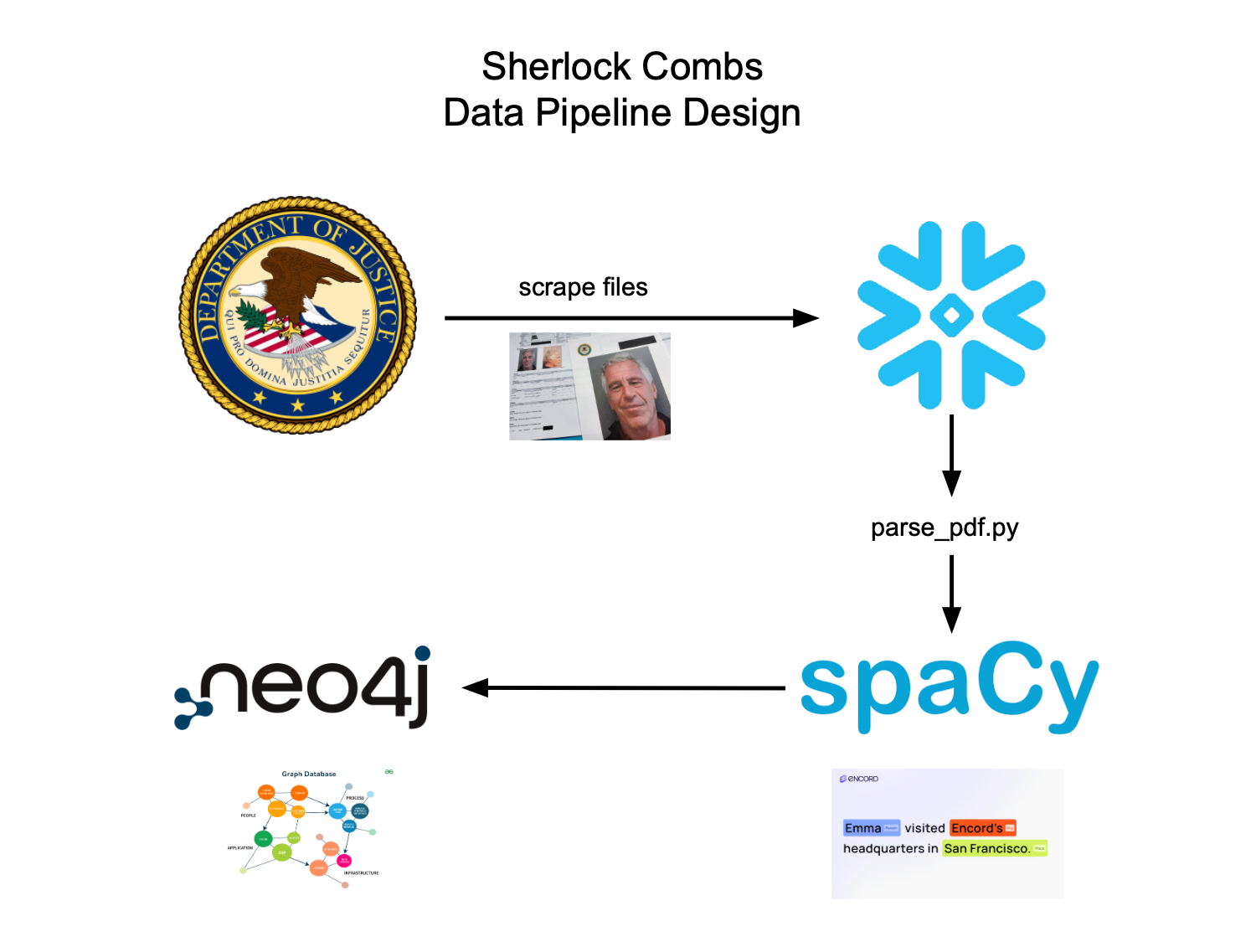
We built a full end-to-end pipeline in 24 hours:
Backend (Python)
- pdfplumber for pulling clean text from PDFs
- spaCy for entity recognition (PERSON, ORG, GPE, DATE)
- OpenAI gpt-4o-mini for summarization + robust date extraction
- Graph construction based on evidence-backed co-mentions
Frontend (Next.js + TypeScript)
- React Flow for an interactive investigation graph
- Custom timeline slider for time-based filtering
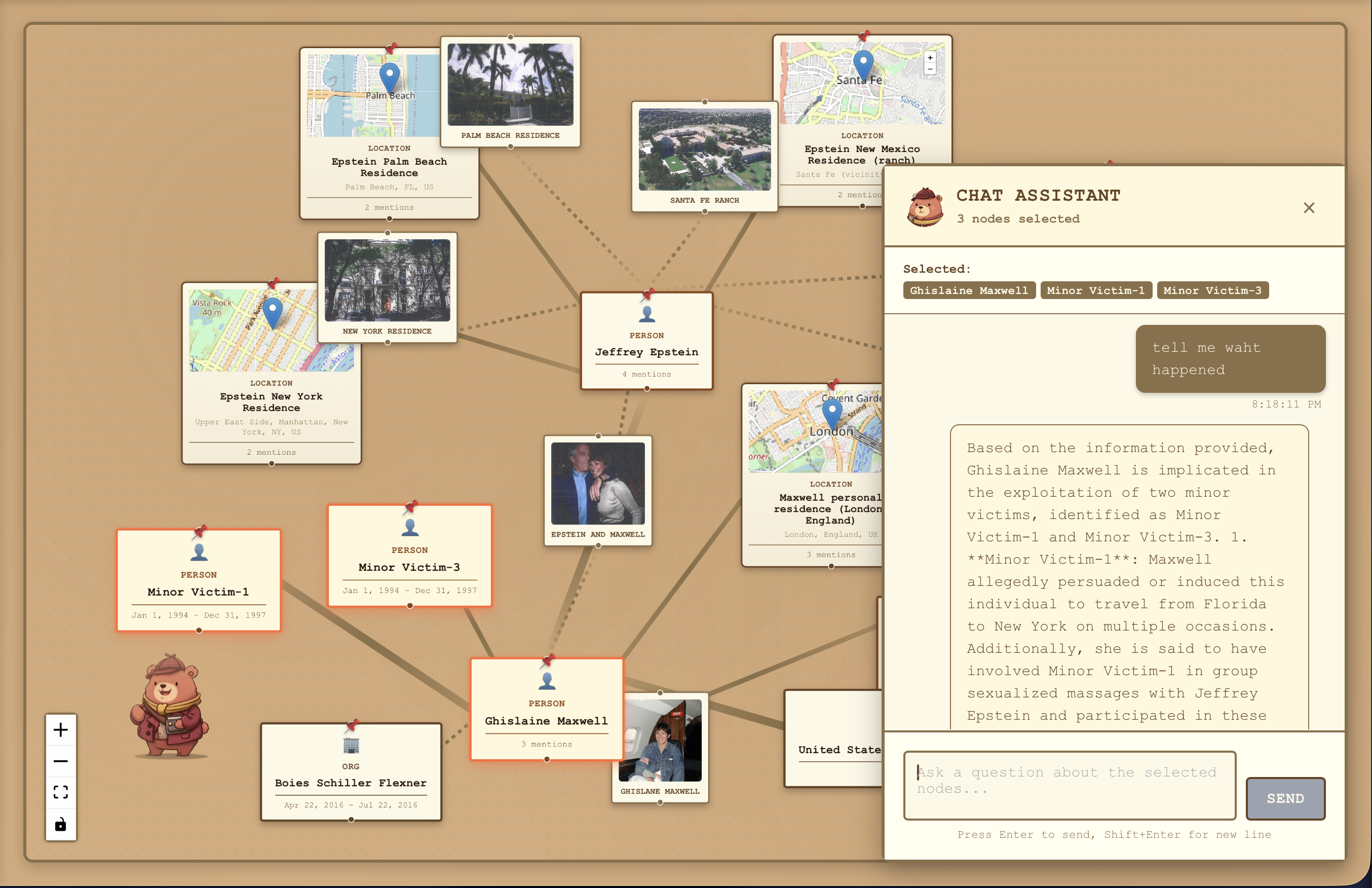
- Evidence side panel for citation tracing
- A gorgeous detective-board aesthetic
- Bonus: 3D globe visualization for geographic context
Pipeline flow:
Upload → Parse → Extract Entities → Build Graph → Explore Visually
⚡ Challenges We Ran Into
Building Sherlock Combs in 24 hours came with a ton of fun (and very real) challenges, especially when dealing with messy investigative documents:
- Distinguishing between different types of PDFs — scanned images, court filings, structured reports, and even email-style exchanges
- Designing the UI to truly feel like an interactive detective corkboard
- Parsing raw text and accurately extracting + classifying dates from inconsistent PDF formats
- Fine-tuning Named Entity Recognition (NER) so we only extract the entities we care about (people + locations)
- Animating Sherlock Combs himself while he’s responding to user prompts for a more immersive experience
- Making sure we only load the most relevant selected nodes into the chat context to keep interactions fast and focused
🏆 Accomplishments We’re Proud Of
In just 24 hours, we managed to build something both powerful and adorable:
- A cute animated bear mascot (Sherlock Combs!) that reacts while answering prompts
- Beautiful flight-path visualizations that bring timeline events to life
- A clean, polished detective-board UI that feels immersive and fun to explore
- A full end-to-end data processing pipeline that actually works:
- Scraping documents directly from the DOJ website
- Storing raw files and metadata in Snowflake
- Parsing PDFs into clean text
- Using GPT-4o to generate summaries and extract key timeline context
- Running Named Entity Recognition (NER) to identify people + locations
- Storing everything in a Neo4j graph database for interactive relationship exploration
- Scraping documents directly from the DOJ website
📚 What We Learned
This project was an amazing crash course in:
- Real-world NLP edge cases
- Graph construction + interactive visualization
- Timeline-based UX as a powerful investigation dimension
- The importance of citations + evidence in AI tools
- Full-stack integration across Python + Next.js
- Prompting + cost-efficient LLM usage
- Performance optimization for dynamic graph interfaces
- Ethical responsibility when building tools involving real people
🌟 What’s Next for Sherlock Combs
We’re just getting started. Future upgrades include:
- Smarter alias merging + entity resolution
- Semantic relationship extraction beyond co-mentions
- Full-text + semantic search across document evidence
- OCR support for scanned archives
- Collaboration workspaces for investigative teams
- External context integration (news + public databases)
Sherlock Combs turns unstructured documents into structured investigations — with every connection backed by proof.
Built With
- d3.js
- gpt-4o-mini
- leaflet.js
- neo4j
- pdfplumber
- reactflow


Log in or sign up for Devpost to join the conversation.