Shepherd
Inspiration
Every engineering team I've worked on has the same problem: critical decisions get made in merge request threads -- "we chose X over Y because of that outage last quarter" -- and then the MR merges and nobody reads those threads again. When someone leaves, their reasoning leaves with them. Six months later a new hire asks "why do we use cursor pagination?" and the best answer anyone has is "I think Sarah decided that? She left in January."
We've all tried wikis and Confluence pages and "just write an ADR" policies. They work for about two weeks. Then people stop writing them because it's extra work with no enforcement loop.
I wanted something that captures decisions from the conversations teams are already having, structures them so they're actually findable, and then closes the loop by checking new code against those decisions. No extra steps, no separate documentation workflow.
What it does
Shepherd watches your merge request discussions and does two things:
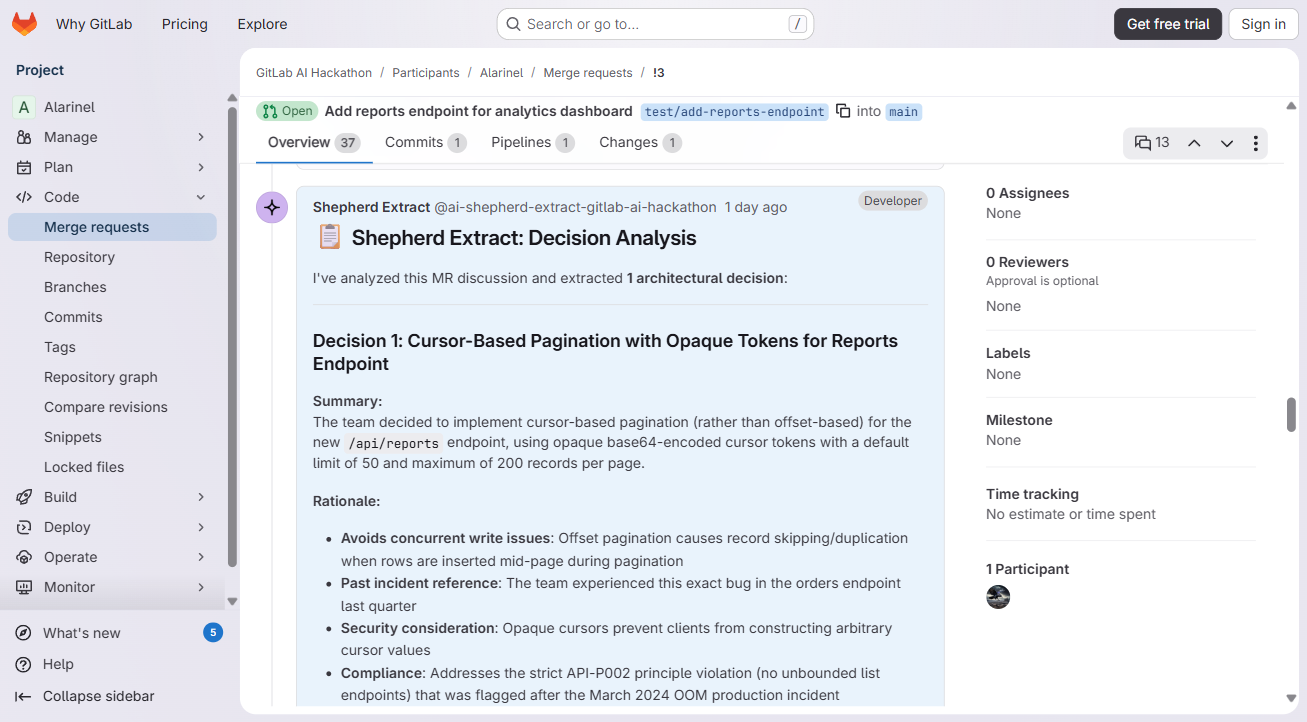
Extracts decisions. When your team debates approaches in MR comments and reaches a conclusion, Shepherd identifies what was decided, creates a structured Architecture Decision Record (ADR), and commits it to your repo. It handles implicit decisions ("ok fine, go for it"), sarcasm ("oh sure, MongoDB for everything, that always works out great"), and calibrates confidence so it doesn't create false ADRs that erode trust.
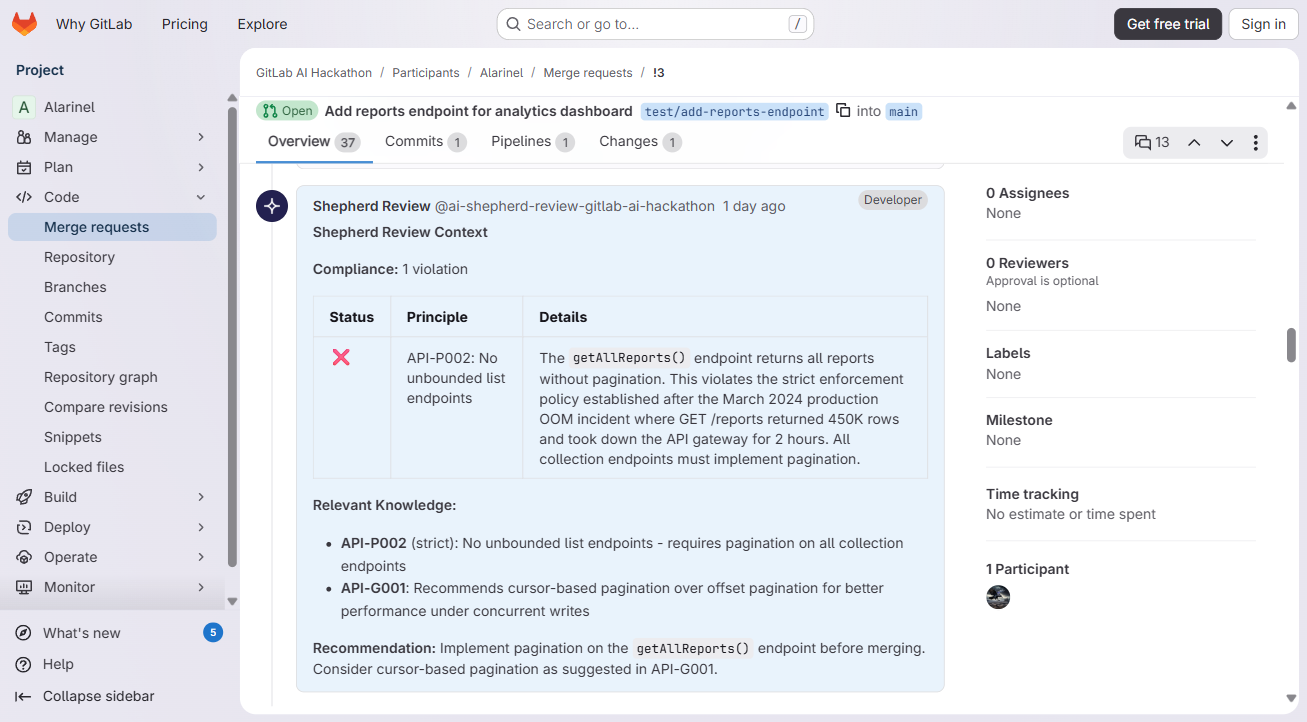
Enforces compliance. When new code comes in, Shepherd checks it against your team's established principles and posts a compliance table on the MR. If your team decided "no unbounded list endpoints" after an OOM incident, Shepherd catches the next
GET /reportsthat returns everything without pagination.
There's also a chat agent for Duo Chat -- ask @shepherd why something is the way it is and it traces through principles, guidelines, and ADRs to give you the full history.
The CLI tool (11 commands) lets you validate domain YAML locally, search your knowledge base, run heuristic compliance checks, generate an interactive dashboard, create knowledge interactively or via scripts, install a pre-push hook, and export everything as JSON or CSV. The live dashboard at shepherd serve has full CRUD -- create principles, guidelines, and domains from the browser.
How we built it
Two multi-agent flows on the GitLab Duo Agent Platform, powered by Claude:
Shepherd Extract (3 agents in sequence):
- Decision Extractor reads MR discussions, detects sarcasm, scores confidence
- Domain Classifier maps extracted decisions to the right domain and checks for contradictions
- Knowledge Writer creates ADR files via
create_commitand posts summary comments
Shepherd Review (2 agents in sequence):
- Compliance Checker reads the diff and domain YAML, compares against active principles
- Context Provider formats findings into a clean compliance table and posts it on the MR
Each agent has its own toolset scoped to what it needs -- the extractor gets list_all_merge_request_notes and list_merge_request_diffs, the writer gets create_commit and create_merge_request_note, etc.
The CLI is standalone Python (click + PyYAML + jsonschema). No GitLab Duo required -- you can validate and search locally. The dashboard is a single-file HTML generator with Tailwind CSS, sortable tables, collapsible sections, and a floating "Quick Add" button for CRUD operations backed by a local HTTP server.
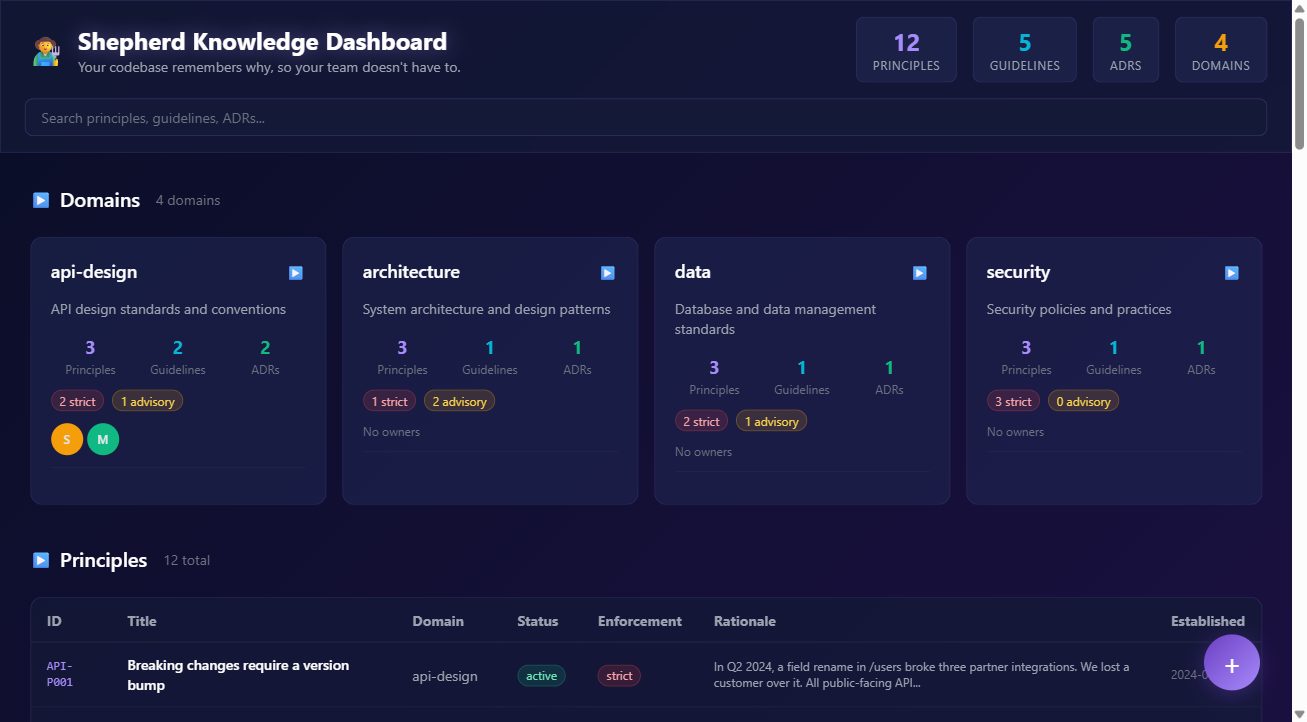
Domain knowledge is organized into a three-layer hierarchy: Principles (WHY -- long-lived rules), Guidelines (HOW -- implementation patterns), and Decisions/ADRs (WHAT -- point-in-time records). Only 4 required fields per principle: id, title, rationale, status.
Challenges we ran into
Project ID resolution. The Duo Agent Platform tools need a project_id for every call, but the flow execution context doesn't expose it directly. We tried using gitlab_blob_search to self-discover the project, but the search scope wasn't reliable. Ended up hardcoding the project ID in the prompt template -- it works but it's the kind of thing you'd want the platform to inject as a variable.
Inter-agent data passing. The flow framework routes agents sequentially, but there's no structured data handoff between them. Agent 1's analysis has to survive in the conversation context for Agent 2 to pick up. When the decision extractor identifies 3 decisions with confidence scores, the domain classifier needs all of that detail. We had to be very explicit in the prompts about output format so the next agent could reliably parse the previous agent's findings.
Confidence calibration tuning. Getting the threshold right was harder than expected. Too low (0.5) and Shepherd creates ADRs for casual suggestions ("we might want to consider GraphQL eventually"). Too high (0.9) and it misses legitimate implicit decisions where nobody explicitly said "we decided." We landed on 0.7 as the extraction floor, with the understanding that a false positive ADR is worse than a missed decision -- if Shepherd extracts 10 decisions and 2 are wrong, the team stops trusting it within a week.
Sarcasm detection edge cases. "Oh sure, let's definitely use offset pagination, that always works out great" needs to be recognized as opposition, not endorsement. The dismissive opener, the hyperbole, the ironic praise -- Claude handles this well, but we had to be very explicit in the prompt about what sarcasm looks like in code review context and what the failure mode is (recording the opposite of the team's actual position).
Accomplishments that we're proud of
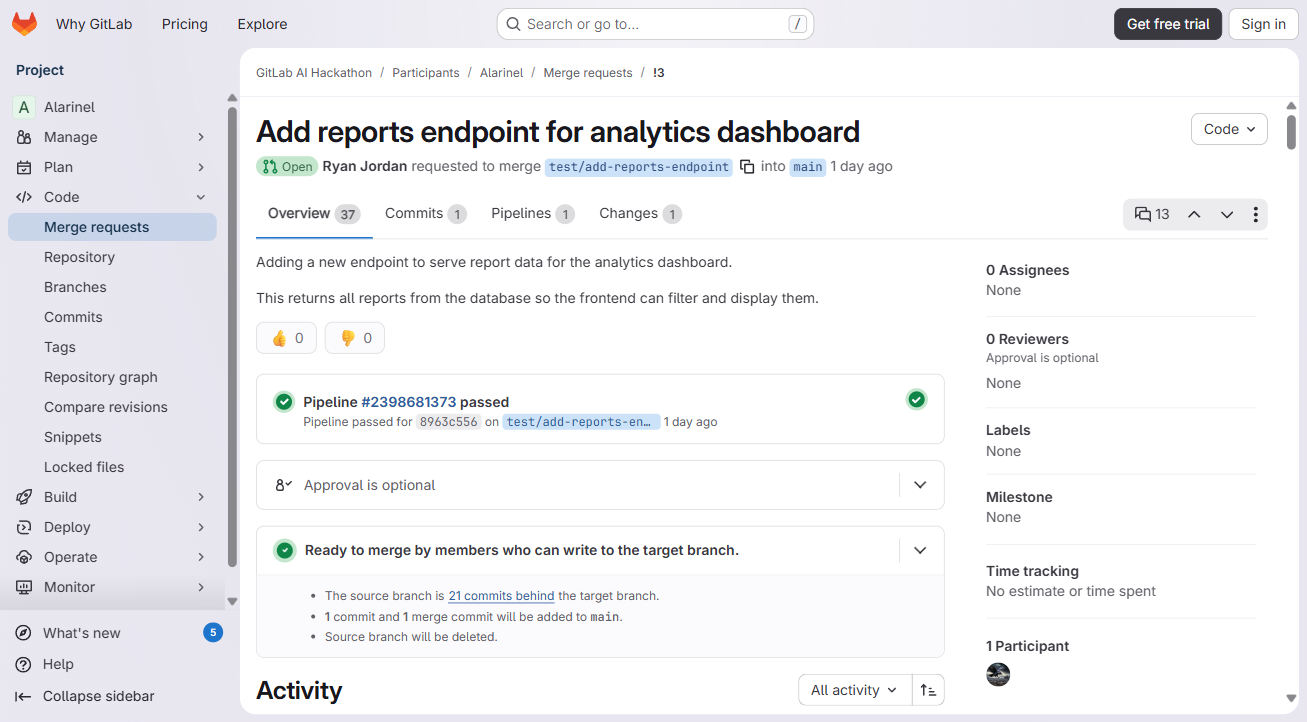
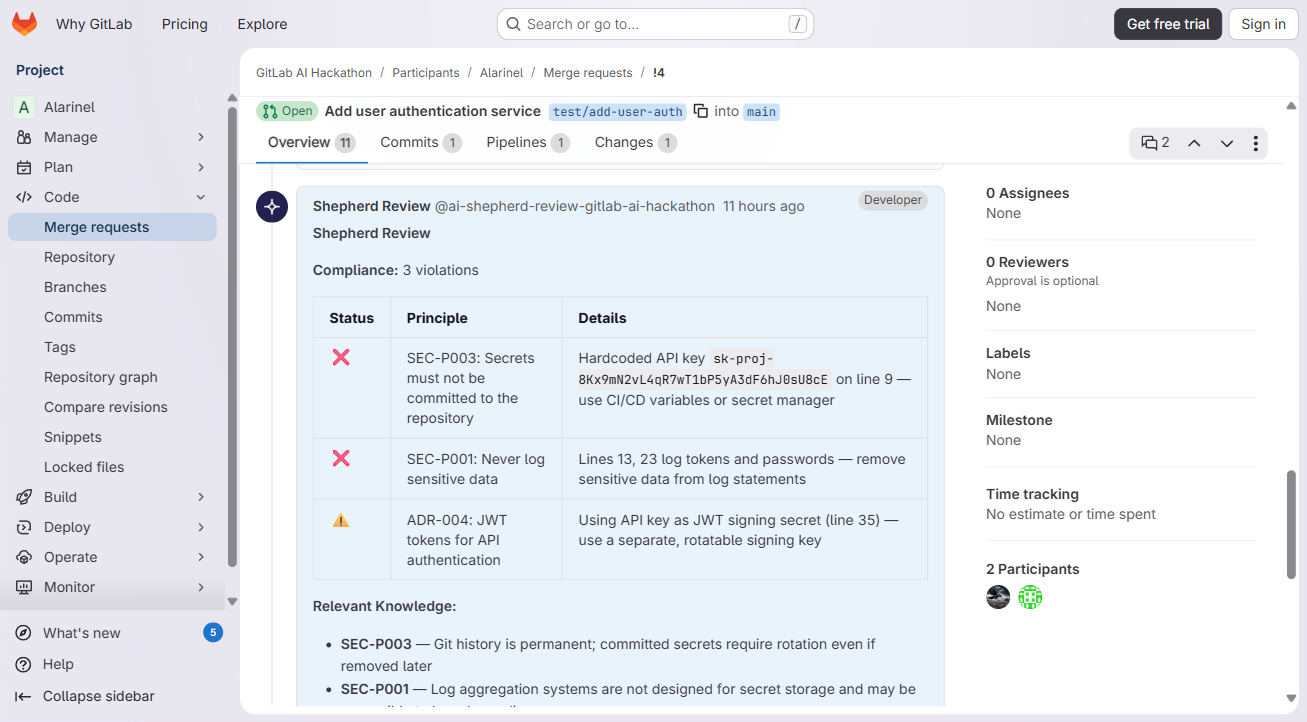
The review flow actually works end-to-end on live MRs. We have 3 test MRs with real Shepherd output -- MR !3 catches a pagination violation (API-P002), MR !4 finds 3 security issues (hardcoded API key, token logging, JWT signing concern), and MR !5 flags PII stored in plaintext. Each one posts a formatted compliance table with pass/fail status and principle references that link back to the original incident that created the rule. Same with extraction -- @shepherd-extract reads the discussion, identifies decisions, and posts a summary with confidence scores.
Sarcasm detection actually working was satisfying. We tested it with real-world patterns from code review -- dismissive openers, ironic praise, rhetorical questions -- and Claude consistently identifies them as opposition rather than endorsement.
The CLI ended up at 11 commands and close to 3,000 lines. validate, search, check, stats, init, dashboard, serve, create principle, create guideline, create domain, why, hook install/remove, export. The why command traces a principle through the full hierarchy -- rationale, implementing guidelines, referencing ADRs -- in a formatted box display. The serve command launches a live dashboard with CRUD modals and a REST API.
The domain knowledge schema hitting the right level of simplicity. We started with 14 fields per principle and kept cutting until we hit 4 required fields (id, title, rationale, status). Everything else is optional. That's the threshold where teams actually fill them in.
The live dashboard was a late addition that turned out to be one of the best features. shepherd serve starts a local web server with a dark glassmorphism UI showing all your domain cards, a sortable principles table, ADR timeline with confidence badges, and a "Quick Add" button that lets you create new principles right from the browser. A CTO can sit down, fill in three things they've learned the hard way, and those rules are enforced on every MR from that point forward.
What we learned
4 required fields beats 14 optional ones. Early versions of the domain schema had fields for severity, category, related_systems, review_frequency, etc. Nobody fills in 14 fields. We cut to 4 required and made everything else optional. Adoption is a feature.
The "silent majority" problem. Most MRs don't contain architectural decisions. They're bug fixes, style changes, dependency bumps. Shepherd needs to gracefully handle the 90% case (post nothing or "no decisions detected") without flooding teams with empty comments. The exclude_labels config and confidence threshold handle this, but it took iteration.
Building the CLI alongside the flows was the best decision we made. The CLI forced us to get the domain YAML schema right early, because we had to parse and validate it locally. It also gave us a testing tool -- shepherd check runs the same heuristic rules locally that the flow agents check with Claude, so we could iterate on detection patterns without waiting for Duo flow executions.
Agent prompt engineering is about failure modes, not happy paths. The prompts don't just say "extract decisions." They say "sarcasm looks like this and misinterpreting it records the opposite of the team's position." They say "a confidence of 0.45 means this is exploration, not commitment." Every prompt clause exists because we observed a specific failure and added a guard against it.
Built With
- GitLab Duo Agent Platform
- Anthropic Claude
- Python (Click, PyYAML, jsonschema)
- YAML (domain knowledge schema)
- JSON Schema (validation)
- Tailwind CSS (dashboard)
What's next for Shepherd
Auto-evolving guidelines. When Shepherd sees the same pattern across 3+ ADRs in the same domain -- like every new API endpoint getting a "add pagination" comment -- it should propose a new guideline automatically. The decisions are already structured; pattern detection across them is the natural next step.
GitLab issue template integration. Right now Shepherd only watches MR discussions. But decisions happen in issue threads too -- "should we build this as a microservice or add it to the monolith?" Integration with issue templates would let Shepherd extract decisions earlier in the lifecycle.
Cross-project knowledge. A principle like "no sensitive data in eventually-consistent stores" applies to every service, not just one repo. Shepherd should support shared domain files that multiple projects inherit from, with per-project overrides.
Expanding beyond MRs to capture decisions from issue discussions. The extraction flow already handles multi-participant discussions with implicit decisions. Applying it to issue threads (where broader architectural debates happen before code exists) would catch decisions that currently fall through the cracks entirely.
Built With
- anthropic-claude
- gitlab
- gitlab-duo-agent-platform
- json-schema
- python
- tailwind
- yaml


Log in or sign up for Devpost to join the conversation.