Inspiration
ShelfEngine came from a very simple frustration: I had an absurd number of bookmarks. Not 50. Not 200. I’m talking hundreds that slowly turned into “I know I saved it somewhere” chaos.
Folders worked until they didn’t. At some point, it stopped being storage and started being a graveyard. I wasn’t organizing knowledge. I was hoarding links.
The real problem wasn’t saving. It was recall.
I didn’t want another prettier folder tree. I wanted something that felt like querying my own memory. Type what I vaguely remember and get back the right thing. Fast. Local. Private.
That was the bar.
What it does
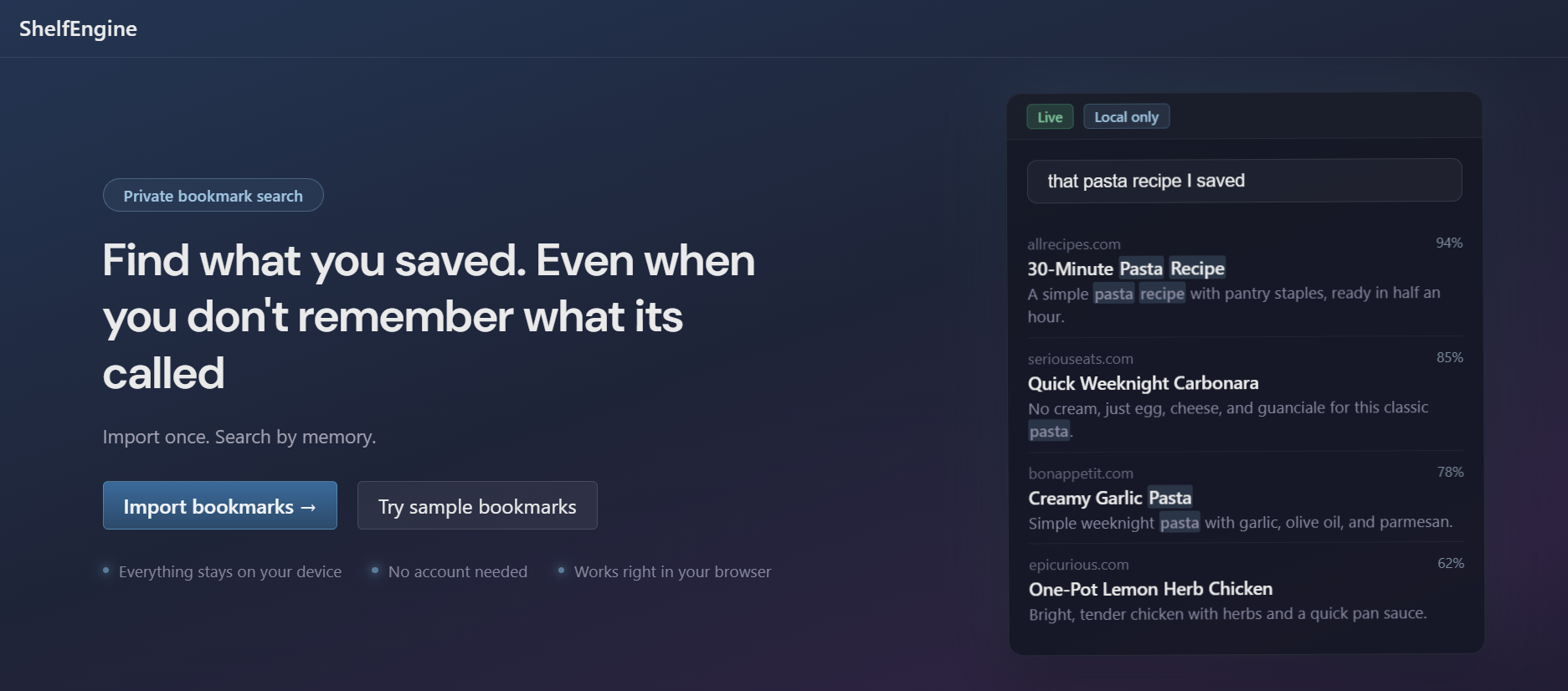
ShelfEngine is a local-first bookmark search engine built for people who’ve let their bookmark list spiral out of control.
You import your bookmarks once. After that, you can search using:
- Plain language
- Power operators like
site:andfolder: - Quoted phrases
- Excludes and OR logic
It blends lexical matching with semantic retrieval so even vague queries work. And instead of just dumping results, it tells you why each link matched.
There’s also an optional Chrome extension bridge to sync changes, but the core product runs entirely in your browser.
No accounts. No backend dependency. No data leaving your machine.
How I built it
Frontend: React + TypeScript + Vite.
Storage: IndexedDB via Dexie.
Embeddings: transformers.js inside a Web Worker so the UI never freezes.
The ranking logic blends lexical and semantic signals:
$$ \text{score} = \alpha \cdot s_{\text{semantic}} + (1-\alpha)\cdot s_{\text{lexical}} $$
Then I layer boosts and penalties for:
- Phrase matches
- Recency
- Noisy titles
- Field weights
I also built structured query parsing so it feels powerful without feeling academic. If you want to search like a power user, you can. If you don’t, you don’t have to.
Challenges
The hardest part wasn’t embeddings. It was consistency.
People search in messy ways:
- Half-remembered titles
- Random keywords
- “That article about vector databases from last month”
Balancing semantic intuition with deterministic lexical signals was tricky. If they disagreed, the ranking could feel random.
Sync reliability was another issue. Handling extension deltas, queue flushes, and resync flows without duplicating or corrupting state required strict ingestion rules.
Performance mattered too. Around ~1000 bookmarks, indexing and scoring had to stay responsive or the whole thing felt fake.
What I’m proud of
- It actually solves the “absurd bookmark pile” problem.
- It’s truly local-first.
- The hybrid retrieval feels intelligent without being opaque.
- The “why matched” layer builds trust.
- The extension sync is optional, not required.
It doesn’t pretend to be a startup SaaS. It’s a focused system that does one thing well.
What I learned
Search quality is systems engineering.
It’s parsing + scoring + filtering + explainability + UX. If one part is weak, the whole thing feels unreliable.
I also learned:
- How to build browser-only data pipelines.
- How to offload heavy compute to Web Workers cleanly.
- How to think about eventual consistency without a backend.
- How to document architecture like I expect other engineers to read it.
What’s next
Before adding features, I want to harden it.
- Better regression fixtures.
- Repeatable performance instrumentation.
- Stronger sync edge-case coverage.
- More confidence in ranking behavior across weird queries.
The long-term goal isn’t “AI bookmarks.”
It’s disciplined, privacy-first personal search that works when your digital life becomes messy.

Log in or sign up for Devpost to join the conversation.