-
-
Chat
-
Menu
-
Dashboard
-

Logo

ShehriSaathi — Citizen's Companion
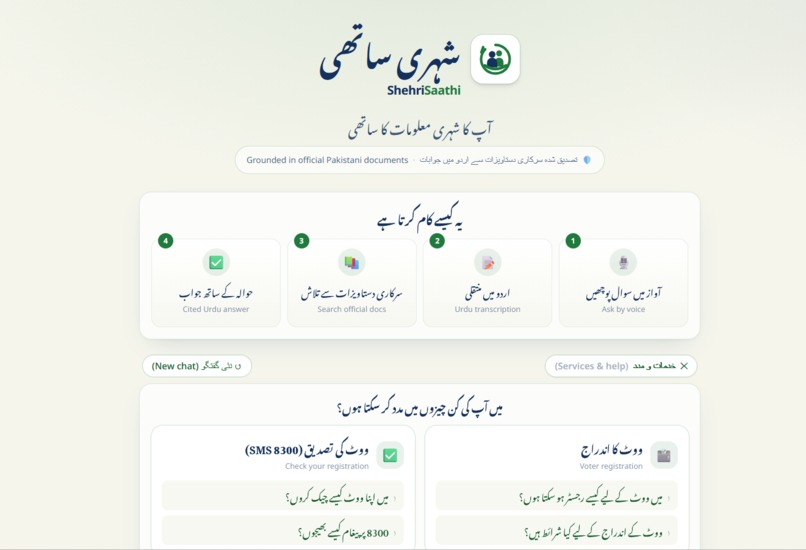
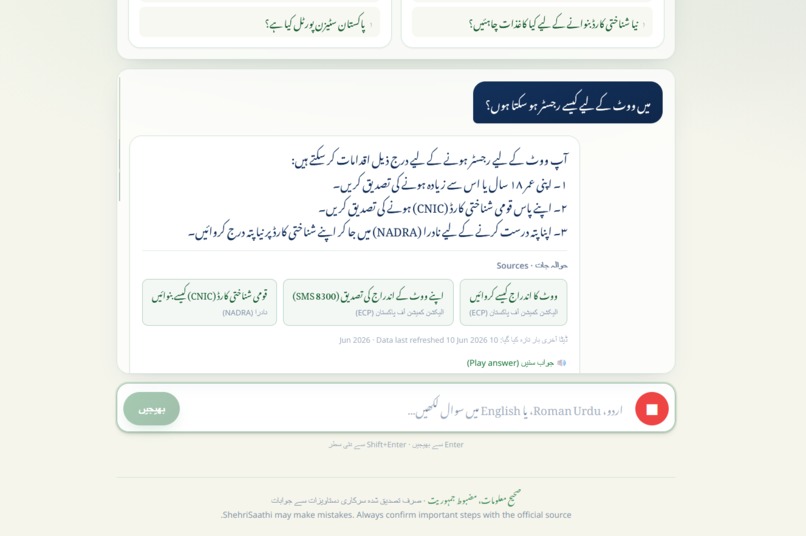
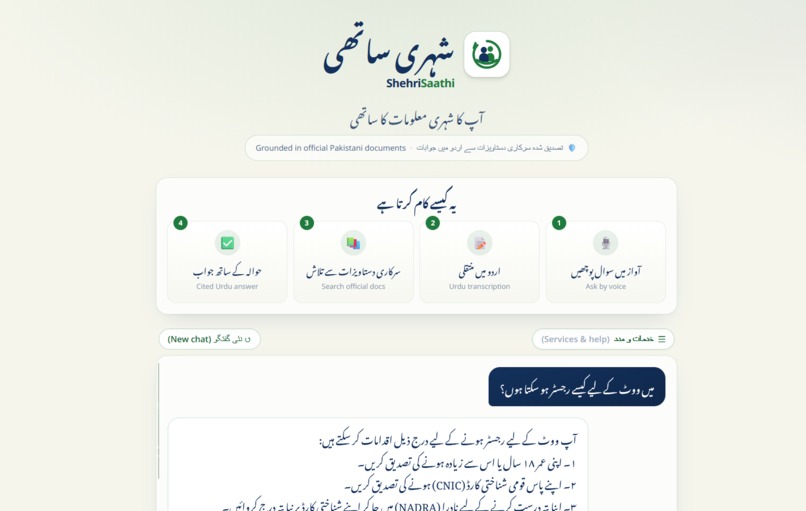
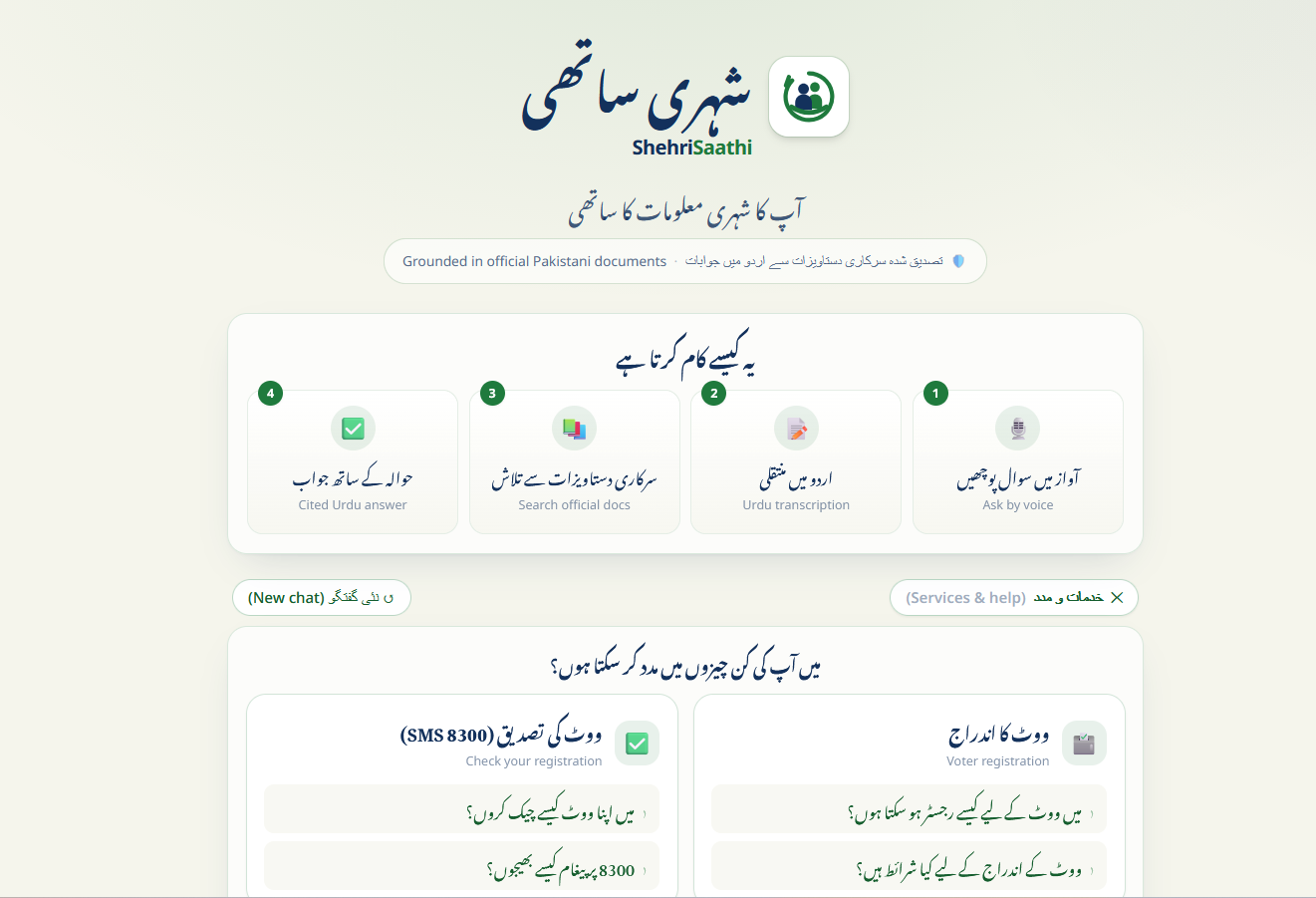
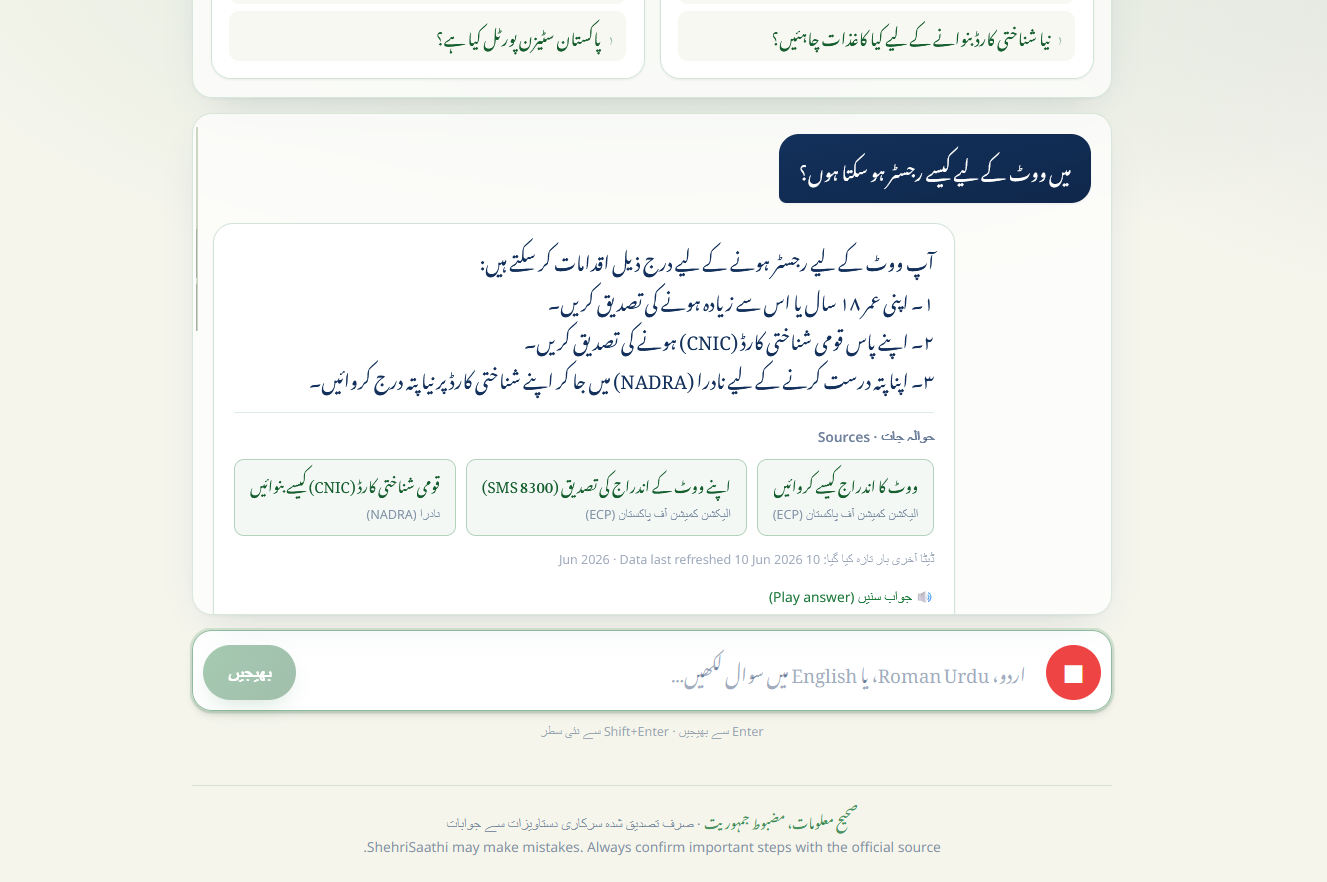
Millions of Pakistanis can't easily access clear civic information. Voter registration steps, how to get a CNIC, and how to file a complaint are scattered across government websites in dense English or formal Urdu — unusable for someone with low literacy, on a low-end phone, with limited data. ShehriSaathi lets a citizen simply ask a question by voice in Urdu and get a short, clear answer — drawn only from official documents, with the source cited every time.
What it does
- Accepts questions by voice or text in Urdu.
- Answers in simple, clear Urdu suitable for low-literacy readers.
- Answers only from a curated set of official Pakistani civic documents (Election Commission of Pakistan, NADRA, Pakistan Citizen Portal) — and cites the source of every answer.
- Refuses to guess. If a question falls outside its verified documents, it says so in Urdu instead of inventing an answer — directly tackling the misinformation problem.
Inspiration
Standard AI chatbots fail exactly the people who need civic help most: they hallucinate legal and procedural details, assume English literacy, and assume fast connections. We wanted the opposite — a tool that is honest about what it knows, speaks the user's language by voice, and runs light enough for the realities of a low-bandwidth, low-end-device user.
How we built it
- Frontend & server: Next.js (App Router) + TypeScript, RTL Urdu UI with the Noto Nastaliq Urdu font, mobile-first.
- Language model: Llama 3.3 70B served on Groq's fast inference (free tier, OpenAI-compatible endpoint).
- Voice input: Groq-hosted Whisper (large-v3-turbo) for Urdu speech-to-text.
- Grounding (RAG): Official content is ingested into local markdown documents, chunked, and retrieved with an in-memory BM25 keyword index. The model is constrained to answer only from the top retrieved chunks and to cite them.
- Automated ingestion pipeline: A re-runnable script fetches content from official government sources and writes it to the document store, with a committed cached fallback so the app always works even offline.
Why AI is the right tool
The problem isn't a lack of information — it's that the information is unreadable for the target user. A language model is uniquely able to take dense official text and restate it in simple spoken Urdu, on demand, for any phrasing of a question. Pairing it with retrieval and forced citation keeps it accurate where a plain chatbot would hallucinate.
Challenges we ran into
- Preventing hallucination of civic facts, where a wrong answer is worse than none — solved with strict retrieval grounding, source citations, and an explicit Urdu refusal when context is missing.
- Urdu rendering and RTL layout with a readable Nastaliq font on small screens.
- Working within free-tier limits — we kept retrieval lean (top-4 chunks) to stay inside the token budget.
- Unreliable access to government sites — handled with a cached document fallback so a demo never depends on a live site.
What we learned
For civic tools, trustworthiness beats fluency. A model that admits "I don't have verified information on that" is more valuable to a citizen than one that sounds confident and is wrong.
What's next
- Replace the curated document set with direct connections to official open-data feeds so it auto-updates.
- Add more regional languages and full voice-out answers.
- Pilot delivery over WhatsApp to reach low-end phones with no app install.
Built With
- bm25
- github
- groq
- llama-3.3-70b
- nextjs
- ocr
- openai
- python
- rag
- react
- tailwindcss
- typescript
- urdu-nlp
- vercel
- whisper


Log in or sign up for Devpost to join the conversation.