-
-
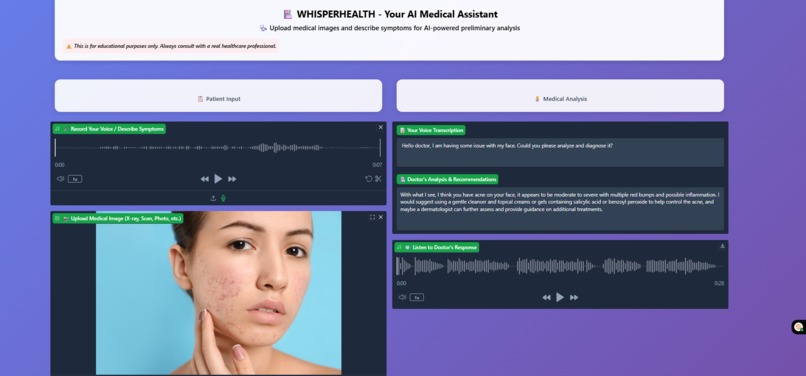
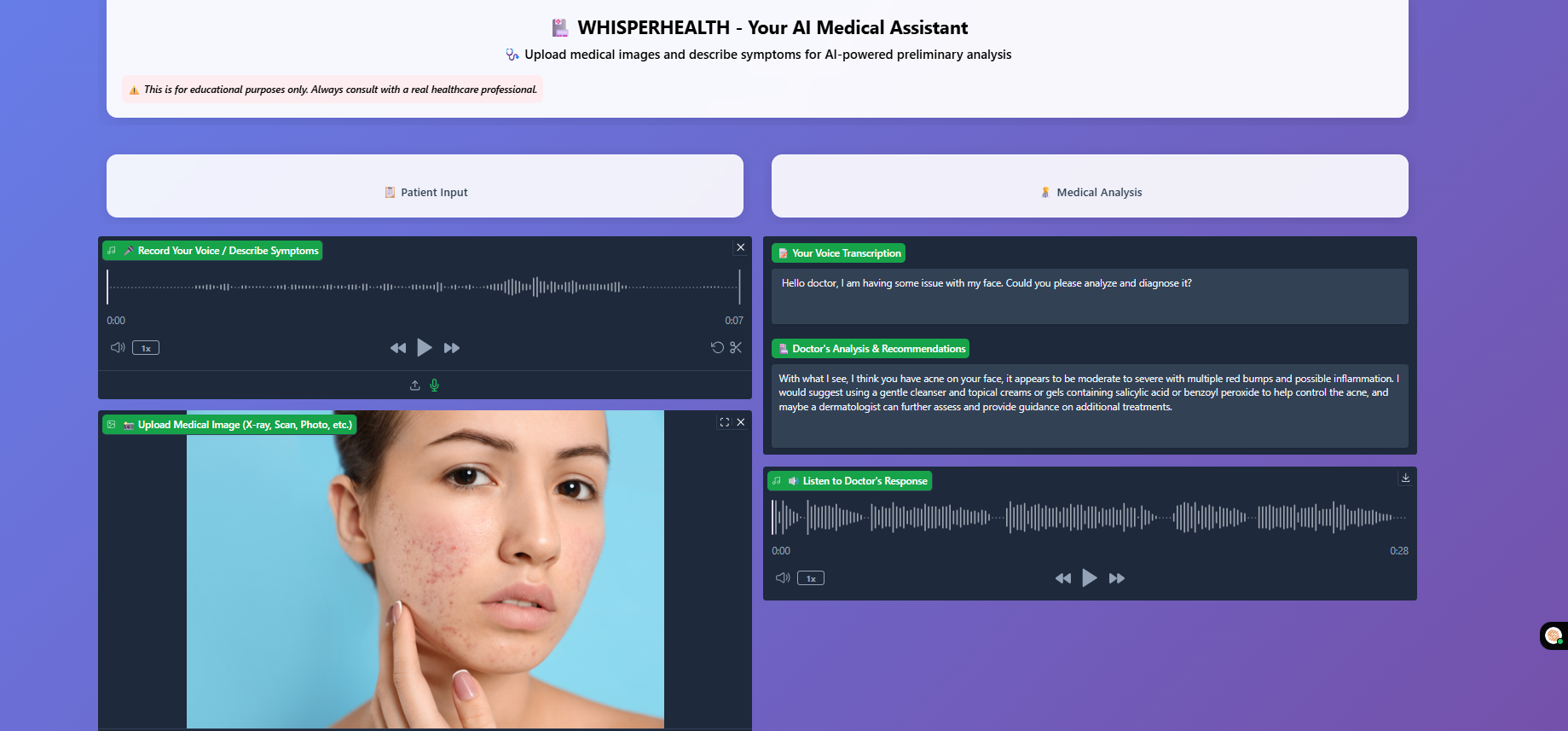
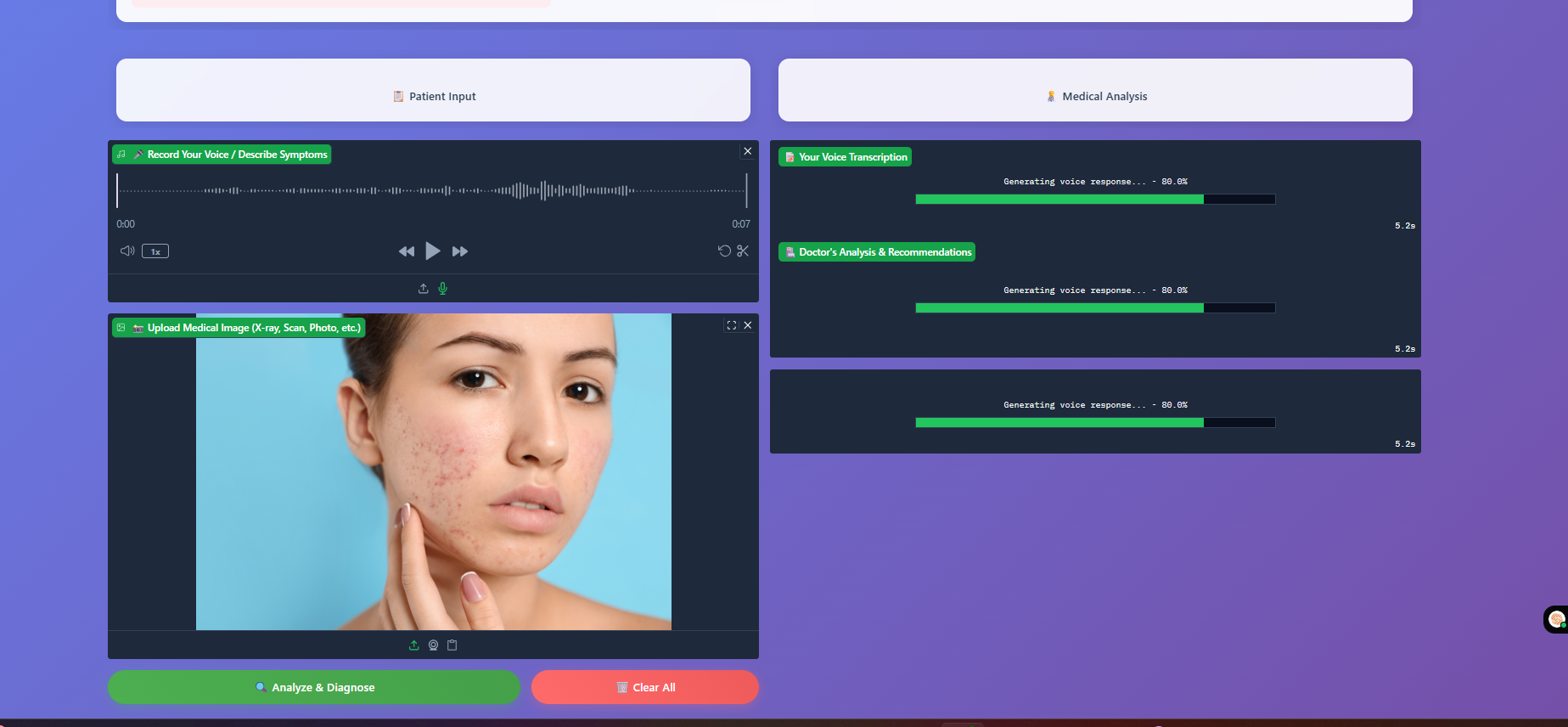
Medical Chatbot's diagnosis report and summary
-
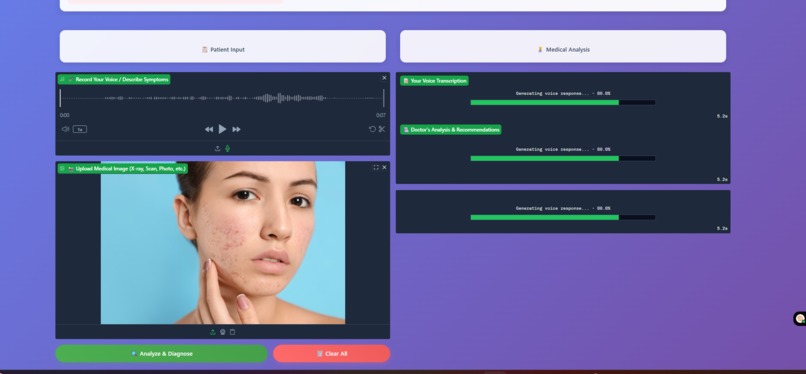
Chatbot analyzing the input
-
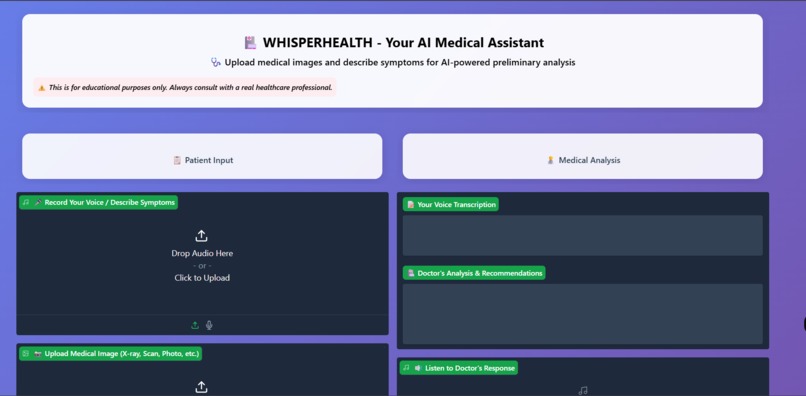
Project preview
-
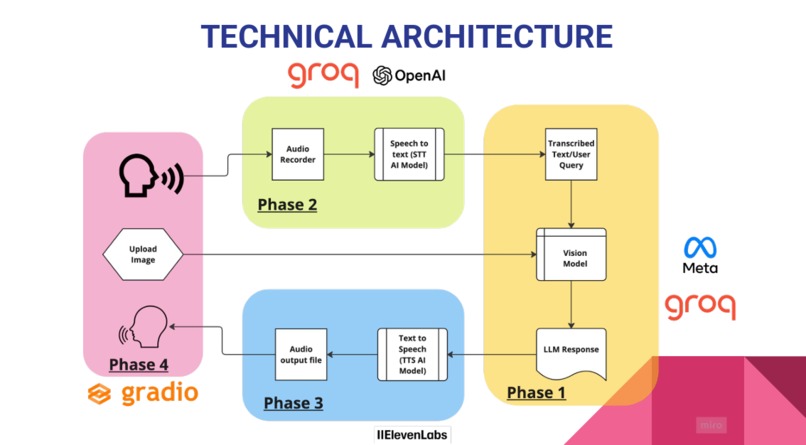
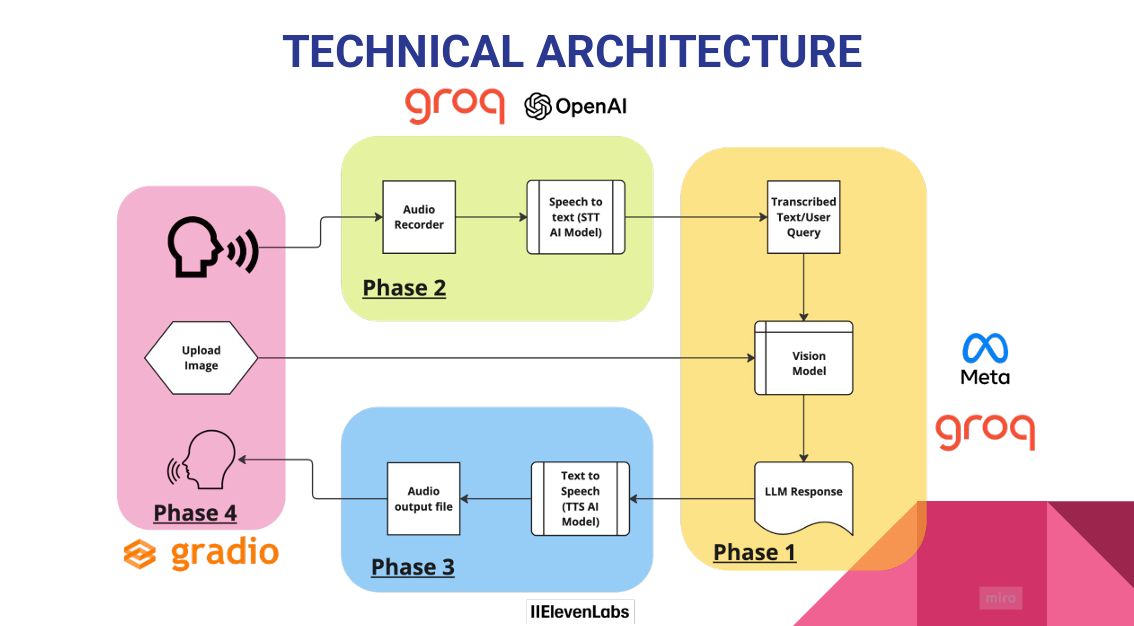
System Architecture
💡 Inspiration
During a visit to a rural health camp, I observed how people struggled to access basic medical guidance due to the lack of doctors, language barriers, and the inability to describe symptoms accurately in writing. This inspired me to build WhisperHealth — a voice- and image-powered AI medical assistant that allows users to simply speak or show their concerns and receive real-time, intelligent feedback using LLMs.
The rise of open-source vision and speech models made this dream possible. I wanted to blend these technologies into a real-world tool that could have meaningful social impact. The aim was simple: make medical assistance more human, more accessible, and more inclusive.
🏥 What it does
WhisperHealth is an AI-powered multimodal chatbot that simulates a medical assistant by:
- 🎙️ Letting users speak naturally about their symptoms.
- 📸 Allowing users to upload medical images like X-rays or rashes.
- 💬 Interpreting the input using Groq-hosted LLaMA 3 Vision and returning medically relevant, conversational responses.
- 🗣️ Reading the AI’s reply back in real-time voice output using TTS (gTTS/ElevenLabs).
- 🌐 All interactions happen on a clean, intuitive Gradio-based UI, deployed live on Hugging Face Spaces.
Whether someone has trouble typing, needs image-based assistance, or just prefers speaking over writing, WhisperHealth adapts and responds like a smart, AI-driven doctor.
🔧 How we built it
The project is built entirely in Python and deployed as a web app. Here's a breakdown:
🔹 Multimodal Core:
- Groq API: Used to access LLaMA 3 Vision for interpreting both image and text queries.
- Prompt engineering: Crafted adaptive prompts to give the LLM enough context for medical responses, depending on input type.
🔹 Speech Interfaces:
- Whisper: Converts user voice input to text using OpenAI’s transcription model.
- gTTS & ElevenLabs: Converts the bot’s text response into realistic speech.
🔹 Gradio UI:
- Interactive web interface with support for:
- Recording audio
- Uploading images
- Seeing and hearing AI responses in real-time
🔹 Deployment:
- Hosted on Hugging Face Spaces for free, open access.
.envhandled securely for API key management.
The overall architecture links these modules in sequence to create a fluid, human-like conversation flow — from voice or image to LLM response to spoken answer.
🧱 Challenges we ran into
- Multimodal prompt handling: Designing a single input pipeline for both image and voice was complex. The LLM’s prompt context had to vary dynamically depending on the input type.
- Latency management: Transcription (Whisper), inference (Groq), and TTS needed to be synced tightly to avoid laggy responses.
- Speech quality control: gTTS is free and fast but robotic; ElevenLabs is realistic but requires key rotation. Creating fallback systems was a challenge.
- Gradio’s audio streaming: Buffering and sample rate mismatches occasionally broke the voice input/output.
- Medical responsibility: Building disclaimers and responsible messaging into an AI healthcare tool was ethically important.
🏆 Accomplishments that we're proud of
- ✅ Built a fully functional AI bot that handles voice + image input, processes it through LLMs, and replies in voice.
- ✅ Successfully integrated Groq-hosted LLaMA 3 Vision — blazing fast and highly capable — for multimodal understanding.
- ✅ Designed a sleek Gradio interface with minimal user friction and live voice interactions.
- ✅ Deployed on Hugging Face Spaces, making it accessible worldwide with just a link.
- ✅ Did it all solo, end-to-end — from backend model orchestration to frontend UI.
📚 What we learned
- The power of Groq’s API and how to harness LLaMA 3 Vision for both text and image understanding.
- How to manage real-time voice interfaces using Whisper, audio libraries like
portaudio, and TTS tools. - The importance of prompt engineering in multimodal LLMs — tiny changes make huge impacts in medical response quality.
- Deployment workflows using Gradio,
.envfiles, and Hugging Face Spaces. - User experience matters — even the smartest AI is useless if the interface is hard to use or understand.
🔮 What's next for WhisperHealth
I plan to take WhisperHealth from a hackathon prototype to a production-ready assistive health tool:
- 💬 Add Retrieval-Augmented Generation (RAG) with trusted medical content (e.g., WHO, CDC, Mayo Clinic).
- 🗂️ User session history tracking for personalized assistance (e.g., MongoDB integration).
- 🌐 Multilingual support — add Hindi, Marathi, and other regional languages to bridge digital healthcare gaps in India.
- 📱 Develop a mobile app using React Native for wider accessibility.
- 🧠 Experiment with fine-tuning LLaMA Vision models on real medical images (MIMIC, ChestXray14).
- 👩⚕️ Collaborate with healthcare NGOs or telemedicine platforms to deploy this tool in rural clinics or camps.
This is just the beginning — I’m excited to continue combining AI and empathy to build meaningful, socially impactful tools.


Log in or sign up for Devpost to join the conversation.