-
-
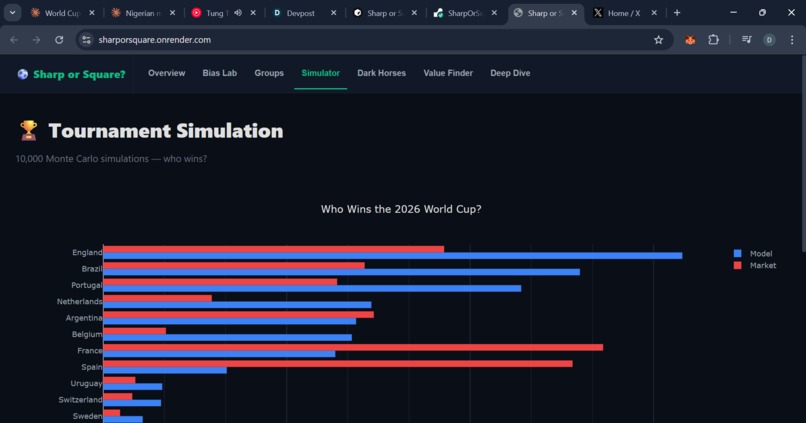
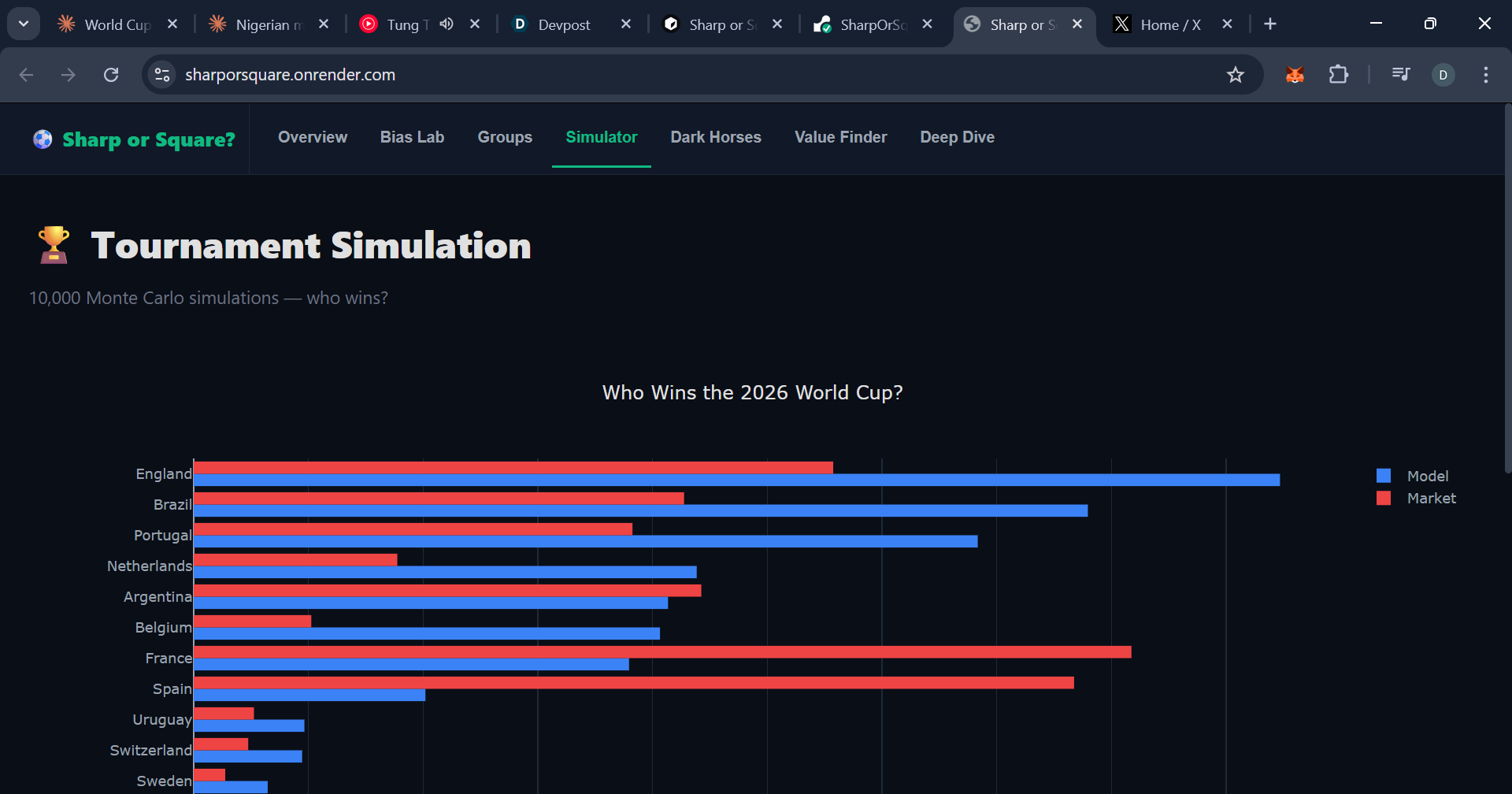
Tournament results after 10,000 simulations.
-
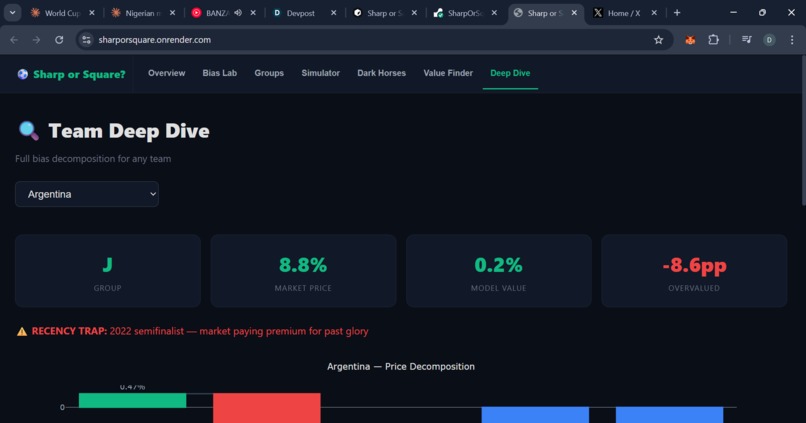
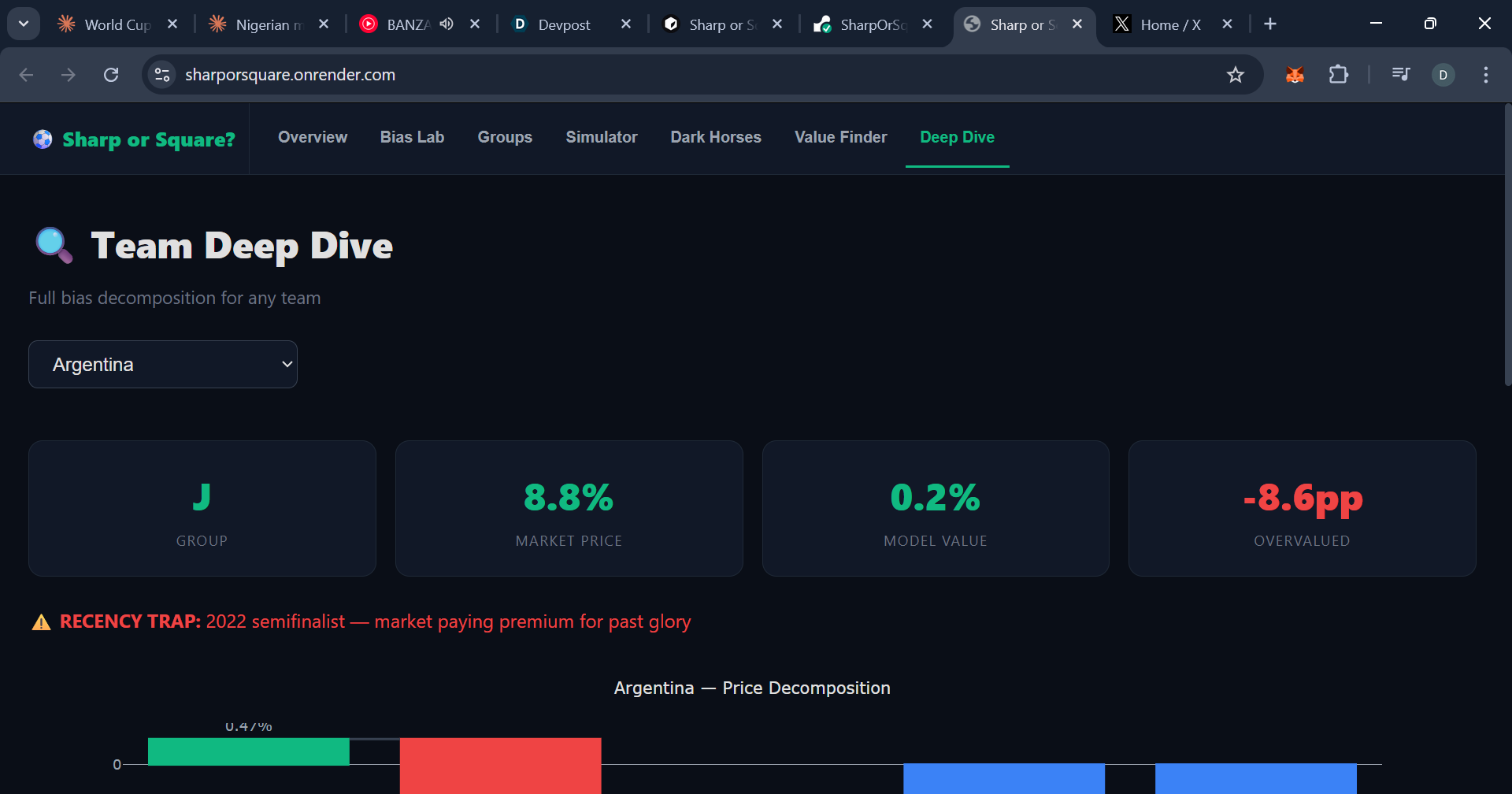
Deep dive of each team.
-
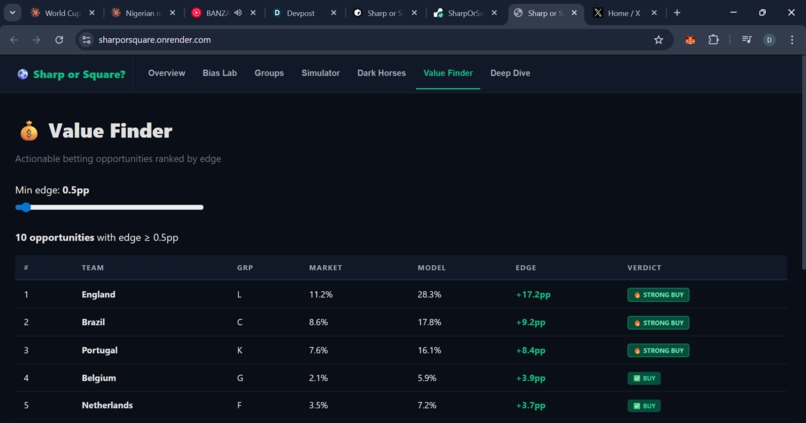
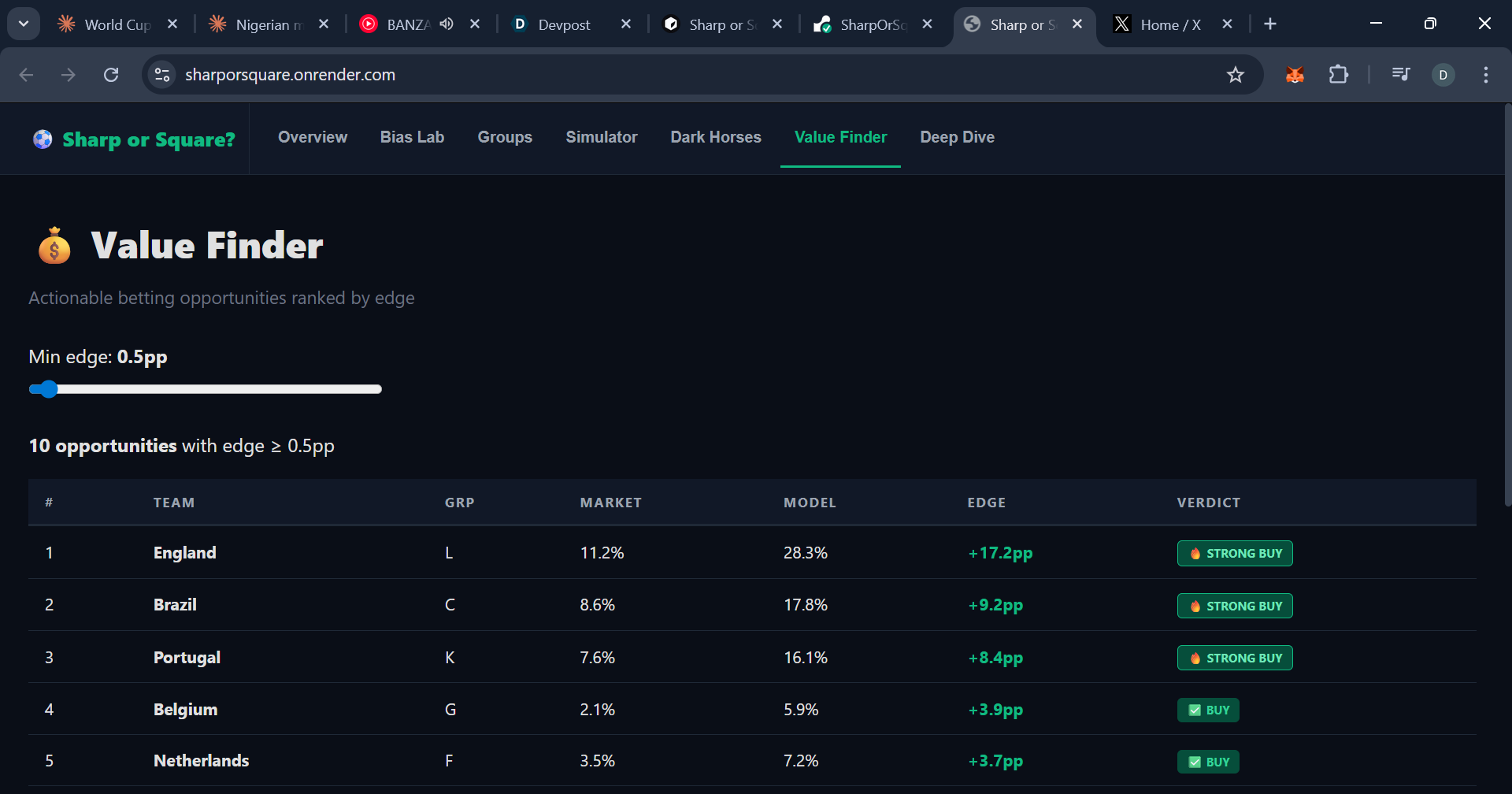
Value finder for gamblers and researchers.
-
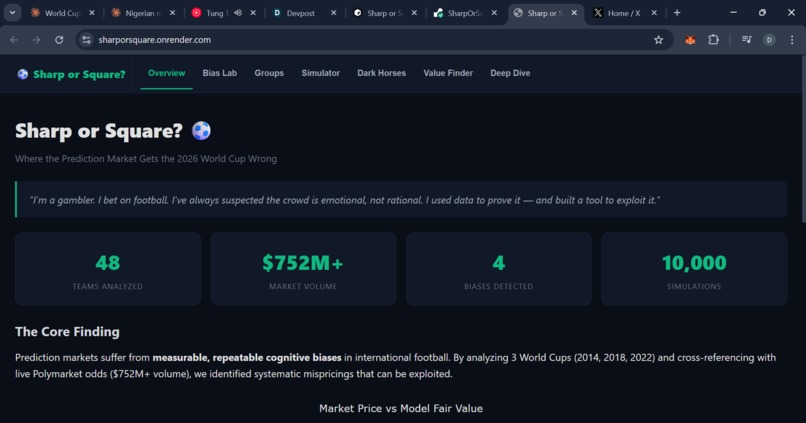
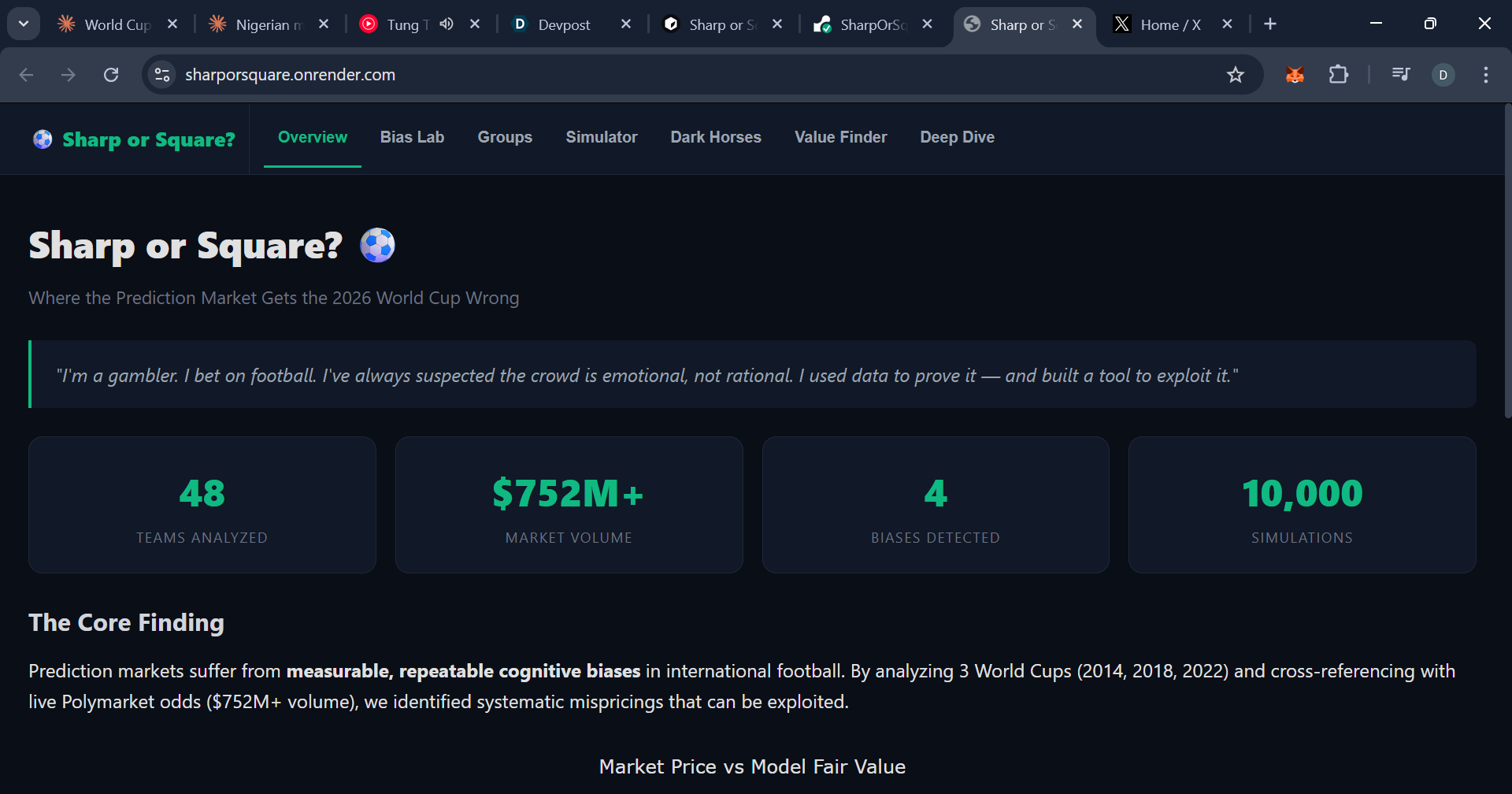
landing page of the website, showing its overview of the product.
Inspiration
I'm a gambler. I bet on football. With the 2026 World Cup approaching and $752M+ sitting in Polymarket's World Cup markets, I had one question: is the crowd actually smart, or are they just emotional?
Prediction markets are supposed to be efficient — the wisdom of crowds. But I've watched enough tournaments to know that fans overhype past winners, ignore host advantages, and chase narratives over numbers. I wanted to stop guessing and start proving it with data.
What it does
Sharp or Square is a bias detection engine that reverse-engineers three World Cups (2014, 2018, 2022) to discover where prediction markets systematically get international football wrong — then applies those findings to live 2026 Polymarket odds to find exploitable mispricings.
It identifies and quantifies four cognitive biases: Recency Bias (previous semifinalists overpriced by 5.3 percentage points), Continental Home Effect (host continent teams outperform by half a round), Star Power Premium (surprisingly reversed — high-profile squads are slightly underpriced), and Group of Death Discount (minimal effect — the market gets this right).
It then generates bias-adjusted fair values for all 48 teams, runs 10,000 Monte Carlo tournament simulations, predicts every group stage match with Poisson xG-based scorelines, and surfaces actionable value bets.
The deployed interactive dashboard has 7 pages: Overview, Bias Lab (historical proof of each bias), Group Stage predictions with match cards, Tournament Simulator, Dark Horses & Square Traps, a filterable Value Finder, and a Team Deep Dive with waterfall bias decomposition charts showing exactly how each team's price breaks down into xG fundamentals plus bias adjustments.
Key findings: England is the most undervalued team (+17.2pp edge). France is the biggest square trap (-16.3pp — recency bias from their 2022 final run). CONCACAF teams are systematically underpriced because the market ignores continental home advantage.
How we built it
The entire pipeline was built in Zerve AI's canvas environment using sequential code blocks:
Data collection — Scraped FBref for historical World Cup xG data across 96 team-tournament observations using pandas and BeautifulSoup with rate-limit-aware retry logic. Pulled live odds from the Polymarket Gamma API (public, zero auth).
Historical odds baseline — Hardcoded pre-tournament consensus betting odds for 2014, 2018, and 2022 and merged them with xG stats to create a master dataset.
Fair value model — Converted xG differentials into tournament win probabilities using softmax normalization within each tournament year.
Bias detection — Ran Welch's t-tests comparing market-vs-model gaps across bias categories: high-profile vs low-profile squads, previous semifinalists vs others, home continent vs away, death groups vs easy groups.
2026 predictions — Applied bias adjustments to current Polymarket odds. Simulated 10,000 full tournaments using Poisson-distributed goal scoring. Generated match-by-match predictions for all 72 group stage matches.
Deployment — Built a self-contained FastAPI application with all data embedded and an interactive Plotly.js frontend. Deployed on Render for instant, reliable access.
Stack: Python, FastAPI, Pandas, NumPy, SciPy, Plotly.js, Polymarket Gamma API, FBref, Zerve AI, Render.
Challenges we ran into
The Zerve agent kept planning instead of building. It would ask 10 clarifying questions instead of writing code. I learned to give it runnable Python code to complete rather than describing what I wanted in plain language — a valuable lesson in prompt engineering for agentic tools.
Wikipedia rate limiting. FBref squad scraping triggered 403 errors mid-run. Solved by increasing request delays to 15 seconds and adding exponential backoff retry logic with 60-second waits on rate limit responses.
Variable persistence between canvas blocks. Zerve blocks don't share Python globals, so intermediate DataFrames disappeared between blocks. Solved by saving to CSV files between pipeline stages.
Incomplete historical data. 2014 World Cup xG data doesn't exist on FBref (coverage started ~2017). Solution: used only 2018 and 2022 for xG analysis but still used 2014 placement data for tracking recency bias carry-forward into 2018.
Small sample sizes. Two World Cups with full data means only 64 observations for bias testing. P-values aren't always below 0.05, but effect sizes are large and directionally consistent — which is what matters for betting decisions where even small edges compound over time.
Accomplishments that we're proud of
Building a complete end-to-end pipeline — from raw data scraping to a deployed interactive app — in under 3 days, on a platform I'd never used before, while fighting an AI agent that wanted to have a meeting about everything instead of just writing code.
The bias detection framework itself. Most World Cup prediction projects stop at "here's a model." This project asks why the market disagrees with the model and names the specific cognitive biases responsible. That's a genuinely different contribution.
The interactive dashboard. Seven pages, interactive Plotly charts, match cards with predicted scorelines, waterfall bias decomposition — all served from a single self-contained Python file with zero external data dependencies.
Finding that the Star Power Premium is reversed. We expected famous squads to be overpriced. They're not. The market is actually rational about star power — it's irrational about recency and geography. That null finding is as interesting as the positive ones.
What we learned
Prediction markets are selectively efficient. They price group difficulty correctly and don't overpay for star power. But they fail on temporal biases (recency — paying for past glory) and geographic biases (ignoring continental home advantage). The crowd is smart about some things and emotional about others. The edge lives in that gap.
On the technical side: when working with AI coding agents, specificity beats description. Writing partial code and asking the agent to complete it works far better than describing what you want. The agent debates descriptions but executes code.
Also learned that xG differential is a remarkably powerful predictor for international football — better than FIFA rankings, Elo ratings, or market odds alone. The teams with the best underlying chance creation and prevention patterns are not always the ones the market favours.
What's next for Sharp or Square
Live tournament tracking. When the 2026 World Cup starts, the app should update in real time — pulling fresh Polymarket odds daily, comparing them against model predictions, and tracking which biases are correcting as the tournament progresses.
Expanded bias library. There are more biases to test: manager effect (new coach premium), squad age curves, travel distance impact, altitude advantage, and referee assignment patterns.
Backtested P&L. Building a full simulated betting portfolio: if you had followed the model's value bets across the last 3 World Cups, what would your return on investment be? That's the ultimate proof that the biases are exploitable.
Multi-sport expansion. The bias detection framework isn't football-specific. It could apply to any event where prediction markets exist alongside performance data — Olympics, tennis grand slams, cricket World Cups, even elections.
Community features. Let users input their own betting positions and see how their portfolio compares to the model's recommendations. Turn it from a read-only dashboard into a tool gamblers actually use throughout the tournament.


Log in or sign up for Devpost to join the conversation.