-
-
Performing inference on 2 macs connected to different networks.
Inspiration
Memory prices are projected to rise by over 50% this quarter, with global supply falling short of demand for the foreseeable future. Yet today’s ML and storage infrastructure remains centralized and inaccessible, leaving vast amounts of consumer-owned hardware unused.
In the U.S. alone, there are approximately 200 million gamers, roughly 30% of whom own GPUs, over 60 million GPUs in aggregate, alongside an additional ~20 million Apple Silicon Macs. Despite this unprecedented installed base, no platform effectively aggregates idle consumer compute and memory for AI inference or other compute-intensive workloads.
Inspired by the success of decentralized computing in blockchains, we are building an inference network that distributes workloads across millions of idle consumer devices, unlocking a massive, untapped compute supply.
What it does
We enable consumers to rent out their hardware, providing compute, inference, and storage at a fraction of the cost of existing platforms.
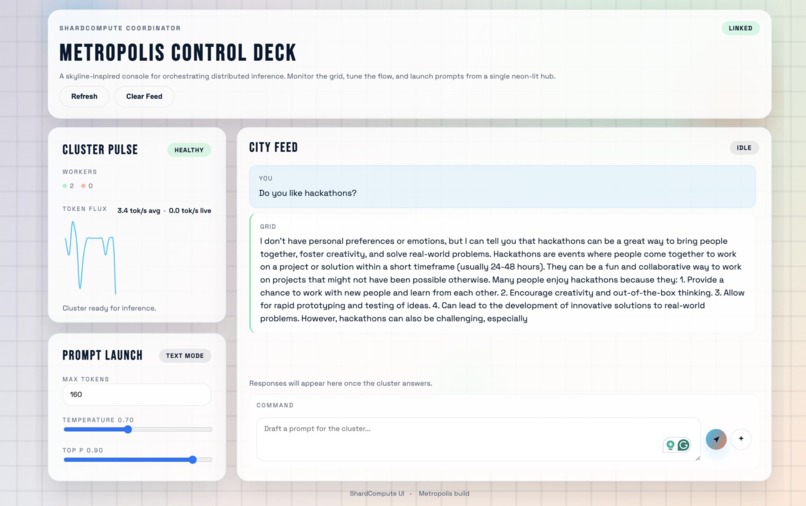
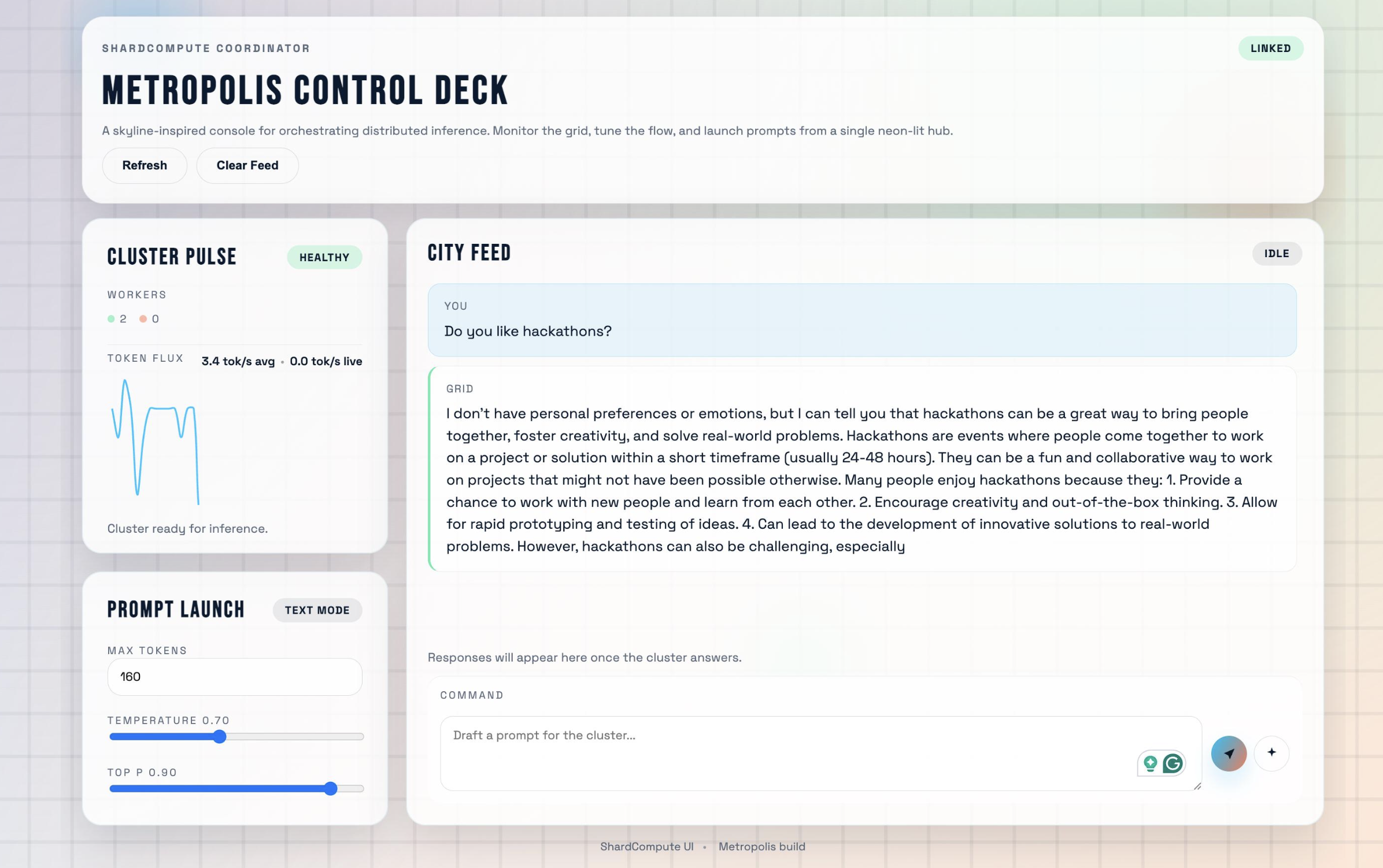
This proof of concept demonstrates large language model inference on a distributed network of MacBooks without requiring a Thunderbolt connection.
How we built it
We built ShardCompute using a coordinator and worker architecture, where each worker holds a shard of the model. Rank 0 receives requests, broadcasts parameters, and all workers compute in sync using collective operations like all-reduce and all-gather.
We connect workers with a WebSocket relay through the coordinator, allowing workers to forward tensor frames without deserializing them. We also added queue flushing to prevent stale data from causing desynchronization. This design allows heterogeneous devices, including Macs, consumer GPUs, and other systems, to perform inference over the internet and makes distributed computing accessible outside traditional clusters.
Challenges we ran into
Initially, we used TCP for communication between worker devices, but ran into frequent connection issues when operating over secured networks.
In a real-world setting, we realized TCP was not practical, so we moved coordination to AWS. We also found that tensor parallelization alone was not effective for live chat inference on a small network of Macs. To improve latency, we implemented pipeline parallelization, loading continuous model layers on each device instead of splitting tensors. This significantly improved speed and is critical for real-time chat use cases.
Accomplishments that we're proud of
Using first principles, we built the proof of concept largely from scratch and achieved a 5x improvement in inference speed for live chat.
What's next for ShardCompute
Next, we plan to extend ShardCompute to mobile phones and enable truly heterogeneous computation across the network, combining laptops, consumer GPUs, and smartphones into a single cluster. The long-term goal is to build a flexible and resilient compute network operating beyond traditional data centers.

Log in or sign up for Devpost to join the conversation.