-
-
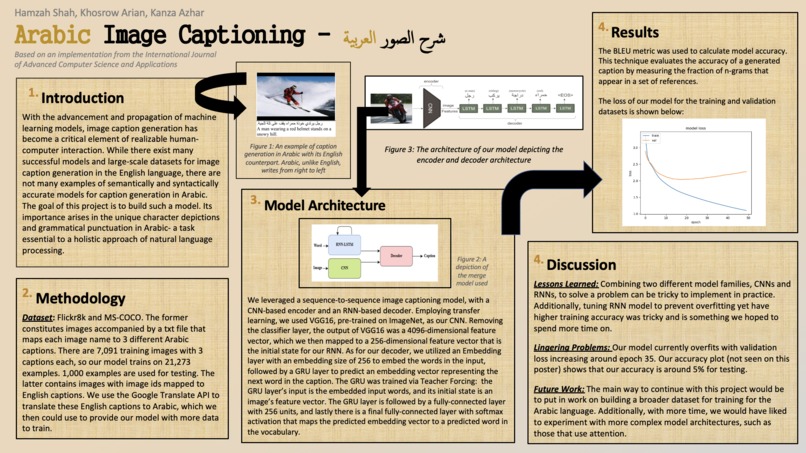
A poster depiction of our model!
Final Project Report Link: Here is the link to our final project report!
Title: A natural language processing model that generates intelligible captions for images in the Arabic language.
Who: Hamzah Shah, Kanza Azhar, Khosrow Arian
Introduction: While there has been a large amount of work done to generate English captions for images, work using deep learning to generate Arabic captions for images has been limited. As a result, we decided to pursue a project in this underexplored area. The task is a supervised learning problem. We will be re-implementing the 2020 paper entitled “Resources and End-to-End Neural Network Models for Arabic Image Captioning.” It is also worth noting that this paper is based upon the 2018 paper entitled “Automatic Arabic Image Captioning using RNN-LSTM-Based Language Model and CNN,” which has a slightly different model architecture for the same task. As a result, we could also be drawing upon this paper’s approach. The motivations for both of these papers align with our personal desire to more deeply explore the area of Arabic image captioning, bringing this beneficial service to a wider audience.
Related Work: We found a paper online that tries to implement a model for generating image captions in Arabic. The model generates image captions by trying to describe what’s in the image using CNNs and RNNs. A deep recurrent neural network for sentences and a deep CNN for images. These two networks interact with each other in a merge layer to predicate and generate the caption. We were not able to find the source code for this paper, but we found other sources online for implementing image captioning and similar projects that generate Arabic image captions using End-to-End neural networks. [Automatic Arabic Image Captioning using RNN-LSTM-Based Language Model and CNN, Image-captioning-using-CNN-RNN GitHub, Arabic-Image-Captioning GitHub Paper 1: “Resources and End-to-End Neural Network Models for Arabic Image Captioning” (2020) Paper 2: “Automatic Arabic Image Captioning using RNN-LSTM-Based Language Model and CNN” (2018)
Data: The dataset we are using comes from the Flickr8k image to caption dataset. This has been translated to Arabic captions using crowd-sourcing techniques and Google Translate API to factor in considerations specific to the Arabic language such as lexical/morphological sparsity. The dataset contains 8092 images of both animals and humans, and each image is mapped to 5 different captions. Significant preprocessing will not be required except potential padding of the inputs. The dataset can be found here.
Methodology: Our proposed model architecture, based on the 2020 paper, is a sequence-to-sequence image captioning model that utilizes a CNN as the encoder and an RNN as the decoder. The CNN serves as a feature extractor for the images, and its output is the initial state of the decoder’s recurrent network.
Employing transfer learning, we used VGG16 — pre-trained on ImageNet — for our CNN. Removing the classifier layer, the output of VGG16 was a 4096-dimensional feature vector, which we then, using a fully-connected layer, mapped to a 256-dimensional feature vector that is the initial state for our RNN. As for our decoder, we utilized an Embedding layer with an embedding size of 256 to embed the words in the input, followed by a GRU layer to predict an embedding vector that represents the next word in the caption. The GRU was trained via Teacher Forcing: the GRU layer’s input is the embedded input words, and its initial state is an image’s feature vector. The GRU layer is followed by a fully-connected layer with 256 units, and lastly there is a final fully-connected layer with softmax activation that maps the predicted embedding vector to a predicted word in the vocabulary. A predefined max length acts as the maximum length of the generated caption- caption generation halts either when an token is hit or when this maximum length is reached. For testing, we performed greedy search to generate captions - though, if we had more time, we would have also liked to perform beam search.
Metrics: For most of our assignments, we have looked at the accuracy of the model. Does the notion of “accuracy” apply for your project, or is some other metric more appropriate? [We think that there’s not a simple way to measure the accuracy of our model because the model is going to spit out a sentence as a caption. And there is not one right way to caption an image. Some captions are definitely more accurate than others. After doing some research we found a metric called BLEU-1 to measure the accuracy of our model. Therefore, we will try to use this metric as part of our stretch goal to compare the accuracy of our model to the start of art Arabic image caption model. The authors of this paper think that sparsity of annotated resources other than English is an issue in morphologically complex languages like Arabic and that was why they took a step towards the goal of developing an image caption generation model for describing images in Arabic language. Before this paper, no RNN models were proposed for image caption generation in Arabic. Even though the state of art image captioning in English is superior to the results that this paper achieves, this paper has a better performance than English-captioning -> English-Arabic-translate. Our goal is to read and understand what methods the paper is using and how the authors are implementing the project. So for our base case we want to have a working solution that captures the objects in the given image and writes a simple English caption based on what the model detects from the image. Our target goal is to try to generate captions by describing the content of the image in English and successfully convert that to Arabic language. Finally, our stretch goal is to try to improve the image captions by using transformers and generating more accurate captions. What experiments do you plan to run? Apart from testing the validity and correctness of our model using the techniques and metrics specified above, we plan on publishing our results to an open-ended crowd-sourcing platform similar to the one used to collect the dataset, and having Arabic-speaking users confirm the validity of returned captions.
Ethics: Since our project idea revolves around generating image captions for images pertaining to a dataset that contains human and animal imagery, misrepresentation and misidentification bias could result in terms of race and gender. Gender misidentification could result from the way the dataset is generated: through crowdsourcing and the Google Translate API. A crowd-sourcers bias in misidentifying a human’s pronouns might then reflect in the pronouns generated in an image caption. Additionally, racial bias could also ensue. As this article mentions, for example, Google Photos facial recognition algorithm was found to be misidentifying black people as gorillas. Another ethical issue arises from the size of the data combined with the architecture of the model. If adequate data is not available for caption generation for a particular image, the closest word to it will be referenced, but even this word could be far from the true label (as in the example of black people being misidentified as gorillas). The LSTM architecture would then compound this bias as it would consider the previous word's context and build upon it to generate the next word in the context sequence, further worsening the problem.
Division of labor: Hamzah will work on the LSTM architecture, Kanza will work on the CNN component, and Khosrow will work on preprocessing and testing. Overall, however, all 3 of us intend to contribute to all parts of the project.
Built With
- keras
- python
- tensorflow

Log in or sign up for Devpost to join the conversation.