
Inspiration
Every day, teams merge code blind. A 2-line auth change and a 200-line docs update get the same review process. Nobody knows which MRs spike CI bills until the monthly invoice arrives. Software sustainability is an afterthought. I built ShadowMerge to make risk, cost, and carbon visible — before you merge.
What it does
ShadowMerge is a multi-agent GitLab Duo Flow powered by Anthropic Claude that automatically forecasts the blast radius, CI cost, and carbon footprint of every Merge Request. Mention @ai-shadowmerge-gitlab-ai-hackathon in any MR comment, and a 4-agent pipeline activates:
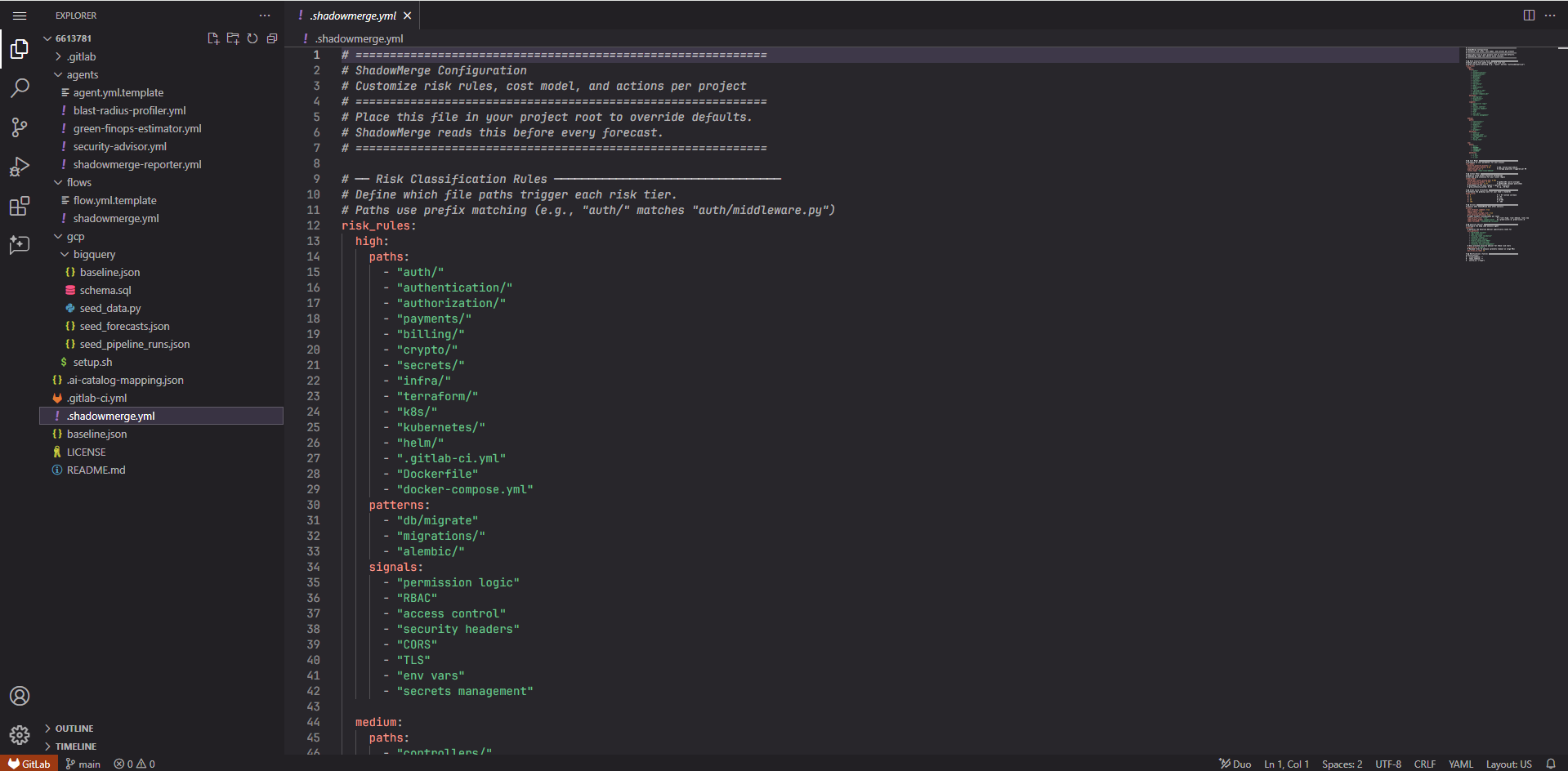
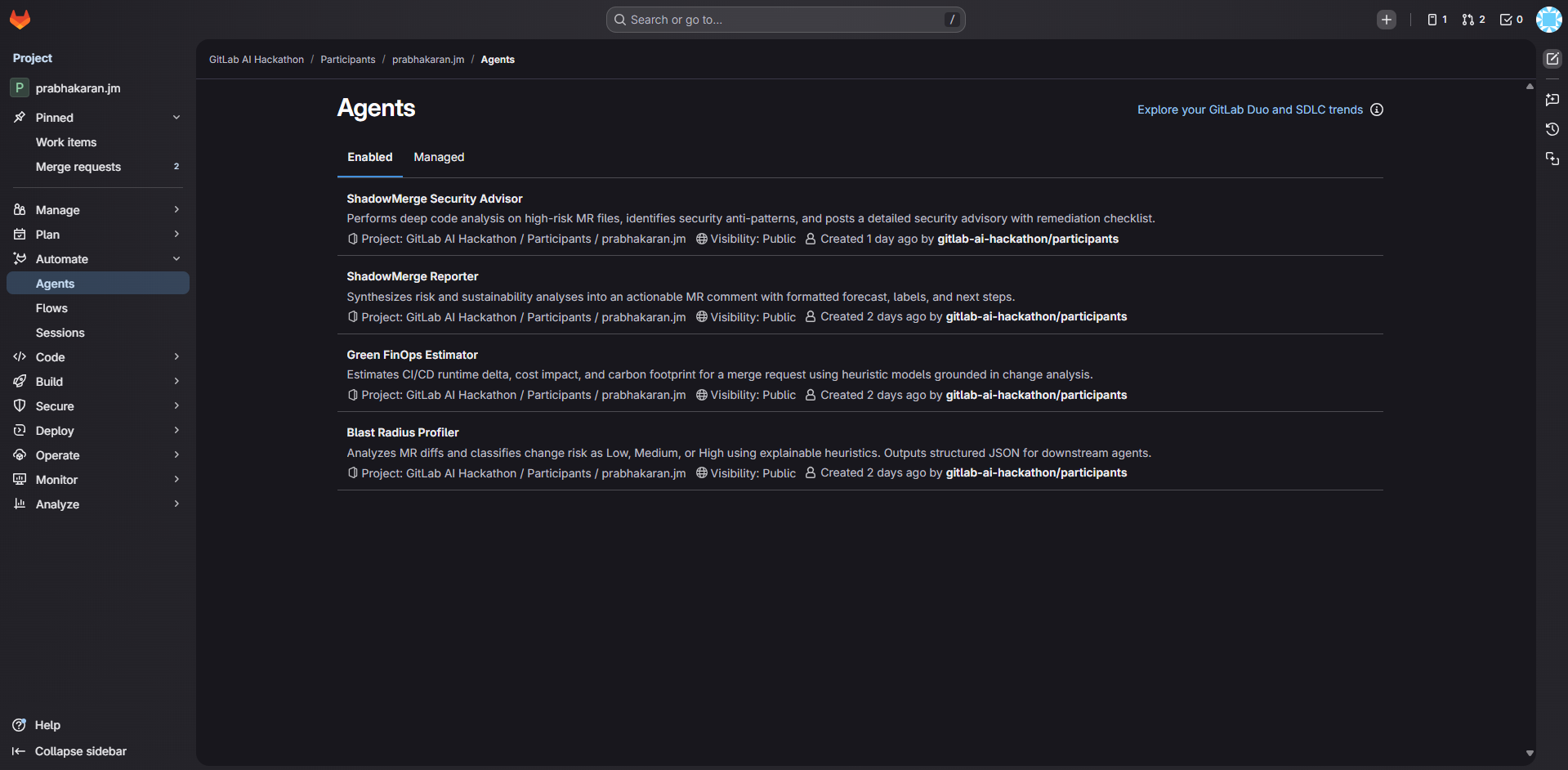
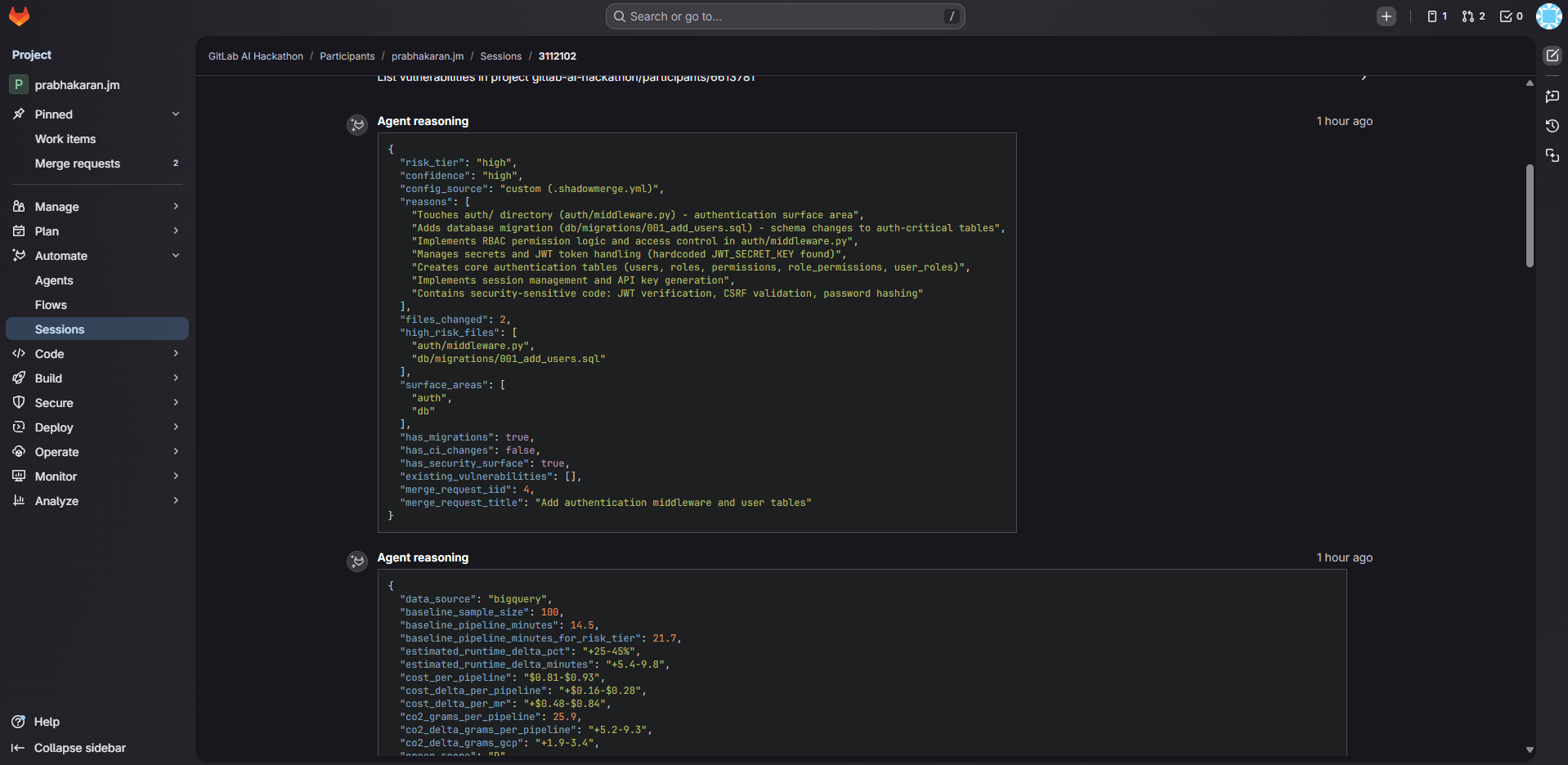
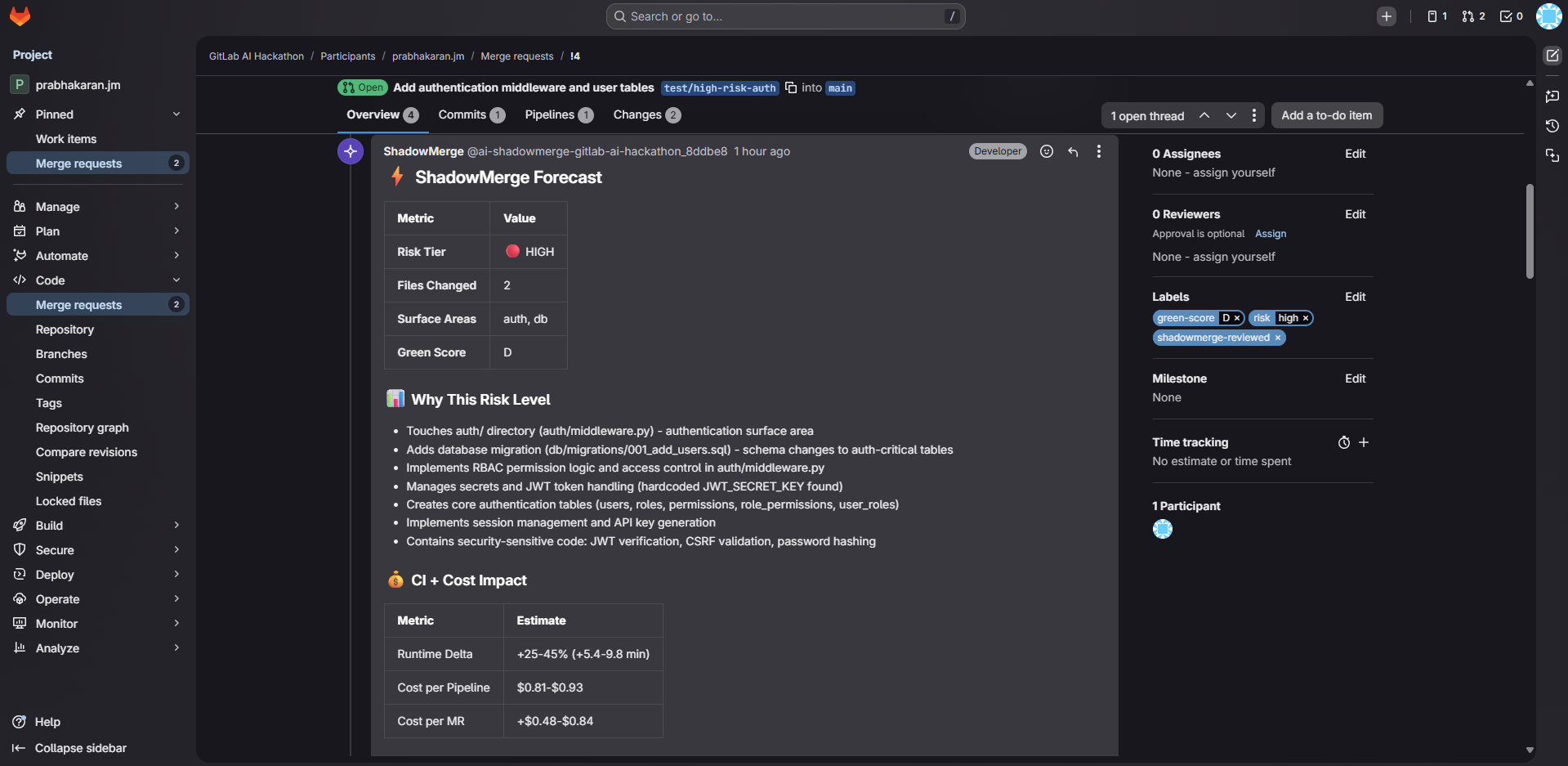
- Blast Radius Profiler — reads MR diffs, checks vulnerabilities, loads team-configurable rules from .shadowmerge.yml, classifies risk (LOW/MEDIUM/HIGH)
- Green FinOps Estimator — reads historical pipeline baselines, forecasts CI runtime delta, pipeline cost, and CO₂ using Cloud Carbon Footprint methodology
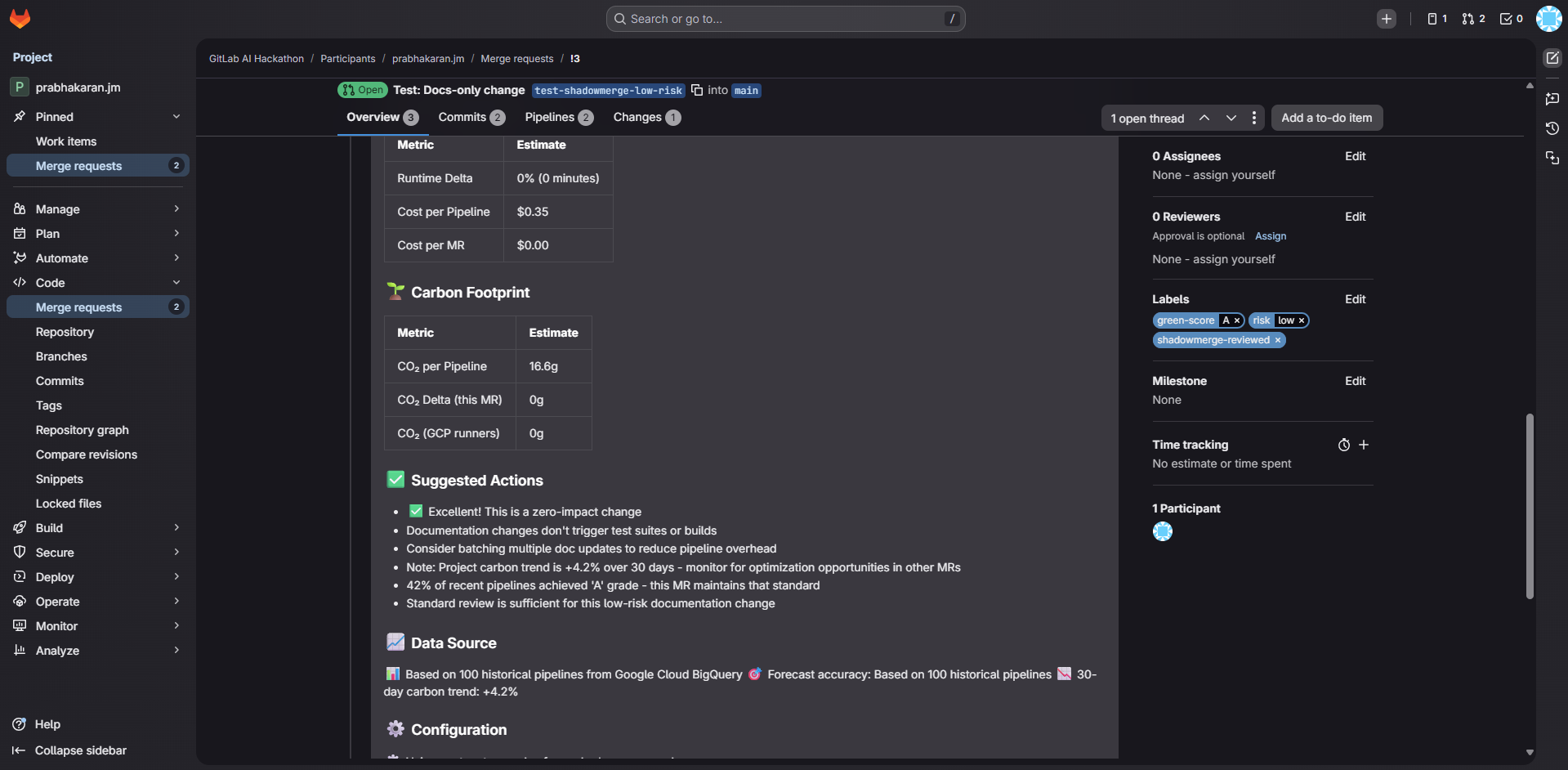
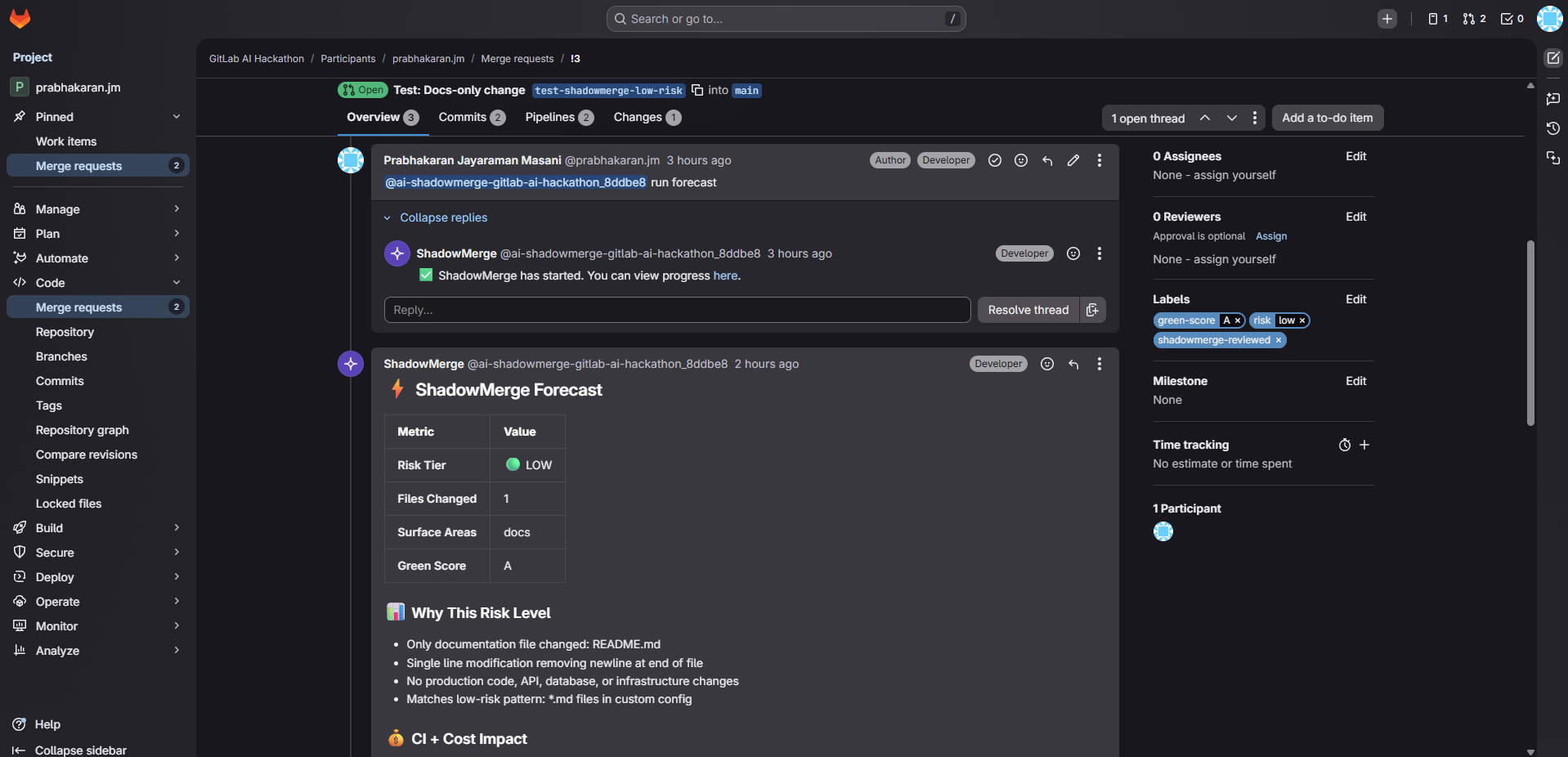
- ShadowMerge Reporter — posts a formatted forecast comment, auto-labels the MR (risk tier + green score), creates a security tracking issue for HIGH risk MRs
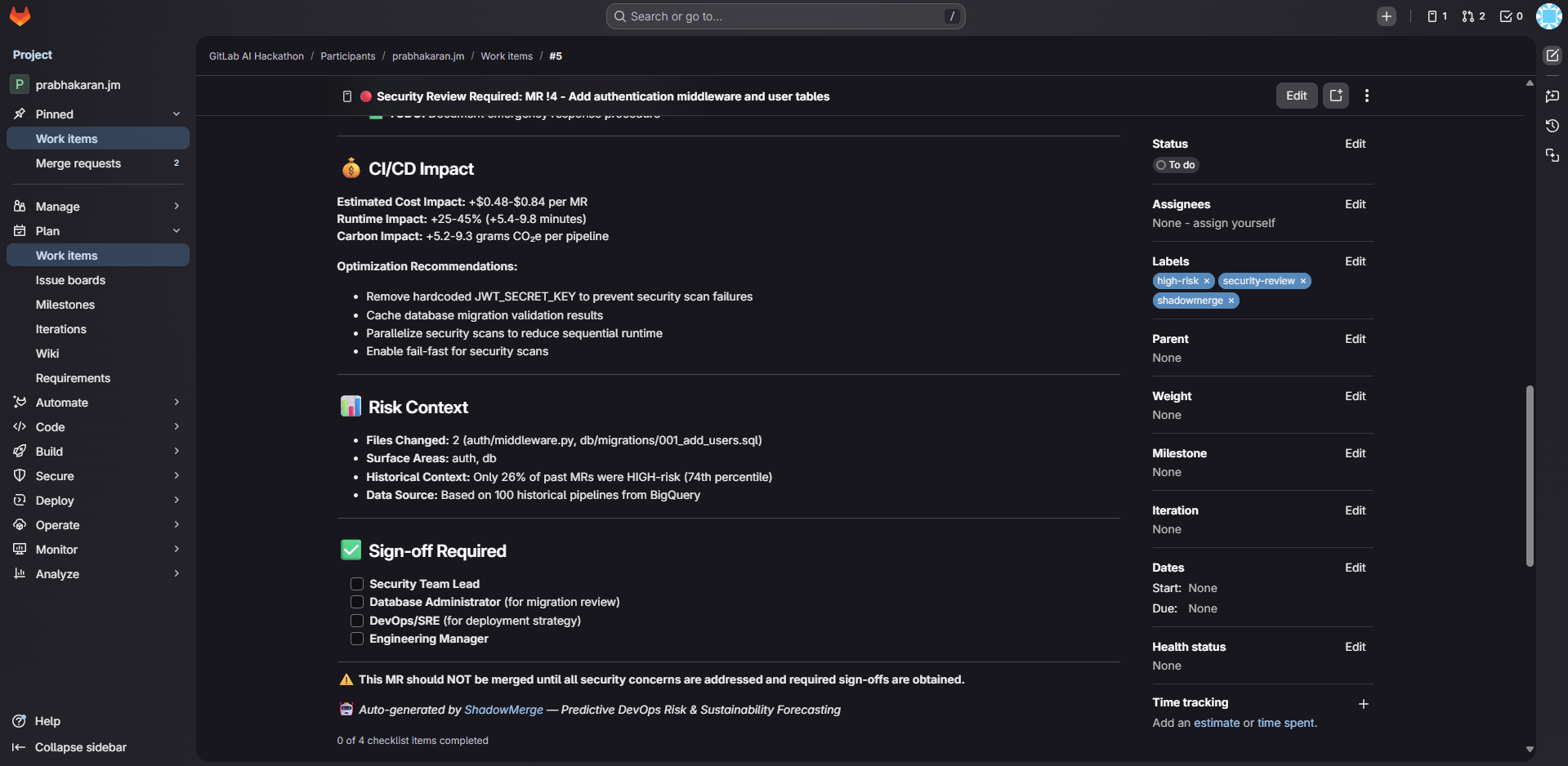
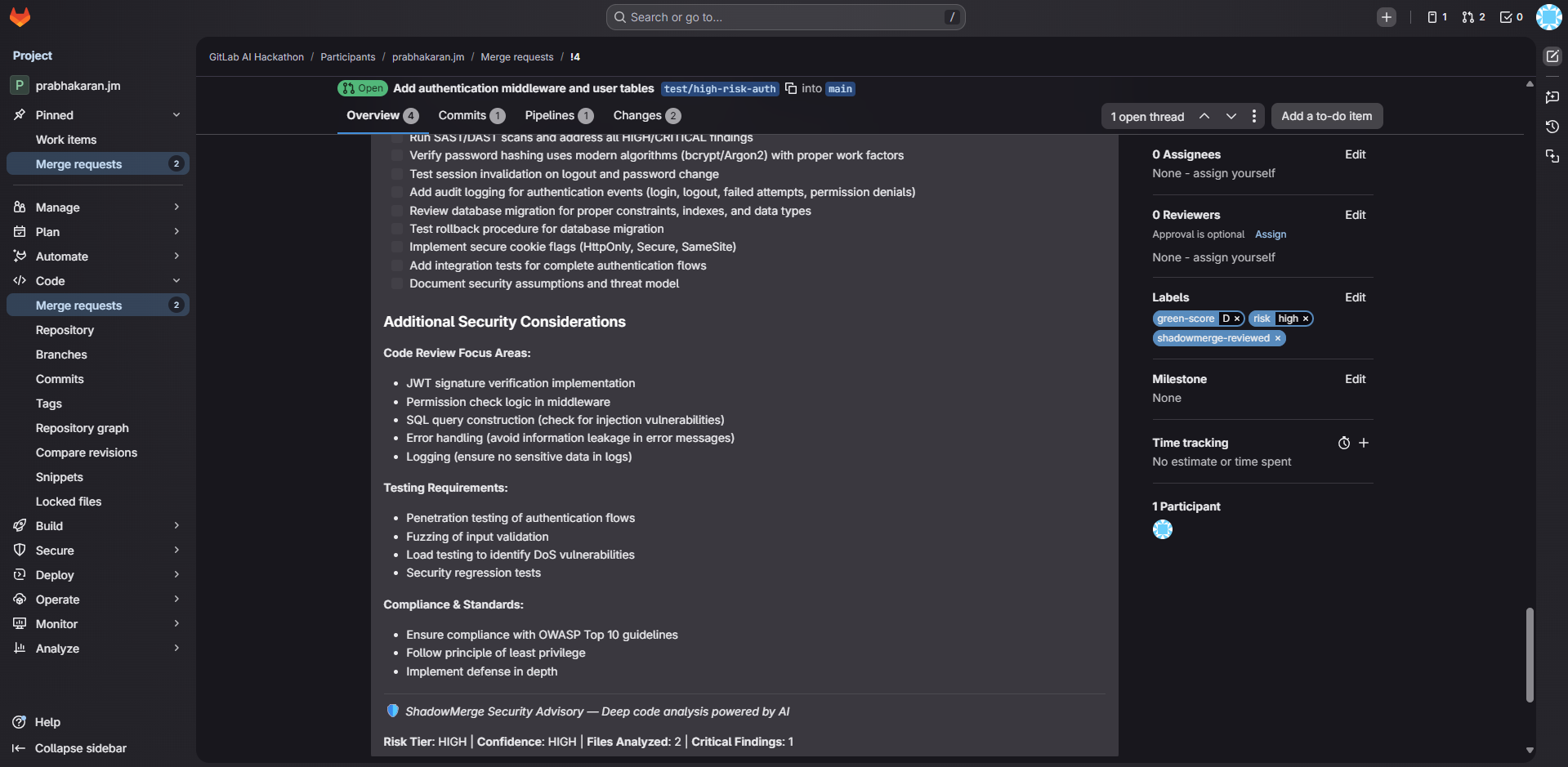
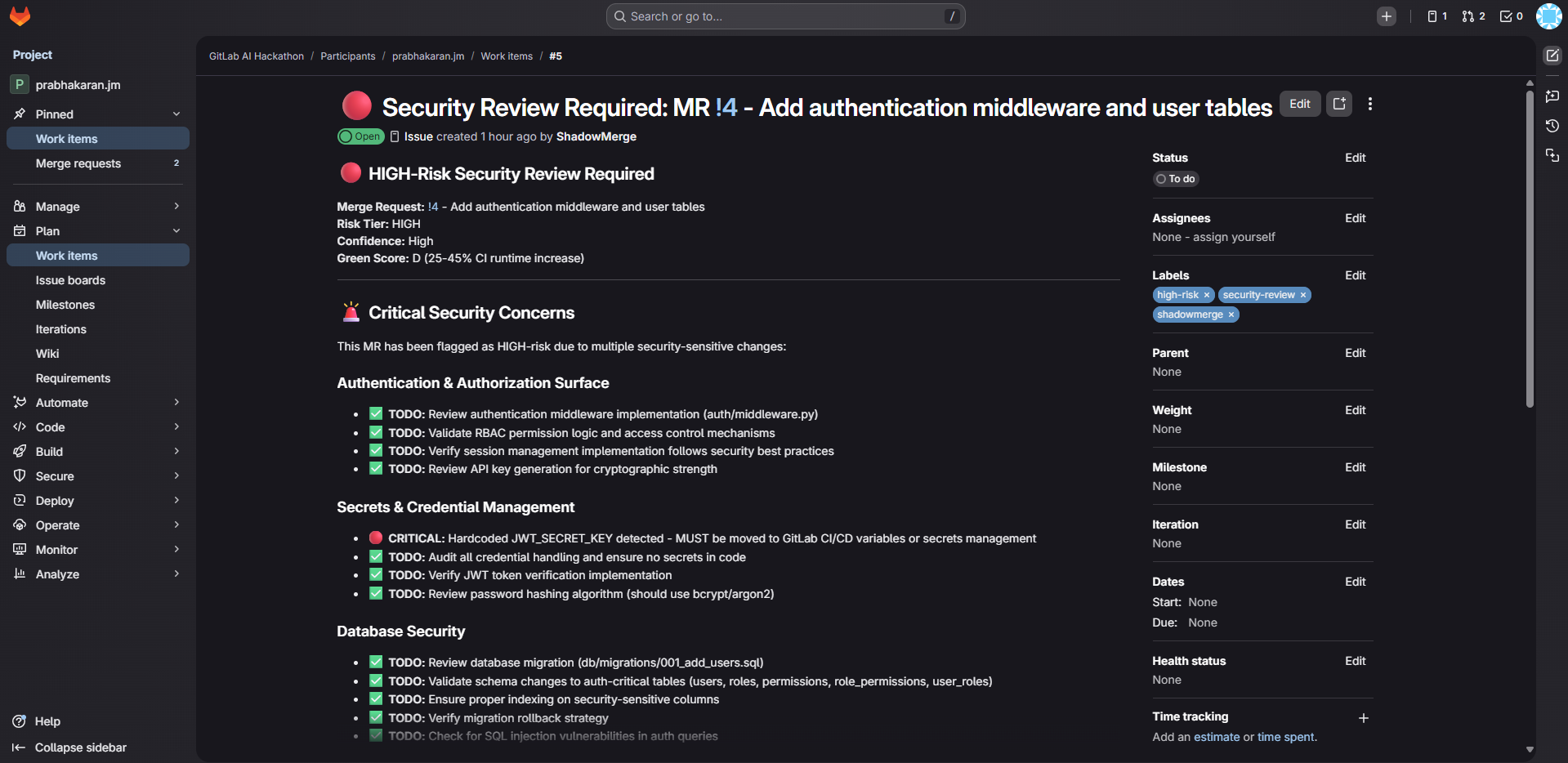
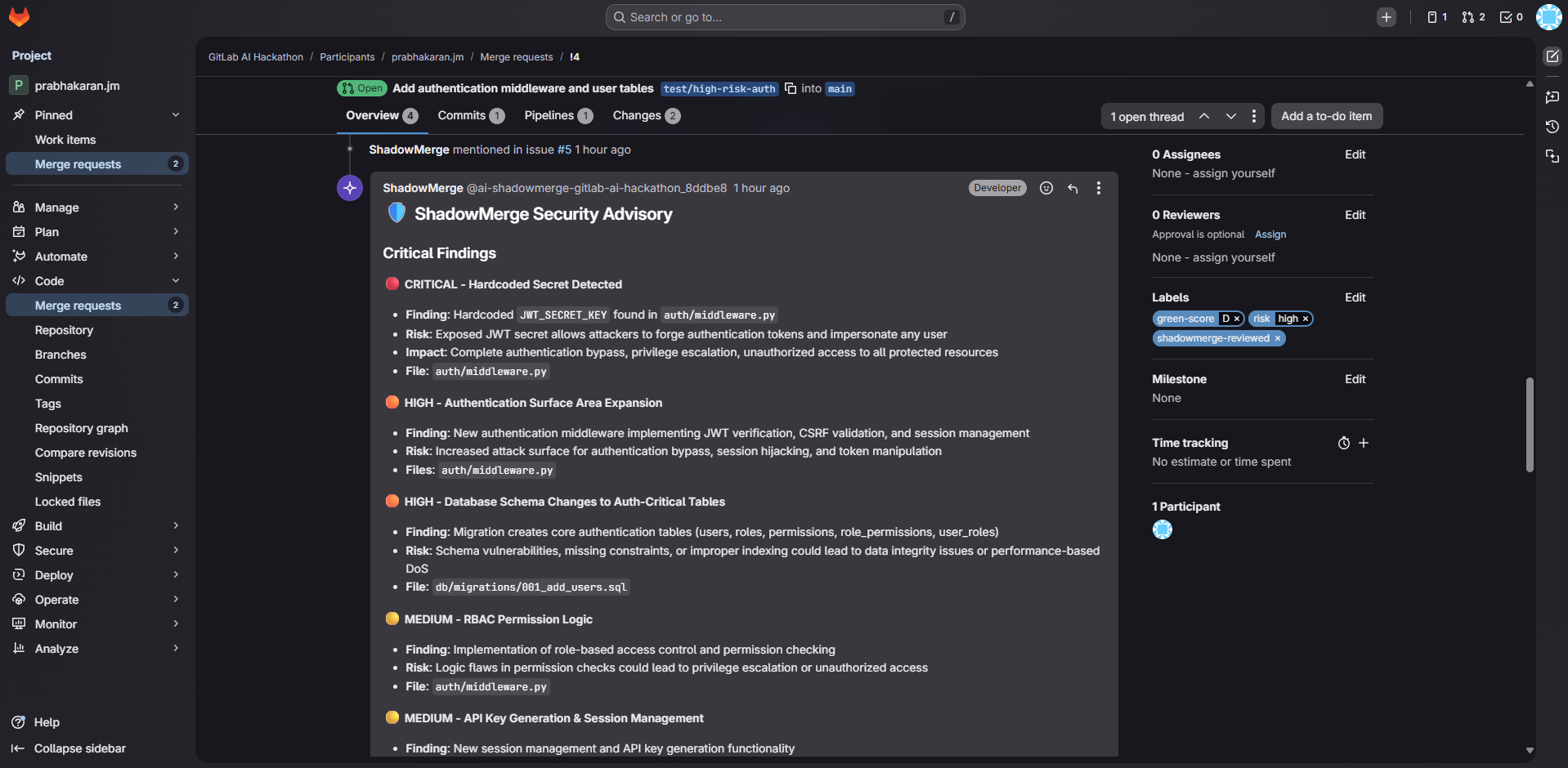
- Security Advisor — reads actual high-risk source code files, identifies anti-patterns (hardcoded secrets, SQL injection, missing auth), assigns CVSS severity ratings, posts a detailed security advisory with remediation checklists
For a high-risk MR, ShadowMerge takes 7 automated actions: forecast comment, 3 labels, security issue, and security advisory comment.
How I built it
I used the GitLab Duo Agent Platform with 4 specialized Claude-powered agents orchestrated in a sequential flow. Each agent's output feeds the next via context:{name}.final_answer, enabling true multi-agent data passing — not just parallel calls.
The key architectural decisions:
- Structured JSON contracts between agents: Agent 1 outputs a strict risk JSON schema, Agent 2 consumes it and outputs a finops JSON schema, Agent 3 reads both to generate actions. This chain-of-reasoning pattern lets each Claude agent build on the previous one's analysis.
- Configurable behavior: Teams drop a .shadowmerge.yml file in their repo to customize risk rules, cost parameters, carbon intensity, and which actions ShadowMerge takes. The Blast Radius agent reads this config before every analysis.
- Conditional execution: The Security Advisor only activates for HIGH risk MRs — Claude checks the risk tier and skips gracefully for low/medium, avoiding unnecessary processing.
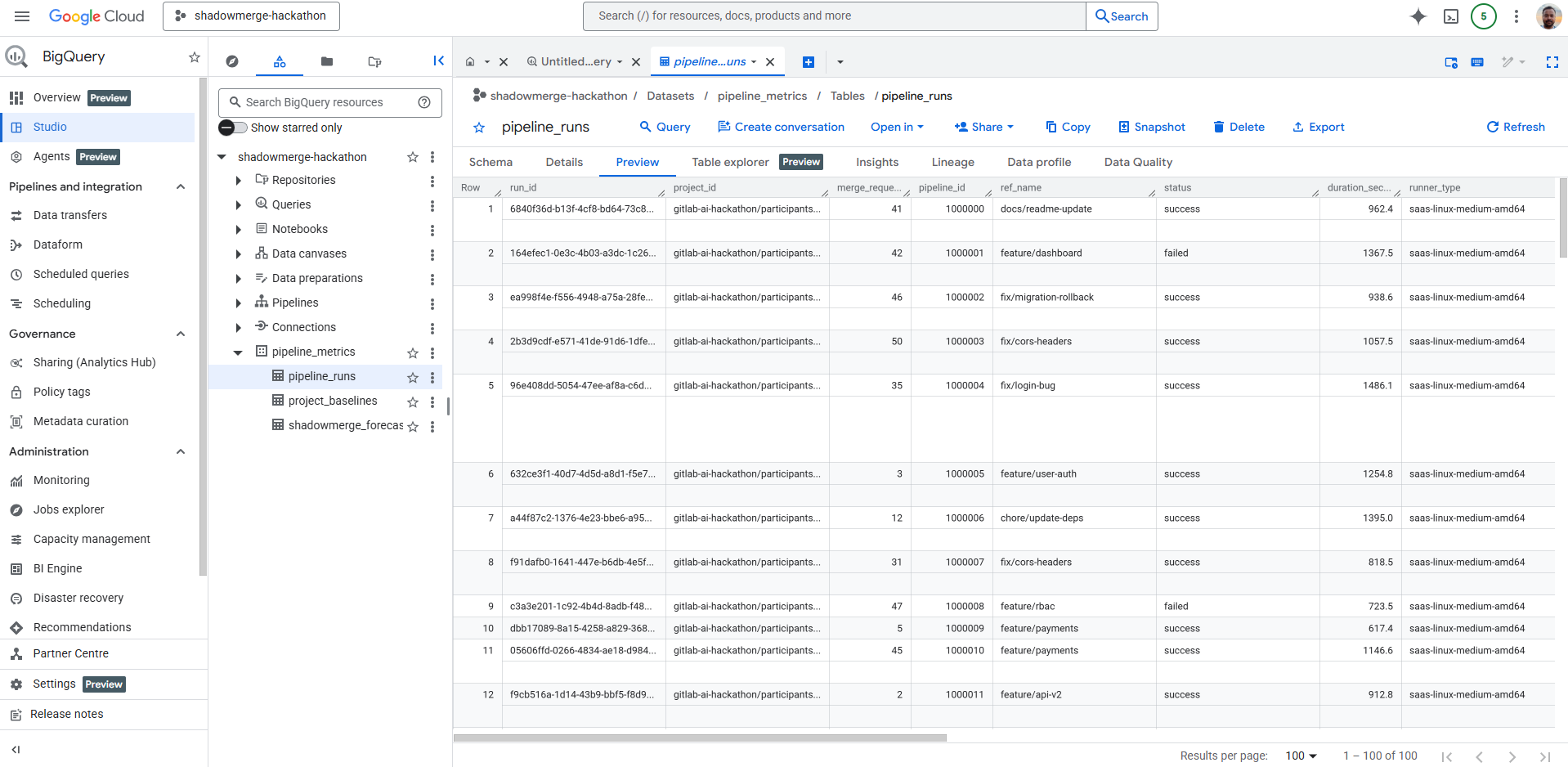
- Historical baselines: The Green FinOps agent reads baseline.json for data-driven estimates instead of static heuristics, with a BigQuery pipeline architecture designed for production deployment.
Carbon estimation follows Cloud Carbon Footprint methodology: energy per runner-minute (0.003 kWh) × grid carbon intensity (0.475 kgCO₂e/kWh global, 0.177 for GCP runners).
Challenges I ran into
- Context passing: The biggest challenge was getting agents to access the MR. The flow's context:project_id needed to be explicitly passed as input to every component, and prompts had to instruct agents how to extract the MR IID from the trigger context.
- Structured output enforcement: Getting Claude to consistently output valid JSON across 4 agents required careful prompt engineering with explicit schema definitions and "Output ONLY this JSON" constraints.
- Sandbox limitations: The hackathon sandbox blocks external MCP servers (GITLAB_WORKFLOW_SANDBOX=true), so BigQuery integration works via baseline file with CI pipeline architecture ready for production.
- Catalog sync: The .ai-catalog-mapping.json file caused pipeline failures when agent files were renamed — required manual cleanup and re-tagging.
Accomplishments that I'm proud of
- 4-agent sequential flow with real structured data passing between Claude agents
- 7 automated actions on high-risk MRs (comment, 3 labels, issue, security advisory)
- Claude performing deep code analysis — reading actual source files, identifying CVSS-rated vulnerabilities, generating specific remediation steps
- Team-configurable risk rules via .shadowmerge.yml — not a one-size-fits-all tool
- Green Score (A-F) with per-MR carbon footprint estimates and historical trend tracking
- Production-grade GCP architecture with Workload Identity Federation and BigQuery schema
What I learned
- Anthropic Claude excels at multi-step reasoning chains — having 4 agents pass structured data creates surprisingly sophisticated analysis compared to a single prompt
- Prompt engineering for structured JSON output requires explicit schema definitions, "ONLY this JSON" constraints, and careful field naming
- The context:{component}.final_answer pattern enables powerful multi-agent pipelines but requires careful coordination of data contracts between agents
- Making carbon footprint visible per-MR is surprisingly actionable — developers immediately start asking "how do I get a better Green Score?"
- Configurable risk rules (.shadowmerge.yml) are essential for real-world adoption — every team has different risk thresholds
What's next for ShadowMerge
- ML-powered predictions: Train a model on historical pipeline data to replace heuristic multipliers with learned patterns
- Slack/Teams integration: Real-time notifications for HIGH risk MRs
- Team dashboards: Visualize risk distribution and carbon trends using auto-applied labels
- Auto-suggest reviewers: Assign reviewers based on risk surface areas (auth expert for auth changes)
- Custom risk rules marketplace: Share .shadowmerge.yml templates across teams

Log in or sign up for Devpost to join the conversation.