-
-
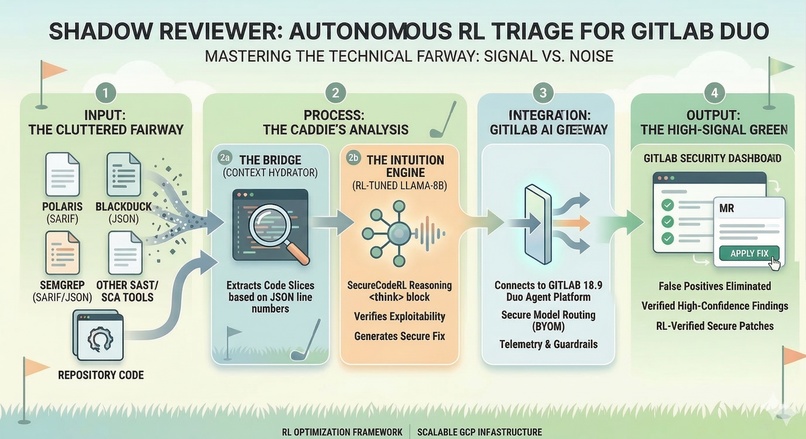
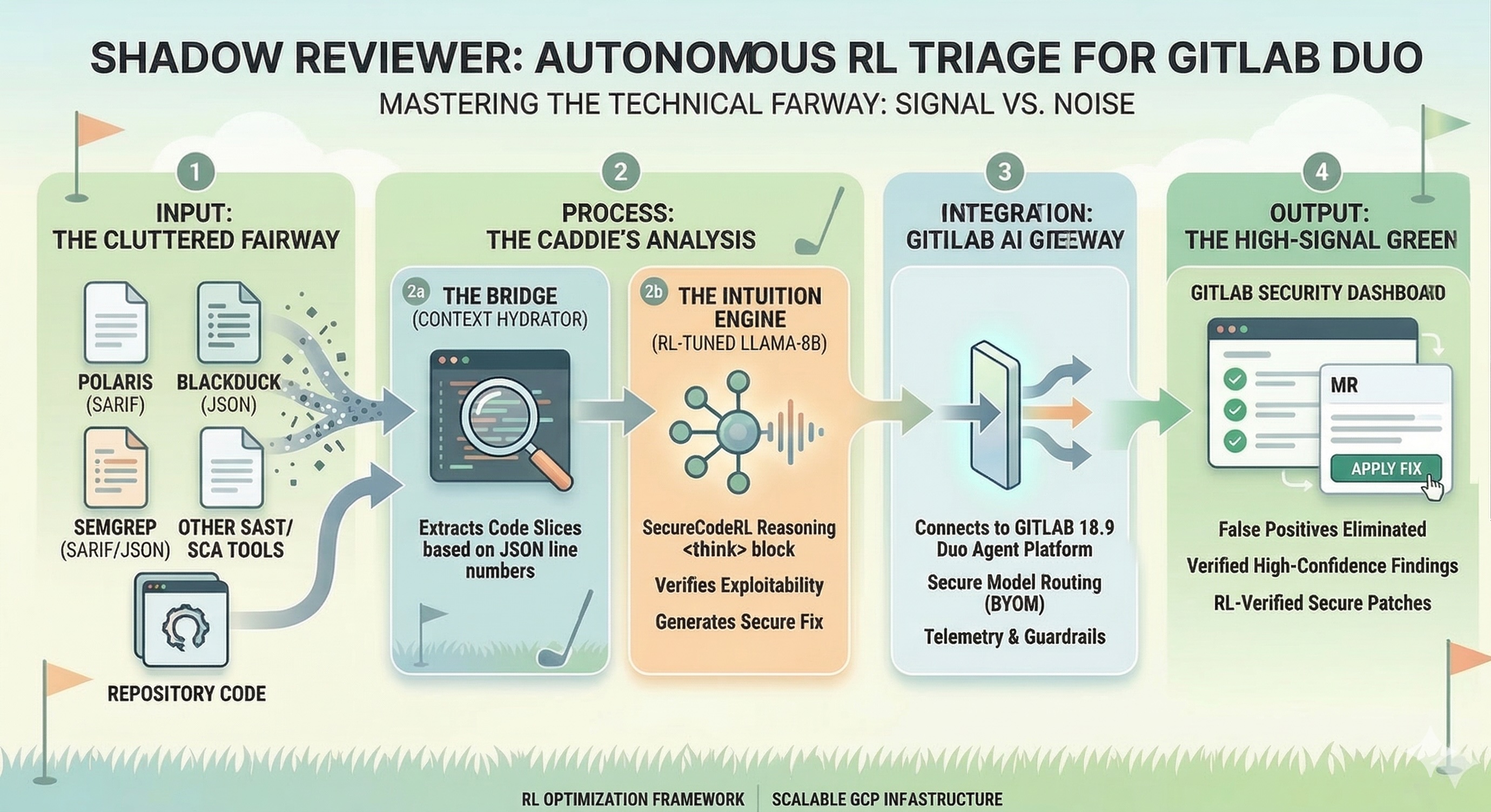
Shadow Reviewer Architecture Flow Diagram
-
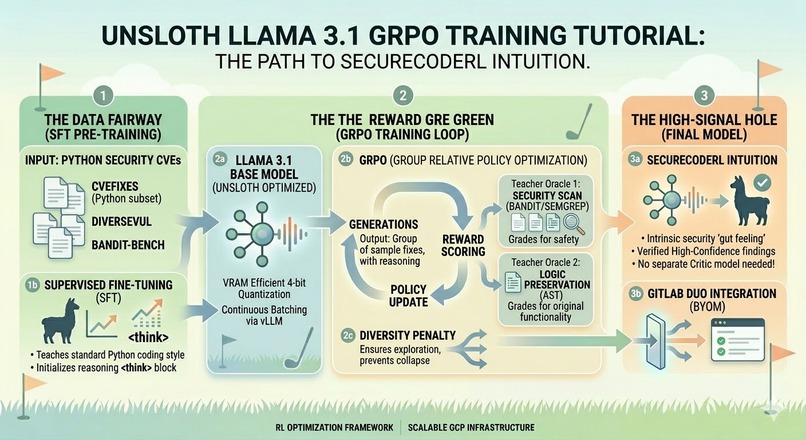
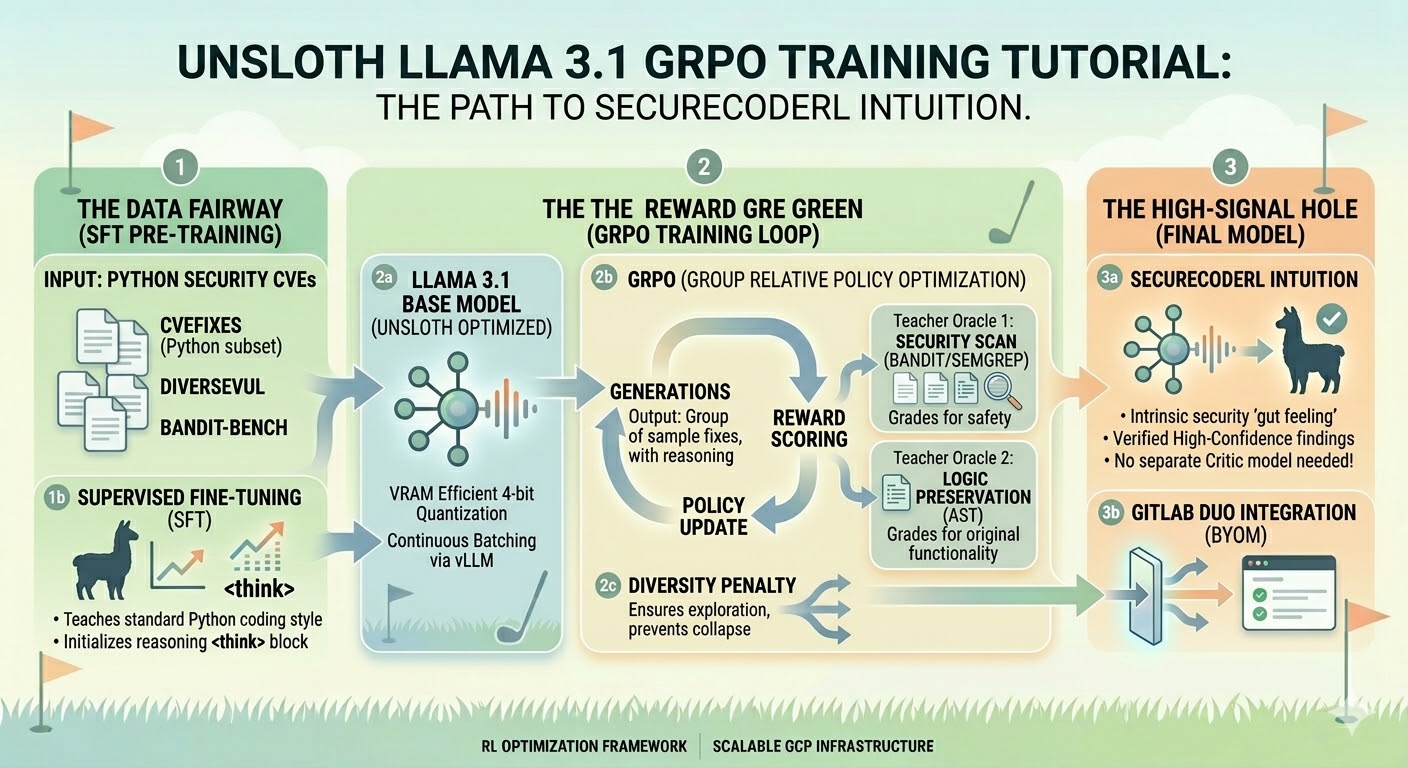
ULSLOTH LLAMA 3.1 GRPO Training Tutorial
-

Difference between LLM vs RL Shadow Reviewer with example

Inspiration
Modern security scanners are built for coverage, not actionability. They generate noise — findings that developers learn to ignore. Shadow Reviewer is built to reason about vulnerabilities the way a security engineer would: understanding context, distinguishing real risk from false positives, and proposing fixes with rationale.
What it does
Shadow Reviewer is an autonomous security review agent integrated into GitLab Duo. Triggered by an @mention in any merge request, it reads the MR diff via the GitLab API and produces a three-stage review:
- Detection — vulnerability identification with CWE classification and line evidence
- Fix Proposal — concrete patch-level fix with defense-in-depth rationale
- Verification — checklist of what to test, residual risk summary, and a clear MERGE / DO NOT MERGE recommendation
Algorithm: GRPO (RL policy gradient) Framework: Unsloth + TRL (GRPOTrainer) Efficiency: LoRA + 4-bit NF4 quantization Base model: DeepSeek-R1-Distill-Llama-8B Reward: ** Semgrep + Bandit (automated SAST oracle) **Hardware: GCP Vertex AI Workbench (NVIDIA L4, 24GB)
How we built it
The agent is built on the GitLab Duo Agent Platform using a custom flow that calls get_merge_request and list_merge_request_diffs to gather diff context, then reasons over the findings using Claude via GitLab Duo.
The underlying model is a Llama-8B base fine-tuned using GRPO (Group Relative Policy Optimization) via Unsloth on GCP Vertex AI with an NVIDIA L4 GPU. GRPO was chosen specifically because it eliminates the need for a separate critic model, making high-quality RL training viable on a single-GPU budget. The reward oracle uses Bandit and Semgrep as deterministic ground truth — the model is rewarded for producing code that passes SAST checks while preserving program logic.
Training data was generated through mutation-based synthesis across five CWEs (CWE-22, CWE-78, CWE-89, CWE-798, CWE-918), supplemented with real-world vulnerable/fixed pairs from CVEfixes. The serving infrastructure is a custom FastAPI container deployed on Vertex AI, designed for integration with the GitLab Duo Agent Platform via MCP.
Challenges
The biggest challenge was the language mismatch. Classic security datasets like Juliet and Big-Vul are almost entirely C++ and Java. The reward oracles (Bandit, Semgrep) and the agentic stack (Unsloth, TRL) are Python-focused. The pivot to CVEfixes for real-world Python vulnerable/fixed pairs was necessary to get a meaningful training signal.
A secondary challenge was reward signal quality. Without Semgrep and Bandit installed in the training environment, the reward function collapses to syntactic validity only. Ensuring the full SAST oracle was available during training was critical to the model learning security reasoning rather than just syntax.
Accomplishments
- Successfully training a security-specialized model using GRPO with SAST tools as the reward oracle
- Building a working GitLab Duo flow that detects context-dependent vulnerabilities — open redirects, stored XSS, race conditions — that static analysis tools miss
- Deploying a complete serving pipeline on GCP Vertex AI with a LoRA adapter loading architecture
What we learned
For security, reasoning in the weights is more reliable than context in a prompt. A model that understands why code is broken generalizes better than one pattern-matching against examples. The quality of the reward function matters more than the size of the dataset — weak reward signal produces a model that games the metric rather than learning security.
What's next
- MCP integration — replace the baseline Claude model with the fine-tuned security specialist in the live flow
- Multi-language expansion — Java and C++ support via SpotBugs and Cppcheck reward oracles
- Multi-agent orchestration — specialized agents for SAST, SCA, and DAST
- Autonomous remediation — moving from triage to automatically opening MRs to fix high-confidence vulnerabilities
Built With
- agent
- bandit
- ci/cd
- deepseek-r1-distill-llama-8b
- duo
- fastapi
- gcp
- gcs
- gpu
- grpo
- javascript
- l4
- mcp
- nvidia
- peft
- python
- pytorch
- semgrep
- transformers
- trl
- unsloth
- vertexai
Log in or sign up for Devpost to join the conversation.