Inspiration
AI tools today are very good at generating ideas and very bad at challenging them.
I wanted to build a tool that did the opposite: one that didn't hand you an answer, but exposed where your thinking was weak, what your plan quietly depended on, and what you'd need to learn before you committed.
What it does
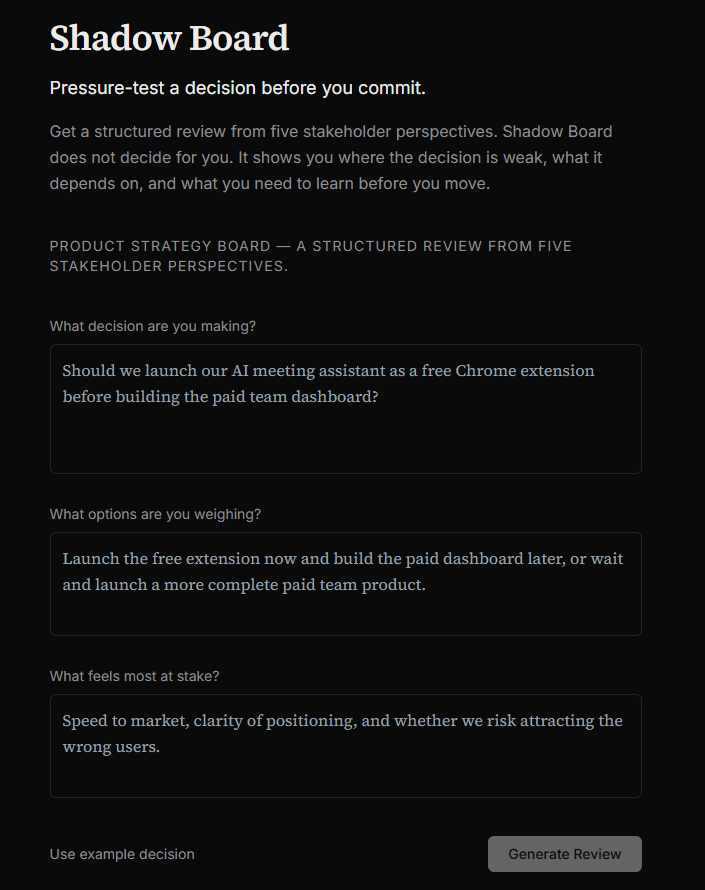
Shadow Board pressure-tests a single decision against five fixed stakeholder perspectives:
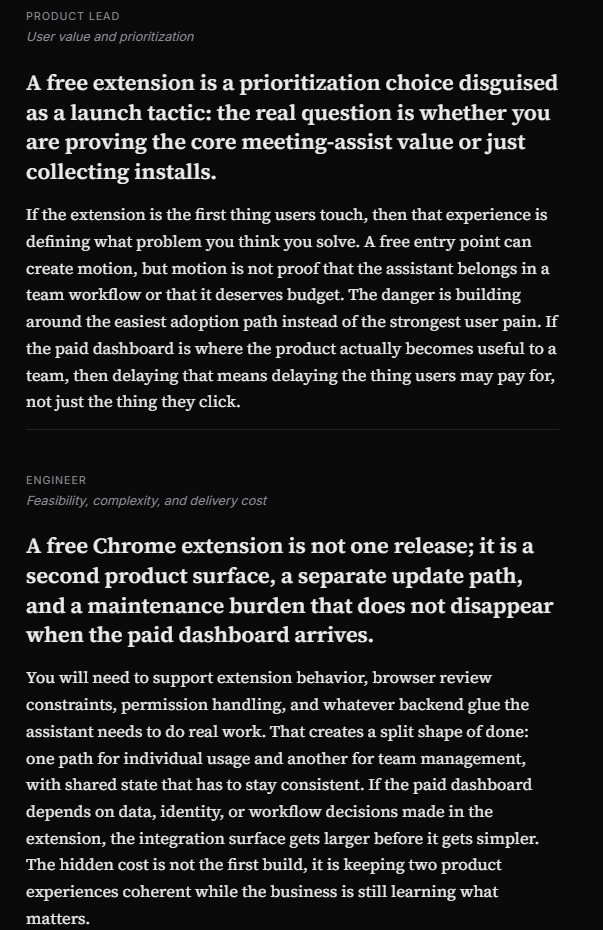
- Product Lead
- Engineer
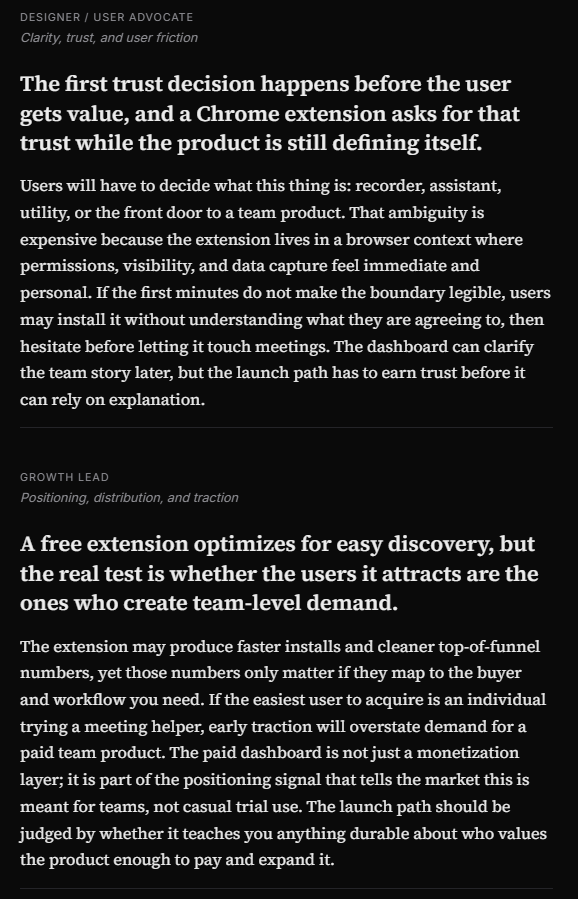
- Designer / User Advocate
- Growth Lead
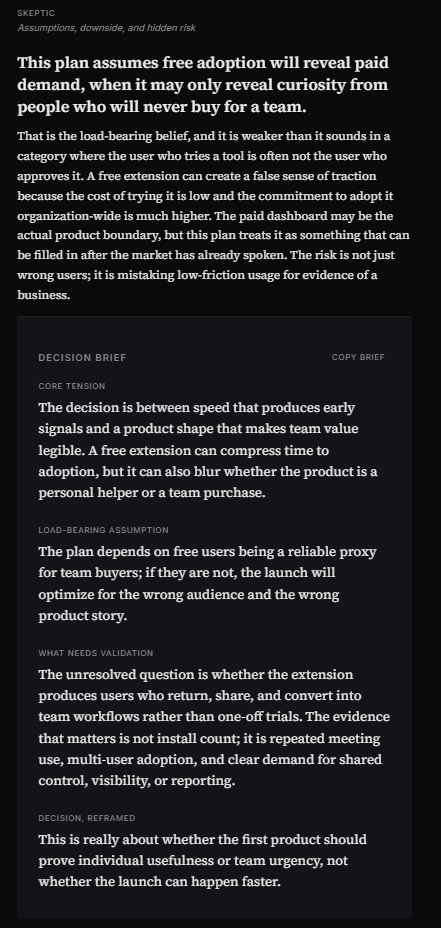
- Skeptic
It then closes with a four-part Decision Brief that names:
- The real tradeoff
- The load-bearing assumption
- The key unknown
- A one-line reframe of the decision
Crucially, there is no verdict.
No "ship it."
No "don't ship it."
The product's job is to sharpen the user's thinking, not replace it.
How I built it
The whole project was built spec-first.
Before writing any code, I wrote four planning docs in sequence:
[scope.md](http://scope.md)— product identity, what's done, what's deliberately cut[prd.md](http://prd.md)— operationalized behaviors and shipped copy[spec.md](http://spec.md)— technical blueprint: data contracts, state machine, prompt architecture[checklist.md](http://checklist.md)— a 17-item, phase-numbered build plan
Then I executed the checklist in order:
- Foundations
- API route
- End-to-end sanity slice
- Production UI
- Polish
- Deploy
The stack is intentionally boring:
- Next.js 16 App Router
- TypeScript
- Tailwind
- One server route
- One OpenAI call per generation
- No database
- No global state library
- No animation library
The five voices are produced by a single gpt-5.4-mini call using the OpenAI SDK's strict structured-output helper.
A Zod schema enforces a fixed-shape object, not an array, so partial-failure cases collapse cleanly to "fail the whole response."
The full planning trail is committed to the repo under docs/.
Challenges I ran into
Voice distinctiveness as a prompt-design problem.
Five "stakeholders" in one schema can easily collapse into five paraphrases of the same opinion. I wrote per-voice "voice cards" with explicit lens, anti-patterns, and example position-statement registers, not verbatim lines. I also added a banned-phrases list to keep the editorial tone calm and quotable.Resisting the easy answer.
Every iteration tempted me toward a final recommendation at the end. I held the line: the Decision Brief reframes the decision but never tells the user what to do.Making "loading" feel like deliberation.
A spinner would have undone the product's tone. I wrote five rotating status lines, one per voice. I enforced a 4-second minimum floor so the response never snaps in too fast. At 20 seconds, the UI shifts to a calmer "this is taking longer than expected" line. The rotation stops because continuing to announce specific voices after 20 seconds reads as performative.Failing cleanly.
Partial output is no output. A single missing voice or malformed Decision Brief field is treated as total failure rather than rendered with a broken section. There's a server-side retry-once and a client-side defensive re-parse before any review reaches the screen.
Accomplishments that I'm proud of
- An MVP that ships with intent: editorial, dark, calm, no dashboard chrome.
- Five voices that have earned, non-overlapping angles on the hero demo prompt. No two voices say the same thing in different words.
- A Decision Brief that ends with a reframed decision the user can quote.
- A complete, public planning trail in
docs/. Anyone can see the spec it was built from, not just the final code.
What I learned
Spec-driven development pays off in hours, not weeks.
Writing scope, PRD, and spec before any code surfaced architectural decisions early: fixed-shape schema vs. array, stale-on-edit semantics, and partial-failure rules. Those would have caused real bugs if discovered during the build.For structured AI output, schema discipline is load-bearing.
Letting the model "shape" output, then validating in code, is much weaker than enforcing the shape via JSON Schema and treating any deviation as failure.Prompting voice distinction is mostly an anti-pattern problem.
Telling the model what not to say, through banned phrases, no paragraph-length filler, and no cross-voice references, did more for tone than positive instructions.Tone is a systems problem.
Typography, copy, timing, error states, and prompt design all have to point in the same direction. One dashboard-y decision anywhere undoes the others.
What's next for Shadow Board
- Two more boards: Startup Launch Board and Hiring Board, each with five prompt-engineered voices to the same discipline.
- Streaming generation: voices stream in one at a time for a stronger "deliberation" demo moment.
- Per-voice regenerate when one voice lands weak.
- Session history in local storage, so users can flip between recent runs.
- Export to PDF or markdown beyond the current Copy Brief.
- Decision Brief sharing via shareable URL or snippet.
Built With
- gpt
- next.js
- openai
- react
- tailwindcss
- typescript
- vercel
- zod

Log in or sign up for Devpost to join the conversation.