


Inspiration
Every major business decision — acquisitions, market expansions, product pivots — goes through a board of directors. But most companies can't afford a room full of senior executives debating every strategic move. What if AI could simulate that boardroom?
Shadow Board was born from a simple question: Can multiple AI agents, each with distinct expertise, produce better strategic analysis than a single AI assistant? We believed that by making agents debate, challenge, and stress-test each other's reasoning, just like real board members do, we could surface risks and opportunities that a single-perspective analysis would miss.
As a first-generation CS graduate student from a small town in India, I've seen how access to strategic advisory is limited to well-funded companies. Shadow Board democratizes executive-level strategic analysis; any startup founder, any small business owner can now convene an AI-powered board of directors.
What it does
Shadow Board is a multi-agent AI executive decision-making simulation in which 5 specialized AI agents (CFO, CMO, Legal Counsel, Devil's Advocate, and Board Moderator) engage in structured, real-time debate over strategic business decisions.
The full flow:
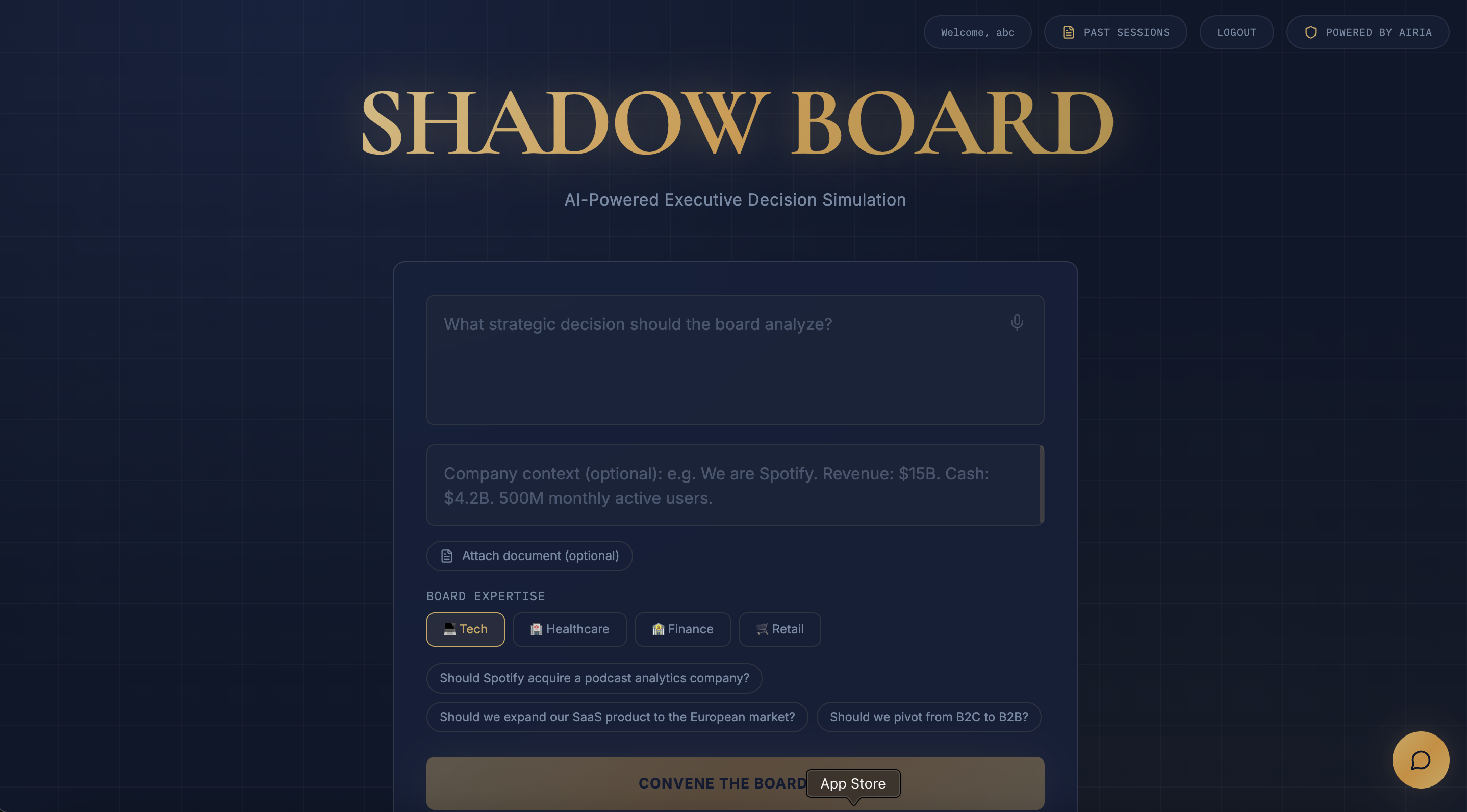
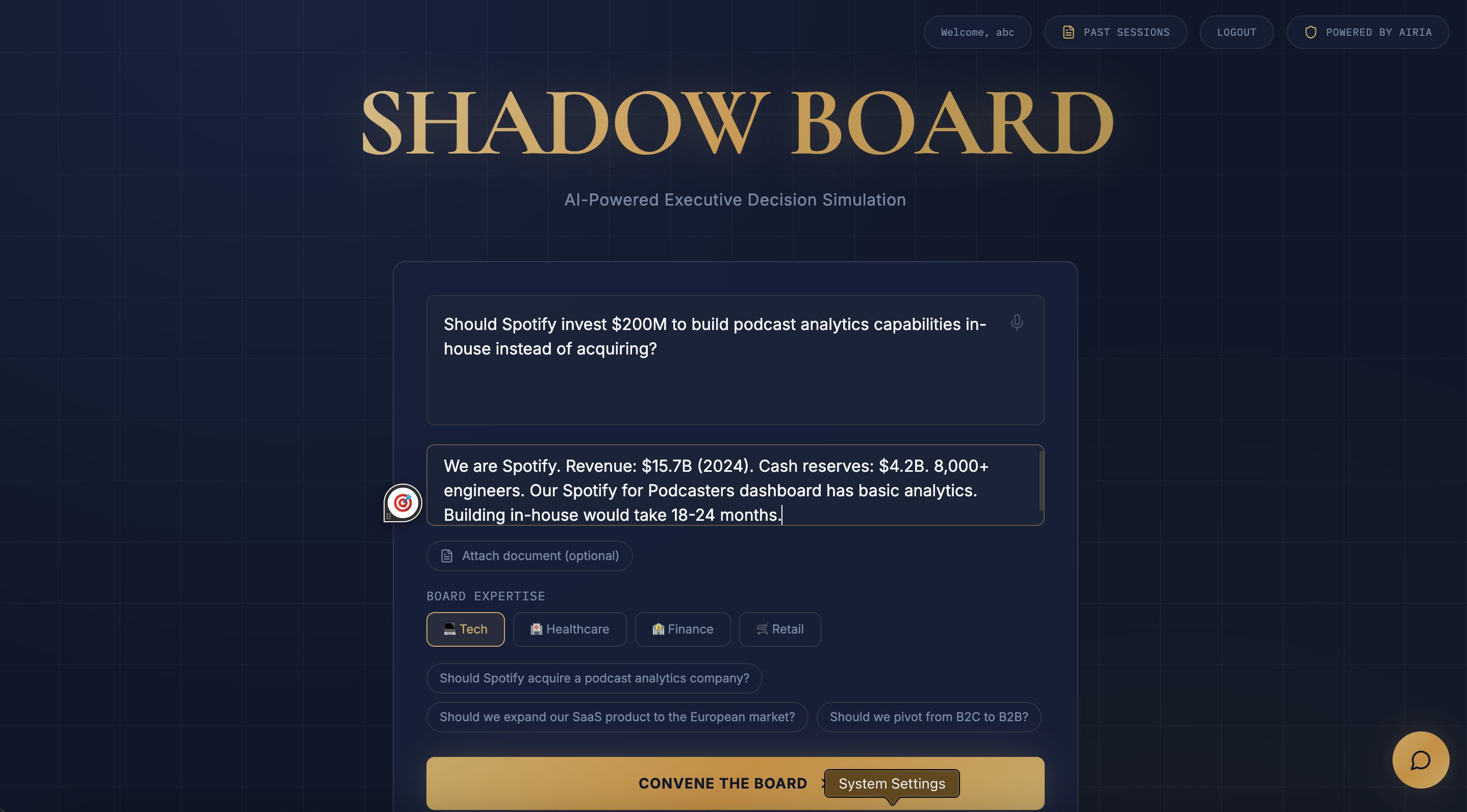
- User signs up/logs in (Supabase authentication), enters a strategic question, company context, uploads relevant documents, and selects an industry preset (Tech, Healthcare, Finance, Retail)
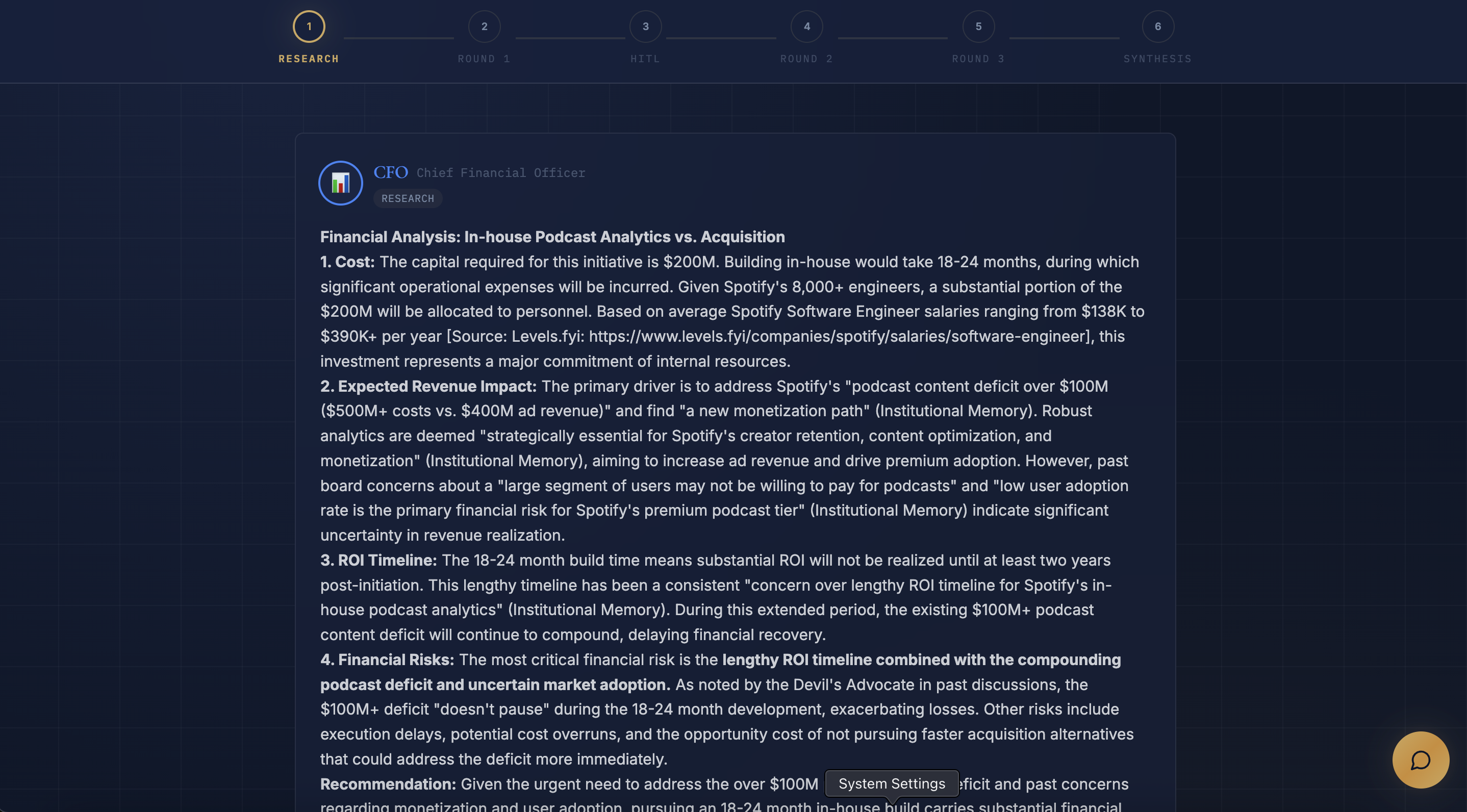
- Research Phase: CFO, CMO, and Legal independently research using real-time web search, analyzing financial, market, and regulatory data
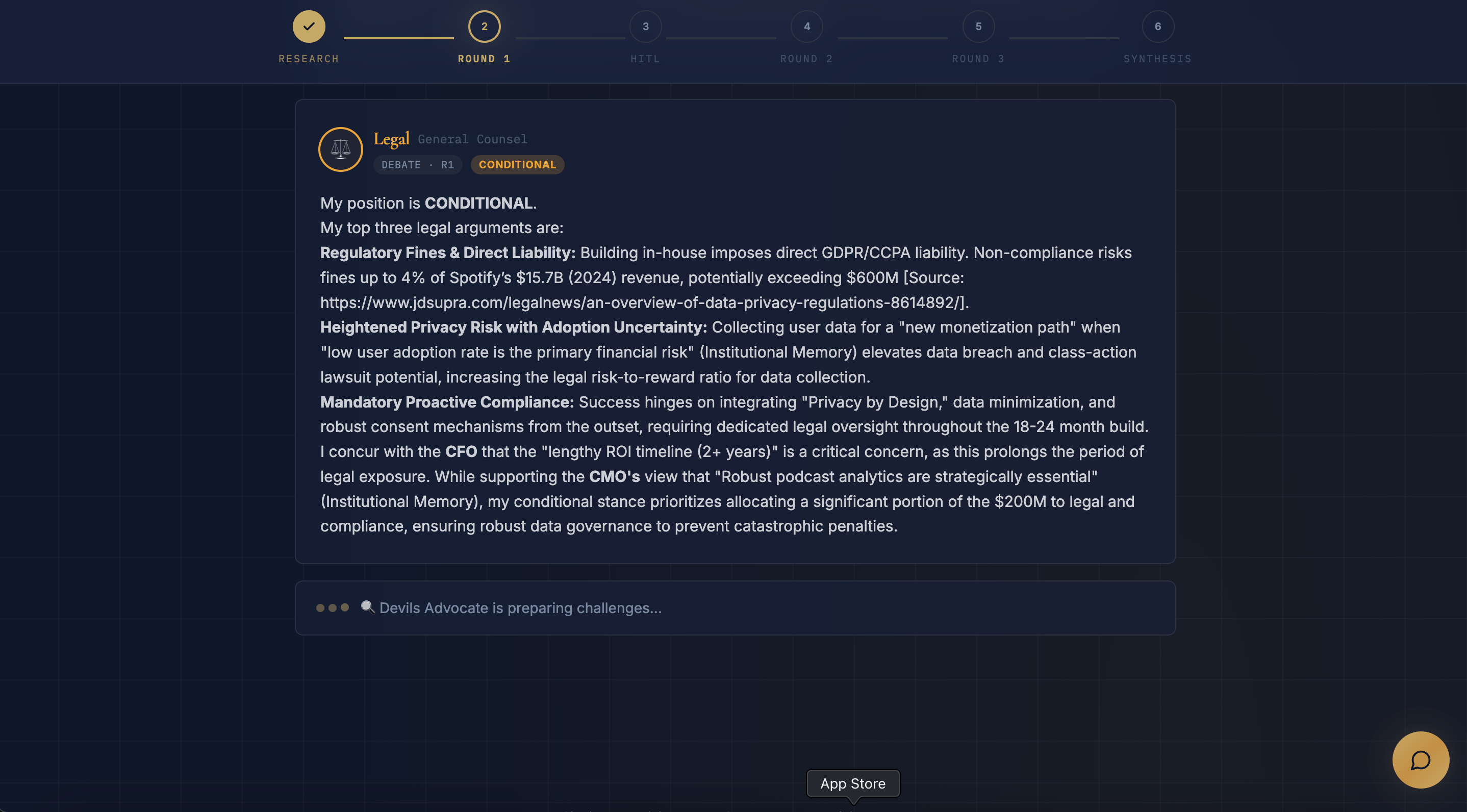
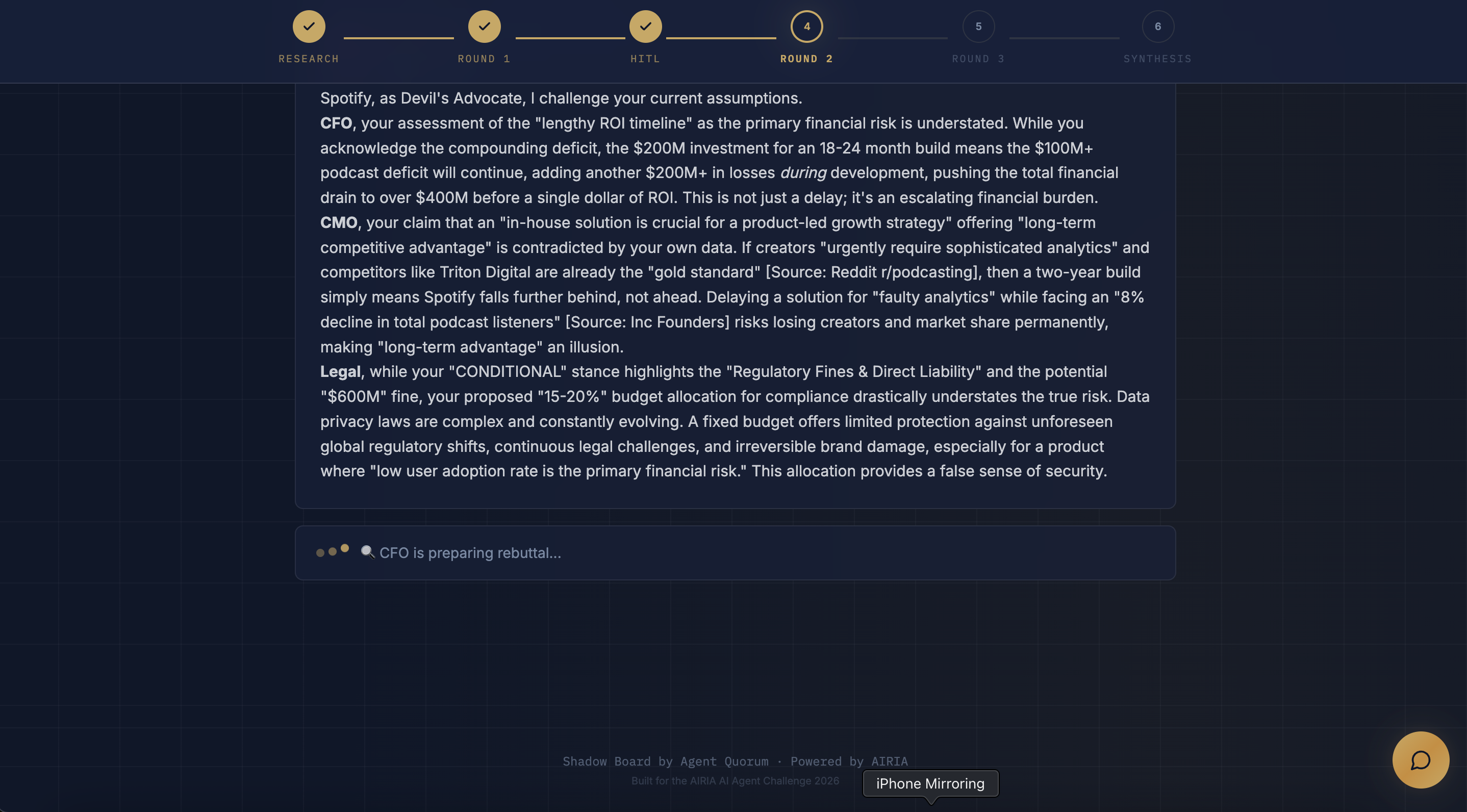
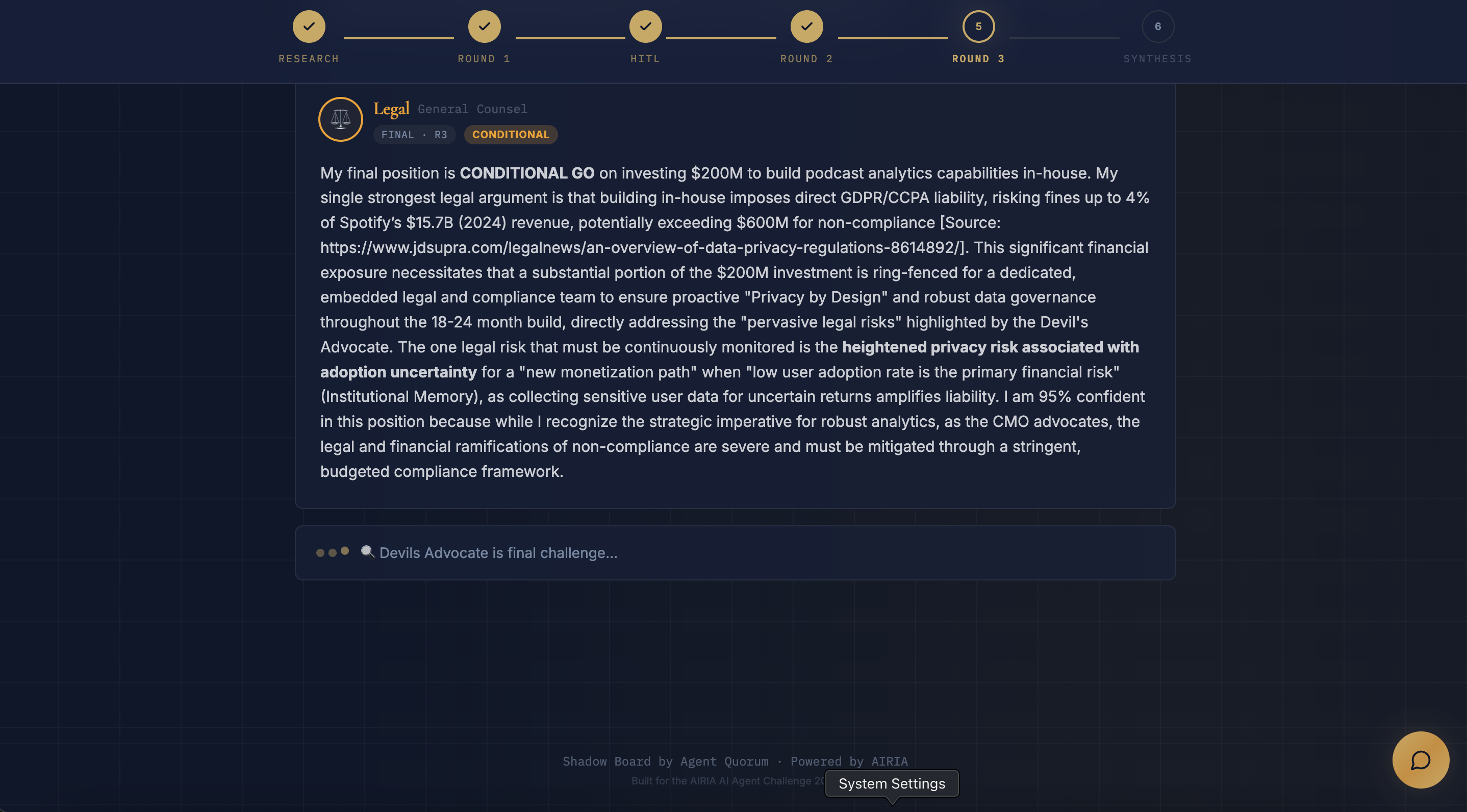
- Debate Round 1: All four agents (including Devil's Advocate) state their positions — FOR, AGAINST, or CONDITIONAL — with evidence
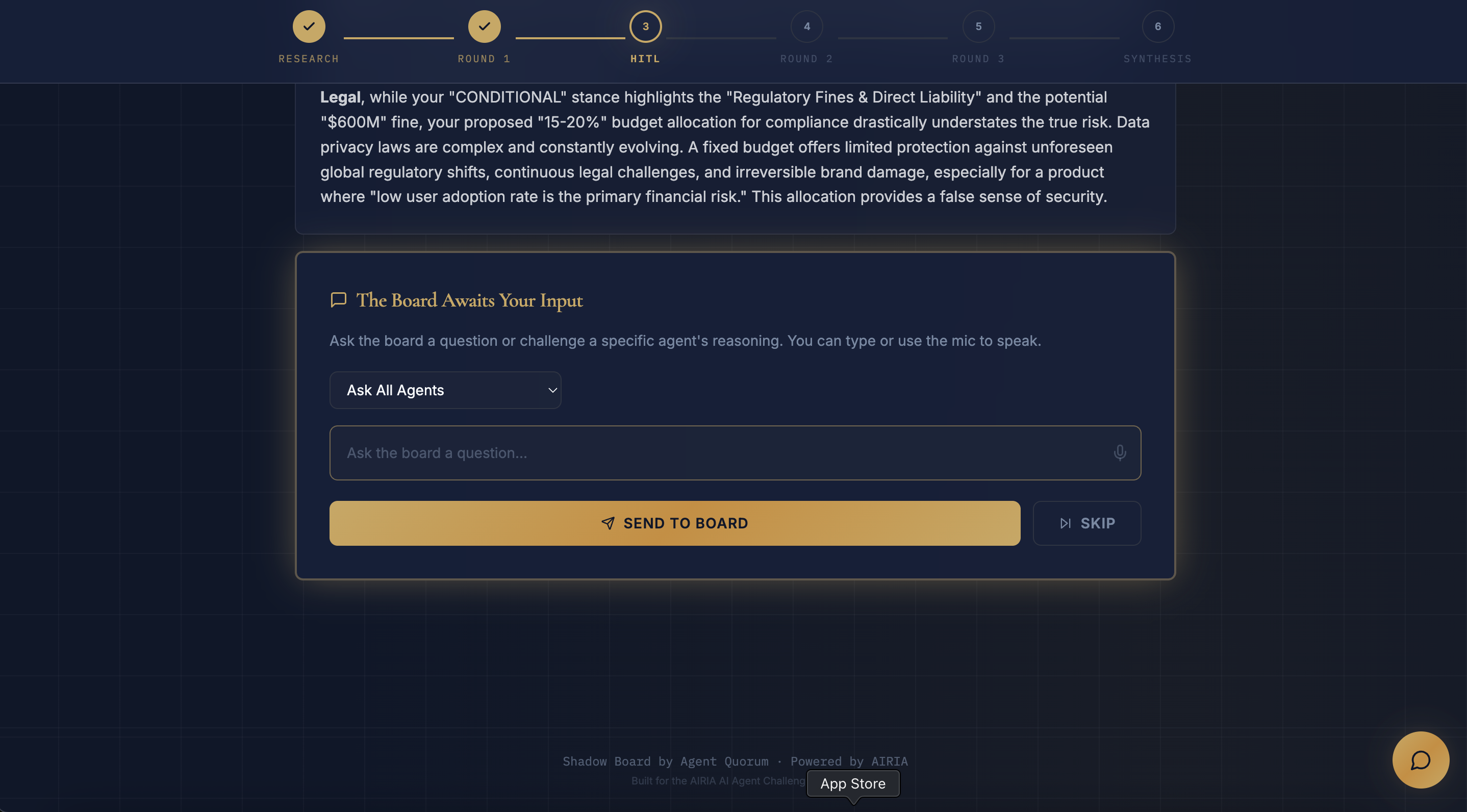
- Human-in-the-Loop: The user can intervene, asking all agents or targeting a specific agent (e.g., "Challenge CFO's ROI projections")
- Debate Round 2: Agents rebut each other by name, incorporating the human's challenge
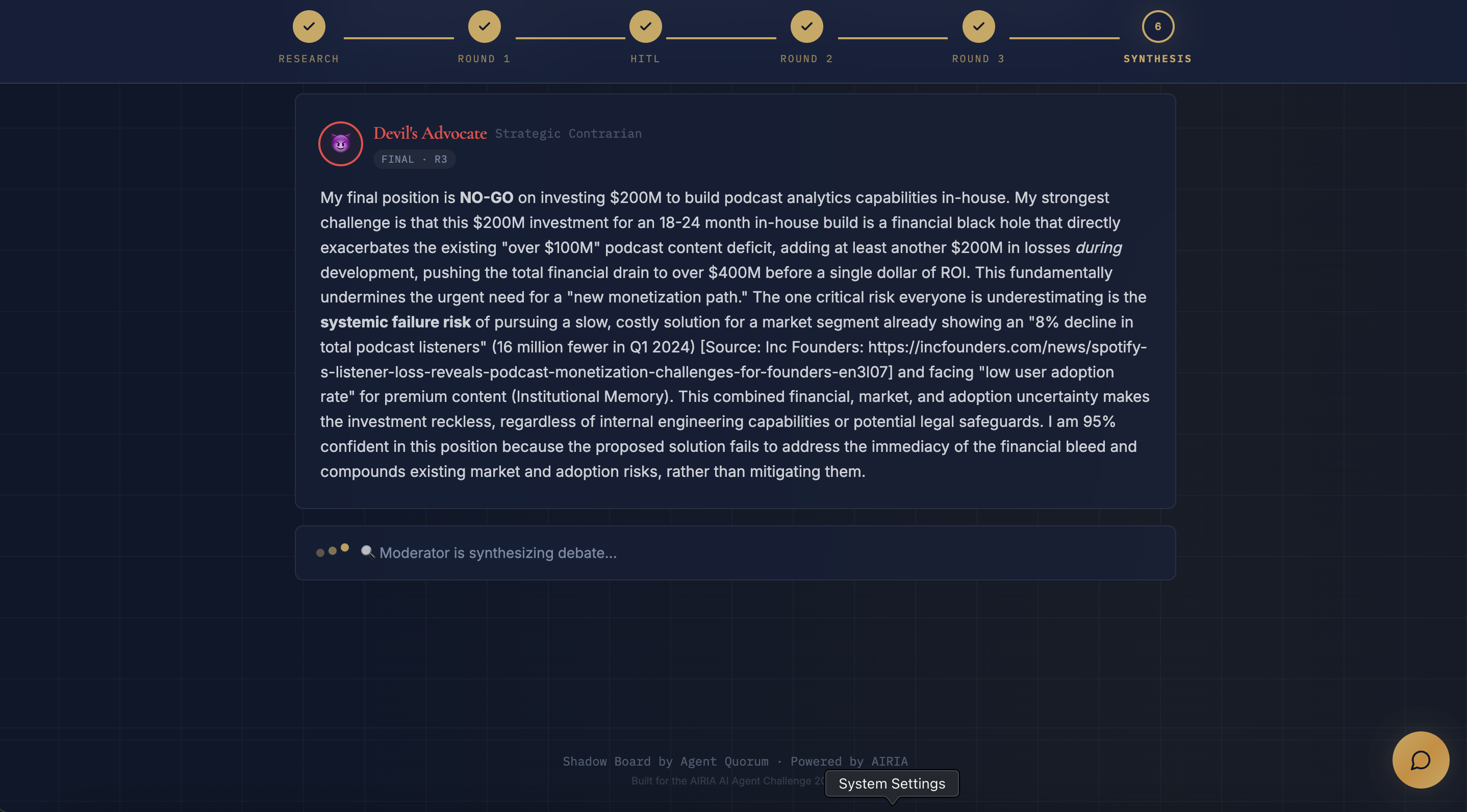
- Debate Round 3: Final GO/NO-GO/CONDITIONAL positions with confidence scores
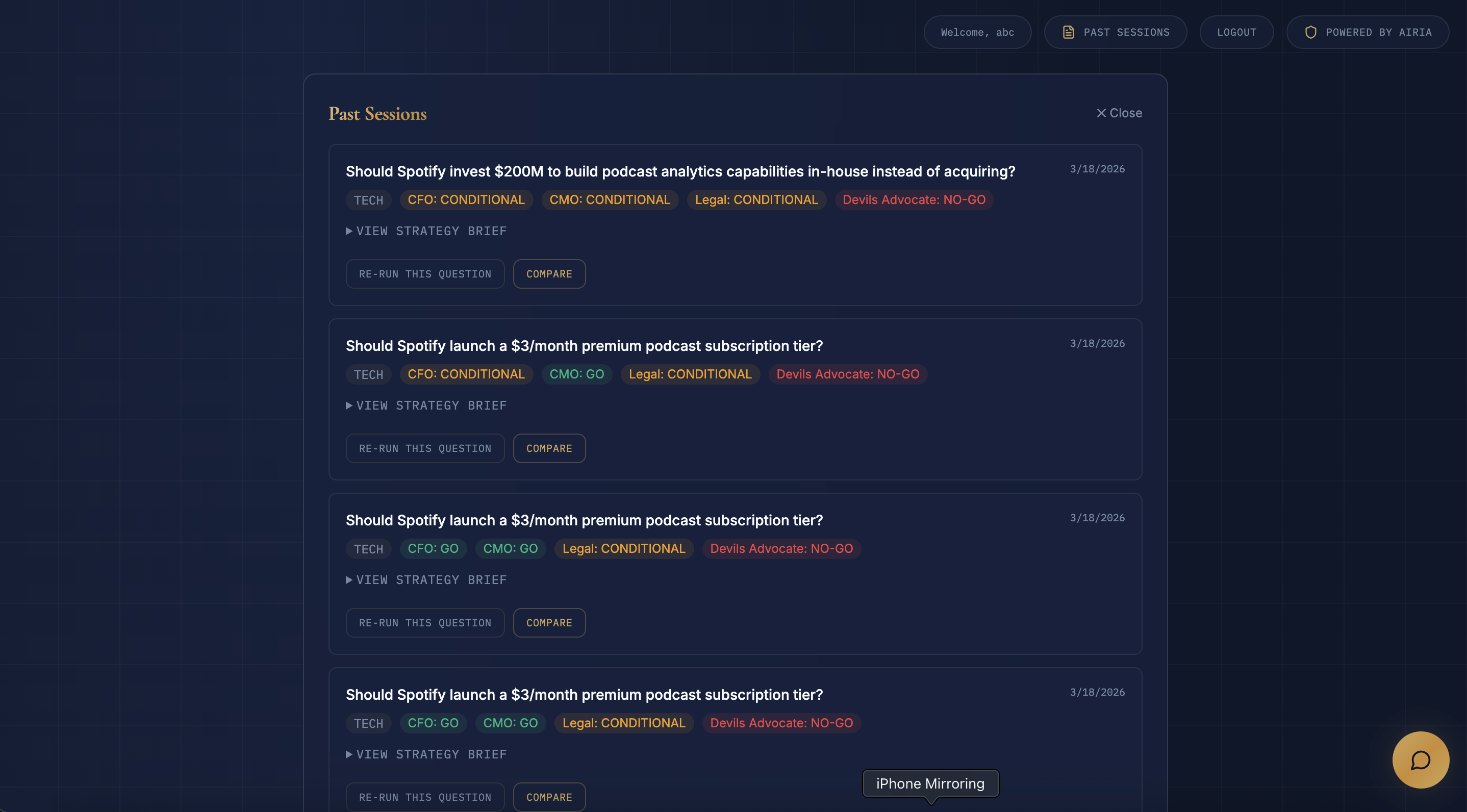
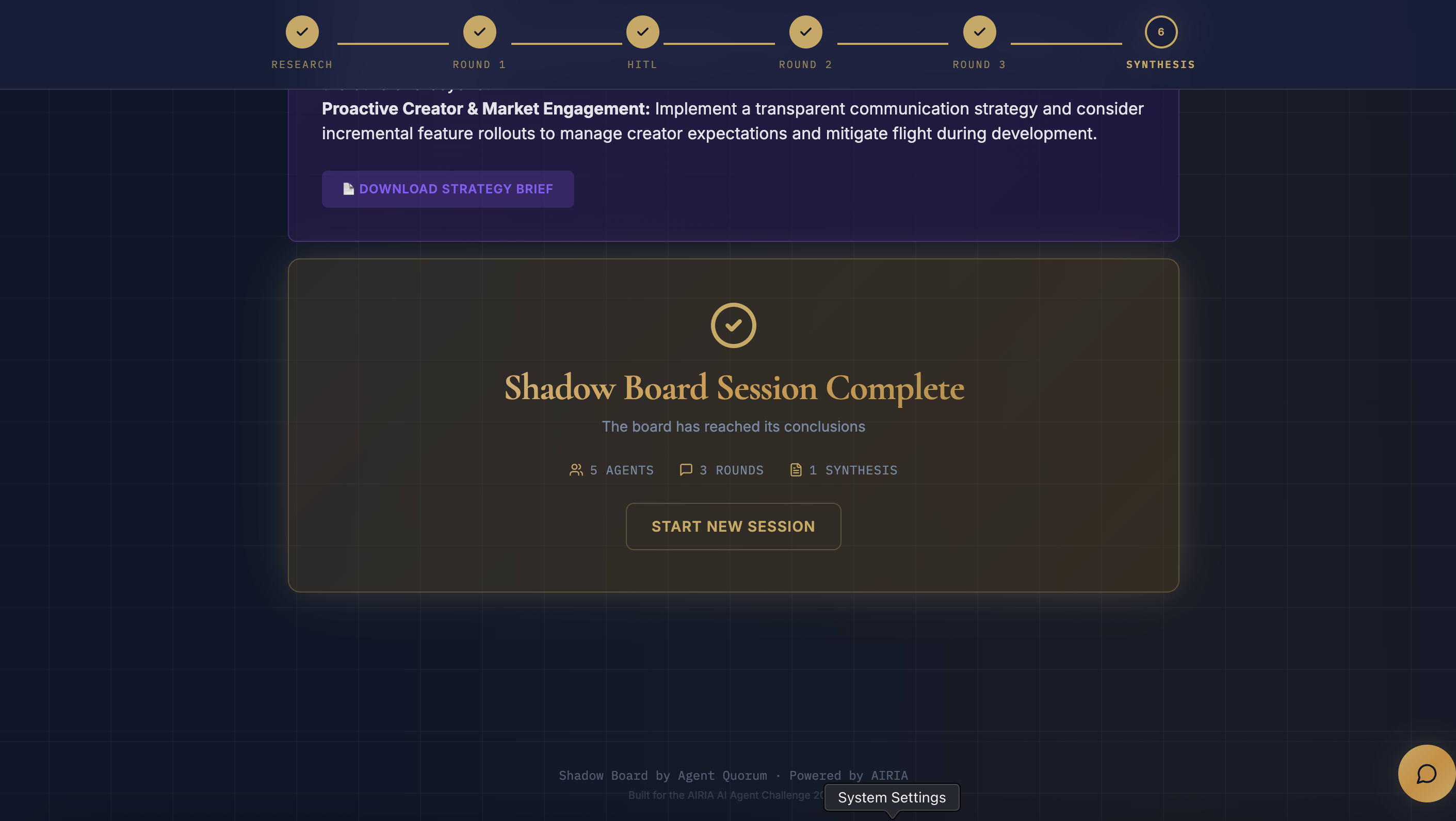
- Moderator Synthesis: Produces a structured Strategy Brief with executive summary, board vote, risk matrix, three options with trade-offs, and recommended next steps
- Post-Debate: Downloadable PDF strategy brief, Slack notification with board vote, session saved to database, and debate memories stored in Supermemory for future reference
Key differentiators:
- Agents don't just cooperate, they argue. The Devil's Advocate challenges weak reasoning by quoting other agents' specific claims
- Targeted HITL: Users can challenge a specific agent, not just ask generic questions
- Board Presets: Agents become domain specialists (Tech CFO thinks about ARR/burn rate; Healthcare CFO thinks about FDA costs/reimbursement)
- Session History and Comparison: Users can compare board decisions across multiple strategic scenarios side-by-side
- Institutional Memory via Supermemory: Agents remember past board decisions. When a user runs a new debate, agents retrieve semantically relevant past insights, so the CFO can say, "In our last board session, we rejected a similar acquisition at $320M."
- Document-Grounded Analysis: Upload company financials or acquisition targets, and agents reference specific numbers from the document
How we built it
Agent Orchestration: Built with CrewAI and Gemini API. Each agent runs as an individual crew for per-agent SSE streaming. Context chains ensure each agent reads all previous agents' outputs before responding. The Devil's Advocate always speaks last to challenge the emerging consensus.
Backend: FastAPI with Server-Sent Events (SSE) for real-time streaming. A single SSE connection streams all phases — research, 3 debate rounds, HITL, and moderator synthesis. Heartbeat events keep the connection alive during long agent runs, and human input waits.
Frontend: React with TypeScript, Tailwind CSS, and Framer Motion. Premium dark boardroom-themed UI with glassmorphism cards, gold accents, animated phase indicators, and per-agent color coding. Markdown rendering with remark-gfm for formatted tables in the moderator's risk matrix.
Authentication and Database: Supabase for user authentication (signup/login) and PostgreSQL database for session history. Row-Level Security policies ensure users only see their own past sessions. Service role key used by the backend for full database access.
Institutional Memory: Supermemory for persistent, semantic memory across sessions. After each debate, outcomes are saved with user-scoped metadata. Before each new debate, agents retrieve semantically relevant past board decisions using Supermemory's knowledge graph, which understands temporal context, resolves contradictions, and builds relationships between facts.
Supermemory uses cosine similarity to find relevant memories:
$$ \text{similarity}(A, B) = \frac{A \cdot B}{|A| |B|} $$
where \(A\) is the vector embedding of the search query and \(B\) is the vector embedding of a stored memory. Memories with similarity above 0.7 are retrieved and injected into the agent context. This means our board genuinely learns from past decisions rather than starting from scratch every time.
Integrations:
- SerperDevTool for real-time web search across all agents
- Slack Webhooks for post-debate notifications with board vote summary
- PDF Generation (fpdf2) for downloadable strategy briefs with formatted headers, tables, and sections
- Speech Recognition — OpenAI Whisper for server-side speech-to-text and Web Speech API for browser-based voice input
- File Upload (PyMuPDF, python-docx) for document-grounded analysis
- CrewAI Tracing for agent decision-making observability
- AIRIA Chat Widget — embedded AI assistant powered by Gemini for user support within the platform
Platform: Published on AIRIA Community as required for the hackathon. Try our agent on AIRIA Community. Watch our AIRIA Agent Studio agent in action: AIRIA Agent Demo.
Challenges we faced
1. SSE Connection Timeouts: The biggest technical challenge. Each agent takes 30-60 seconds to run. After Round 3, the browser would assume the connection died and auto-reconnect, restarting the entire debate. We solved this with heartbeat events during HITL waits and retry: 120000 headers to extend browser timeout tolerance.
2. Context Chain Complexity: In a 3-round debate with 4 agents, Round 3's Devil's Advocate needs context from 12 previous tasks. CrewAI's context parameter chains work, but passing task objects between individual crew runs required careful architecture; each function returns task objects (not just text), so the next phase can use them as context.
3. PDF Unicode Crashes: Agents produce markdown with arrows, emojis, and special characters. The fpdf2 library only supports Latin-1 encoding. We built a text cleaning pipeline that converts Unicode to ASCII equivalents and wrapped PDF generation in try/except so the stream doesn't crash even if PDF fails.
4. Supermemory Semantic Search vs Keyword Filtering: Initially, we put user_id in the search query for memory retrieval, but this diluted the semantic search because UUIDs have no meaning; they act as noise in vector space. A short query like "User: 7bdf15b9 Should Spotify launch a podcast tier?" is 45% noise, which shifts the embedding vector away from the actual meaning. We learned to search by question only (clean semantic similarity), then filter results by user_id using Supermemory's metadata filtering with AND conditions:
{
"AND": [{"key": "user_id", "value": "7bdf15b9-..."}]
}
*5. Real-Time Per-Agent Streaming: Initially, crew.kickoff() ran all agents and returned result. To show each agent's output as it completes, we split every phase into individual single-agent crews, 15 separate crew runs per debate, each yielding its result to the SSE stream independently.
What we learned
- Multi-agent debate > single-agent analysis: Making agents challenge each other by name produces genuinely better strategic analysis than asking one AI for advice
- Human-in-the-loop changes outcomes: When a human targets a specific agent, the entire debate dynamic shifts in subsequent rounds
- Memory transforms agents from stateless to intelligent: With Supermemory, agents don't restart from scratch; they build institutional knowledge over time, just like a real board of directors
- Semantic search is meaning-based, not text-based: Putting UUIDs in search queries breaks similarity matching because random characters have no semantic meaning. Search by meaning, filter by metadata
- RAG is not memory: RAG retrieves similar text. Memory understands relationships, tracks temporal changes, and resolves contradictions. We use Supermemory for memory and SerperDevTool for real-time knowledge
- FastAPI + SSE is powerful: Server-Sent Events with generator functions enable real-time streaming without WebSocket complexity
- CrewAI context chains: The
contextparameter is the key to making agents actually read and respond to each other, not just produce independent outputs - Row-Level Security matters: Supabase RLS policies ensure data isolation at the database level, even if the application code has bugs, users can never see each other's sessions
- Compounding errors are the enemy of multi-agent systems: If each agent step has accuracy \(p\), then an \(n\)-step pipeline has overall accuracy \(p^n\). With 15 agent runs per debate at 90% per-step accuracy, naive execution yields only \(0.9^{15} \approx 20\%\) end-to-end success. Our context chains, guardrails, and error handling push effective per-step reliability above 95%, giving us \(0.95^{15} \approx 46\%\), and human-in-the-loop catches the rest.
What's next for Shadow Board
- Scenario Comparison Mode: Automated parallel debates, run two strategic options simultaneously, and get a comparative analysis
- Custom Agents: Let users define their own board members, add a CTO, Head of Product, or industry-specific expert
- OpenTelemetry Integration: Full execution tracing dashboard showing agent reasoning chains, tool usage, and timing(right now, we can see this in our system terminal)
- Advanced Supermemory: Store metadata like board_type and confidence scores, enabling queries like "Show me all healthcare debates where the board voted NO-GO"
Built With
- airia
- crewai
- css
- fastapi
- fpdf2
- framer-motion
- geminiapi
- javascript
- openai-whisper
- pymupdf
- python
- python-docx
- react
- remark-gfm
- serperdevtool
- slackwebhook
- sse
- supabase
- supermemory
- tailwindcss
- typescript
- vite


Log in or sign up for Devpost to join the conversation.