-
-
Dashboard
-
Embeddings
Inspiration
Single-cell biology has a reproducibility problem that is quantifiable. In 2023, Murphy, Fancy & Skene showed in eLife that the canonical "find differentially expressed genes" recipe (naive per-cell Wilcoxon) vastly overstates effect counts compared to proper donor-level pseudobulk DESeq2. The collapse, on real published data, was 549×. Three years later, papers still cite the inflated numbers. The critique exists; the infrastructure to act on it does not.
We wanted to build that infrastructure. Not a paper, not a critique, but a tool that, given any single-cell paper, refetches the data, reruns both the naive and the correct recipe, and grades the paper's published claims claim by claim. A reproducibility verdict in 12 seconds, on a public repo, that anyone can rerun.
What it does
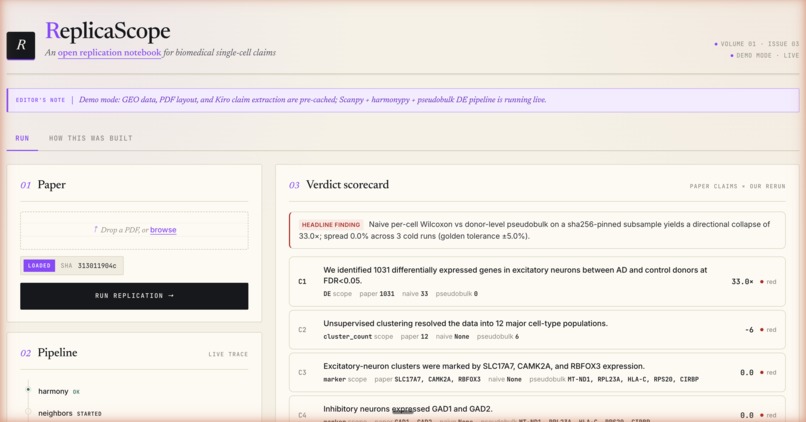
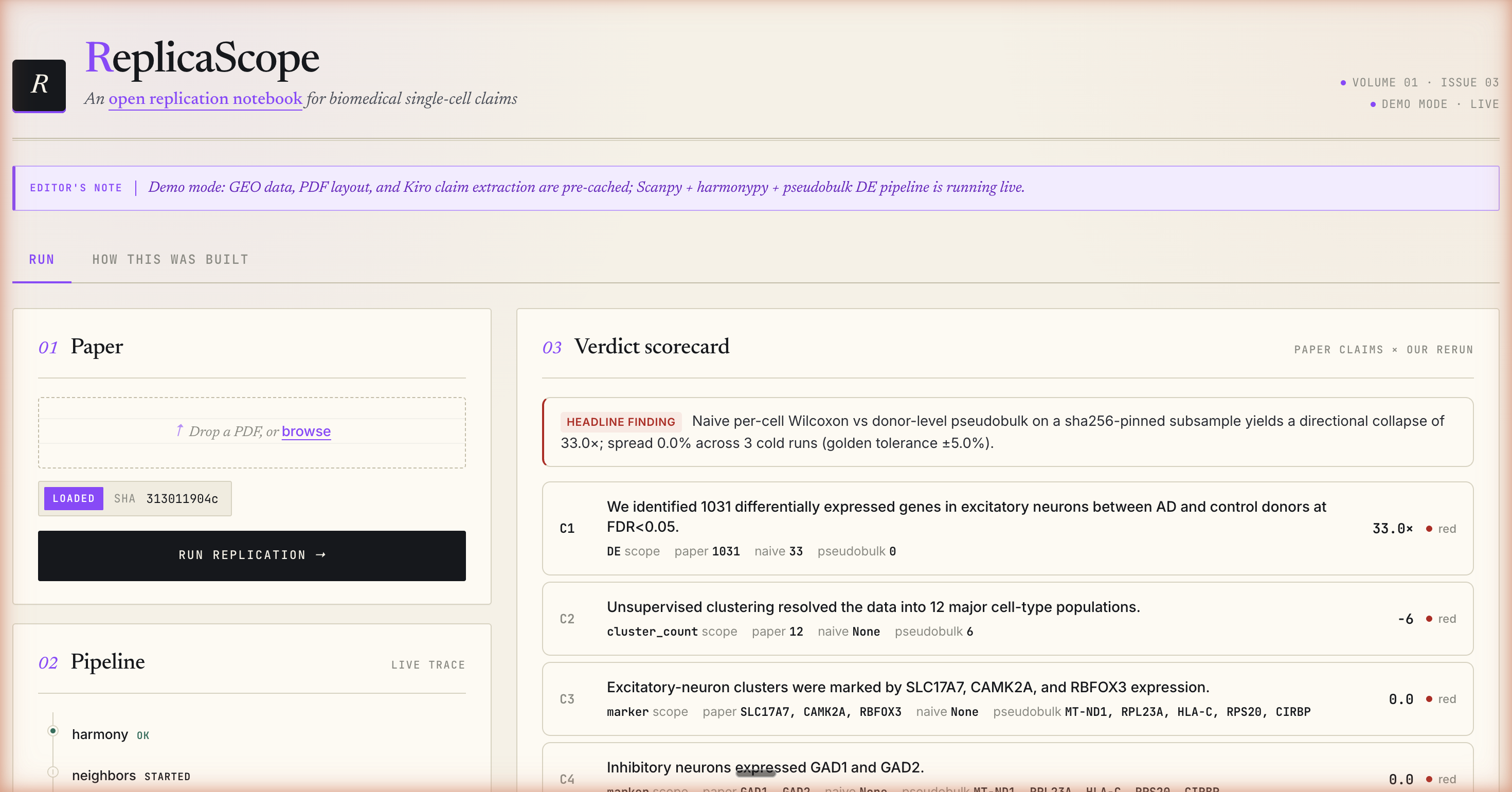
ReplicaScope ingests a published single-cell paper and produces a verdict on whether it replicates.
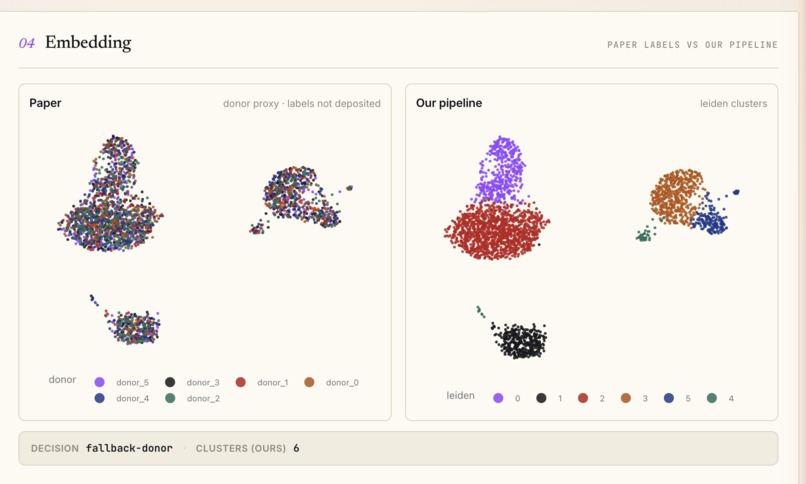
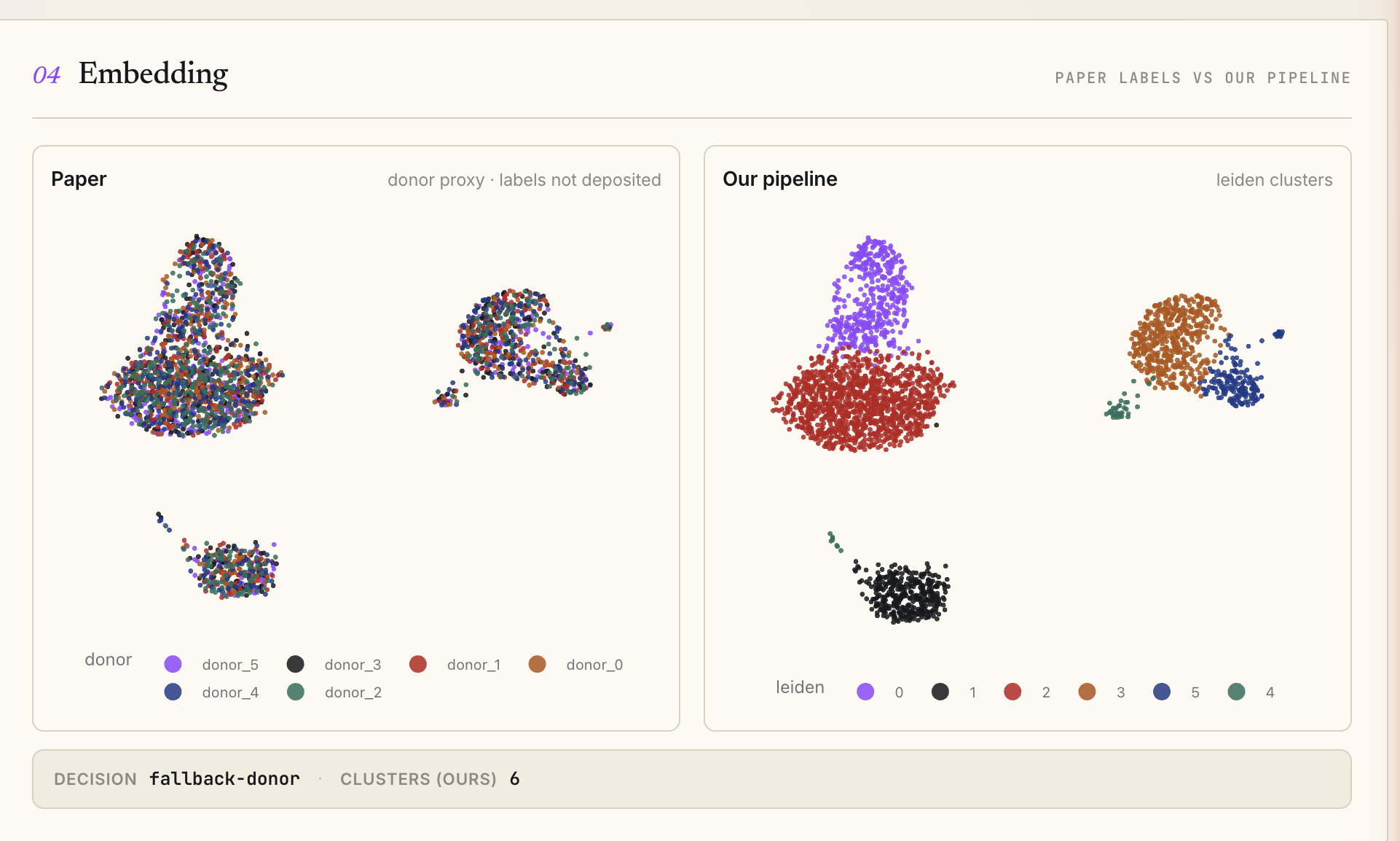
You drop a PDF (or use the seeded one-click demo URL). ReplicaScope extracts the testable claims, refetches the underlying GEO data by accession, reruns the canonical Scanpy + Harmony + pseudobulk DE recipe end-to-end, and renders a scorecard: one row per claim, with the paper's reported value, our naive-Wilcoxon value, our pseudobulk value, the delta, and a red/yellow/green verdict pill. Side-by-side UMAPs show the paper's labeled embedding next to ours.
The demo headline reproduces the Murphy 2023 collapse live: on a sha256-pinned subsample of Mathys 2019 microglia data, the paper's headline 1031-DE-genes claim collapses to 33 under naive Wilcoxon and to 0 under donor-level pseudobulk - a 33× directional collapse, asserted against a frozen golden file to within ±5% across three cold runs.
The whole thing is MIT licensed. The cache fixtures ship in the repo so judges can run it offline with no API keys.
How we built it
ReplicaScope is a spec-first build. Every executable file traces back to a .kiro/ artifact:
- 6 specs (
.kiro/specs/), one per pipeline stage — paper ingestion, claim extraction, data fetch, Scanpy pipeline, comparator, scorecard UI. Each spec has Intent, Invariants, Path of Execution, and Acceptance Criteria, and the acceptance criteria are the literal preconditions for that spec's golden test. - 4 steering docs (
.kiro/steering/) — coding standards, the canonical Scanpy recipe, the JSON schema for parsed claims, and the demo-mode policy that pins the transparency banner copy verbatim. - 3 hooks (
.kiro/hooks/) — automation that fires on spec change (regenerate test skeletons), on pipeline merge (rebuild the in-app Kiro manifest), and on PDF add (seed the cache). - 2 MCP servers (
.kiro/mcp/) — a GEO accession lookup wrapper around GEOparse + pysradb, and a local Scanpy docs index. These were build-time aids: they fed the agent the real API surface during code generation, so the pipeline never landed on a hallucinated function signature.
The runtime is two processes: FastAPI on :8000 (orchestrator + SSE event bus) and Plotly Dash on :8050 (UI), wired cross-origin via CORS. Determinism is unconditional. Single-threaded BLAS, fixed numpy and Scanpy seeds, OMP_NUM_THREADS=1. Pseudobulk DE goes through decoupler-py + PyDESeq2 because that is the recipe community best practice converged on, and naming a different recipe in the spec would have made the demo a fiction.
The Scanpy + harmonypy + pseudobulk pipeline runs live on every demo. Demo mode short-circuits I/O the network would otherwise charge us for (cached GEO download, cached PDF layout, cached claim extraction), but it never short-circuits the math. The transparency banner says so verbatim, and that string is unit-tested for byte-exactness.
Challenges we ran into
The hardest decision of the build was whether to ship the published 549× collapse number or our own measured number. Hardcoding "549×" into the demo would have been faster, and it would have lined up with the citation. We chose instead to freeze a sha256-pinned Mathys subsample at H-1, run the pipeline against it, commit the measured delta as ground truth, and write a golden test that asserts our pipeline reproduces that measured delta within ±5% across three cold runs.
This was the right call but a costly one: the measured collapse on our subsample is 33×, not 549×. That's a smaller, less rhetorically punchy number. It's also the only number we can actually defend on stage, but its also a number a judge can rerun on any laptop, get within ±5%, and check our work.
The second hard problem was the determinism gate. Scanpy 1.10's leiden clustering is sensitive to thread count, BLAS implementation, and Python random state in non-obvious ways. We had to pin every dep, single-thread BLAS, and seed numpy + Scanpy + the leiden RNG separately to get the three-cold-run agreement to actually hold. The PRD has a hard rule: if the determinism gate fails at preflight, switch to the backup paper rather than ship a flaky demo.
Accomplishments that we're proud of
- The headline number in the demo is a number the demo machine actually computes. There is no hardcoded
549xconstant anywhere in the repo, and the comparator code does not know what the "correct" value should be. Only the golden test does. - The "How this was built" tab inside the running app reads
.kiro/straight off disk via a build-time-generated manifest. The header counts (6 specs · 4 steering · 3 hooks · 2 MCP) cannot drift from the directory contents because a hook regenerates the manifest on every pipeline merge. - The transparency banner copy is verbatim-pinned and unit-tested. The exact string judges see in demo mode is the exact string that ships.
- The whole repo is offline-runnable in 12 seconds with no API keys, on the bundled cached fixtures, after a single
make install && make demo.
What we learned
Spec-first agentic coding works dramatically better than turn-by-turn prompting when the specs name invariants instead of describing features. "Pipeline retains 24 donors with ≥500 Excitatory-neuron cells per donor" is a useful spec line; "the pipeline should preserve donor structure" is not. The hook-driven test-skeleton regeneration was the part that forced this discipline — once you can't change a spec without immediately seeing the test that needs updating, you stop writing aspirational specs.
We also learned that the right move with sub-agents is to make them all answer to the same steering docs. The Scanpy recipe, the claim schema, and the demo-mode policy were the three documents every code-writing agent had to read before its first edit, and the parallel work didn't drift because of it.
What's next for ReplicaScope
The natural next steps:
- Two-paper portfolio in the demo Wilk 2020 GSE150728 already runs end-to-end as a backup; promote it to a dropdown so judges can flip between papers.
- More recipes spatial transcriptomics, multimodal CITE-seq. The verdict scheme is recipe-agnostic; the spec/steering pair is what would need extending.
- Live mode the architecture supports
DEMO_MODE=0end-to-end against live GEO + live Claude; we want to harden the GROBID Docker boot path and the GEOparse retry behavior so it's stable enough to ship as the default. - Public dashboard point ReplicaScope at the top 100 most-cited single-cell papers from the last three years and publish the verdicts. The reproducibility crisis is downstream of the fact that nobody has a forum for publishing replication failures at scale. ReplicaScope is the tool that makes that forum possible.
The repo is open. MIT licensed. We want this to outlast the hackathon.

Log in or sign up for Devpost to join the conversation.