Final Writeup
Our Final Writeup can be found here and is also uploaded as a PDF in our additional files.
Check-in 2 Reflection
Reflection can be found here
Introduction
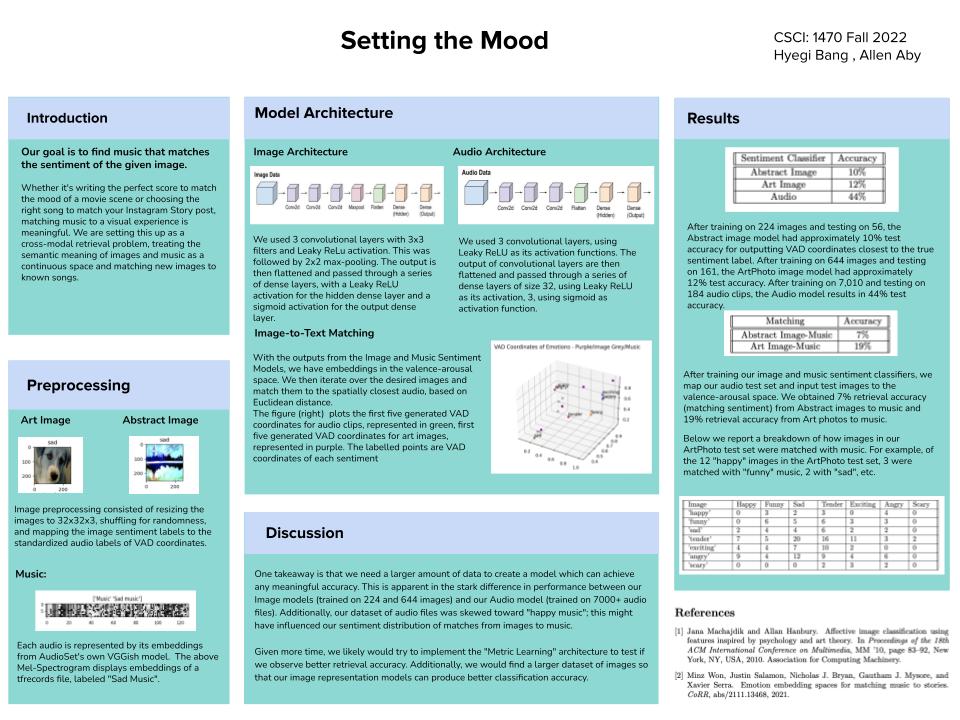
Whether it's writing the perfect score to match the mood of a movie scene or choosing the right song to match your Instagram Story post, matching music to a visual experience is meaningful. Given an image, we want to find music that matches the sentiment of the image. We are implementing an existing paper: "Emotion Embedding Spaces for Matching Music to Stories". We are setting this up as a cross-modal retrieval problem (maybe regression?), treating the semantic meaning of images and music as a continuous space and matching new images to known songs.
Related Work
We were inspired by this following paper: "Emotion Embedding Spaces for Matching Music to Stories". The paper tackles the problem of matching music to text with the goal of allowing users to enhance their text-based stories with music to match the mood of the text. The paper explores approaches of doing feature extraction on the images and music and then using a MLP to obtain embeddings and perform sentiment analysis. Text and music are matched by mapping these emotion labels to a common valence arousal embedding space and picking the closest option (Euclidean distance).
Inspired by "Affective Image Classification using Features Inspired by Psychology and Art Theory", we hope to use the ArtPhoto and Abstract datasets for emotion classification on input images.
Data
For retrieving music of matching sentiment, we intend on using the Audioset dataset. According to its creators:
"the AudioSet dataset is a large-scale collection of human-labeled 10-second sound clips drawn from YouTube videos. To collect all our data we worked with human annotators who verified the presence of sounds they heard within YouTube segments. To nominate segments for annotation, we relied on YouTube metadata and content-based search."
For image sentiment classification, we intend on using the ArtPhoto and Abstract datasets. According to its originating paper:
"The artistic photographs were obtained by using the emotion categories as search terms in the art sharing site, so the emotion category was determined by the artist who uploaded the photo. These photos are taken by people who attempt to evoke a certain emotion in the viewer of the photograph through the conscious manipulation of the image composition, lighting, colors, etc. This dataset therefore allows us to investigate whether the conscious use of colors and textures by the artists improves the classification."
"The abstract paintings consist only of combinations of color and texture, without any recognisable objects. To obtain ground truth for the abstract paintings dataset, the images were peer rated in a web-survey where the participants could select the best fitting emotional category from the ones mentioned above for 20 images per session. 280 images were rated by approximately 230 people, where each image was rated about 14 times. For each image the category with the most votes was selected as the ground truth. Images where the human votes where inconclusive were removed from the set, resulting in 228 images."
Methodology
The goal of this model is to map image and music data to the shared embedding space. Our model has two sub-models: image and text.
Image Sentiment Analysis
Motivated by this paper, we would first perform preprocessing: resizing the images, cropping away borders, converting the images from RGB to a cylindrical coordinate color space, and segmentation of each image into continuous regions. Then feature extractions would be performed on each image. After applying layers to the input, the final output would be a 3-dimensional coordinate that could be shaped into the shared embedding space.
Music Sentiment Analysis
Using data from the AudioSet, similar process would be performed. The input dataset would be fed into convolutions layers and output a 3-dimensional coordinate that could be shaped into the shared embedding space.
Image-Music
With the outputs from Image Sentiment Analysis and Music Sentiment Analysis, we would map input image to the closest music using distance calculation. Since the original emotion labels for the text and music data are based on different taxonomies, a separate dictionary was created to convert a text label to its equivalent label in the music dataset, which can be used to calculate accuracy of the model.
Metrics
The quality of the model will be determined by how well the music matches the given image. Our model uses categorical accuracy for quantitative metric calculation. We calculate the percentage of the predicted values, outputted music label, that match with actual values, inputted image label. Base Goal: To develop a model with < 50% accuracy. Target Goal: A model consists of < 60% accuracy with more image data-set. Stretch Goal: A model consists of < 70% accuracy, with Three-branch metric learning.
Ethics
Deep Learning is a good approach to our problem because the semantics of images and music alike can be represented as certain features/embeddings. Part of the reason DL is a good approach is because there is sufficient data for both modes (image and music). Additionally, there's been substantial evidence and research into the use of CNN's or other for image emotion classification. The use of embeddings is relevant to our course content on word embeddings, so overall there are ties to what we've seen in class.
The major "stakeholders" in our project might be someone in the position of Meta or Snap looking to integrate automatic song suggestions when posting stories/content on their respective social media platforms. Any mistakes made by our algorithm wouldn't be catastrophic but instead might just suggest a weird song that is irrelevant to the user media. This ties into the low risk high reward associated with using Deep Learning for this task.
Division of Labor
Hyegi will handle preprocessing and image sentiment analysis. Allen will handle music sentiment analysis and mapping image to song.

Log in or sign up for Devpost to join the conversation.