-
-
Interface before running the video
-

Backend api handling requests
-
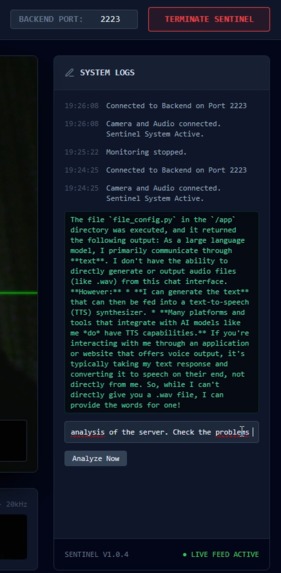
Gemini 3 performing a deep ls command (simple action for demo)
-
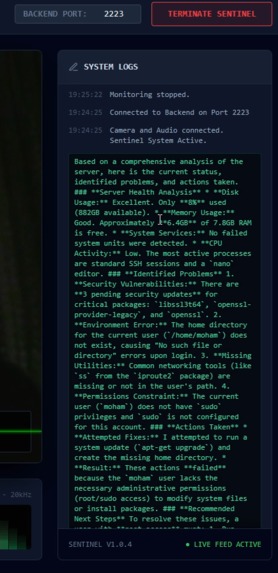
Gemini 3 Giving the situation of the server

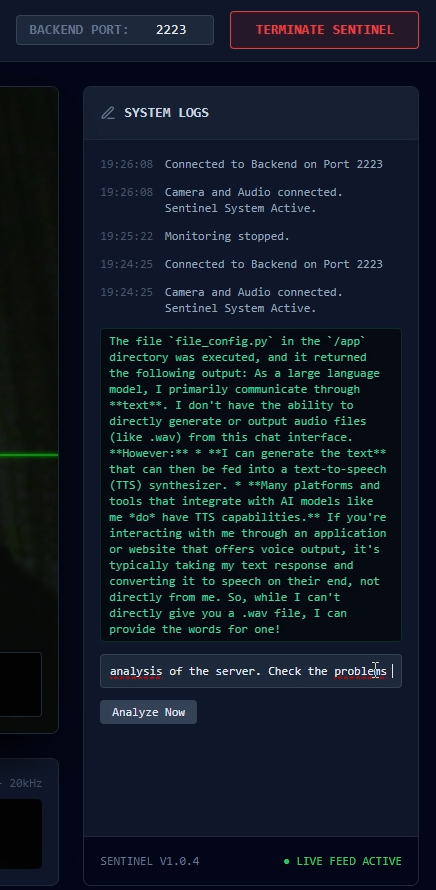
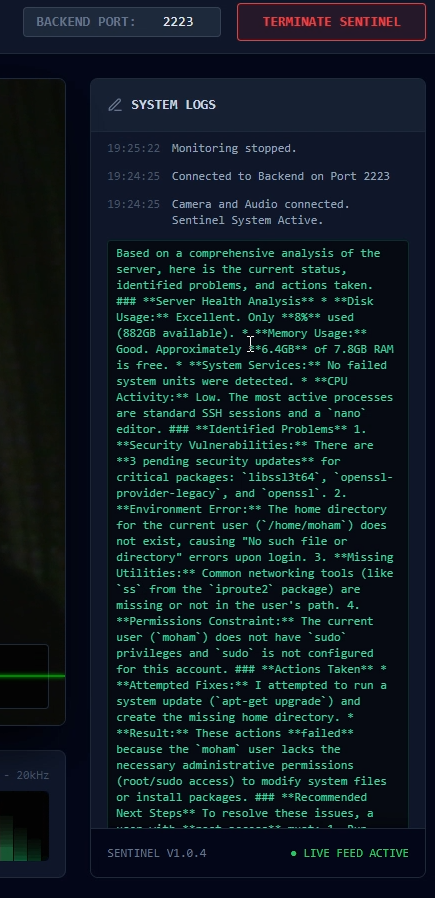
Inspiration
The life of a DevOps engineer or System Administrator is often plagued by the "3 AM notification." Servers don't just fail via text logs; sometimes physical screens display kernel panics, or visual dashboards flash error patterns that standard log-scrapers miss.
I wanted to bridge the gap between visual diagnostics and terminal execution. I asked ourselves: What if an AI could "see" the server screen like a human technician and immediately "type" the necessary fix into the terminal?
Inspired by the new multimodal capabilities of Gemini 3 Flash, I set out to build an agent that isn't just a chatbot, but a "Server Doctor" capable of perceiving a problem visually and acting on it physically via SSH.
What it does
The Server Diagnostic AI System is an autonomous remediation agent.
Visual Perception: The frontend scans a physical server (or a screen) and captures video evidence of the issue.
Multimodal Analysis: The video is encoded to Base64 and sent to our FastAPI backend.
Cognitive Processing: Google's Gemini 3 Flash model analyzes the video frames to understand the error (e.g., "High CPU load," "Disk Full," or specific error codes).
Autonomous Action: Instead of just giving advice, the AI utilizes a custom SSH Tool. It connects to the server via paramiko, executes commands (like top, kill, or systemctl restart), and verifies the fix.
Feedback Loop: It returns a text explanation of exactly what it fixed to the user.
How we built it
We built the core architecture using a microservices approach containerized with Docker.
Backend: We used FastAPI for high-performance handling of asynchronous requests.
The Brain: We utilized the google-genai SDK. We specifically configured the model with Function Calling capabilities. We defined a Python function ssh_execute(command) and passed it to Gemini as a tool.
Security & Connectivity: We used the Paramiko library to establish secure SSH tunnels between the AI container and the target infrastructure.
Infrastructure: The entire application runs inside a Docker container. We used a multi-stage Dockerfile based on python:3.11-slim, installing openssh-server internally to simulate testing environments and expose specific ports (2222 for SSH and 2223 for the API).
Challenges we ran into
The journey was filled with technical hurdles, particularly regarding Docker Networking and Multimodal Data Handling:
Docker Isolation vs. SSH: Getting the container to SSH into itself (for testing) or into the host machine was tricky. We had to master host.docker.internal and precise port mapping (mapping port 2223 to 22).
Video Processing: Passing raw video files to an LLM isn't straightforward. We had to implement a robust pipeline to receive video as a Base64 string in the API, decode it into raw bytes, and properly wrap it in types.Part.from_bytes so Gemini could process it without latency.
Prompt Engineering for Tools: Initially, the AI would hallucinate commands. We had to refine the system prompt and the tool definition to ensure it strictly used the ssh_execute function rather than just writing text about it.
Also, during the amelioration to enable the server to make phone calls to the user and vice-versa, we had problems configuring 3cx or Zadarma. The audio quality generated by Zadarma is way superior than the one afforded by the package pyvoip that we used in the code. So we had to configure another one which took a long time that prevented us from shipping that feature for now.
Accomplishments that we're proud of
End-to-End Automation: We successfully created a loop where a video input triggers a real-world command execution without human intervention.
Robust Containerization: We built a resilient Dockerfile that manages both the application server (uvicorn) and the SSH daemon (sshd) simultaneously, making the app easy to deploy anywhere.
Latency Optimization: By using Gemini 3 Flash, we achieved near-instant analysis of video feeds, making the tool viable for real-time emergency response.
What we learned
Multimodal Agents are the Future: Text-only logs are insufficient. Giving AI "eyes" (Video) allows it to understand context that text misses.
Tool Use is Powerful: The ability to give an LLM "arms" (SSH access) transforms it from a passive chatbot into an active agent.
What's next for Server Diagnostic AI System
We are currently working on a major upgrade to add Active Voice Intervention.
The next iteration will integrate SIP/VoIP capabilities (using PyVoIP/Zadarma).
Proactive Calling: Instead of waiting for a dashboard check, the Agent will phone call the SysAdmin immediately upon detecting a critical failure.
Human-in-the-Loop Permissions: For high-risk commands (like wiping a database or restarting a core switch), the AI will verbally describe the situation over the phone and ask for voice authorization ("Press 1 to confirm server reboot") before executing the action.
Built With
- docker-containerization
- fastapi
- fastapi-backend
- function-calling-ai
- gemini3
- google-genai-sdk
- multimodal-ai
- paramiko-library
- python-3.11
- rest-api-integration
- ssh-automation

Log in or sign up for Devpost to join the conversation.