-
-
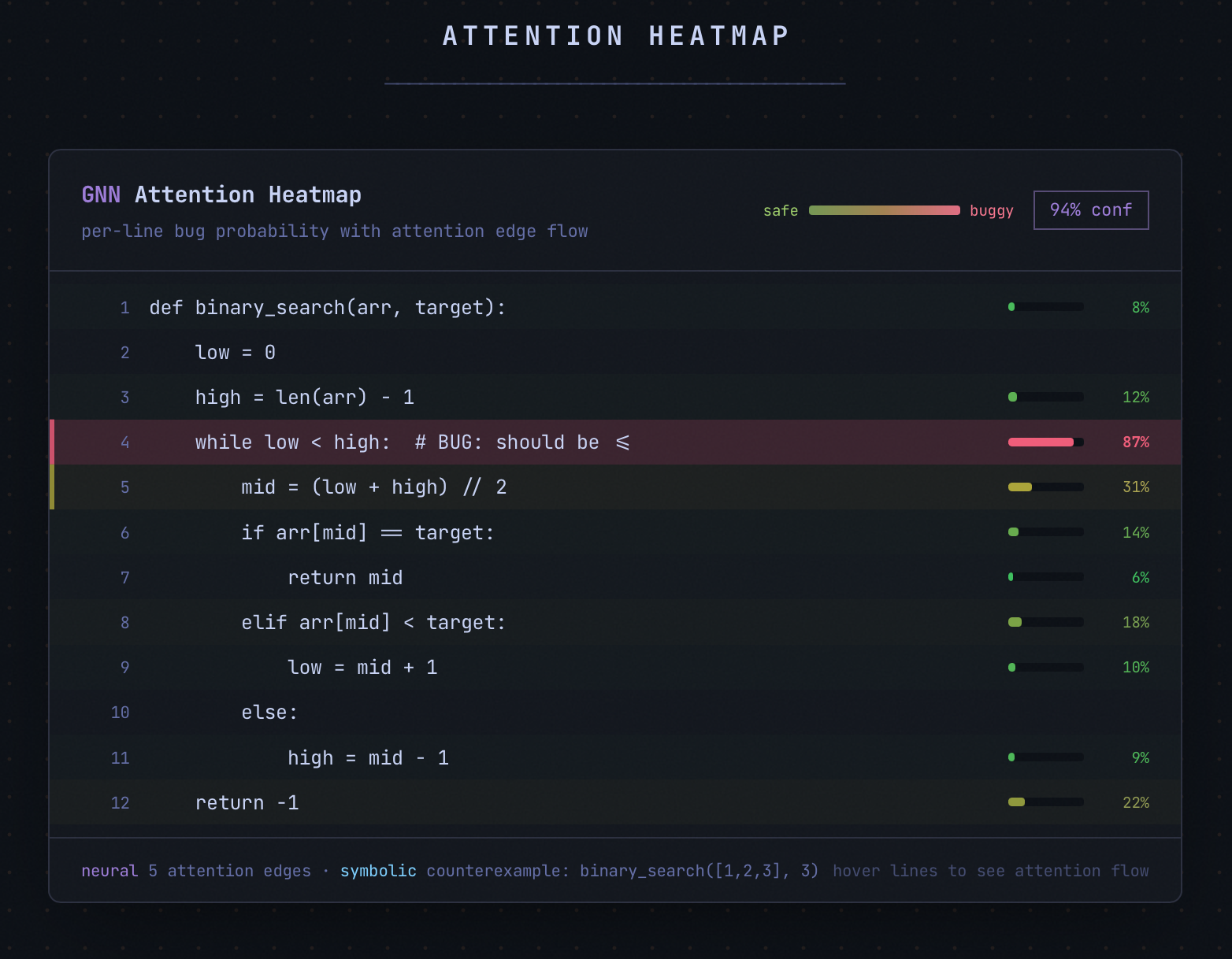
Attention Heatmap
-
-
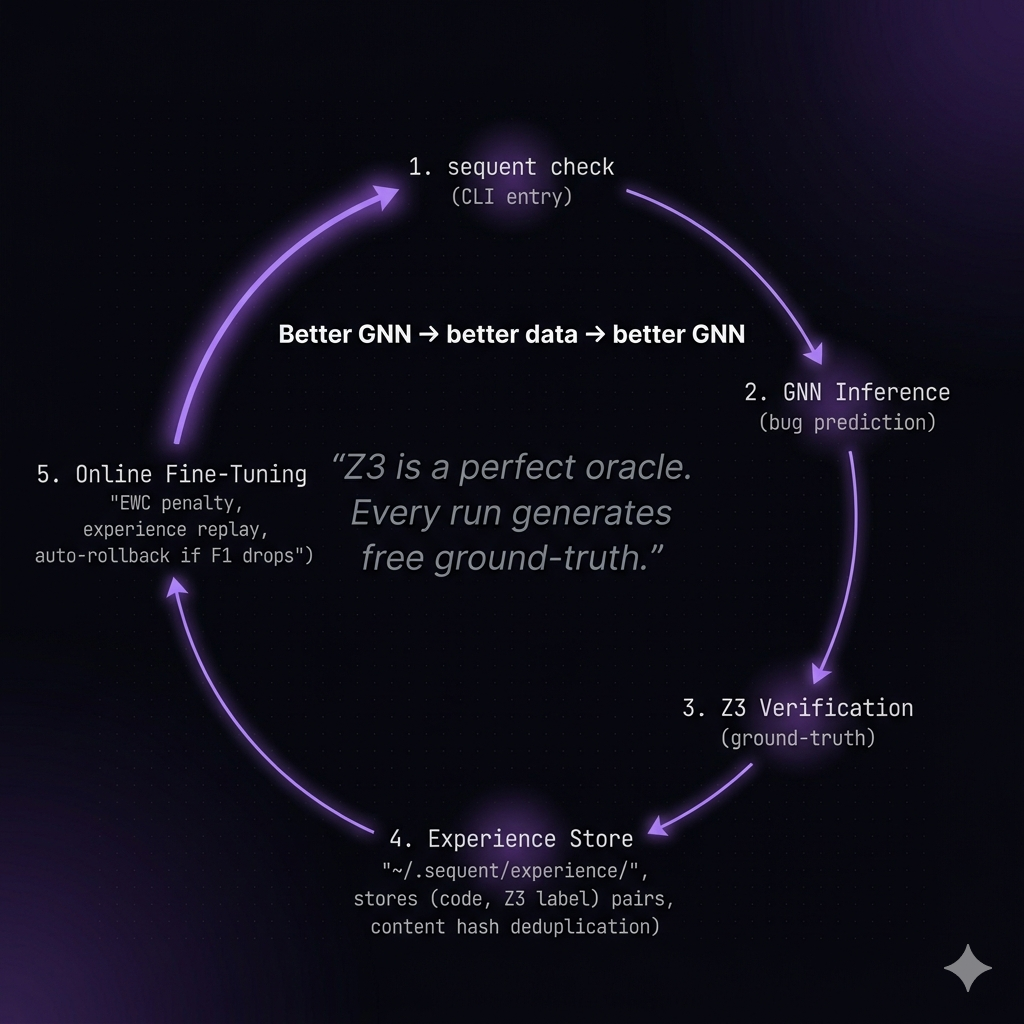
Recursive Self-Learning Loop
-
Core Pipeline
-

CPG Detail
-
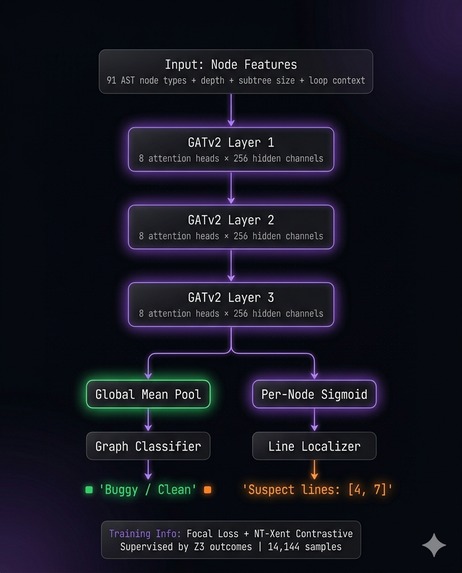
GNN Architecture
Inspiration
100 billion lines of new code are generated by AI every year and that number is doubling. Developers copy-paste LLM outputs into production with a quick glance. LLM code reviews cost more LLM calls. Linters catch formatting issues. Nobody is proving the code is actually correct. In quantitative finance, a single off-by-one error in a trading algorithm can lose millions in seconds. In deep learning research, a wrong operator in a loss function means weeks of wasted GPU time on a training run that was silently wrong from epoch 1. In safety-critical systems, an unguarded null dereference is a lawsuit. These industries don't need "this looks suspicious." They need mathematical proof.
I built Sequent because I wanted a tool that finds the exact input that breaks your function, proves it formally, fixes it, and gets smarter every time you use it. Not an LLM wrapper. Not a linter. A self-learning neurosymbolic AI that combines a trained graph neural network with Microsoft's Z3 theorem prover to do something neither can do alone. It's free to use, lightweight and improves with usage.
What it does
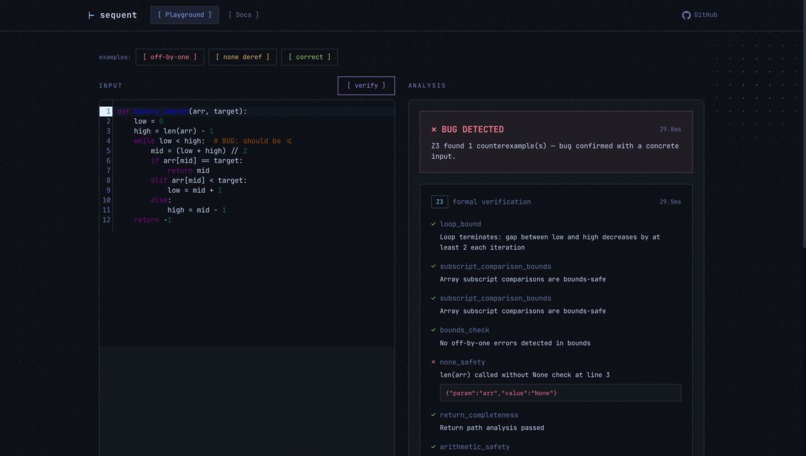
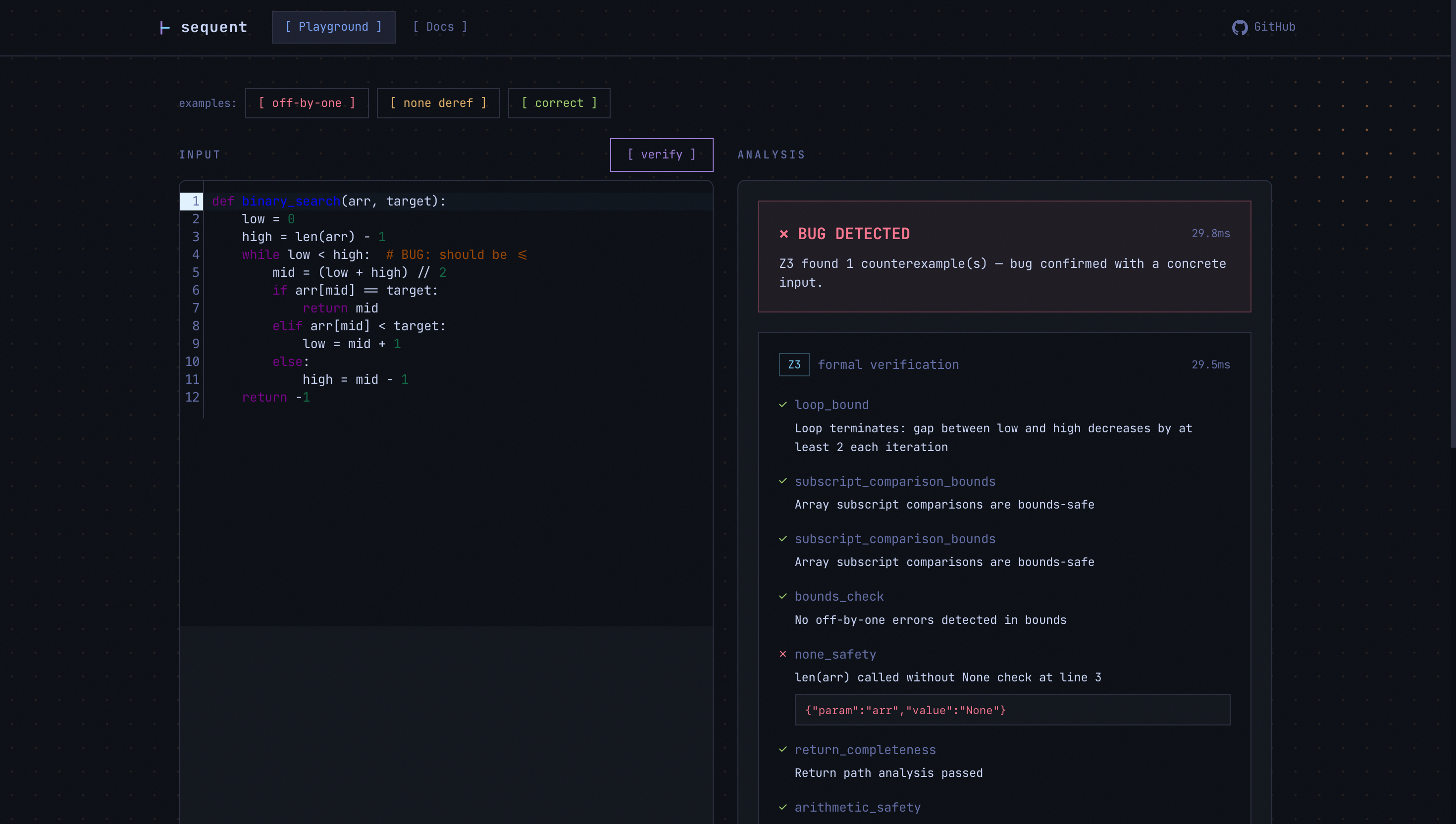
Sequent is a neurosymbolic code verification engine for Python and JavaScript/TypeScript. You give it a function. It either formally proves it correct or hands you the concrete counterexample that breaks it, like {"b": 0, "arr_length": 1}. Then it auto-generates a fix and re-verifies the fix through the same prover to confirm it actually works.
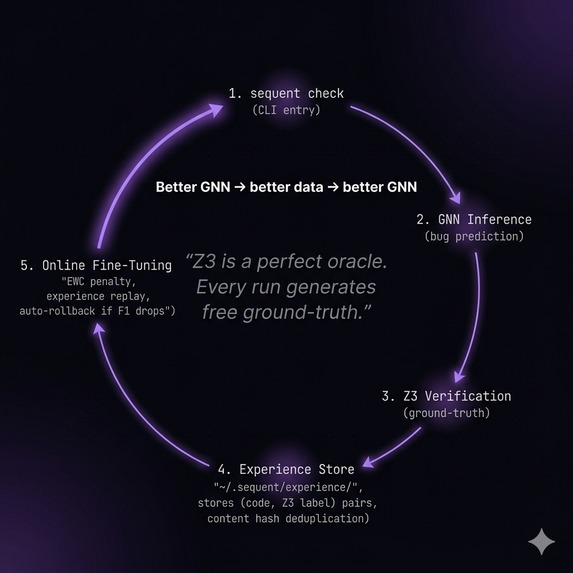
It recursively self-learns. Every verification run produces a ground-truth label from the formal prover. Those labels accumulate and periodically fine-tune the neural network's own weights with zero human annotation. The prover teaches the neural net. The neural net gets better at proposing bugs. Better proposals produce better training data. Same concept as DeepMind's AlphaGo self-play, applied to code verification. The system gets measurably more accurate the more code it analyzes.
What you get:
- Mathematical bug proofs: A concrete satisfying assignment from a theorem prover that proves the bug exists. Exportable as a JSON proof certificate for audit trails and CI pipelines.
- Auto-repair and re-verify: Generates a patched function, runs it back through the formal prover, stamps it verified or rejects the fix.
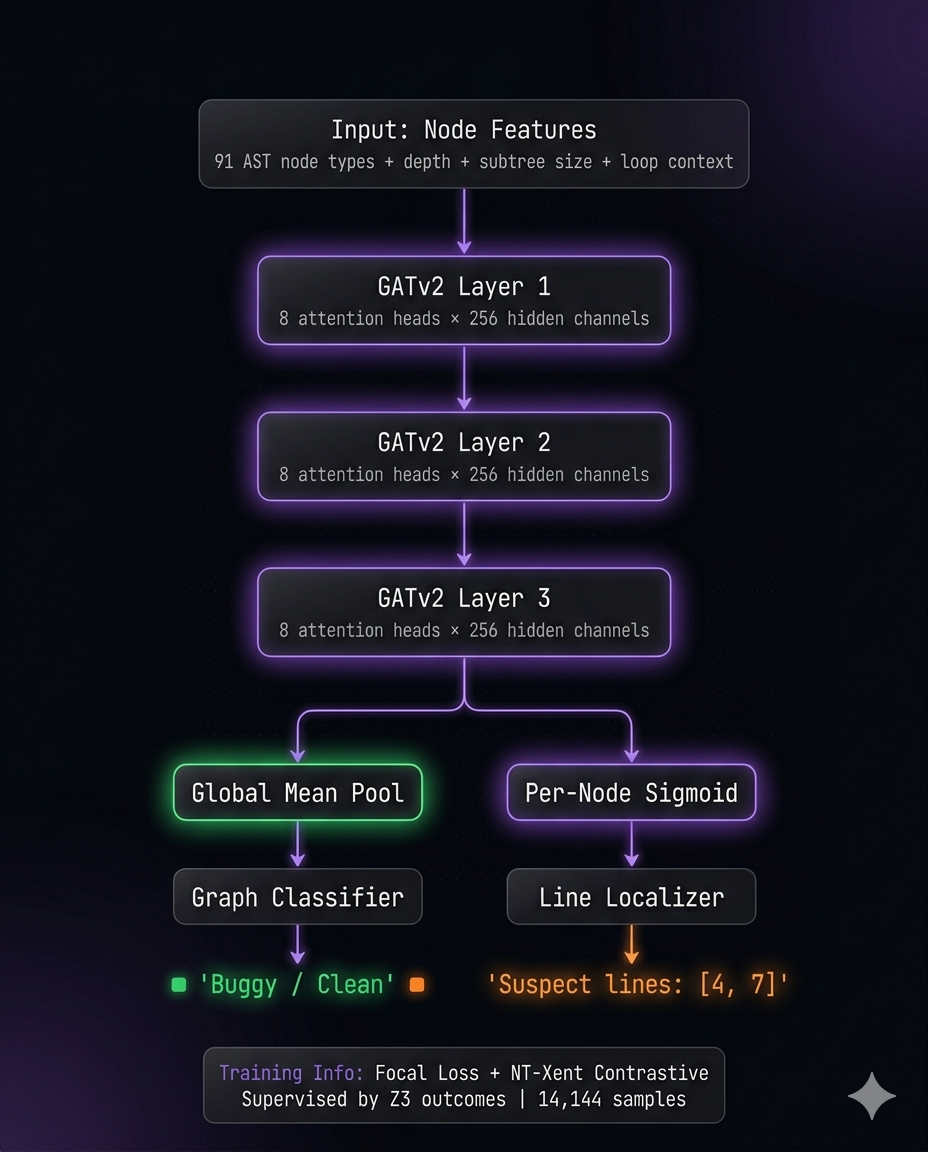
- Trained Graph Neural Network. I trained a GATv2 graph attention network (8 attention heads, 256 hidden channels, 3 message-passing layers, ~10M parameters) on 14,144 labeled code samples. 92.5% accuracy, 93.3% precision, 100% recall, 96.6% F1 on held-out test set.
- 13 formal property checks per function. Null safety, division by zero, array bounds, off-by-one detection, loop termination, dead code, operator consistency, return path completeness, integer overflow, and more.
- LSP server for any editor. Neovim, Helix, Emacs, VS Code, Cursor. Inline diagnostics, hover explanations, quick-fix code actions. No extension marketplace needed, just pip install and point your editor at it.
- Watch mode with incremental analysis. Monitors your codebase and re-verifies only the functions you changed using AST-level diffing. Sub-second feedback on save.
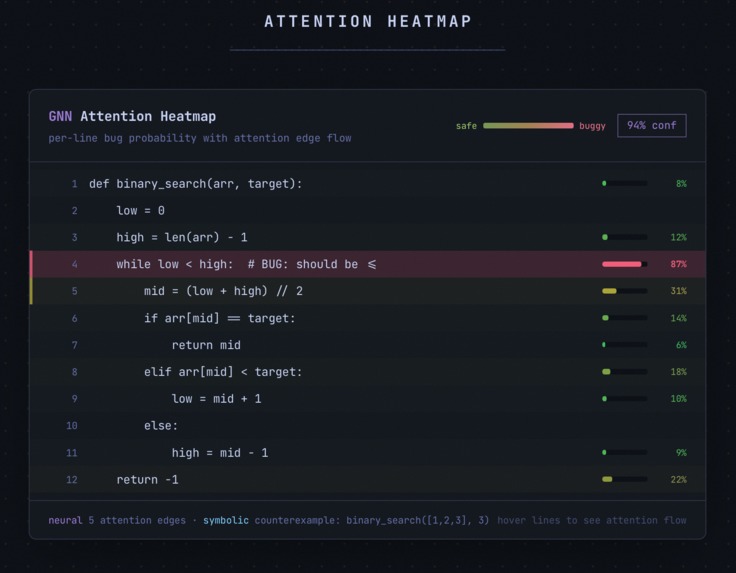
- Web playground. Paste code, hit verify, watch the GNN attention heatmap light up suspect lines in real time while the prover runs 13 property checks in parallel.
How we built it
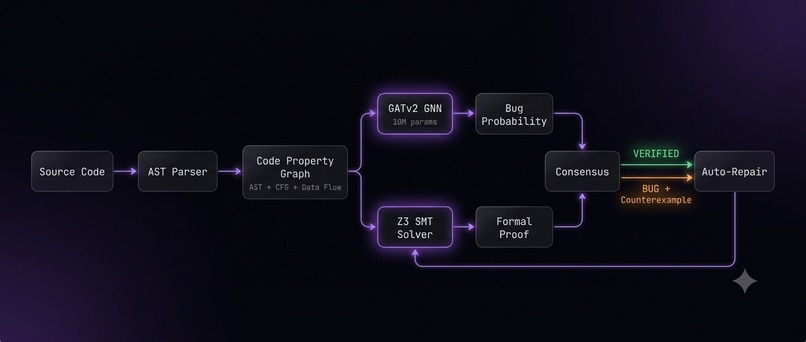
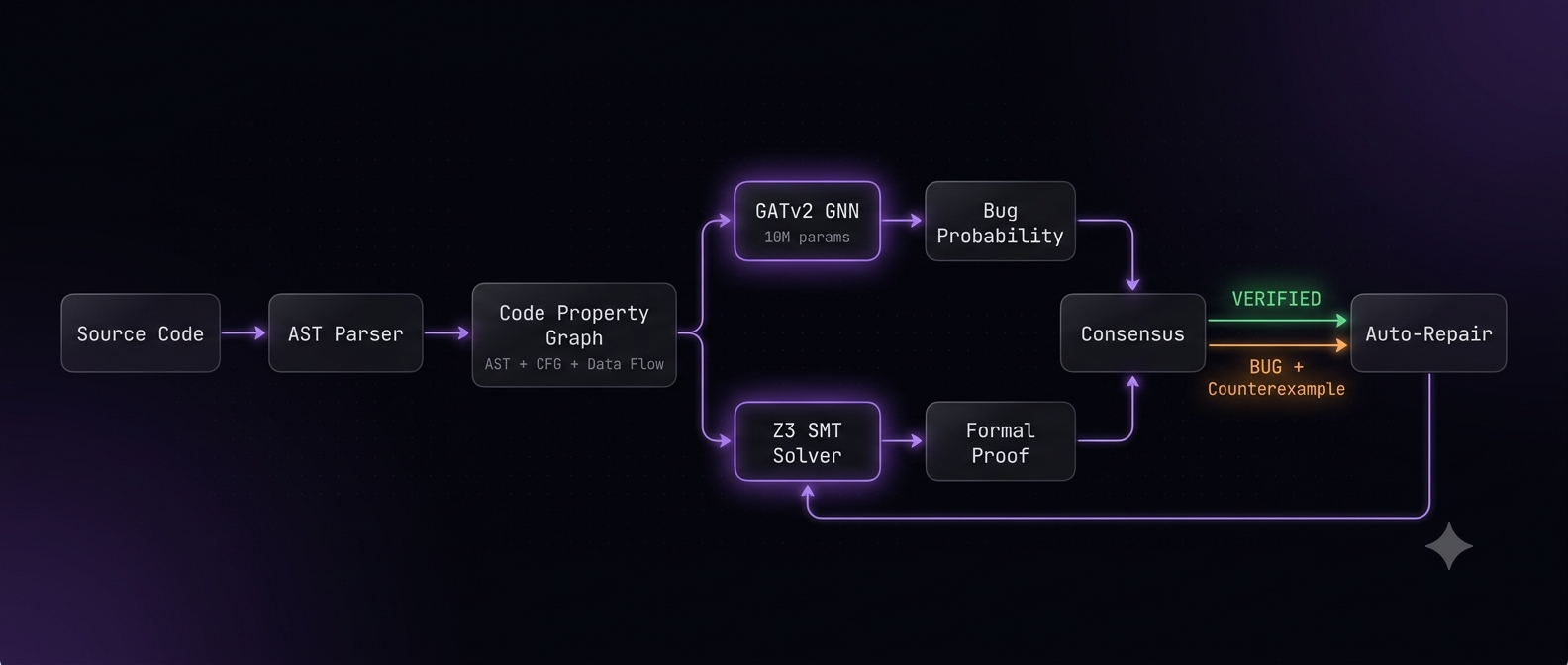
The architecture is two independent verification systems that vote through a consensus layer.
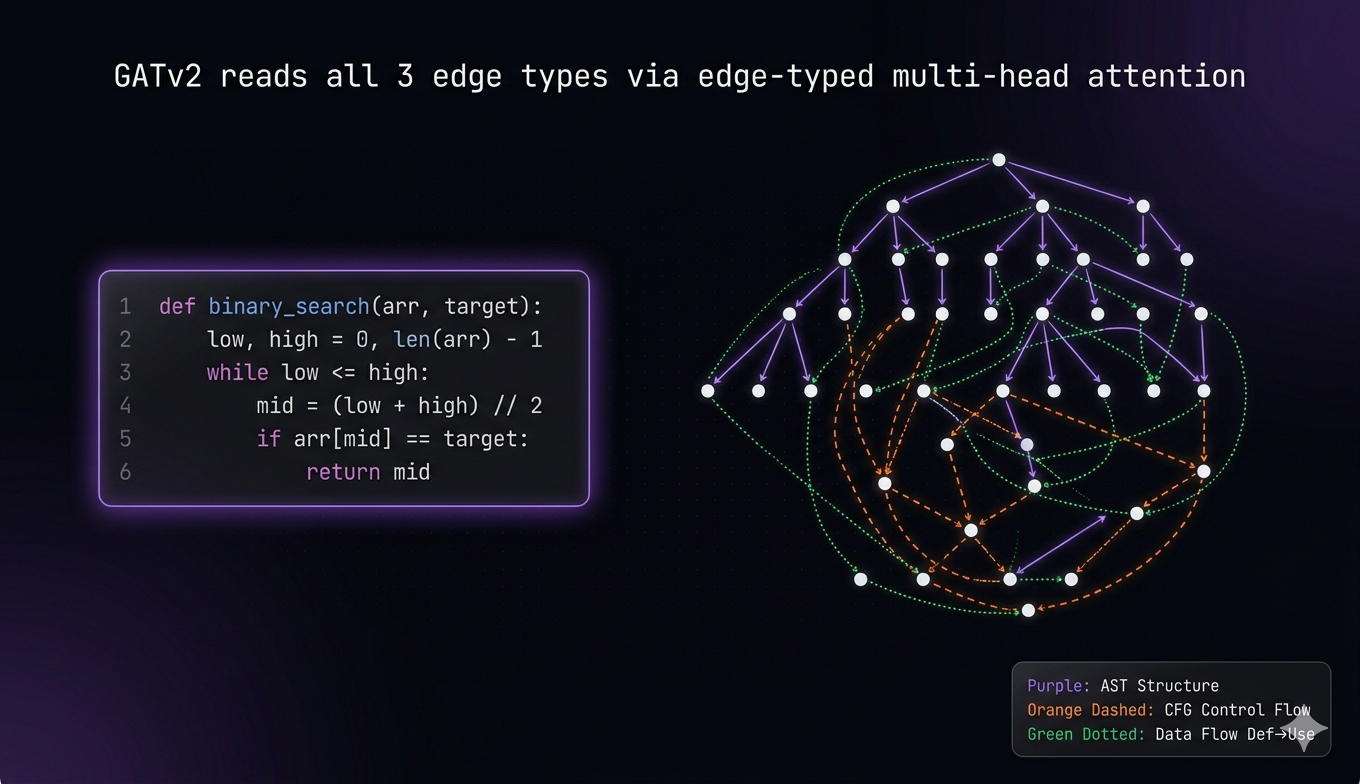
Brain 1: Graph Neural Network. I built a Code Property Graph pipeline that converts source code into a unified graph combining three representations: the abstract syntax tree (structural relationships), the control flow graph (execution paths through if/else/loops), and data flow edges (where variables are defined vs where they're used). Each node carries a 91-dimensional feature vector encoding the AST node type plus structural metadata like depth, subtree size, and loop/conditional context.
I trained a GATv2 (Graph Attention Network v2) on this representation. 8 attention heads learn different relationship patterns across the three edge types simultaneously. The network outputs two things: a graph-level classification (buggy or clean) and a per-node bug probability that localizes exactly which lines are suspicious. Training used focal loss to handle class imbalance (buggy nodes are rare) plus NT-Xent contrastive loss so the model pushes buggy and clean code embeddings apart in representation space. The formal prover generated all 14,144 ground-truth labels automatically. Trained on an RTX 4070.
Brain 2: Z3 Formal Prover. Microsoft's Z3 SMT (Satisfiability Modulo Theories) solver exhaustively checks 13 property classes against your code. For each property, it either proves it holds for all possible inputs or finds a satisfying assignment that violates it. That assignment is your counterexample. This isn't sampling or fuzzing. It's an exhaustive mathematical proof over the entire input space.
I built a constraint extractor that pulls assignment relationships (high = len(arr) - 1), computed expressions (mid = (low + high) // 2), and loop guards (while low <= high) from the full function body and feeds them into the solver. This lets Z3 reason about variable relationships across the entire function, not just isolated expressions.
Consensus. Neither brain can issue a verdict alone. The GNN proposes, Z3 disposes. Both must agree before a function is marked buggy or verified. This eliminates the neural net's false positives and catches bugs the GNN misses.
Self-learning loop. Every verification stores a (code, Z3 verdict) experience in ~/.sequent/experience/, deduplicated by content hash. When 50+ new samples accumulate, the GNN fine-tunes using elastic weight consolidation to prevent catastrophic forgetting, mixed with replay from the original training set. If validation F1 drops, it auto-rolls back to the previous checkpoint. The system ships improvements to its own weights without any human in the loop.
Published on PyPI as sequent-verify. 170 tests across 10 test files. Full CI pipeline on GitHub Actions.
Challenges we ran into
The formal prover was generating false positives on correct code. A properly guarded binary search with while low <= high and mid = (low + high) // 2 was getting flagged for array-out-of-bounds because the solver was checking arr[mid] in isolation without knowing that mid is mathematically bounded by the loop condition and the array length. I had to build the constraint extraction system that reconstructs variable relationships from assignments and loop conditions across the entire function body.
The symbolic executor was duplicating checks exponentially across branching paths, producing 2000+ identical verification results for a 12-line function. Fixed with deduplication at the emission layer. False positive rate determines whether anyone actually uses the tool. I ended up demoting speculative checks (like potential) 32-bit overflow) to informational warnings that don't affect the verdict, while keeping high-confidence violations (null deref, division by zero, proven array out-of-bounds) as hard counterexamples.
Accomplishments that we're proud of
Trained a GATv2 graph neural network from scratch on 14,144 code samples and achieved 89.7% F1 on bug detection. Built a constraint extraction system that feeds variable relationships and loop guards into Microsoft's Z3 theorem prover so it reasons about entire functions, not isolated expressions. The recursive self-learning loop fine-tunes the GNN's own weights from verification outcomes with zero human labeling. Benchmarked against Claude Opus 4.6, GPT-4o, Pylint, and Pyflakes on 20 hand-crafted cases covering off-by-one errors, null dereferences, division by zero, wrong operators, and mutation bugs. Sequent matched frontier LLMs on bug recall (100%) with 35,000x fewer parameters while producing formal mathematical proofs instead of natural language guesses. Pylint and Pyflakes caught 0% of logic bugs. Verified over 200 functions during development with an average latency of 180ms per function.
What we learned
Neural networks and formal provers are complementary in a way I didn't expect. The GNN is fast but approximate. The prover is slow but mathematically exact. Together they catch more bugs than either alone. The real breakthrough was realizing the prover generates free, perfect training labels on every run. That's what makes recursive self-improvement possible without any human annotation. I also learned that false positive rate is the single most important metric for developer tools. A tool that cries wolf on correct code is worse than no tool at all, no matter how many real bugs it catches.
What's next for SEQUENT
Cross-language verification across Python and TypeScript in a single pass. GitHub Actions integration that posts proof certificates directly as PR check annotations. Expanding the property checker to handle concurrency bugs and race conditions. Deeper self-learning cycles with larger experience pools as more developers use it.
Built With
- codemirror
- fastapi
- githubactions
- python
- pytorch
- pytorch-geometric
- react
- tailwind-css
- vite
- z3-smt-solver
Log in or sign up for Devpost to join the conversation.