-
-
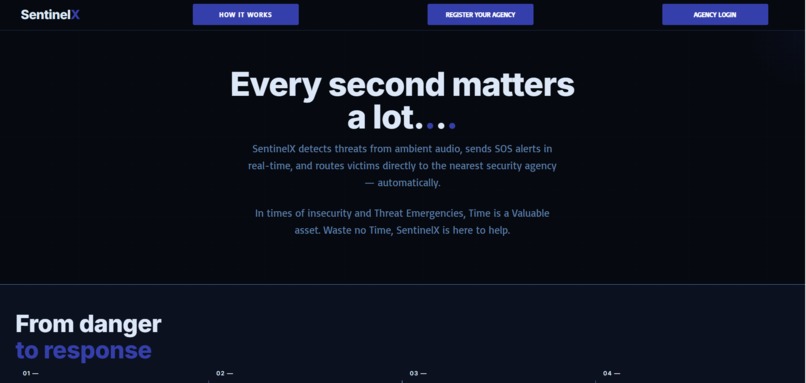
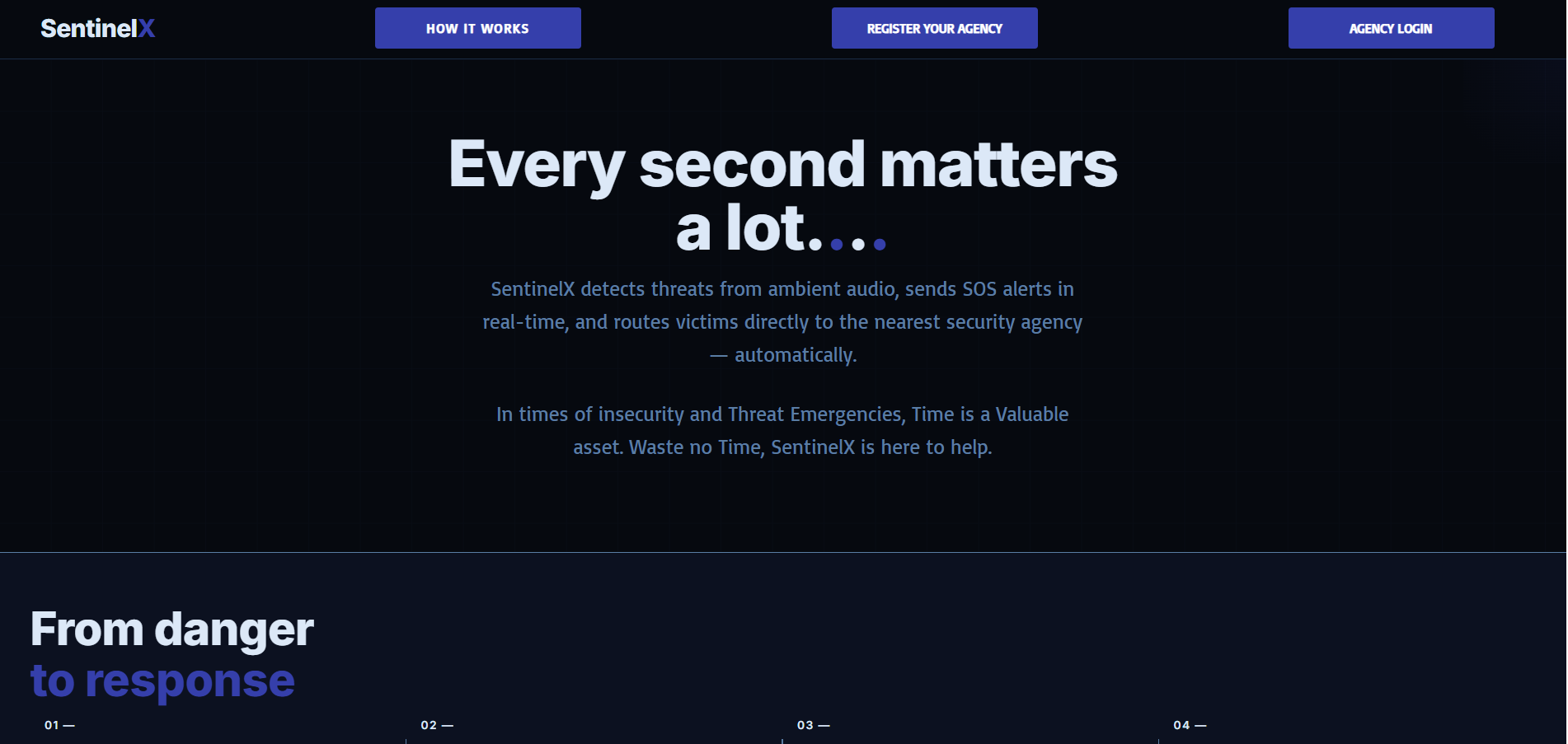
SENTINELX_NGO_WEB_DASHBOARD_HOME
-
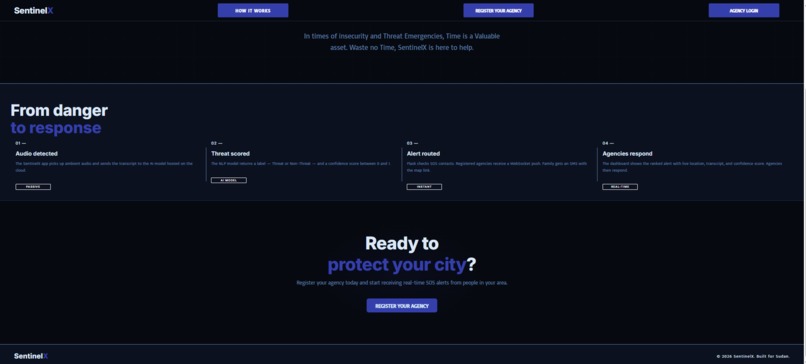
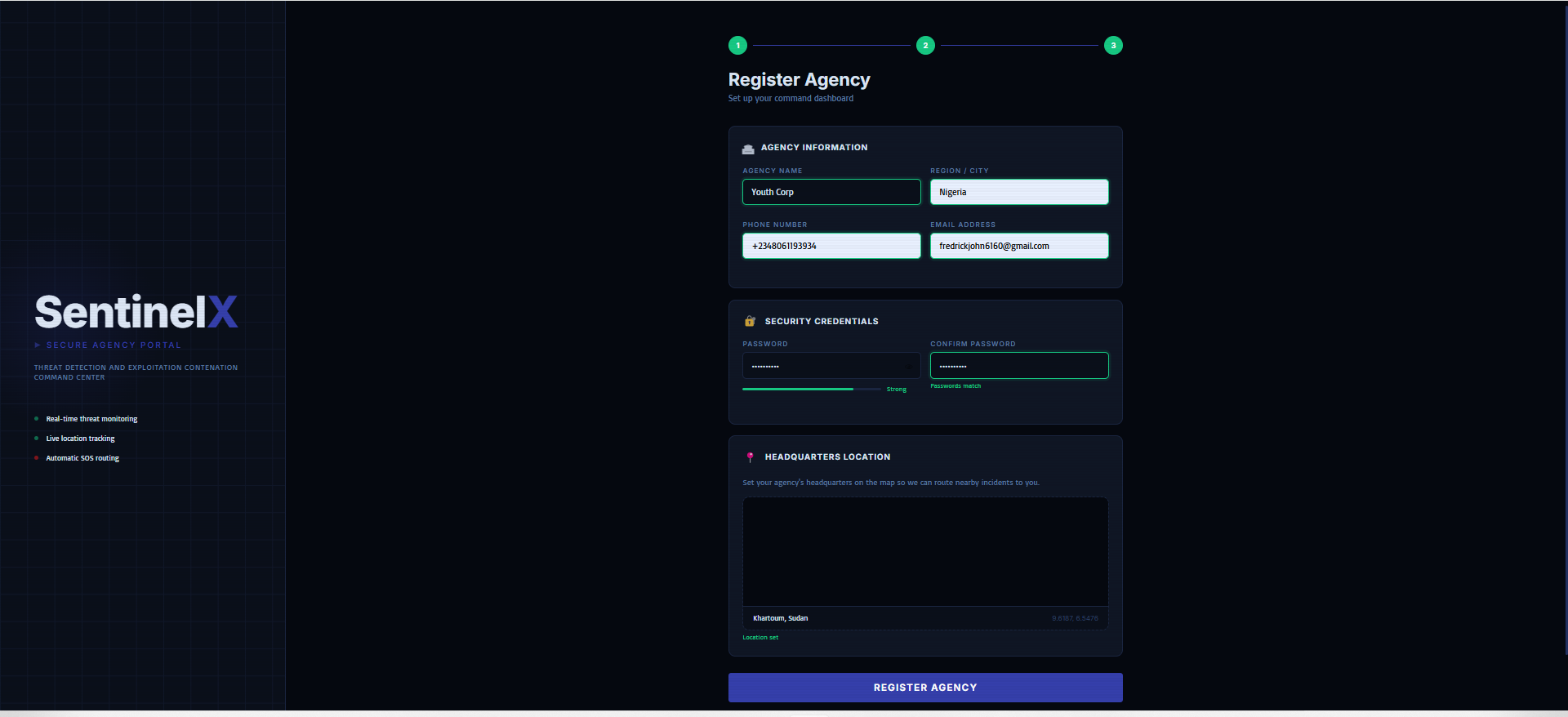
SENTINELX_NGO_WEB_DASHBOARD_ONBOARDING 1(REGISTER_YOUR_ORGANIZATION)
-
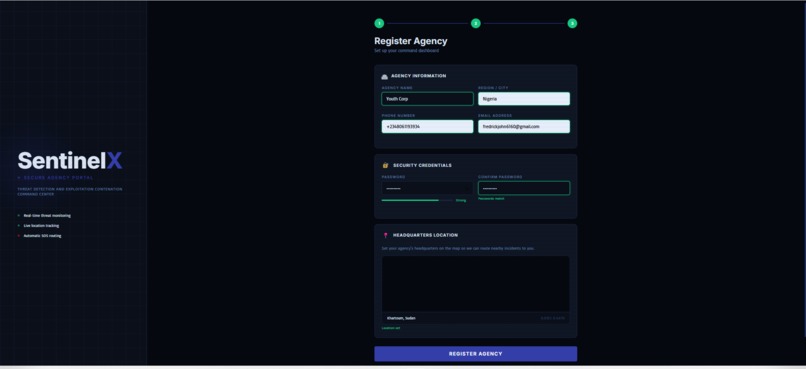
SENTINELX_NGO_WEB_DASHBOARD_ONBOARDING 2(REGISTER_YOUR_ORGANIZATION_WITH _YOUR_CURRENT_LOCATION)
-
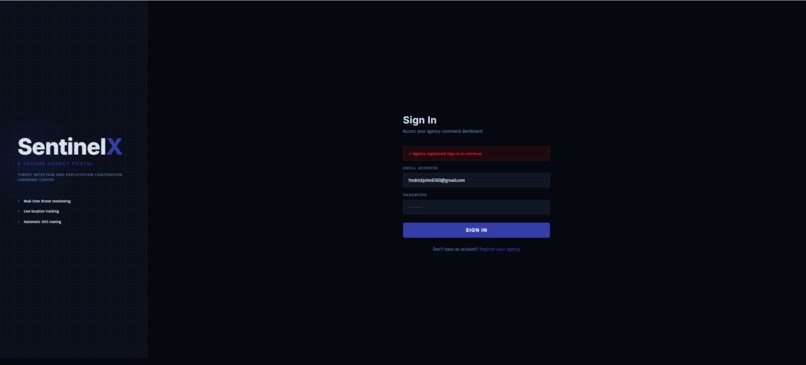
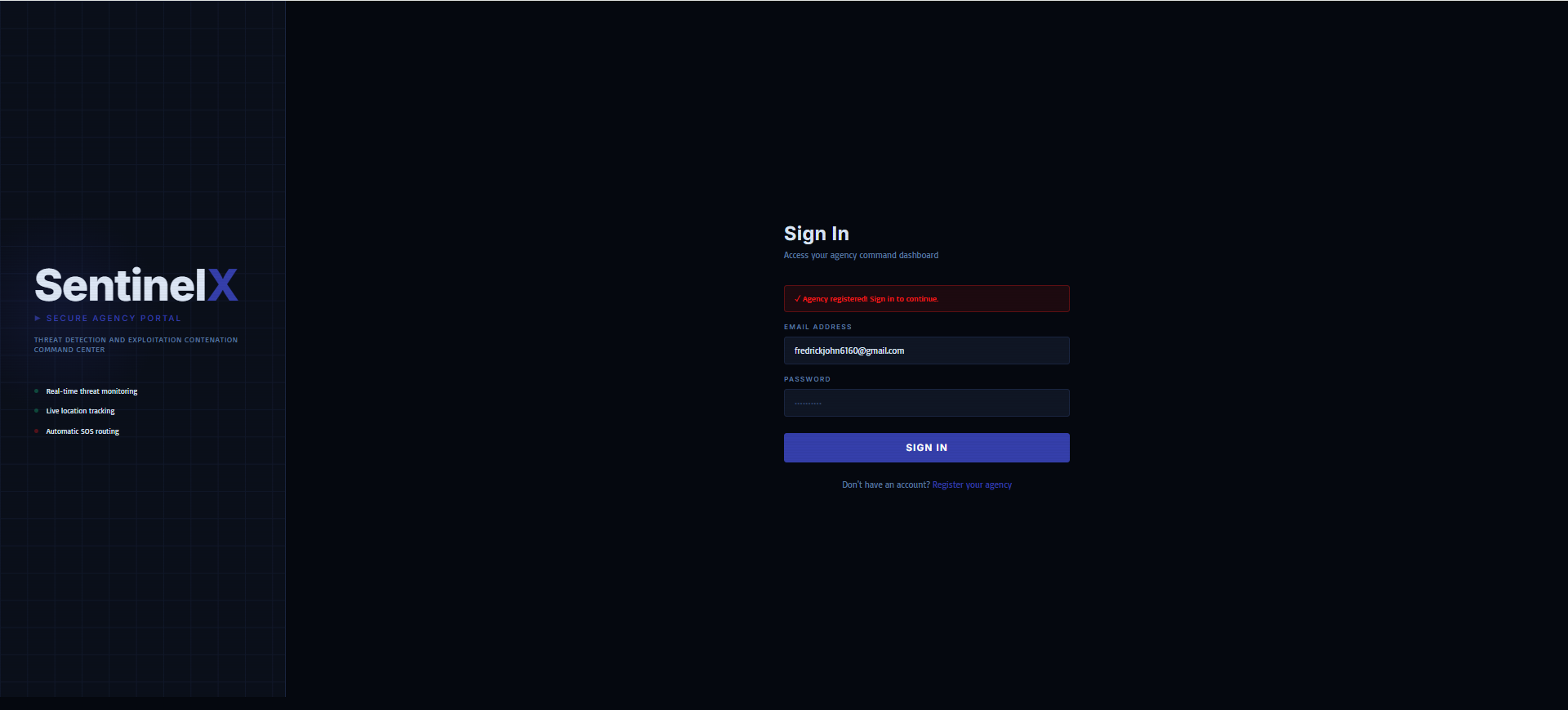
SENTINELX_NGO_WEB_DASHBOARD_ONBOARDING 3(SIGN_IN_YOUR_REGISTERED_ORGANIZATION)
-
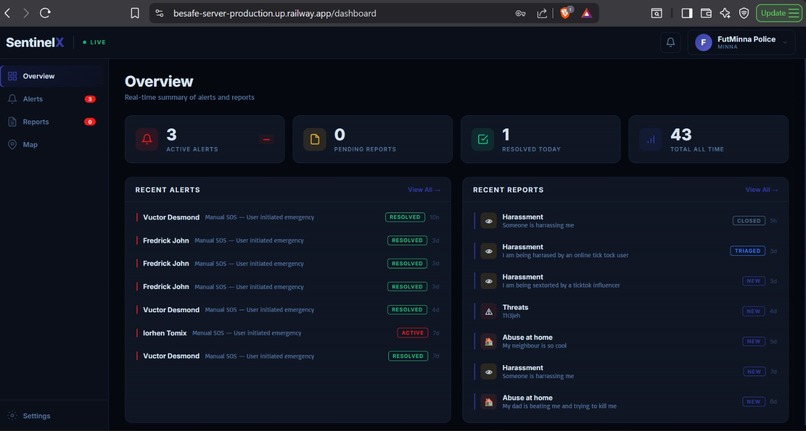
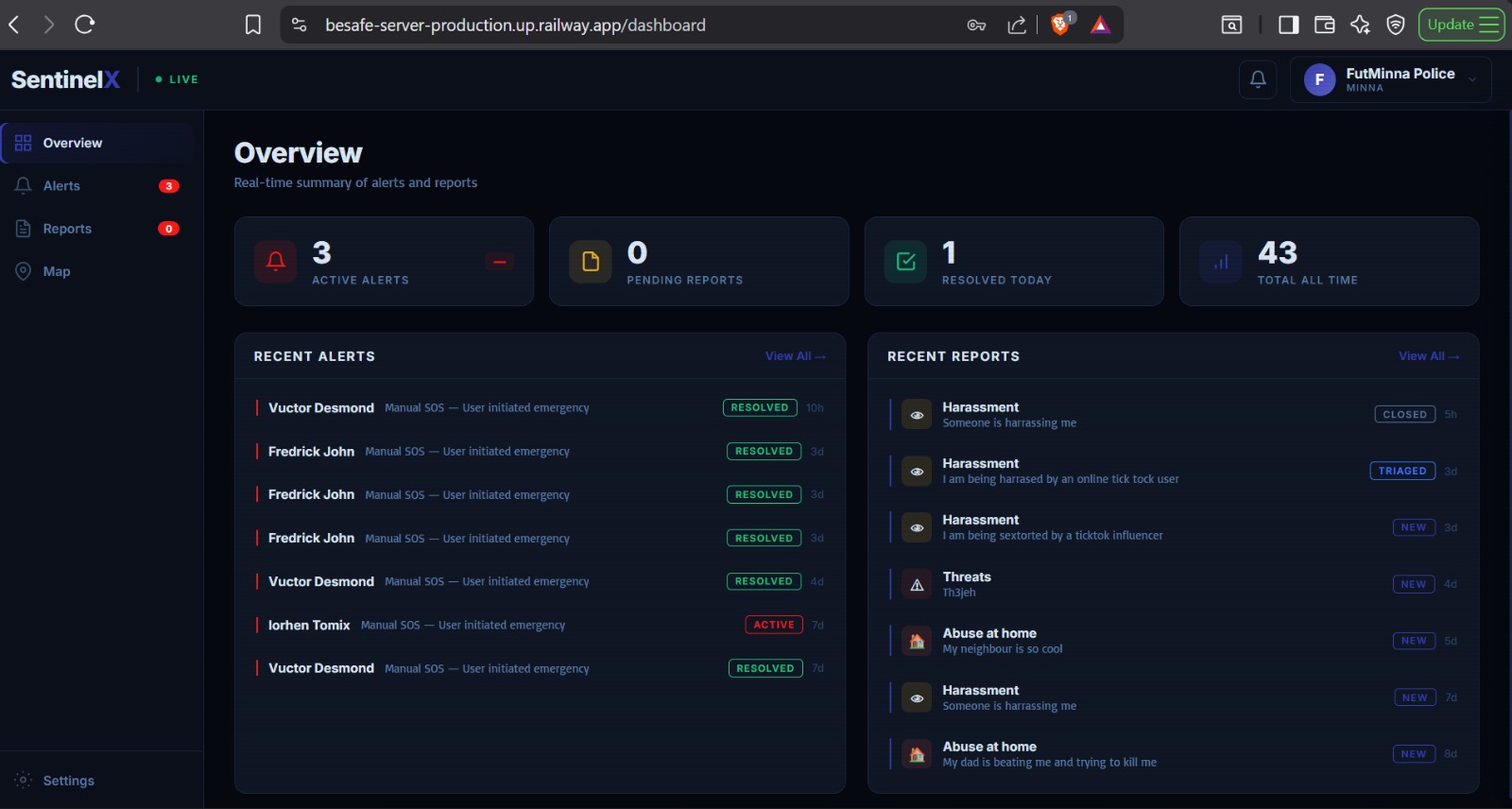
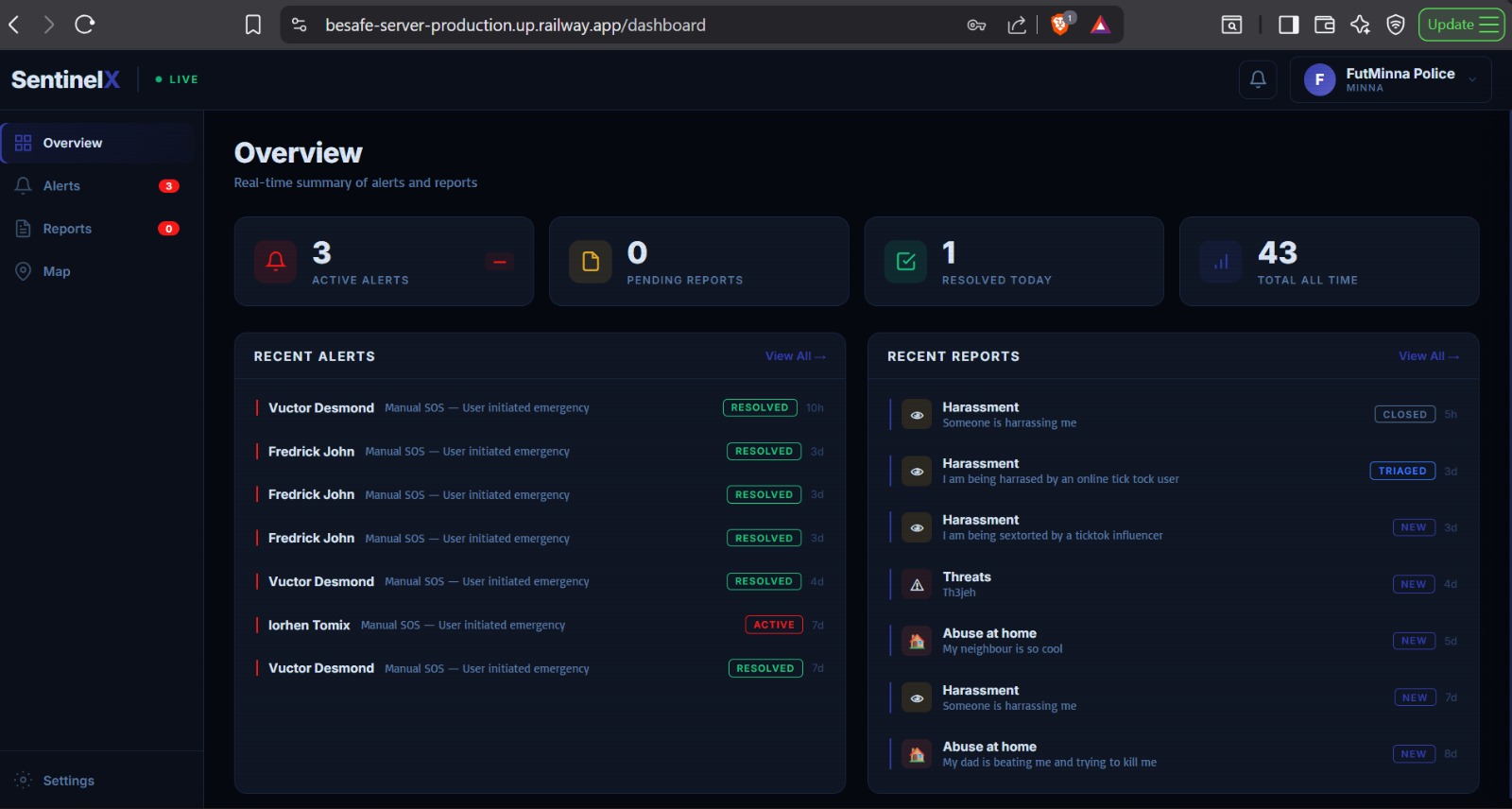
SENTINELX_NGO_WEB_DASHBOARD_WITH_HOME_ALERT
-
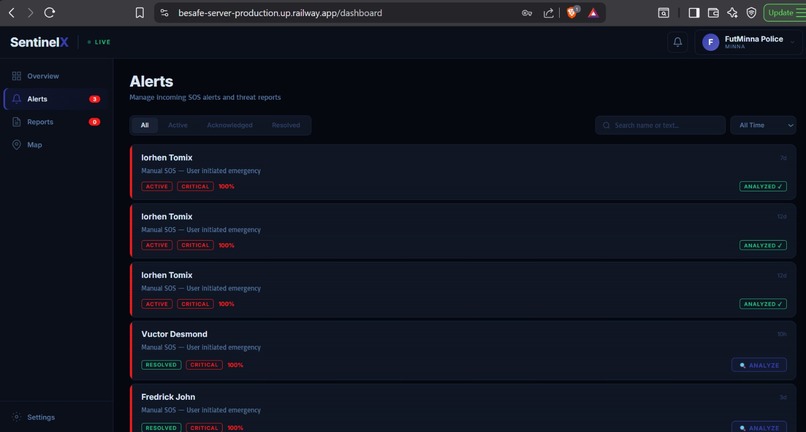
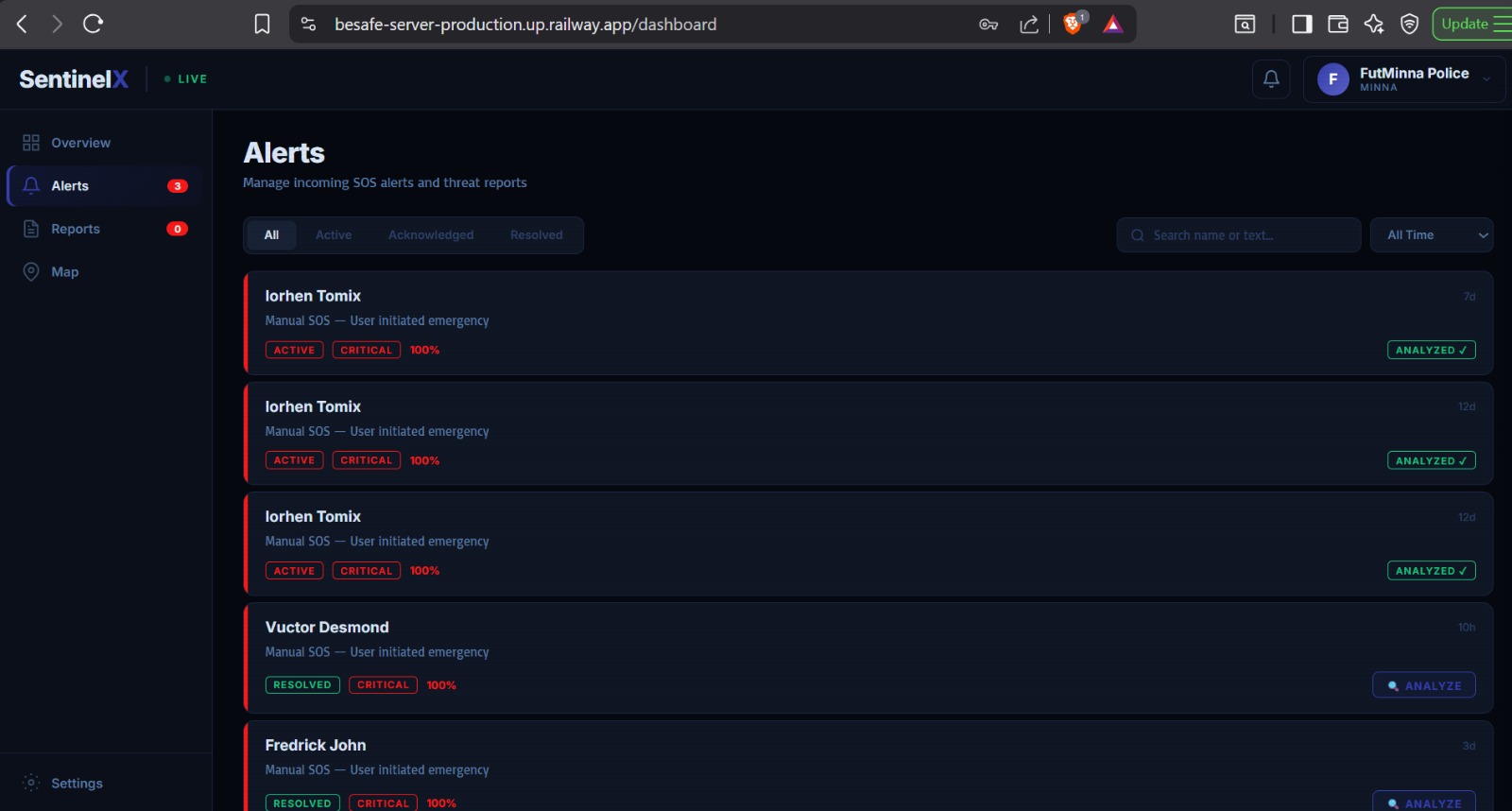
SENTINELX_NGO_WEB_ALERT_QUEUE_TABLE_FILTER
-
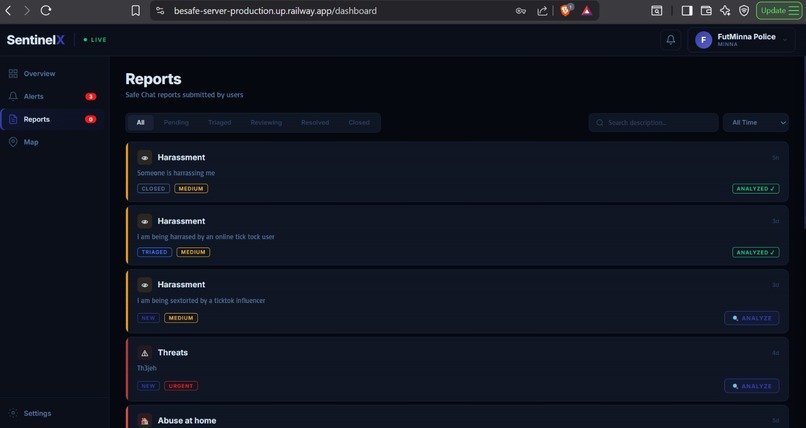
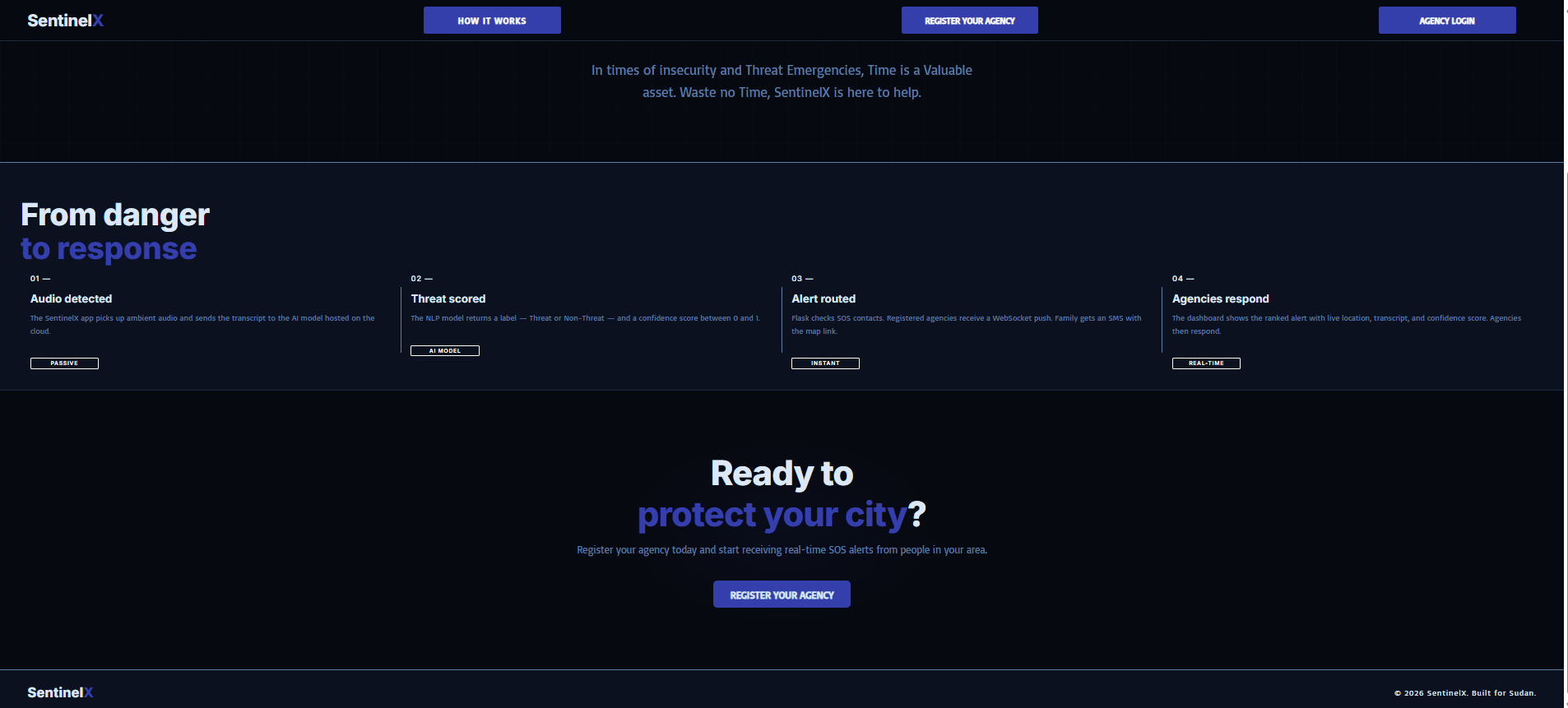
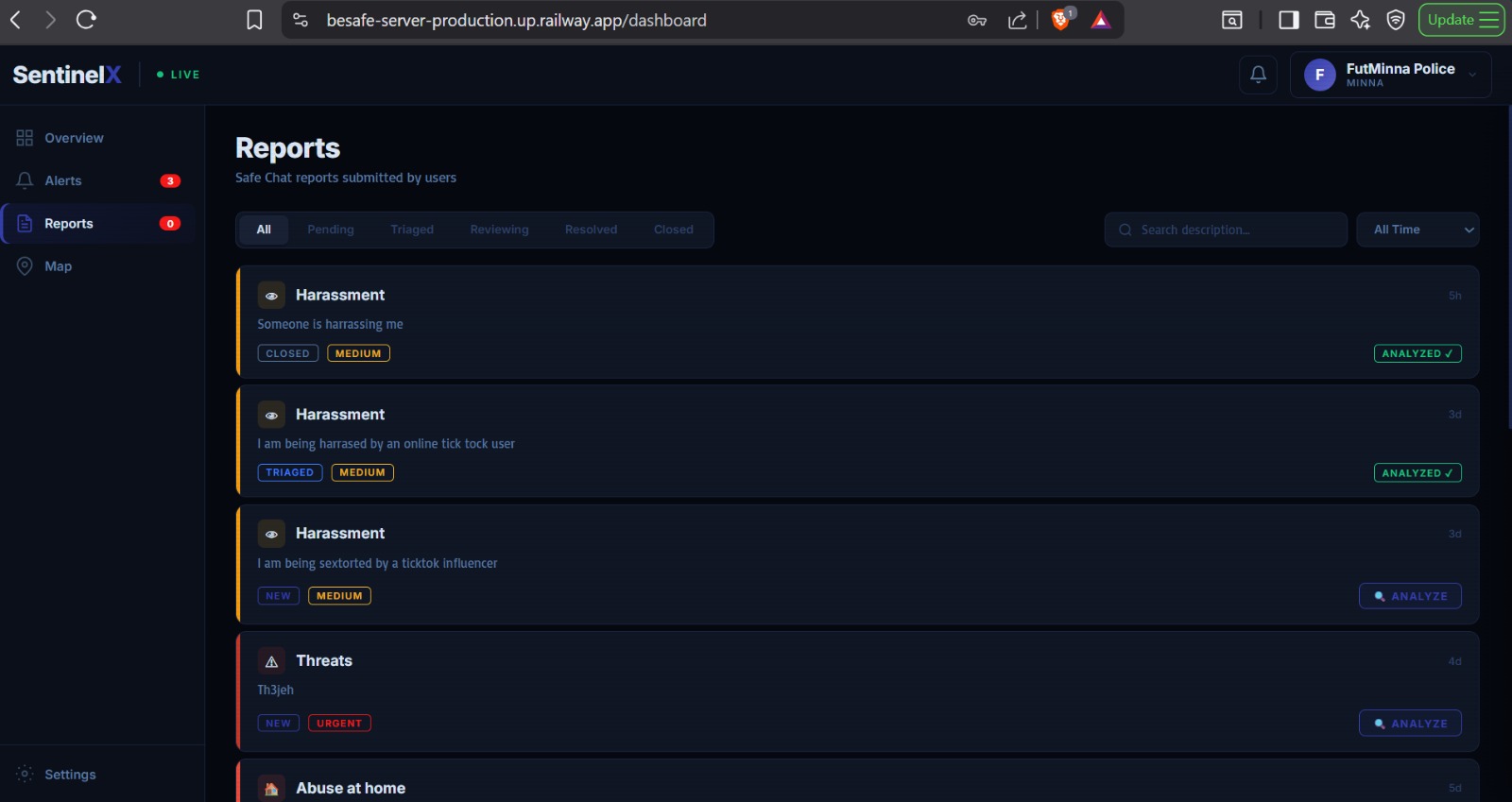
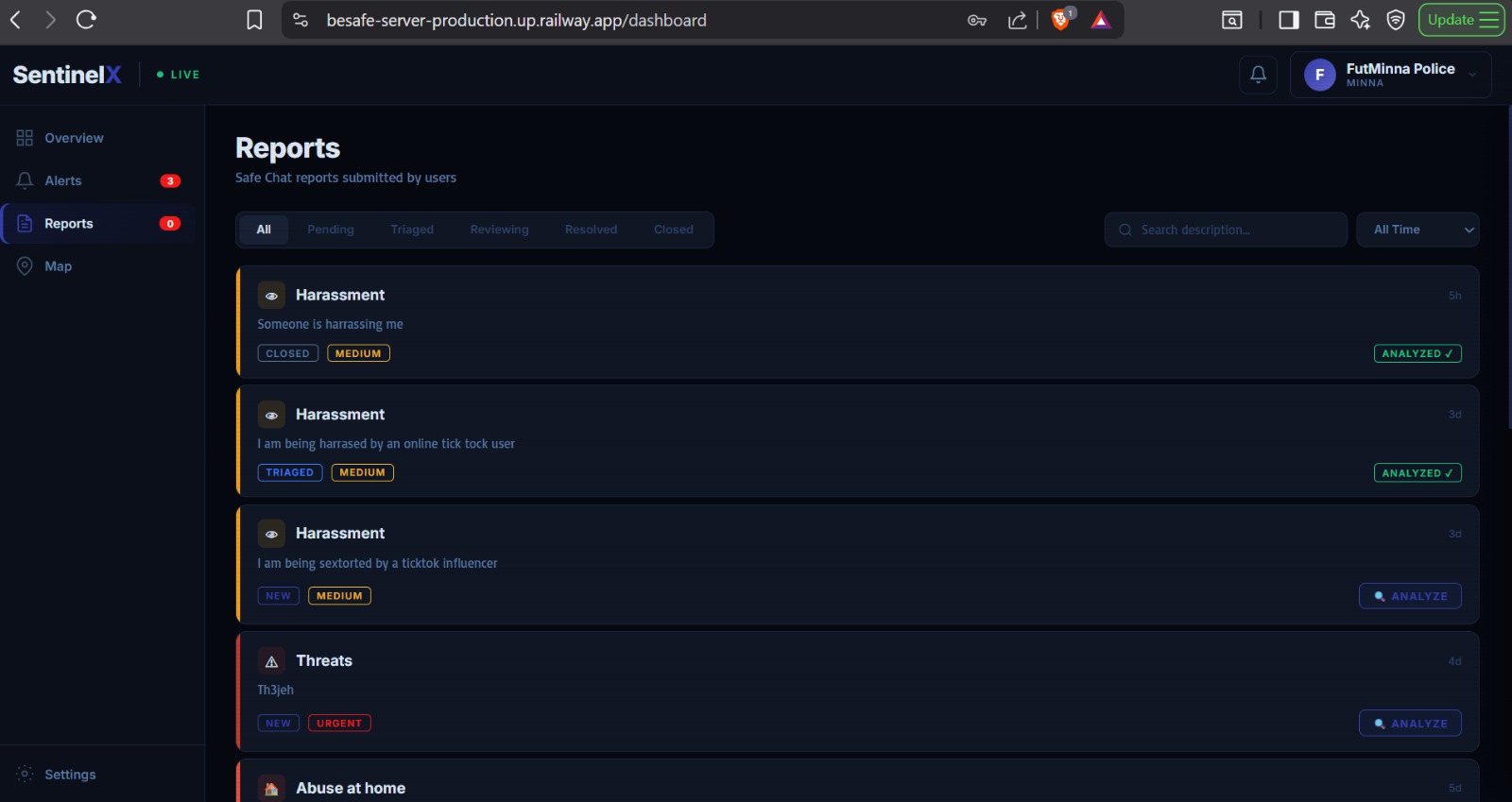
SENTINELX_NGO_WEB_REPORTS_QUEUE
-
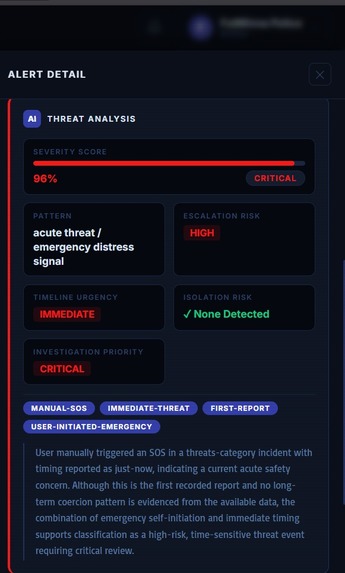
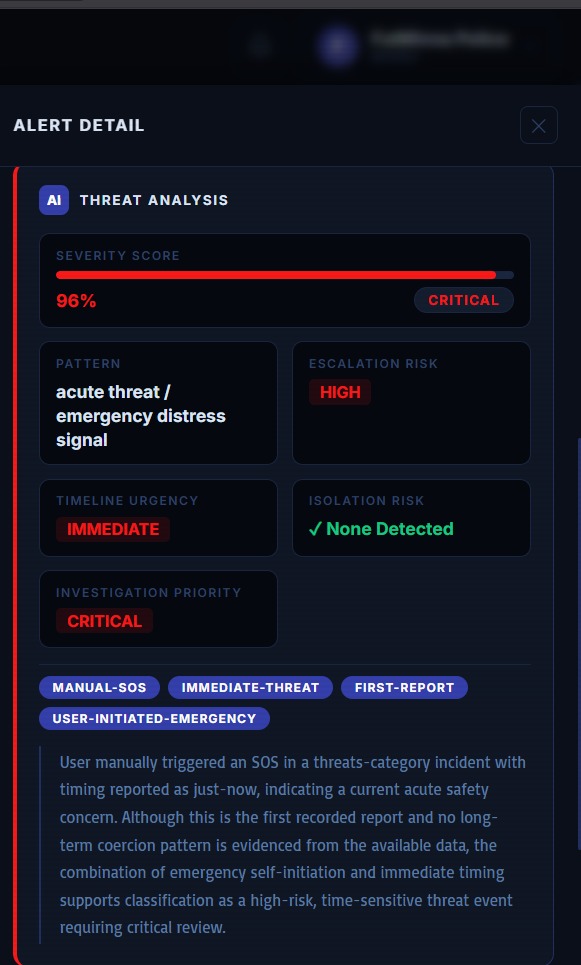
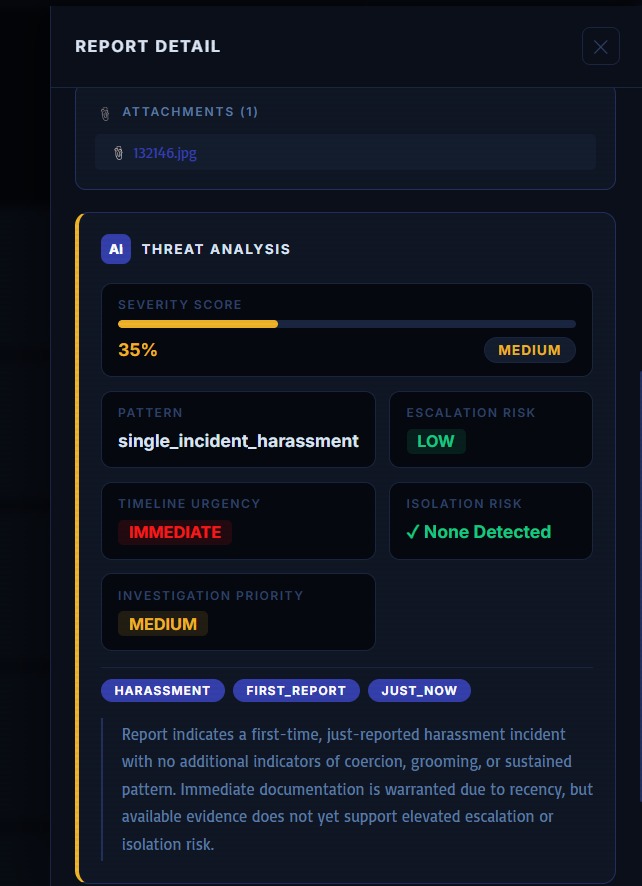
SENTINELX_NGO_WEB_XAI_ALERT_PANEL
-
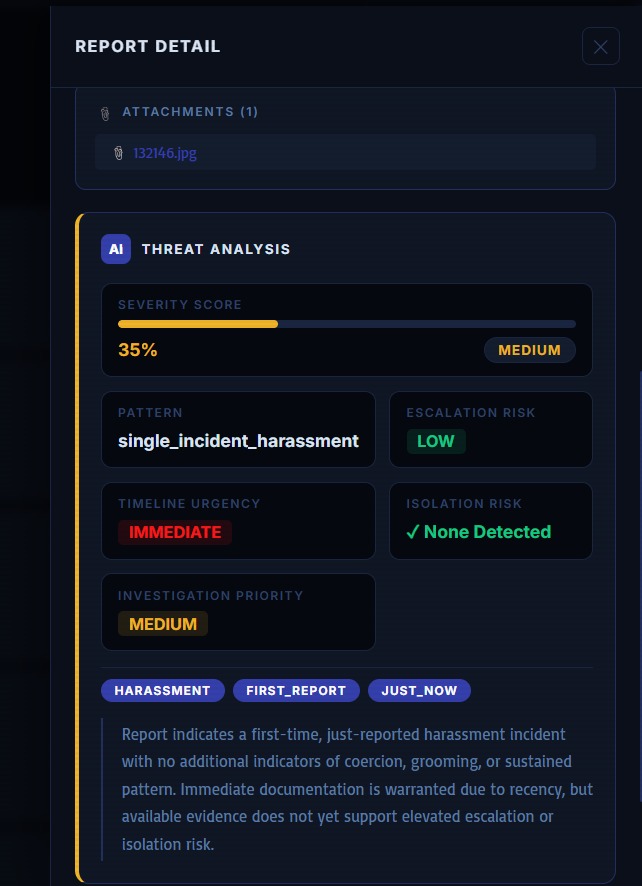
SENTINELX_NGO_WEB_XAI_ANALYSIS
-
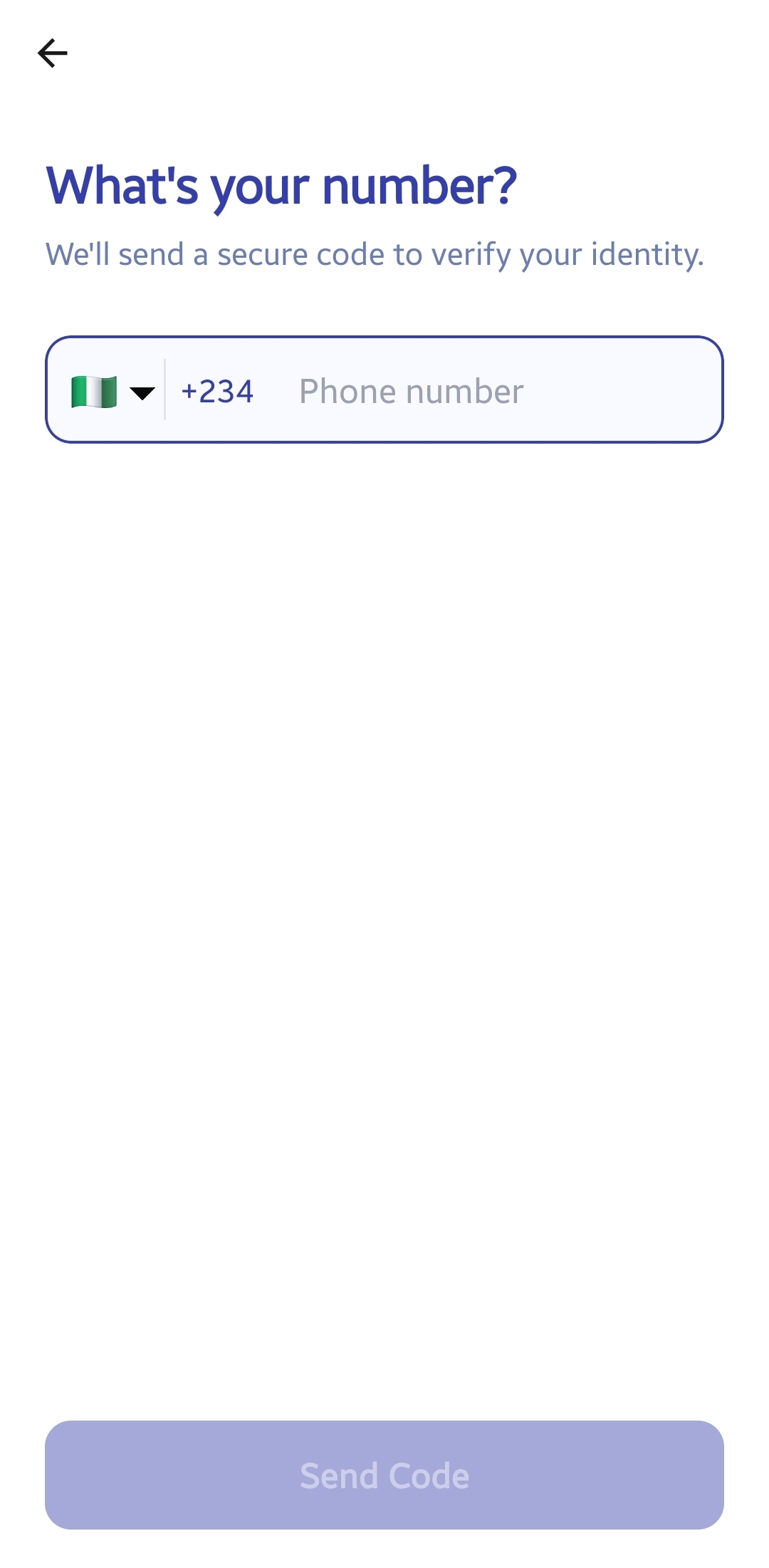
ONBOARDING_PROCESS_ON_MOBILE_APP(2. INPUT_PHONE_NUMBER)
-
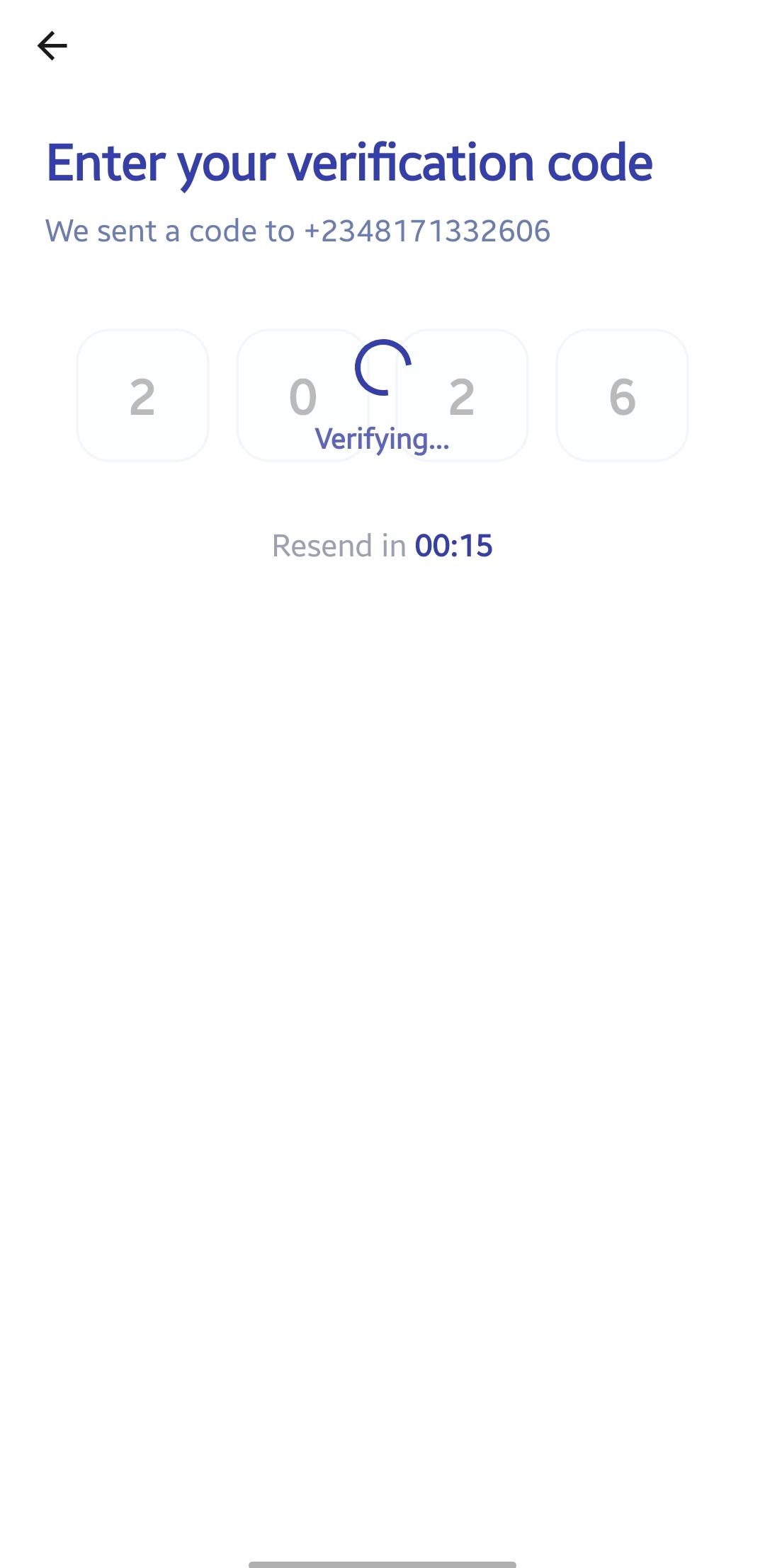
ONBOARDING_PROCESS_ON_MOBILE_APP(3. OBTAINING_OTP) NOTE: HARD_CODED_OTP: 2026
-

ONBOARDING_PROCESS_ON_MOBILE_APP(4. ALLOWING_LOCATION_ACCESS)
-

SENTINELX_MOBILE_SOS_SCREEN_HOME_PAGE
-

SENTINELX_MOBILE_DETECT_THREAT_SCREEN
-

SENTINELX_SAFE_CHAT_ICON
-
-
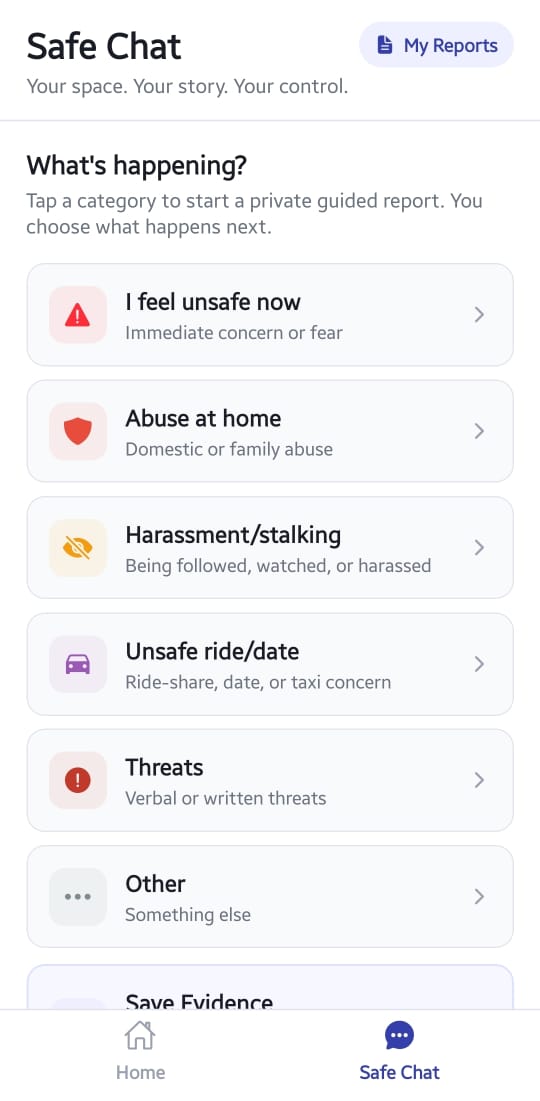
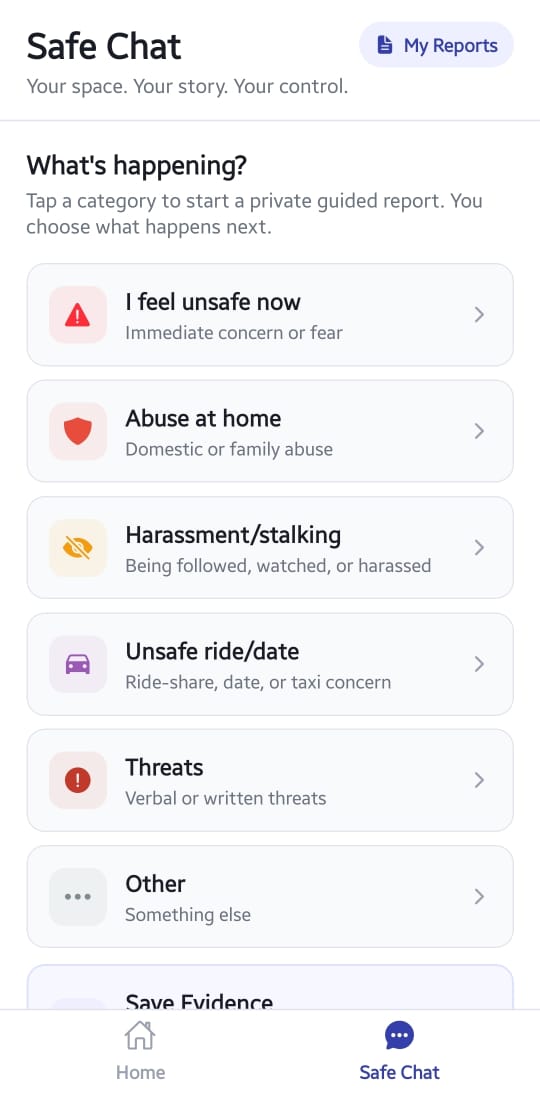
SENTINELX_SAFE_CHAT_STEP1_(CATEGORY)
-
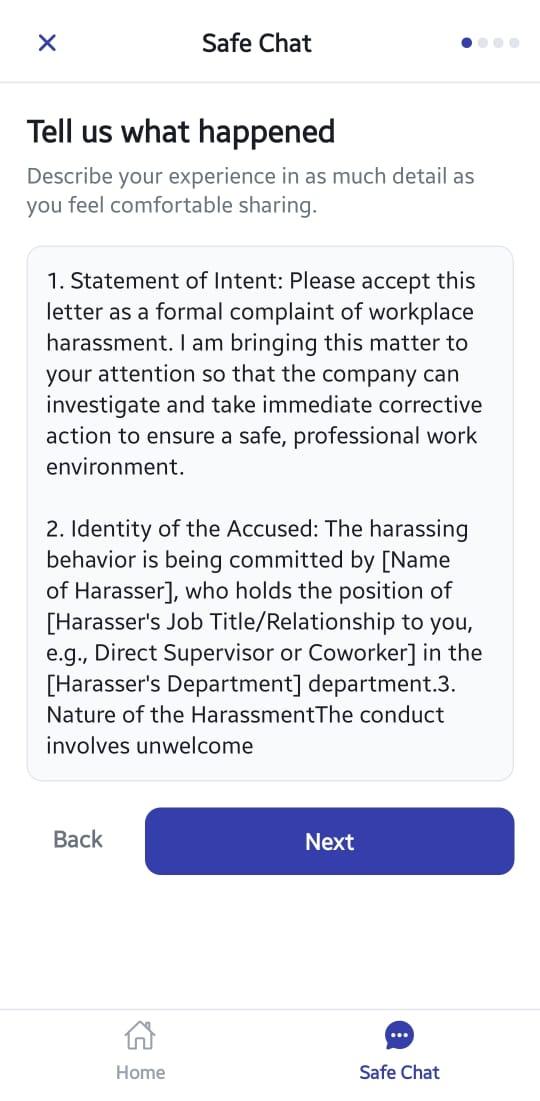
SENTINELX_SAFE_CHAT_STEP2_(NARRATIVE)
-
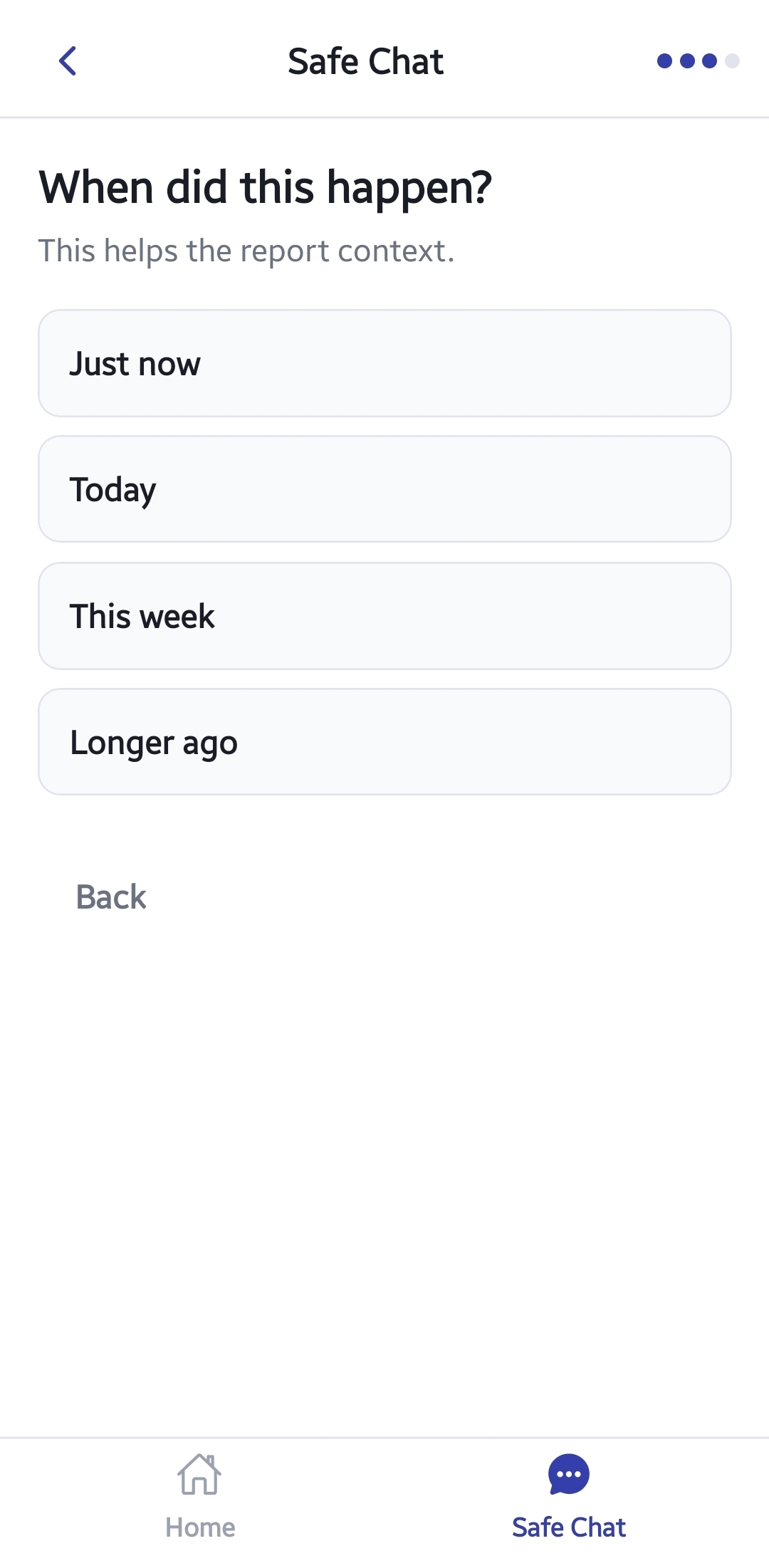
SENTINELX_SAFE_CHAT_STEP3_(TIMING)
-
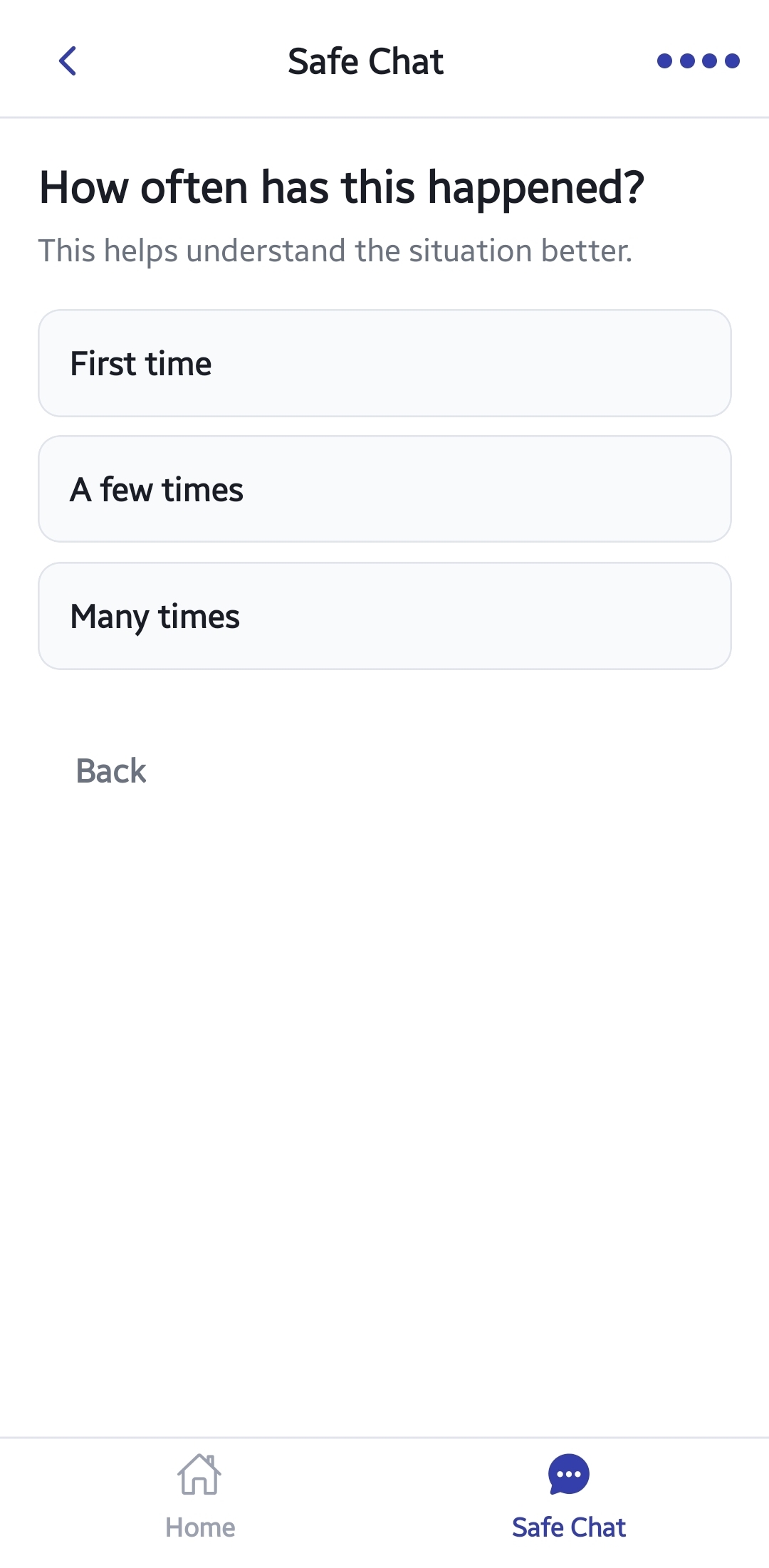
SENTINELX_SAFE_CHAT_STEP4_(FREQUENCY)
-
SENTINELX_SAFE_CHAT_STEP5_(UPLOAD EVIDENCE)
-
SENTINELX_NGO_WEB_DASHBOARD_WITH_HOME_ALERT
-
SENTINELX_NGO_WEB_REPORTS_QUEUE
-
SENTINELX_NGO_WEB_XAI_ANALYSIS





SentinelX
Inspiration
The inspiration behind SentinelX comes from a deeply personal place.
I am the eldest son in my family, with an elder sister and a younger brother, and I grew up with a strong sense of responsibility toward protecting the people I care about. I was raised believing that family means protection, responsibility, and showing up for those who depend on you. Over time, that instinct expanded beyond my immediate family to a broader concern for the safety and well-being of women, children, and other vulnerable individuals, both physically and digitally.
As I became more aware of issues such as online coercion, cyber-harassment, stalking, exploitation, and abuse, I noticed a recurring pattern: warning signs often existed long before meaningful intervention took place. Harm tended to escalate gradually while organizations struggled to process fragmented reports, identify patterns, and coordinate timely responses. In many cases, the problem was not the absence of care, but the absence of intelligent systems capable of surfacing risks early enough to enable action.
When the USAII Hackathon challenge was announced on June 14, 2026, that same protective instinct naturally influenced the direction of our thinking. My team and I initially explored several ideas, driven by a shared desire to build technology that could actively protect vulnerable individuals. Motivated by this vision, we began developing a concept centered on autonomous emergency escalation. However, as we studied the challenge more closely, we realized that our original approach did not fully align with the competition's emphasis on responsible AI-assisted organizational systems. Rather than creating a system that acted independently, the challenge called for solutions that would empower human organizations to make better, faster, and more informed decisions.
Instead of forcing that approach into the challenge, we decided to completely rethink the system architecture during the hackathon itself.
We shifted from building an autonomous safety application into designing a human-centered AI-assisted threat triage and contextual exploitation analysis platform for NGOs and intervention organizations.
That pivot became SentinelX.
Our goal became clear:
Build a responsible AI system that helps organizations identify contextual exploitation patterns earlier while ensuring humans remain fully accountable for intervention decisions.
What it does
SentinelX is an AI-assisted contextual threat triage and organizational intelligence platform designed for NGOs, intervention organizations, and protection-focused teams working with vulnerable individuals.
The platform helps organizations process structured reports related to:
stalking, cyber-harassment, coercion, grooming, exploitation, threatening behavior, and contextual abuse patterns.
Rather than functioning as an autonomous surveillance system, SentinelX was intentionally designed as a human-supervised organizational decision-support platform.
The mobile application acts strictly as a structured intake interface for contextual reporting.
It contains three primary features:
1. SOS
Allows users to quickly flag emergency situations to connected organizations.
This is triggered by a 3-second long-press on the large SOS button on the home screen. The long-press sends an immediate alert to both the user's emergency contacts and the NGO dashboard at the same time. No AI is involved in this flow at all it is a direct, instant alert mechanism, intentionally kept as simple and fast as possible for true emergencies.
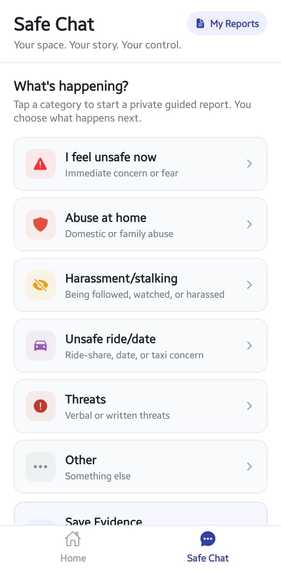
2. Safe Chat
A low-stress, guided 4-step intake wizard designed to help vulnerable users safely provide contextual incident reports without requiring large media uploads or complex interaction flows.
Rather than allowing unrestricted uploads of random screenshots or heavy media files, we intentionally designed a structured reporting workflow to:
*reduce cognitive stress for vulnerable users,
*improve contextual consistency,
*generate cleaner organizational triage signals,
*and improve explainability within downstream AI analysis.
The Safe Chat flow operates as follows:
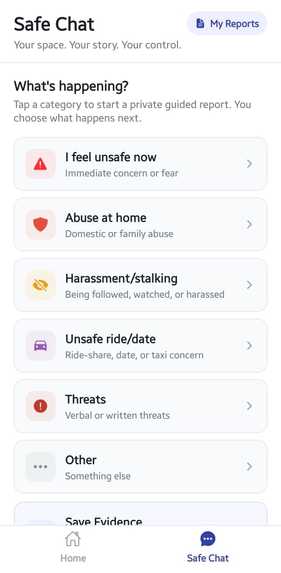
Step 1 Category Selection
Users select a scenario context such as:
*Stalking
*Cyber-harassment
*Physical tracking
*Threatening communication
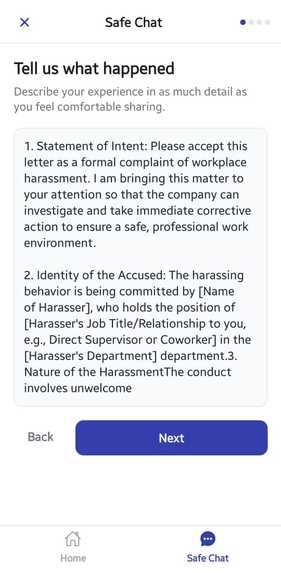
Step 2 Narrative Description
Users provide a raw text description of the situation in their own words.
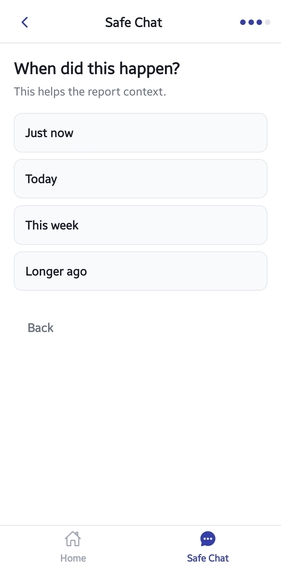
Step 3 Timing Selection
Users specify when the incidents occurred:
*Today
*This week
*Months ago
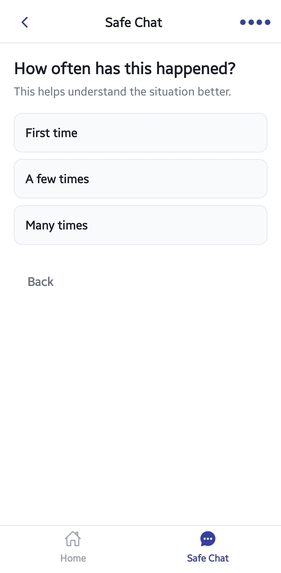
Step 4 Frequency Selection
Users indicate escalation patterns:
*First time
*A few times
*Many times
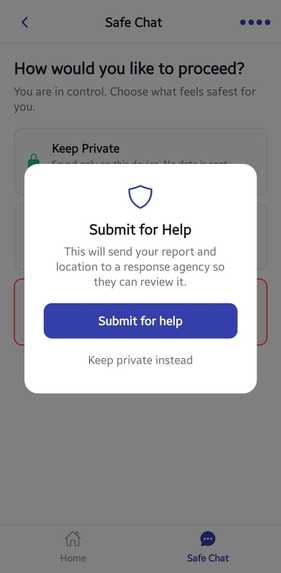
Step 5 Upload Evidence
After completing the four guided steps, users may optionally upload supporting evidence a video, audio recording, or image documenting the coercion, sextortion, grooming, or abuse described in their report.
Once submitted, the report and any attached evidence are securely stored inside MongoDB as a static un-triaged case with a status of:
$$ \text{Pending Analysis} $$
Importantly, no AI analysis occurs automatically.
Multimodal Evidence Intelligence
Beyond structured reporting, SentinelX also supports multimodal evidence-assisted investigation workflows for organizational analysts.
Within the Safe Chat flow, users can optionally attach contextual evidence such as:
screenshots,
chat exports,
images,
voice notes,
and short videos related to coercion, grooming, cyber-harassment, stalking, sextortion, or exploitation incidents.
When an authorized analyst intentionally initiates review, the uploaded evidence is processed through a multimodal AI synthesis pipeline powered by Gemini API workflows.
Rather than functioning as an autonomous enforcement engine, the system is designed to help analysts transform fragmented evidence into structured investigative intelligence.
The AI synthesis workflow evaluates uploaded evidence together with:
$$ \text{Narrative Context} + \text{Timing Metadata} + \text{Escalation Frequency} $$
to surface:
grooming progression indicators,
coercive behavioral patterns,
intimidation escalation signals,
contextual exploitation markers,
and probable communication environments or digital platforms associated with the reported abuse.
This allows investigators to move beyond isolated screenshots or disconnected reports and instead understand how exploitation behavior may evolve across time, context, and digital interaction spaces.
Importantly, SentinelX does not make autonomous conclusions about criminal intent or enforcement actions.
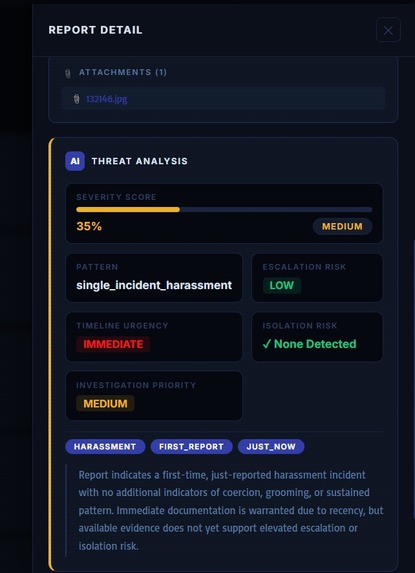
The platform generates explainable contextual synthesis outputs designed to support analyst understanding, prioritization, and responsible human-led intervention workflows.
Human agency remains the sole catalyst for algorithmic analysis.
An authorized NGO analyst must intentionally select a report and manually click the explicit [Analyze Report] button before any AI processing begins.
This intentional human gate was designed to:
*prevent automated over-reliance,
*reduce unnecessary AI processing,
*maintain analyst accountability,
*and preserve responsible human oversight in high-stakes intervention scenarios.
When the analyst triggers analysis:
The Flask backend retrieves the stored contextual report and any uploaded evidence,
Sends the uploaded evidence video, audio, or image to the Gemini API for contextual analysis,
Receives an explainable evidence analysis describing what the evidence shows,
Updates the case state to:
$$ \text{Triaged} $$
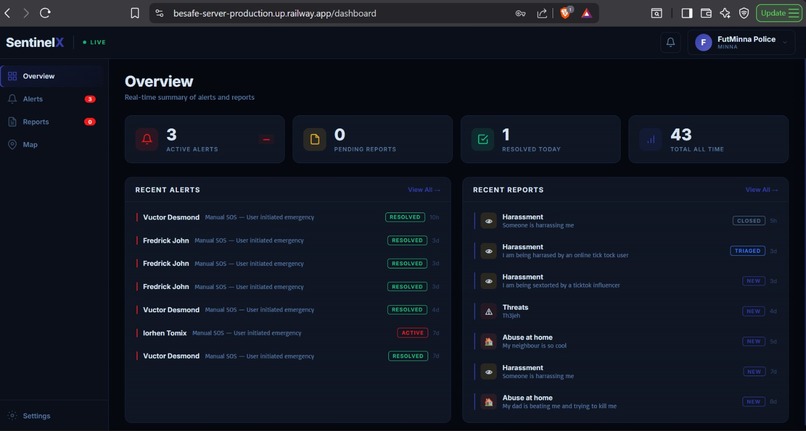
The NGO dashboard then dynamically displays:
*contextual risk summaries,
*escalation indicators,
*dynamic risk weighting,
*explainable synthesis reports,
*and transparent audit-oriented reasoning outputs.
3. Detect Threat
When intentionally toggled on by the user, this feature runs entirely on the user's device. The app captures audio, transcribes it to text locally, and immediately discards the audio no raw audio is ever stored or transmitted anywhere. The transcribed text alone is then passed through a Bi-LSTM model running on the device itself, which classifies it as threat or non-threat language.
If a threat is detected, only the classification result and the relevant transcript snippet are sent to the organizational dashboard for analyst review. The Bi-LSTM does not act on the user's behalf it never autonomously escalates, contacts authorities, or notifies anyone directly. It only flags.
Threat escalation, coercion, stalking, and abusive behavior are highly contextual problems that cannot be reliably identified using static keyword systems alone. Meaning often depends on:
*repetition,
*timing,
*narrative framing,
*escalation patterns,
*and situational context.
For this reason, SentinelX uses a trained contextual language model rather than rule-based detection systems.
The platform does not autonomously contact authorities or perform automated intervention actions. Human analysts remain fully responsible for all escalation and intervention decisions.
AI Architecture
SentinelX does not run a single AI pipeline. It runs three separate flows, and only two of them ever touch AI at all.
Inputs what goes in
SOS: a 3-second long-press on the home screen button. No data is analyzed by AI here the press itself is the entire input.
Detect Threat: short segments of audio captured on the device, transcribed to text locally, with the audio discarded immediately afterward. Only the transcribed text ever becomes AI input raw audio never leaves the phone.
Safe Chat + Upload Evidence: the four guided answers (category, narrative, timing, frequency) plus any uploaded video, audio, or image evidence. The evidence itself not the narrative text — is what Gemini later analyzes.
Outputs — what comes out
SOS produces an instant alert sent to the user's emergency contacts and the NGO dashboard. No AI output is involved at any point in this flow.
Detect Threat produces a threat / non-threat classification from the on-device Bi-LSTM. Nothing is sent anywhere unless a threat is actually detected, in which case the classification and the relevant transcript snippet reach the NGO dashboard.
Safe Chat + Upload Evidence produces a Gemini-generated, plain-language analysis of the uploaded evidence, shown on the dashboard once the case status moves from Pending Analysis to Triaged.
None of these outputs are final decisions. They are signals an NGO analyst reviews and acts on.
Human-in-the-Loop Decision
There is one decision SentinelX never makes on its own: whether a case should be escalated.
Across all three flows, the system can flag, classify, or describe but it never decides that a situation is dangerous enough to act on. The on-device Bi-LSTM can say a transcript sounds like a threat; it cannot decide what should happen next. Gemini can describe what an uploaded video, audio file, or image shows; it cannot decide whether that warrants intervention. That decision belongs to a human analyst, every time, because exploitation and abuse cases carry consequences that go beyond what a model's confidence score can responsibly capture a false escalation can damage trust and cause further harm, and a missed one can leave someone unsupported in a dangerous situation.
Responsible AI Guardrail
The risk we worried about most was automation bias analysts starting to treat an AI flag or evidence analysis as a verdict instead of a starting point. We reduced that by making sure neither AI component ever outputs a final classification on its own: the Bi-LSTM only flags, Gemini only describes, and both results are shown as explainable text an analyst has to actually read, not a score they can rubber-stamp.
The second risk was specific to Detect Threat: any feature that captures audio is, by definition, a privacy risk, and a poorly designed version of it would be indistinguishable from the surveillance tools this challenge explicitly warns against. We addressed this with strict data minimization audio is transcribed to text on the device and discarded immediately, never stored, never uploaded, and the feature only ever runs when the user has deliberately toggled it on.
Decision Impact
What actually changes for an NGO analyst because SentinelX exists is simple: instead of reading every SOS alert, transcript flag, and uploaded evidence file cold and in isolation, they open one dashboard where each signal already carries its own explainable read attached to it. They still make every real decision — whether to escalate, prioritize, or dismiss — but they make it starting from structured, attributed context instead of raw, disconnected reports arriving from three different places.
How we built it
As the team lead, I registered for the hackathon with the intention of building a strong team capable of tackling meaningful challenges. I reached out to colleagues from different academic levels who shared a passion for innovation and problem-solving, and together we eagerly awaited the official start of the competition.
When the USAII Challenge officially commenced on June 14, 2026, our team immediately began exploring ideas and evaluating how they aligned with the challenge objectives. After several brainstorming sessions and discussions, we selected one concept that closely matched the focus of Track A. We then collaboratively designed the solution architecture, identified the necessary AI capabilities, and refined our approach, ensuring that all development and planning activities were carried out within the competition timeframe.
*responsible AI,
*organizational intelligence,
*explainability,
*and human-in-the-loop intervention systems.
During the hackathon itself:
*our mobile developer designed the application experience,
*our UI/UX designer created the organizational dashboard and analyst workflows,
*and our AI engineer developed the contextual NLP threat analysis pipeline and responsible AI interaction flow.
One of our most important architectural decisions was ensuring that AI analysis could never occur autonomously.
This describes the Safe Chat and Upload Evidence flow specifically — SOS and Detect Threat operate differently, as described above. The system workflow for Safe Chat and Upload Evidence operates as follows:
$$ \fbox{\text{User Report}} \rightarrow \fbox{\text{Secure Storage}} \rightarrow \fbox{\text{Human Review Trigger}} \rightarrow \fbox{\text{AI Analysis}} \rightarrow \fbox{\text{Explainable Risk Output}} \rightarrow \fbox{\text{Human Decision}} $$
Incoming reports are first stored securely in MongoDB without AI interpretation.
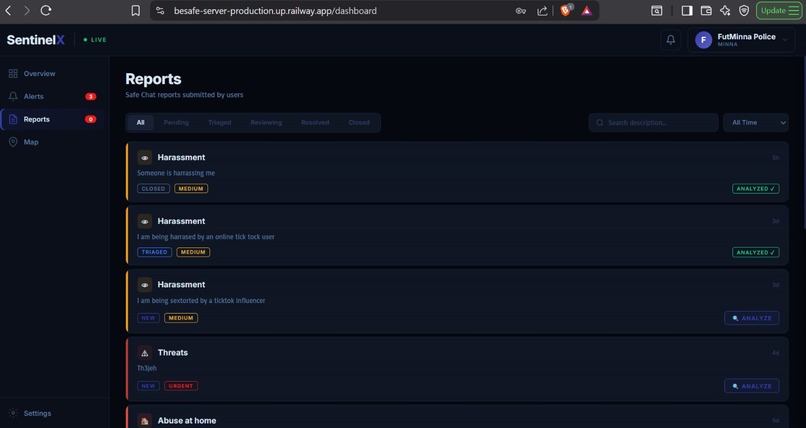
The dashboard initially displays reports in a neutral, un-triaged state with a visible [Analyze Report] button beside each case.
Only after an authorized analyst intentionally initiates processing does the Flask backend:
Retrieve the stored report and any uploaded evidence,
Send the uploaded evidence to the Gemini API for contextual analysis,
Receive an explainable evidence analysis output,
Update the report state and dashboard display dynamically using WebSocket-based UI updates.
This explicit human gate was intentionally designed to reduce:
*automation bias,
*over-surveillance risks,
*and uncontrolled AI escalation behavior.
We also intentionally designed the system around Explainable AI (XAI) principles.
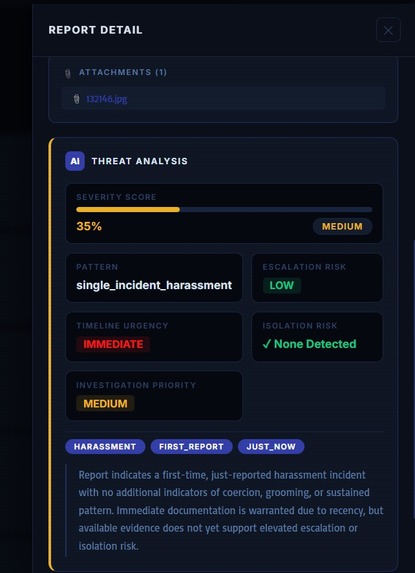
Rather than generating opaque classifications, SentinelX produces transparent synthesis summaries intended to support analyst understanding and accountability during case review.
For our core AI layer, we built two independent components that operate in entirely different places rather than a single backend pipeline. A Bidirectional Long Short-Term Memory (Bi-LSTM) model, trained on over 100,000 labeled statements and reaching 96% test accuracy, was converted into a lightweight on-device format and bundled directly into the mobile app. It powers the Detect Threat feature, classifying locally-transcribed text as threat or non-threat in real time, entirely on the user's device — the raw audio itself is never stored or transmitted.
Separately, our Flask backend deployed on Railway handles the Safe Chat and Upload Evidence flow. When an analyst clicks [Analyze Report], the backend sends the evidence the user uploaded video, audio, or image to the Gemini API, which analyzes the evidence and returns a plain-language contextual justification on the NGO dashboard. The Bi-LSTM and Gemini never interact with each other; they power two completely separate features.
However, we quickly learned that building responsible AI systems requires far more than achieving high accuracy scores.
A technically accurate model without:
*human oversight,
*explainability,
*intentional activation boundaries,
*and transparent workflows
can still create harmful real-world outcomes.
Because of this, our primary focus shifted toward designing a responsible organizational intelligence workflow rather than simply maximizing model performance.
Challenges we ran into
One of our biggest challenges was realizing that our initial idea conflicted with several responsible AI expectations introduced in the USAII Track A challenge brief.
Initially, our concept focused heavily on autonomous emergency escalation. After carefully reviewing the challenge requirements, we recognized that systems operating in high-stakes human safety environments require clear human oversight and accountability boundaries.
This forced us to redesign all portions of the system architecture during the hackathon itself.
Another major challenge involved balancing:
*safety,
*privacy,
*explainability,
*organizational usability,
*and responsible AI governance.
We intentionally avoided building a system that continuously monitored users or autonomously analyzed private conversations without explicit human involvement. Instead:
*reports are intentionally submitted,
*analysis is intentionally triggered,
*and intervention decisions remain fully human-controlled.
We also faced the challenge of reducing automation bias.
One concern we identified early was the possibility that analysts could over-rely on AI-generated outputs during sensitive intervention cases. To reduce this risk, we intentionally designed the dashboard so that AI results appear as explainable synthesis panels rather than opaque final decisions or absolute classifications.
Another technical challenge involved contextual ambiguity.
Threatening language is often highly situational. Phrases may appear dangerous in isolation while actually being harmless in context, or vice versa. To improve contextual interpretation, we incorporated:
*timing metadata,
*escalation frequency indicators,
*contextual narrative framing,
*and structured intake constraints
into the AI processing workflow.
Beyond the technical and architectural challenges, we also faced a personal one. Partway through the build window, the teammate responsible for our AI and model development came down with a fever and was unable to work at full capacity for a stretch of the hackathon.
The rest of the team stepped in to keep the build moving forward, giving him room to recover, while compressing an already tight model development timeline even further.
Another challenge we encountered was the limitation of relying primarily on free-tier AI development tools such as ChatGPT and Claude. While these tools greatly accelerated ideation, coding, and debugging, their usage limits and occasional unavailability often interrupted our workflow. There were instances where we had to pause development and wait for access limits to reset, and in some cases, we had to restart conversations and reconstruct context from scratch, resulting in lost time and reduced productivity during critical stages of the hackathon. Managing these constraints while maintaining momentum added an unexpected layer of complexity to the project.
We also encountered technical challenges involving:
*rapid backend restructuring,
*WebSocket synchronization,
*dashboard state management,
*explainable AI rendering,
*and coordinating multiple architecture changes within hackathon time constraints.
As students balancing technical execution and academic responsibilities, redesigning an entire AI workflow architecture under tight timelines became one of the most demanding parts of the experience.
Accomplishments that we're proud of
One of our proudest accomplishments was successfully redesigning the system architecture during the hackathon itself rather than forcing our original concept into the challenge requirements.
We transformed the platform from an autonomous emergency-response concept into a responsible AI-assisted organizational intelligence workflow centered around human oversight and accountability.
We are especially proud that SentinelX:
enforces explicit human oversight,
prevents autonomous intervention escalation,
uses intentional AI activation workflows,
and preserves human accountability in high-stakes decisions.
We are also proud of designing:
the 4-Step Safe Chat intake wizard,
the NGO analyst dashboard,
the explicit [Analyze Report] human-gated workflow,
and the Explainable AI review interface.
We implemented transparent Explainable AI synthesis panels rather than opaque risk scoring outputs to support analyst understanding and accountability.
Another accomplishment was successfully transforming fragmented contextual narratives into structured organizational intelligence capable of helping intervention teams prioritize cases more effectively.
Most importantly, we are proud that the system was designed around protecting vulnerable individuals while still respecting privacy, transparency, and responsible AI principles.
What we learned
This project taught us that building AI systems for human safety requires far more than technical accuracy.
We learned that:
transparent analyst interaction,
explainable reasoning,
accountable escalation workflows,
and clear operational boundaries
We also learned that organizational workflows are just as important as AI capabilities themselves.
A powerful AI model without:
transparent analyst interaction,
explainable reasoning,
accountable escalation workflows,
and clear operational boundaries
can create confusion rather than meaningful intervention support.
One of our most important realizations was that AI should support human decision-making not replace it. The strongest systems are not fully autonomous systems. The strongest systems combine:
human judgment,
contextual intelligence,
transparency,
responsible governance,
and accountable intervention workflows.
We also learned that responsible AI is not simply about model accuracy. It is about designing systems where:
humans remain accountable,
algorithmic reasoning remains understandable,
and vulnerable individuals remain protected from unintended harm.
As a team, we learned how quickly architectural priorities can shift once ethical considerations become central to system design.
What's next for SentinelX
Our next goal is to continue expanding SentinelX into a more robust AI-assisted organizational intelligence and intervention support platform. We plan to:
improve contextual threat synthesis accuracy,
strengthen explainable AI reporting,
improve analyst collaboration workflows,
enhance multilingual contextual analysis,
and build stronger privacy-preserving case management systems.
We also plan to explore:
AI-assisted case prioritization,
cross-case escalation trend analysis,
collaborative intervention workflows for NGO teams,
and broader contextual intelligence capabilities for protection-focused organizations.
Future versions of SentinelX may also explore identifying repeated behavioral escalation patterns across organizational case histories while preserving privacy boundaries and maintaining strict human oversight controls.
Long-term, we envision SentinelX becoming a responsible AI-assisted safety intelligence infrastructure that helps organizations identify risks earlier, prioritize vulnerable cases more effectively, and support human-centered intervention workflows at scale.
Built With
- android
- bi-lstm
- chatgpt
- claude
- flask
- github-copilot
- google-gemini
- javascript
- kaggle
- keras
- lovable(ui-ideation)
- mongodb
- on-device-ml
- python
- railway
- react-native
- tensorflow
- websocket


Log in or sign up for Devpost to join the conversation.