The Problem with Software Testing Today
Writing test cases is slow, expensive, and requires deep knowledge of the codebase. Most startups and hackathon projects ship with zero automated tests. Even when tests exist, they only cover happy paths that developers already know about — the edge cases that break real users are never tested.
Three specific pain points:
Time cost — Manual QA is a bottleneck. Testers must read code, understand user flows, and write scripts by hand before a single automated test can run.
Coverage drift — Test suites go stale. As UIs change, tests break and developers stop maintaining them, leaving large untested surface areas.
Blind spots — Developers write tests for flows they already know. An autonomous agent that explores the app fresh discovers failure modes a human writer would never think to test.
What SentinelQA Does
SentinelQA gives any developer a QA engineer on demand. Paste a URL — no codebase access, no SDK, no test scripts required. The agent handles everything:
- Crawls the app and maps all interactive elements
- Generates 8–15 diverse test cases autonomously using Gemini
- Executes every test in a real headless browser via Playwright
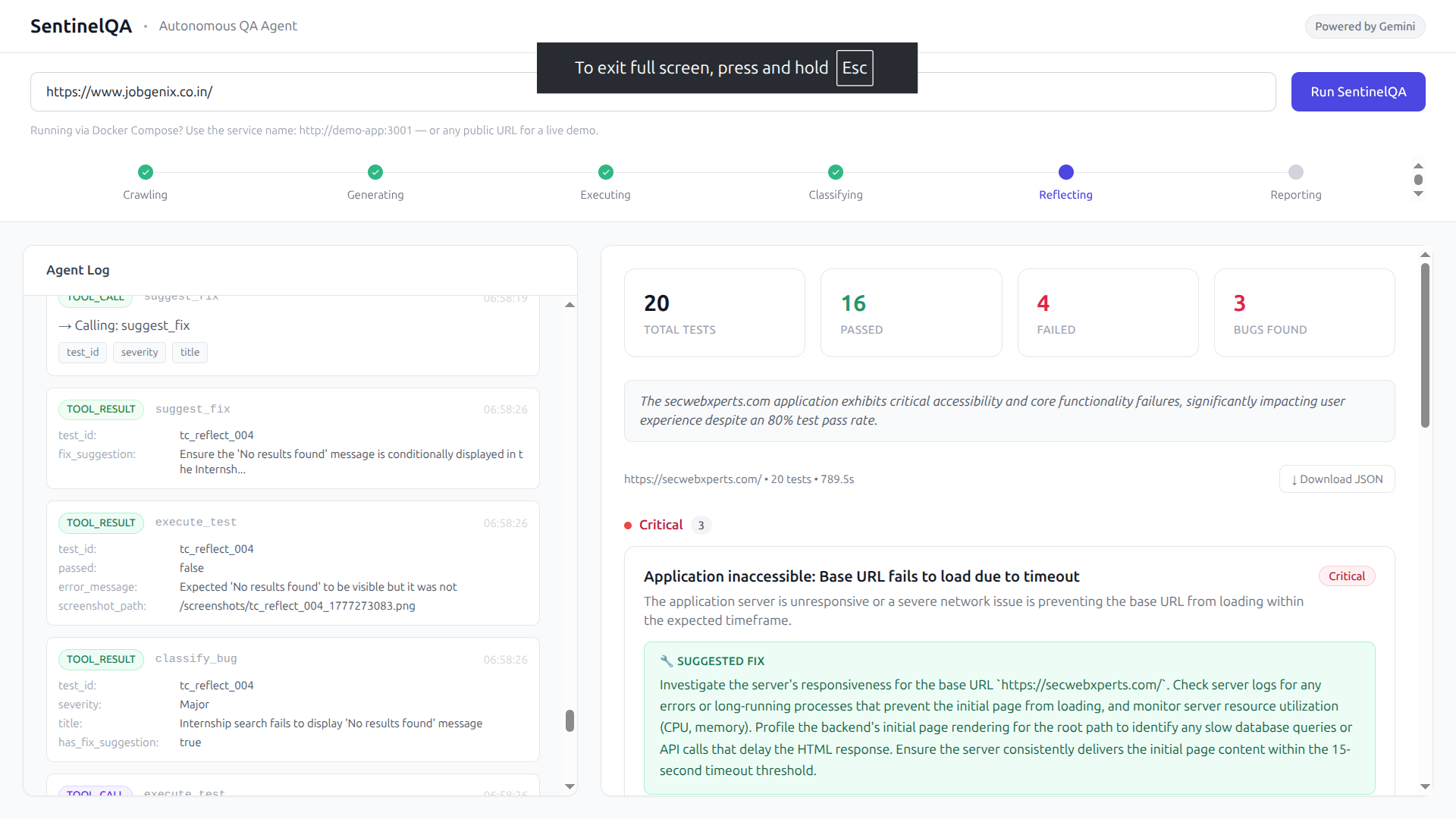
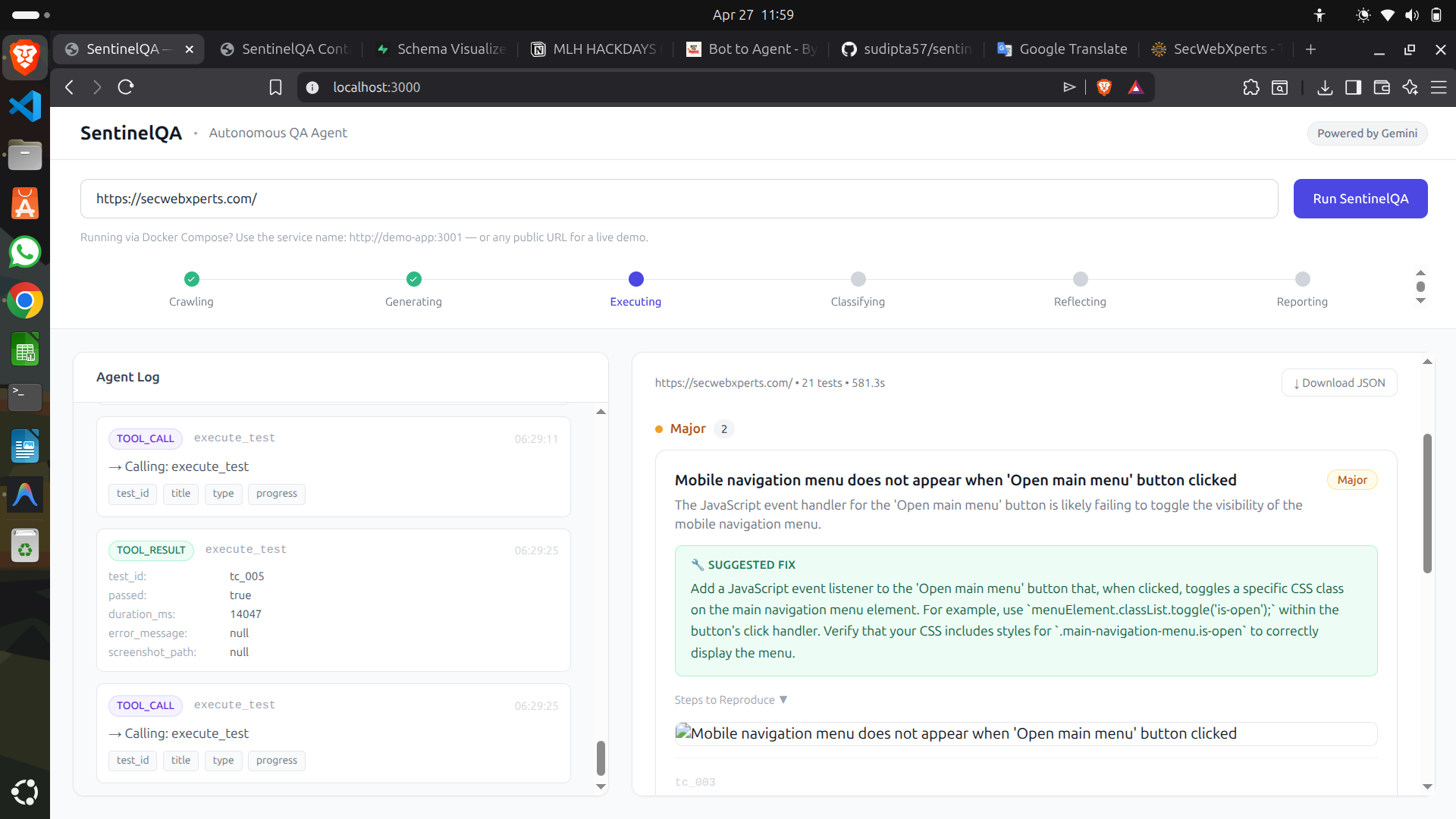
- Classifies each failure as Critical, Major, or Minor
- Reflects on its own coverage and runs follow-up tests
- Suggests fixes for every Critical and Major bug found
- Delivers a structured, human-readable bug report
The entire loop runs in under 3 minutes. No human writes a single test script.
Building a Truly Autonomous Agent
1. Making Playwright understand natural language test steps
Gemini generates test steps in plain English like "Click the button with label 'Add Contact'". Translating these into actual Playwright actions required building a custom NLP-to-action interpreter with 12+ pattern matchers and multi-strategy fallback chains. A single failed selector could cascade into false positives across the entire test run.
2. False positives on real websites
When testing external URLs, Playwright flagged mobile-only hamburger menus and slow-loading elements as bugs. We had to teach the agent the difference between "Playwright couldn't click it" and "the feature is genuinely broken" — adding viewport-aware visibility checks and a false positive detection layer in the Gemini classification prompt.
3. Gemini JSON reliability
Gemini 2.0 Flash occasionally wraps JSON responses in markdown fences or returns slightly malformed structures despite explicit instructions. We built a robust multi-strategy JSON parser that handles fences, trailing text, and partial responses — with exponential backoff retry on rate limit errors.
4. Docker networking and Supabase connectivity
Running Playwright's headless Chromium inside Docker requires
specific --no-sandbox flags and system dependencies. Getting
outbound network access from Docker containers to reach external
services (Supabase, Gemini API) required diagnosing a DNS resolution
failure inside the container and fixing it at the Docker daemon level.
5. The self-reflection loop without infinite recursion
The most agentic feature — reflect_and_expand() — required careful
design. Gemini needed enough context about what was already tested to
make genuinely novel suggestions, while a hard iteration cap of 2
prevented runaway execution. Balancing "smart enough to find new
gaps" with "constrained enough to terminate" took several iterations.
6. SSE streaming with real-time UI updates
Implementing Server-Sent Events from FastAPI to React using fetch
with ReadableStream (instead of EventSource which doesn't support
POST) required custom stream parsing logic and a 60-second timeout
watchdog to handle dropped connections gracefully during the demo.

Log in or sign up for Devpost to join the conversation.