-
-
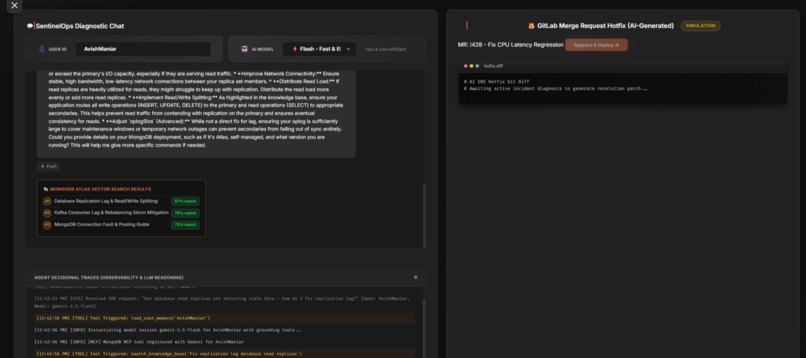
Every answer is provably sourced — matched runbooks with live cosine-similarity scores.
-
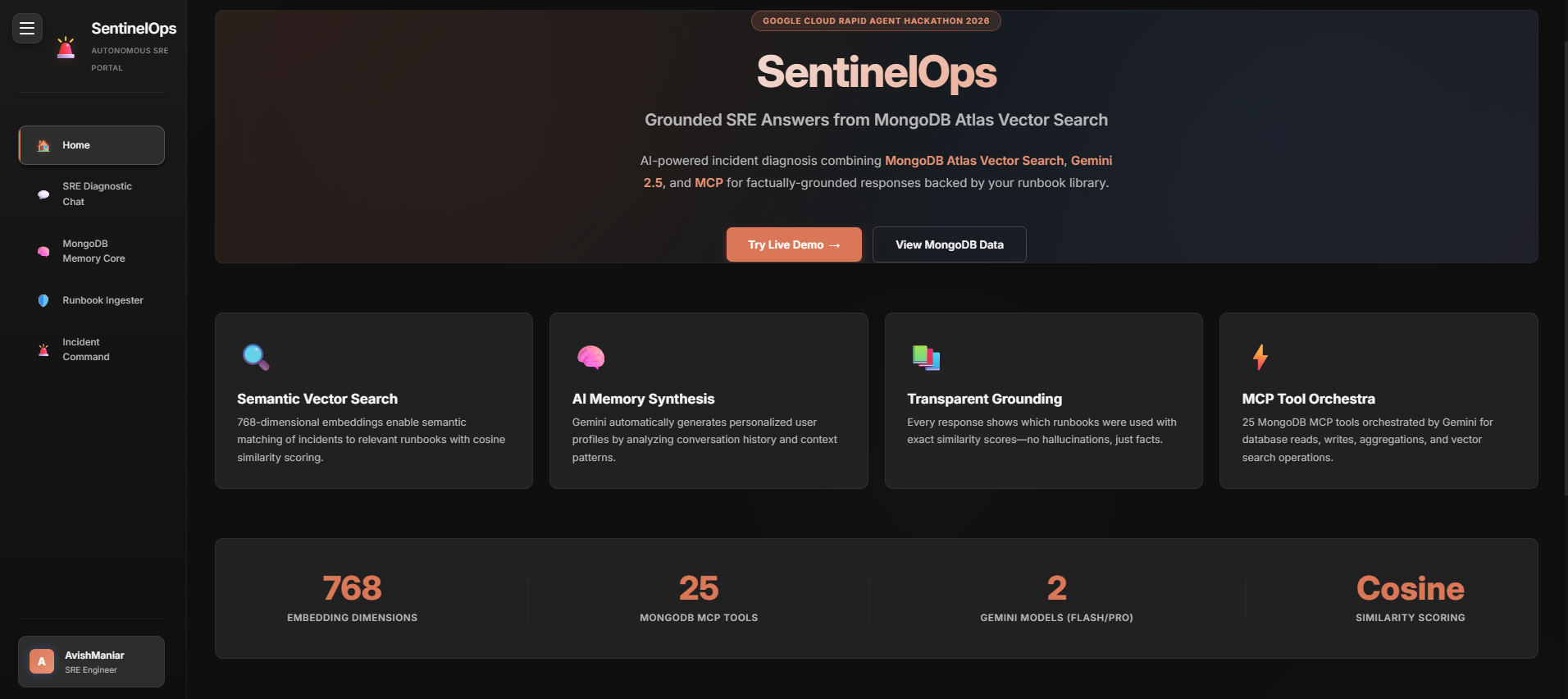
MongoDB Atlas Vector Search + Gemini 2.5 for grounded SRE incident diagnosis.
-
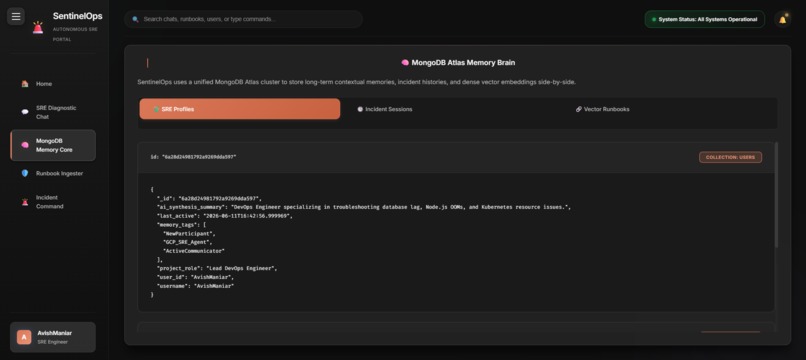
Live MongoDB Atlas data with Gemini-synthesized user memory profiles.
-
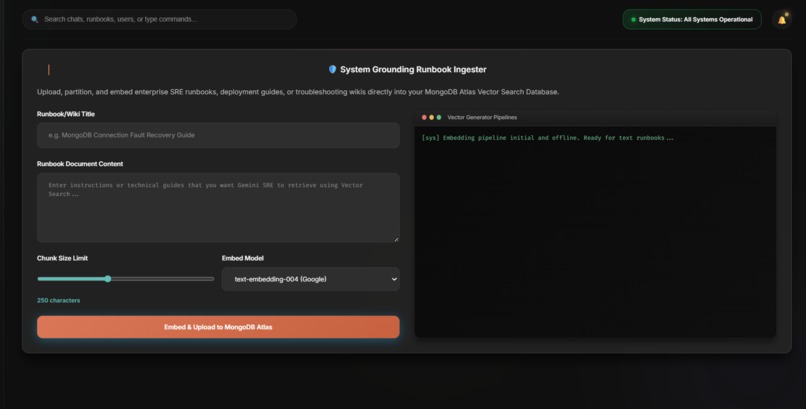
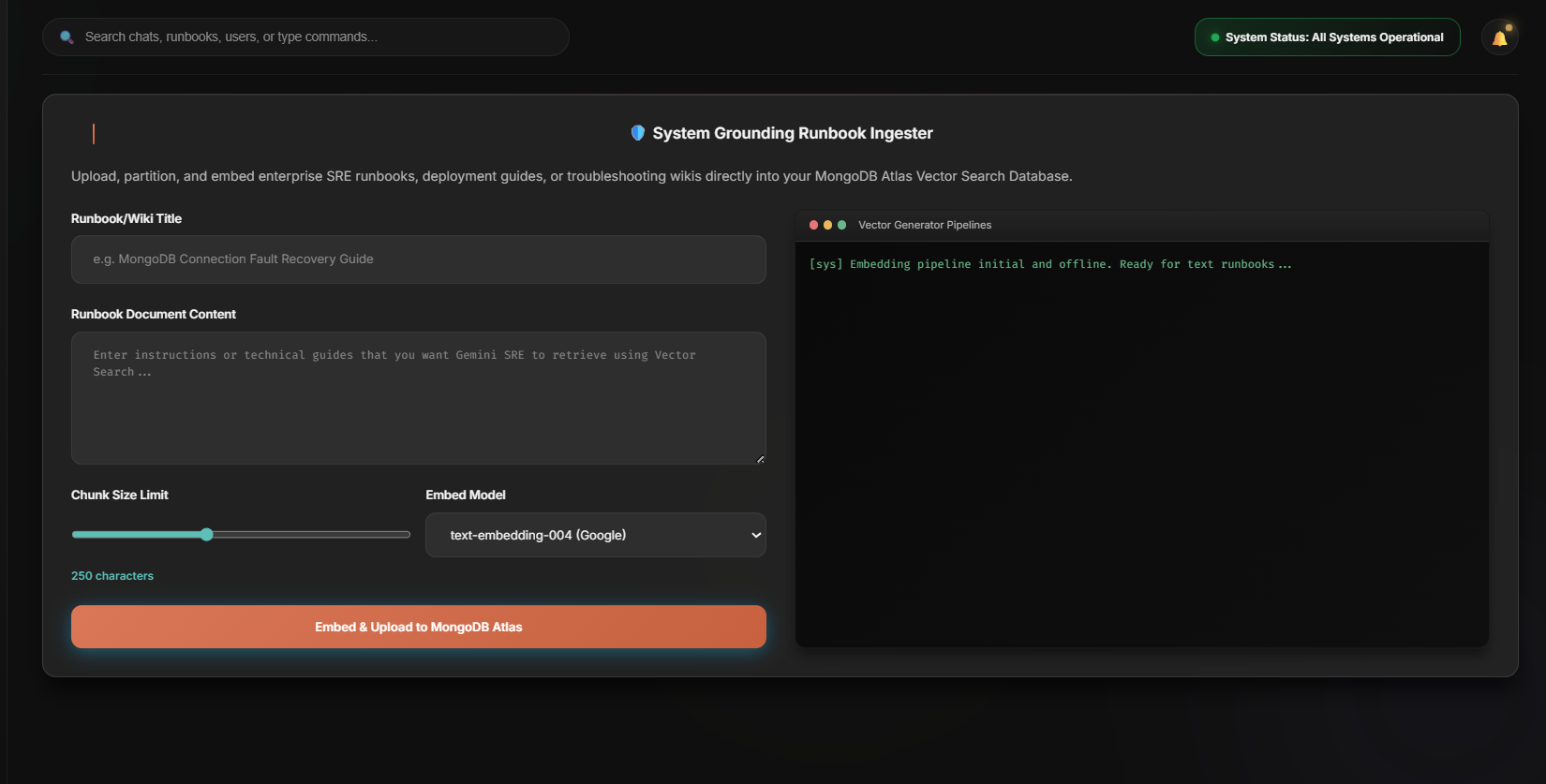
Ingest any runbook — embedded with text-embedding-004 into 768-dim vectors and written straight into MongoDB Atlas, instantly searchable.
Inspiration
Every engineer who has been on call knows the feeling: it's 3 AM, production is down, and you're frantically grepping through wikis, Slack threads, and half-outdated runbooks trying to remember how you fixed this last time. The knowledge exists somewhere — it's just scattered and slow to reach when every minute of downtime costs money.
At the same time, AI chatbots are everywhere now — but you can't trust a tool that confidently makes things up when production is on fire. We wanted an assistant that's both fast and provably trustworthy: it answers instantly, and it shows you exactly which document the answer came from. That combination — speed plus grounded transparency — became SentinelOps.
What it does
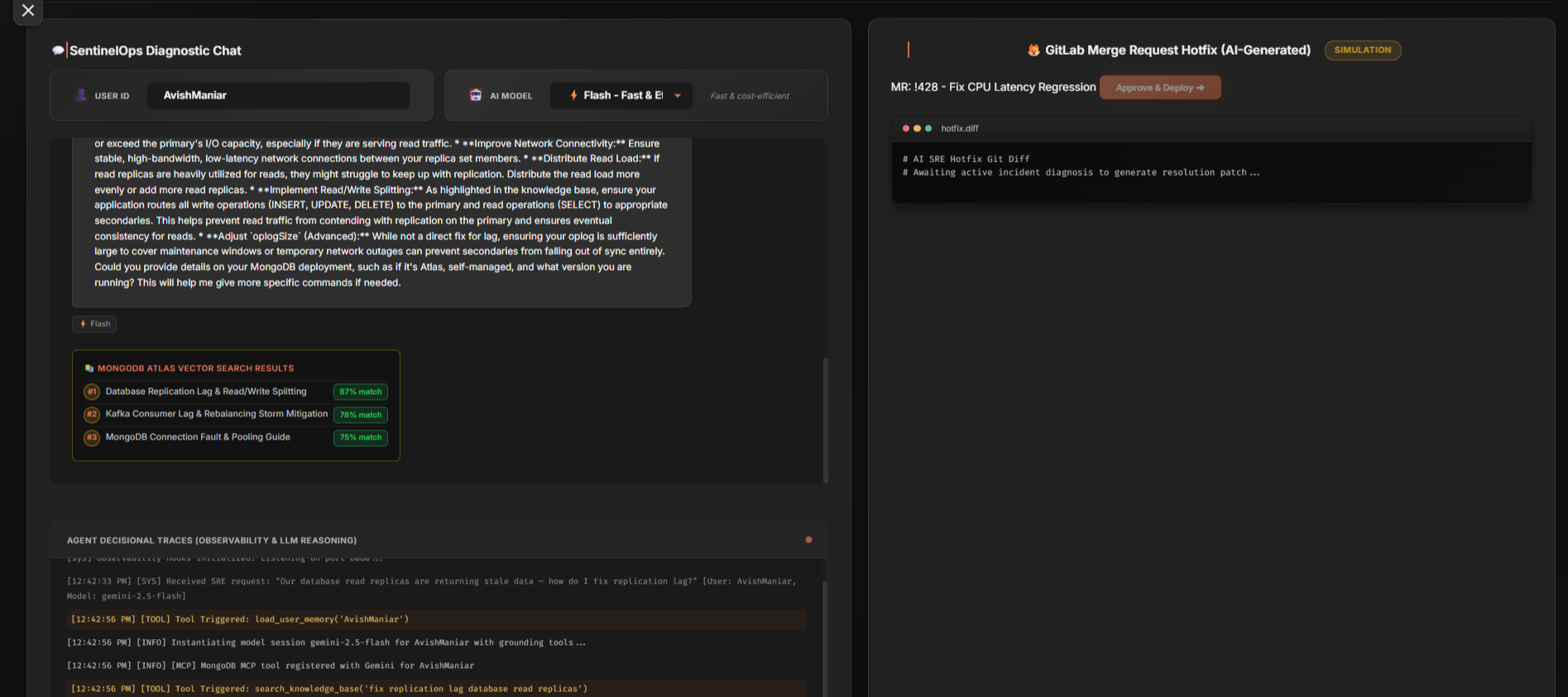
SentinelOps is an autonomous SRE (Site Reliability Engineering) agent that diagnoses production incidents using your own runbook library.
- Ask in plain English — "How do I fix Redis cache key eviction during high traffic?" — and the agent retrieves the most relevant runbooks and answers from them.
- Grounded, not hallucinated — every response shows a MongoDB Atlas Vector Search Results panel with the matched runbooks and their cosine-similarity scores, so you can verify the source.
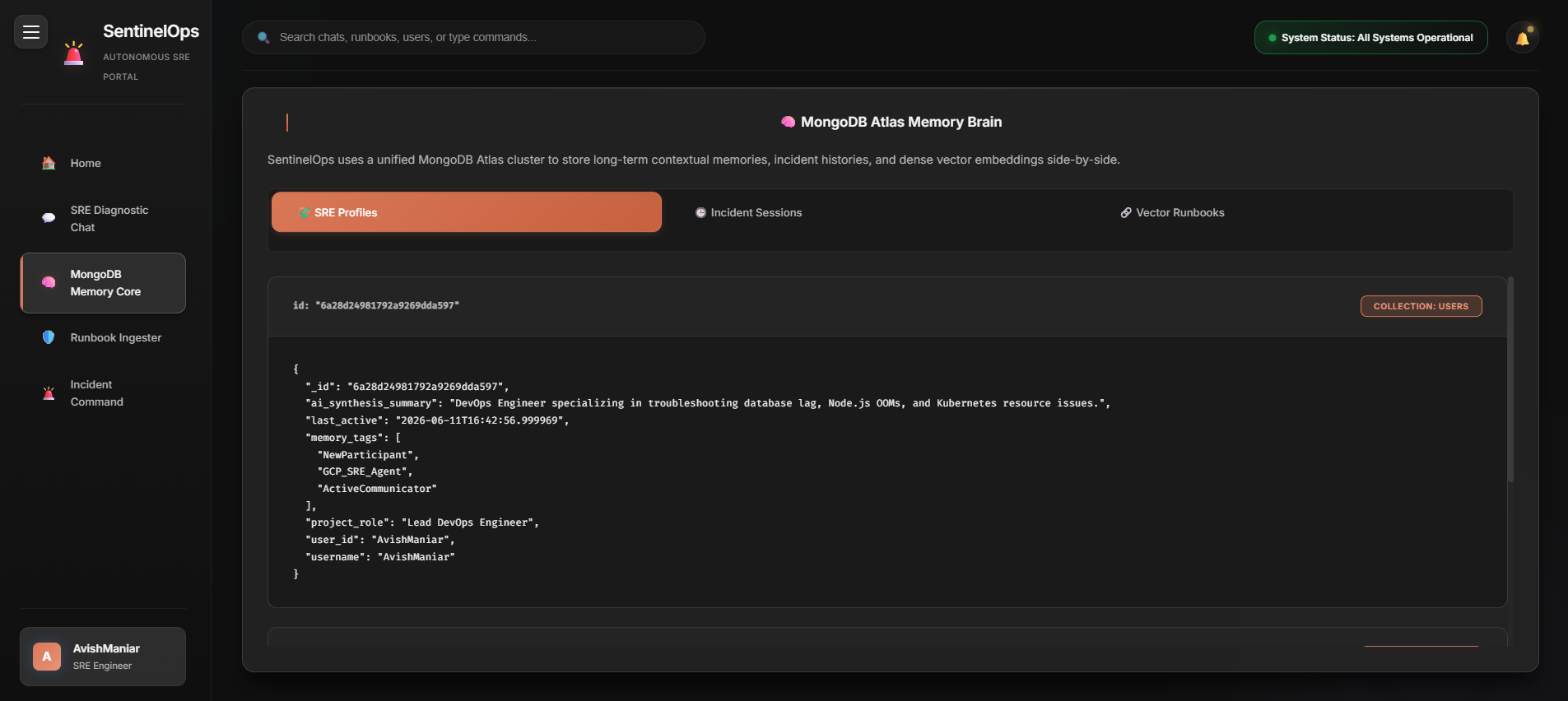
- Persistent memory — Gemini synthesizes a per-user memory profile from conversation history, stored in MongoDB Atlas.
- Ingestion pipeline — paste any runbook and it's embedded into a 768-dimensional vector and written straight into Atlas, instantly searchable.
- Dual models — switch between Gemini 2.5 Flash (fast) and Pro (deeper reasoning), both backed by the same Atlas grounding.
- Observability hooks — an authenticated webhook endpoint lets monitoring tools trigger autonomous diagnosis.
How we built it
The foundation is MongoDB Atlas, which powers three live collections — users, sessions, and knowledge_vectors.
The retrieval flow:
- A user's question is embedded with Google's
text-embedding-004model into a 768-dimensional vector. - MongoDB Atlas Vector Search runs a
$vectorSearchaggregation, ranking runbooks by cosine similarity:
$$\text{similarity}(\mathbf{q}, \mathbf{d}) = \frac{\mathbf{q} \cdot \mathbf{d}}{\lVert \mathbf{q} \rVert \, \lVert \mathbf{d} \rVert}$$
- The top matches are injected into Gemini 2.5's context as grounding, and the matched titles + scores are surfaced in the UI.
Stack:
- Backend: Python + Flask REST API, with four Vertex AI tools (
search_knowledge_base,load_user_memory,save_chat_history,execute_mongodb_mcp_tool). - AI: Google Gemini 2.5 Flash & Pro via Vertex AI;
text-embedding-004for embeddings. - Database: MongoDB Atlas (M0 free tier) with a cosine-similarity vector index on 768-dim embeddings.
- MCP: The official MongoDB MCP Server (25 tools) wired to Gemini over JSON-RPC 2.0, so the agent can run live database operations.
- Infra: Containerized with Docker (Python + Node.js), deployed serverless on Google Cloud Run, with Cloud Logging and GCS runbook backups.
- Frontend: A vanilla-JS glassmorphic dashboard on GitHub Pages — incident command, diagnostic chat, a live MongoDB Memory Core explorer, and a runbook ingester.
Challenges we ran into
- Running the MCP server inside Cloud Run. The MongoDB MCP server is a Node.js subprocess, while our app is Python. Getting both runtimes into one container — and handling the cold-start timeout before the MCP handshake completed — took a multi-runtime Dockerfile and a threaded, timeout-guarded initialization with graceful fallback.
- A silent AI-synthesis bug. Our memory-summary feature was calling an undefined
GenerativeModel, which threw an exception that got swallowed by a try/except — so it silently fell back to a templated string instead of real AI output. We caught it by inspecting the live database and switched to the unifiedgenaiclient. - Securing a public webhook. Our alert endpoint triggered a Gemini call on every request — an open door for quota abuse. We added
X-Webhook-Secretauthentication to lock it down. - "Committed" ≠ "deployed." More than once we fixed code, pushed to Git, and the live behavior didn't change — because Cloud Run was still serving the old revision. We learned to verify against the live endpoints, not the repo.
- Vector index naming. Atlas Vector Search silently returns nothing if the index name in code doesn't match the one created in the Atlas UI — a subtle gotcha we now document explicitly.
Accomplishments that we're proud of
- Grounding you can see. The similarity-score panel turns "trust me" into "here's the proof" — exactly what makes an AI agent usable for real incident response.
- A genuinely live, end-to-end system — deployed on Cloud Run, with real Atlas vector search, real Gemini answers, and a real ingestion write-path, all working together.
- Honest by design. Simulated/demo panels are clearly badged, and our stats are all verifiable facts — no inflated metrics.
- Real partner integration — not just storing data in MongoDB, but using Atlas Vector Search and the official MongoDB MCP Server as core, load-bearing parts of the agent.
What we learned
- RAG is only as trustworthy as its transparency. Surfacing the retrieved sources and scores changed the product from "a chatbot" into "a tool an engineer would actually rely on."
- Vector search quality lives in the details — embedding model choice, index configuration,
numCandidates, and similarity metric all materially affect results. - Tool-use orchestration is powerful but fragile — subprocess lifecycles, timeouts, and silent fallbacks need deliberate handling, especially serverless.
- Demo integrity matters. Closing the gap between what we claimed and what the code did made the whole project stronger.
What's next for SentinelOps: Autonomous SRE & DevOps Incident Command Portal
- Real integrations to replace the simulated panels — live Dynatrace/Datadog alert ingestion and genuine GitLab/GitHub merge-request creation for AI-generated hotfixes.
- Multi-tenant runbook libraries so teams can ground the agent on their own private documentation.
- Auto-ingestion of runbooks from existing wikis, Confluence, and Git repos.
- Feedback loop — let engineers rate answers so retrieval and synthesis improve over time.
- Proactive incident response — chaining Atlas-grounded diagnosis with automated remediation actions, with a human approval gate.

Log in or sign up for Devpost to join the conversation.