-
-

Project Banner
-
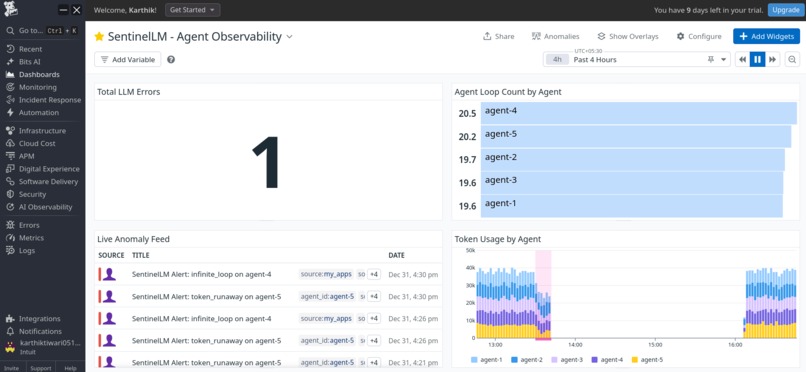
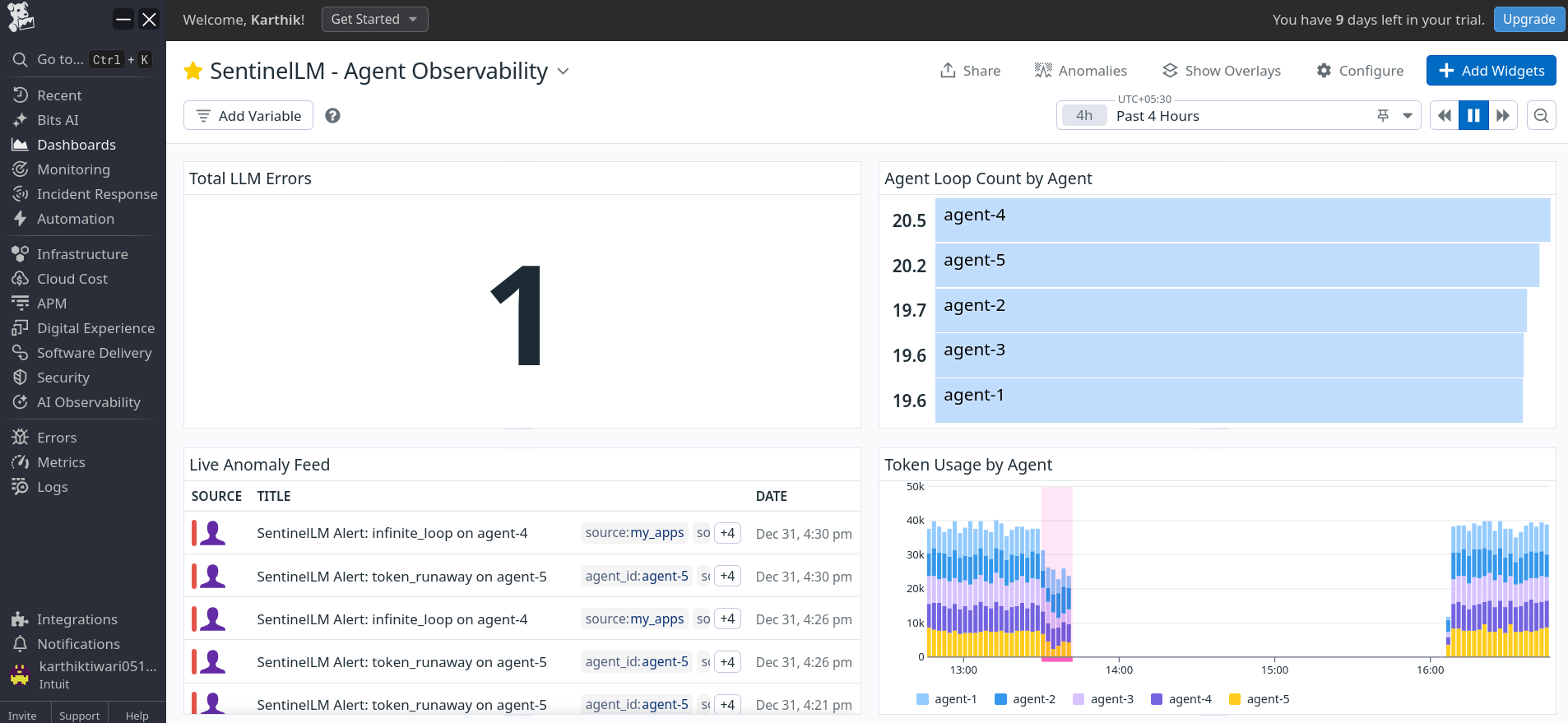
Datadog Dashboard

Inspiration
As an engineer in the Platform team at Intuit, I've observed several teams deploying Agentic Services in production across the Industry. Traditional observability focuses on infrastructure and request latency, but it doesn’t explain agent behavior and token usage. SentinelLM came from the need to treat LLM systems like real production workloads and make their failures visible and actionable.
What it does
SentinelLM is an observability and incident response system for LLM agents. It tracks agent execution, token usage, and latency, detects issues like agent loops and token runaway in real time, and turns those signals into actionable incidents. It provides context on what likely went wrong and surfaces that information clearly to engineers.
How we built it
All agent telemetry is streamed through Kafka using Confluent, which allows us to process signals in real time and detect anomalies like repeated agent nodes or abnormal token growth. These signals are sent to Datadog as custom metrics, where we define dashboards, monitors, and incidents. When an incident is created, Gemini generates a short explanation of the issue, and ElevenLabs converts that summary into a brief voice notification for faster on call awareness.
Challenges we ran into
One challenge was simulating Incidents using Real Agents since it would drive up the cost and triggering edge cases might not be deterministic. A decision was made to simulate the same using artificial Agent Logs to demo the system instead so the focus remained on enhancing the functionality.
Accomplishments that we're proud of
We’re proud that SentinelLM focuses on real, practical failure modes that teams already face in production, like silent agent loops and unexpected cost spikes. The system stays simple, uses existing tools and standards, and connects detection directly to action.
What we learned
LLM observability needs to focus on behavior, not just performance. Metrics like token velocity, agent depth, and execution patterns are critical for understanding failures. Also, Integrating Confluent, Datadog and ElevenLabs APIs helped understand how to build a highly scalable system with existing frameworks instead of building from scratch and gave me insights into how feature rich the platforms are.
What's next for SentinelLM
Sentinel LM should support more complex multi agent workflows and add adaptive baselines so anomaly detection improves over time. We also want to explore automated safeguards, such as limiting or stopping agents when high-risk behavior is detected. Longer term, SentinelLM could serve as a control plane for operating LLM systems safely in production.


Log in or sign up for Devpost to join the conversation.