Inspiration
Large Language Models are rapidly moving from experiments to mission-critical production systems. However, while models have become more powerful, the operational tooling around them has not kept pace. In real-world deployments, LLMs often behave like black boxes—latency spikes silently, costs grow unpredictably, hallucinations increase gradually, and safety failures surface only after user impact.
Coming from an SRE and cloud infrastructure background, we noticed a gap: traditional observability platforms are excellent at monitoring infrastructure, but they lack AI-specific visibility. SentinelLLM was inspired by the idea that LLMs should be operated with the same discipline as distributed systems—using SLIs, SLOs, incident management, and root cause analysis—augmented by AI itself.
Datadog dashboard link: https://p.us3.datadoghq.com/sb/59c9464b-ddaa-11f0-b3b9-524d673540d7-1bc7ff37ee11430a0f0df567f68673f0
What it does
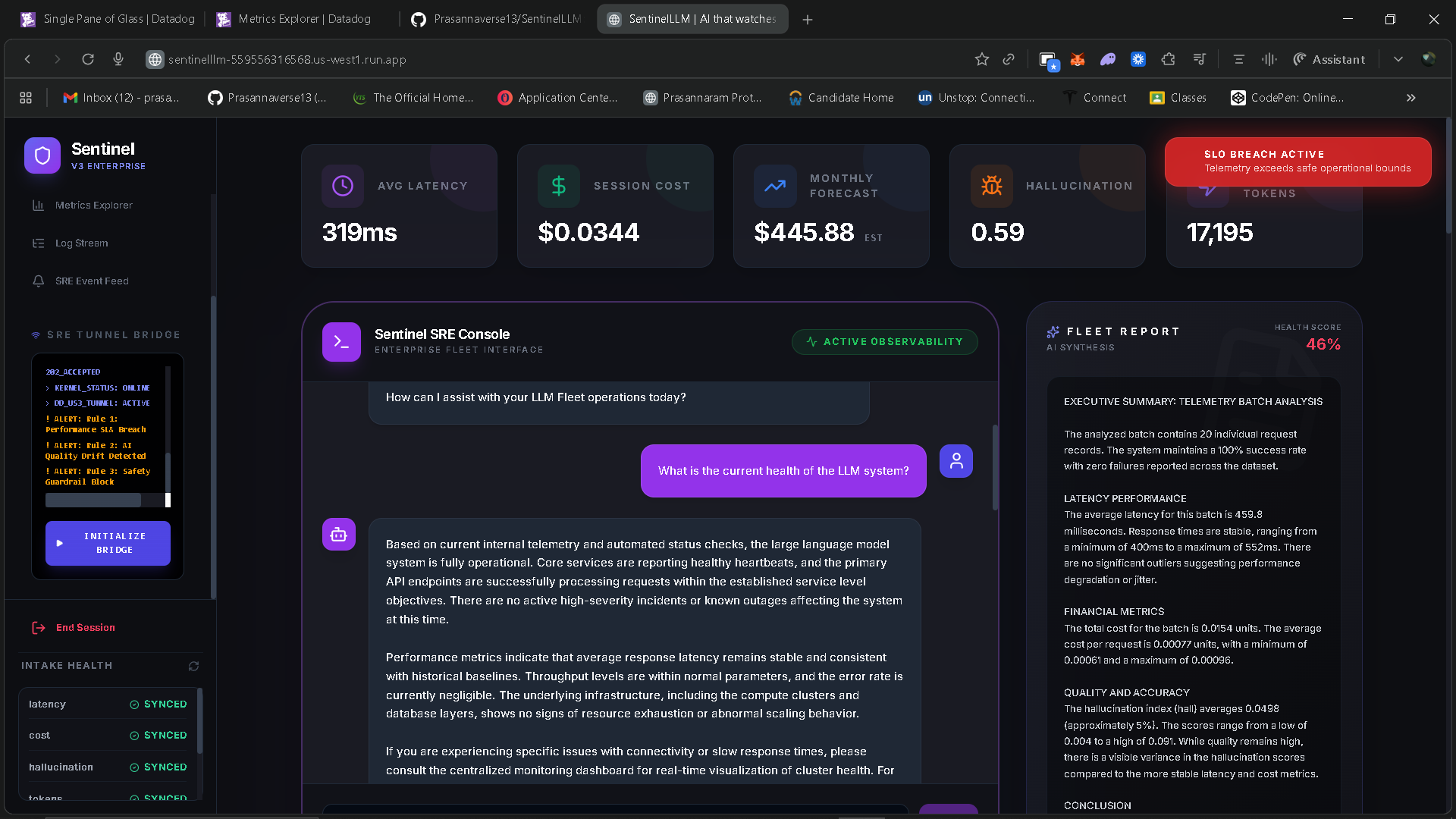
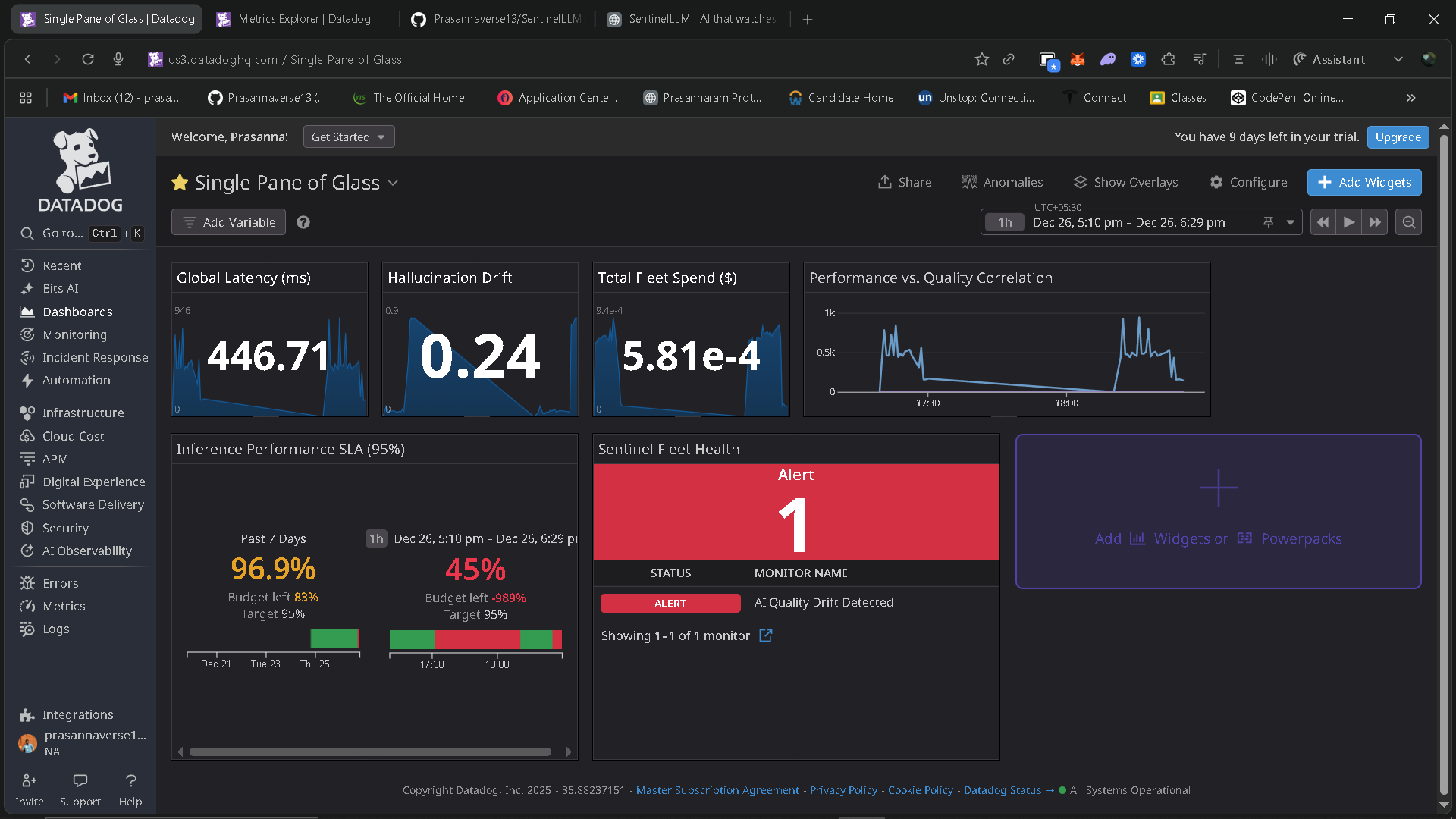
SentinelLLM is an enterprise-grade AI observability and SRE platform for production LLM systems. It provides real-time visibility into four critical dimensions of AI operations: performance, cost, quality, and safety.
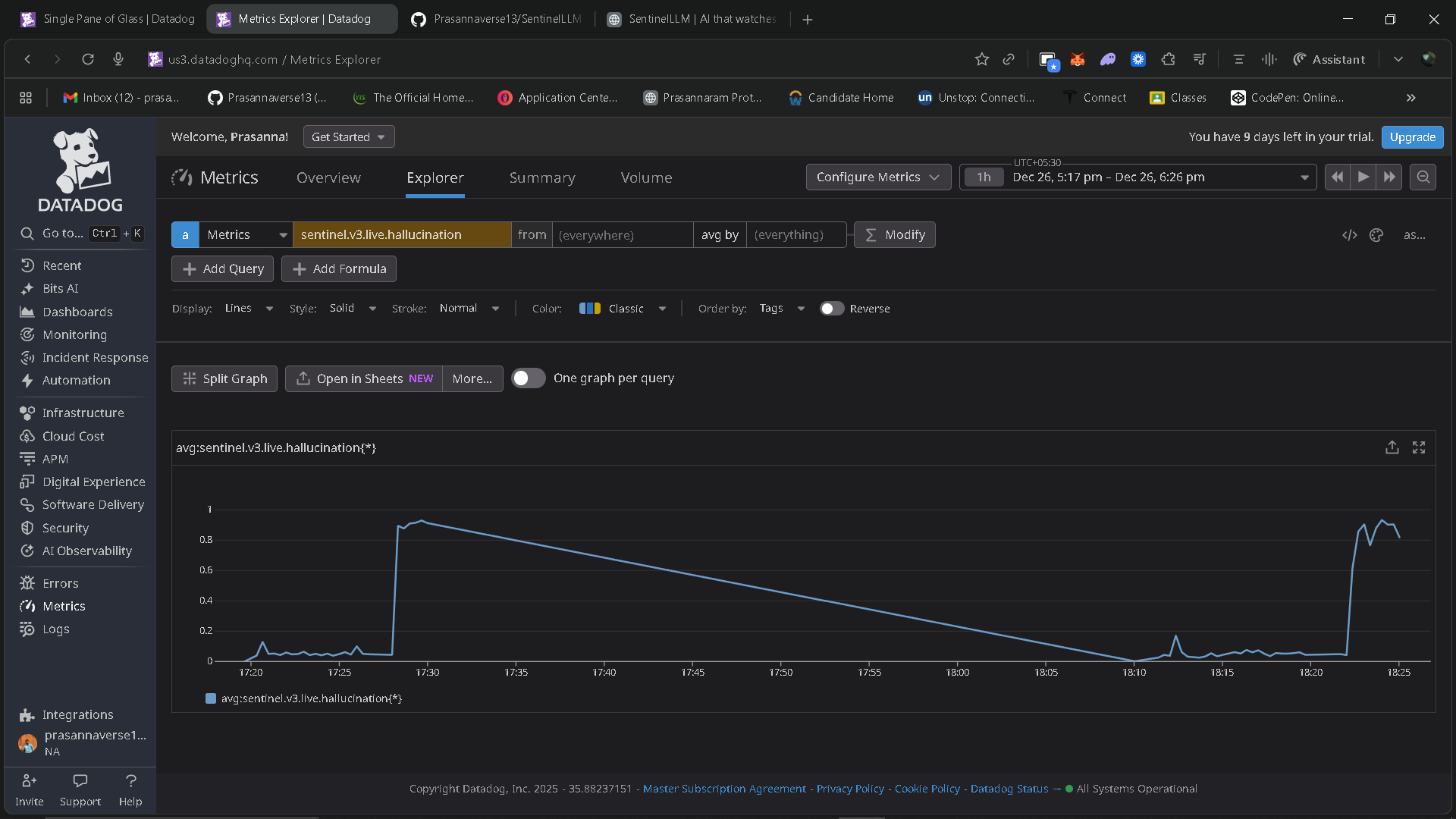
The platform streams live telemetry—latency, token usage, cost per inference, hallucination probability, and safety guardrail signals—into Datadog. On top of this telemetry, SentinelLLM uses Gemini as an autonomous SRE evaluator to reason about incidents, explain why failures occurred, and generate actionable runbooks.
Instead of just showing metrics, SentinelLLM answers operational questions like:
- Why did latency spike?
- Are we overspending on LLM usage?
- Is the model hallucinating more than usual?
- Did a safety guardrail block occur, and why?
How we built it
SentinelLLM is built on Google Cloud and deeply integrated with Datadog.
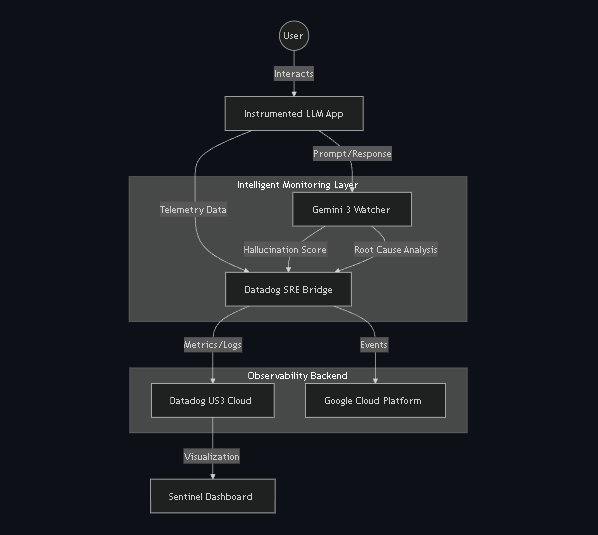
The LLM inference layer runs on Vertex AI using Gemini models. Every request is instrumented to emit structured telemetry. A custom high-resilience component called the SRE Tunnel Bridge securely streams metrics, logs, and events to the Datadog US3 intake using HTTP APIs.
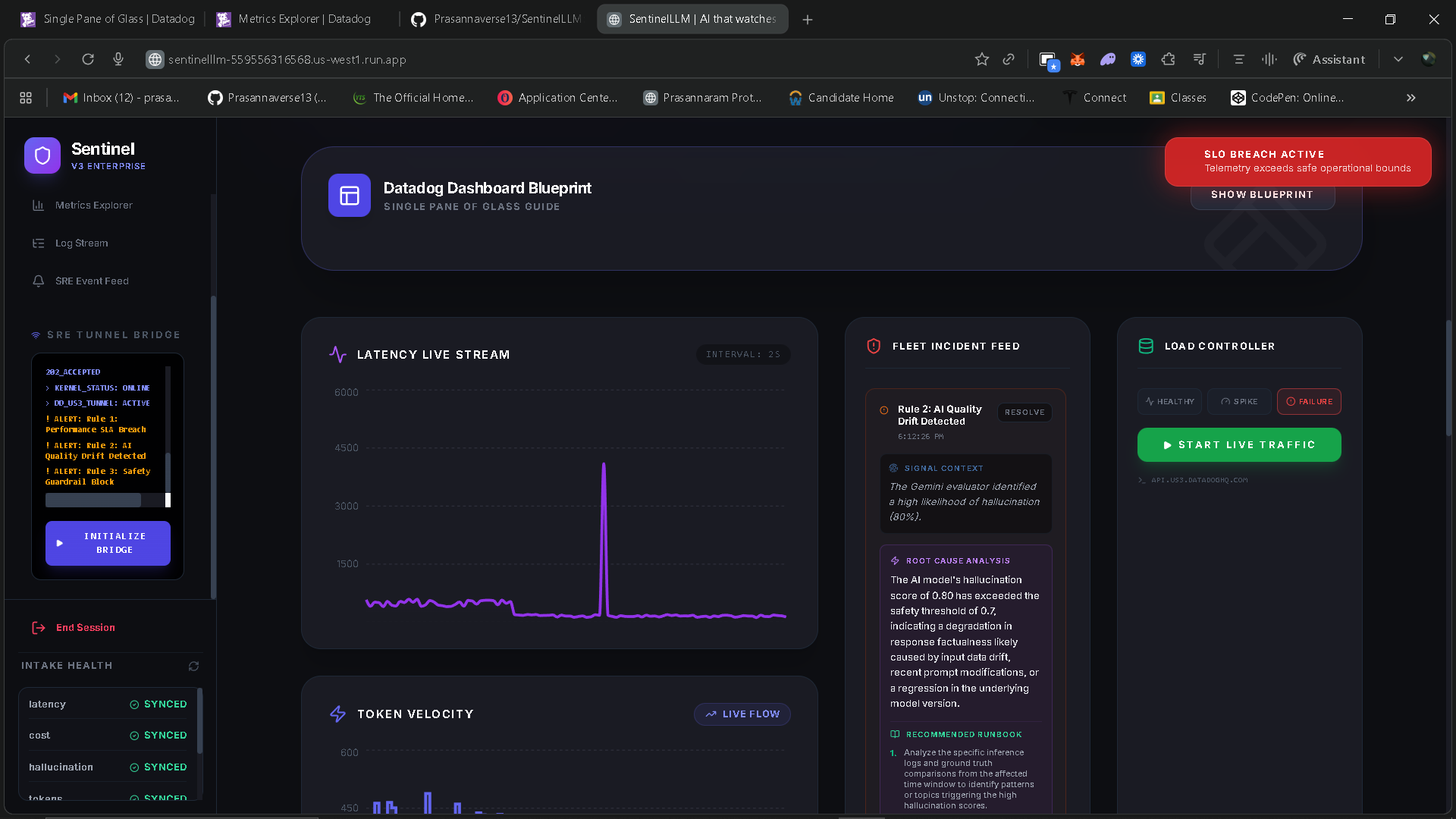
Datadog is used as the observability backbone, handling metrics ingestion, log correlation, monitors, SLOs, and dashboards. Detection rules continuously evaluate signals such as SLA breaches, hallucination drift, and safety blocks.
When a detection rule fires, SentinelLLM invokes a Gemini supervisor model to perform automated root cause analysis. The AI generates a contextual explanation and a step-by-step remediation runbook, which is surfaced directly in the SentinelLLM interface.
The frontend is a real-time operations console that acts as a “single pane of glass,” combining live metrics, SLO status, incident feeds, and an AI SRE assistant.
Challenges we ran into
One of the main challenges was designing AI-specific observability signals that are meaningful and reliable. Metrics like latency and cost are straightforward, but measuring hallucination probability and quality drift required careful prompt design and evaluation logic.
Another challenge was ensuring real-time telemetry ingestion into Datadog without data loss, especially during traffic spikes and failure simulations. Correctly configuring region-specific Datadog endpoints and ensuring consistent metric schemas was critical.
Finally, balancing realism and demo reliability was challenging. We needed the system to behave like a production-grade platform while remaining stable and demonstrable within a hackathon environment.
Accomplishments that we're proud of
We successfully built a working end-to-end system that treats LLMs as first-class production services. SentinelLLM does not just visualize metrics—it closes the loop from detection to explanation to action.
We are particularly proud of:
- Real-time Datadog integration with live metrics, monitors, and SLOs
- Automated AI-driven root cause analysis for LLM incidents
- A clean, enterprise-style operations console that mirrors real SRE workflows
- Exportable Datadog JSON configurations for easy adoption
What we learned
This project reinforced that observability is not just about data collection, but about interpretation and action. AI systems introduce new operational risks, and those risks require new observability primitives beyond traditional infrastructure metrics.
We also learned that AI can be used not only as the system being monitored, but as the system doing the monitoring. Using Gemini as an SRE evaluator unlocked powerful automation for incident analysis and decision support.
What's next for SentinelLLM
Next, we plan to expand SentinelLLM with deeper trace-level analysis, cross-model comparisons, and long-term trend detection for prompt drift and quality regression.
We also aim to integrate automated remediation workflows, where SentinelLLM can suggest or execute safe corrective actions such as prompt rollbacks, caching strategies, or model configuration adjustments.
Ultimately, SentinelLLM aims to become a standard SRE layer for AI systems—bringing reliability, transparency, and operational confidence to production LLM deployments.
Log in or sign up for Devpost to join the conversation.