-
-
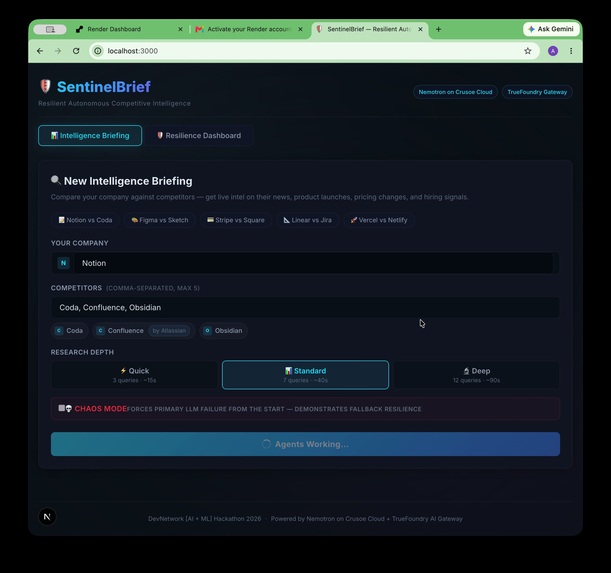
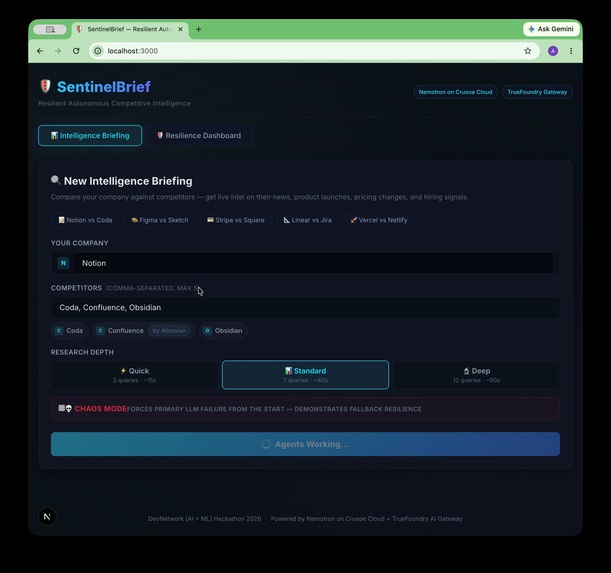
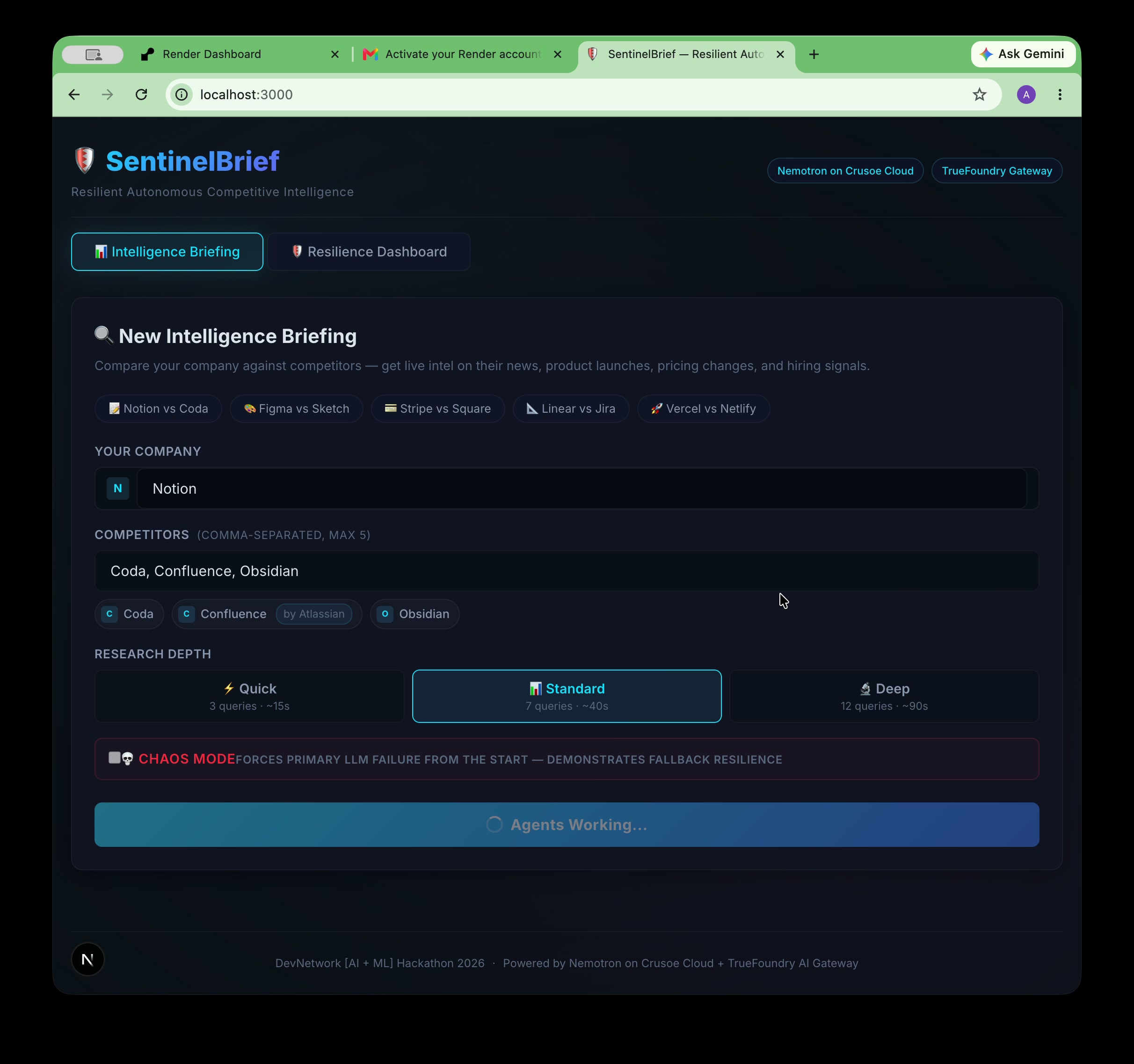
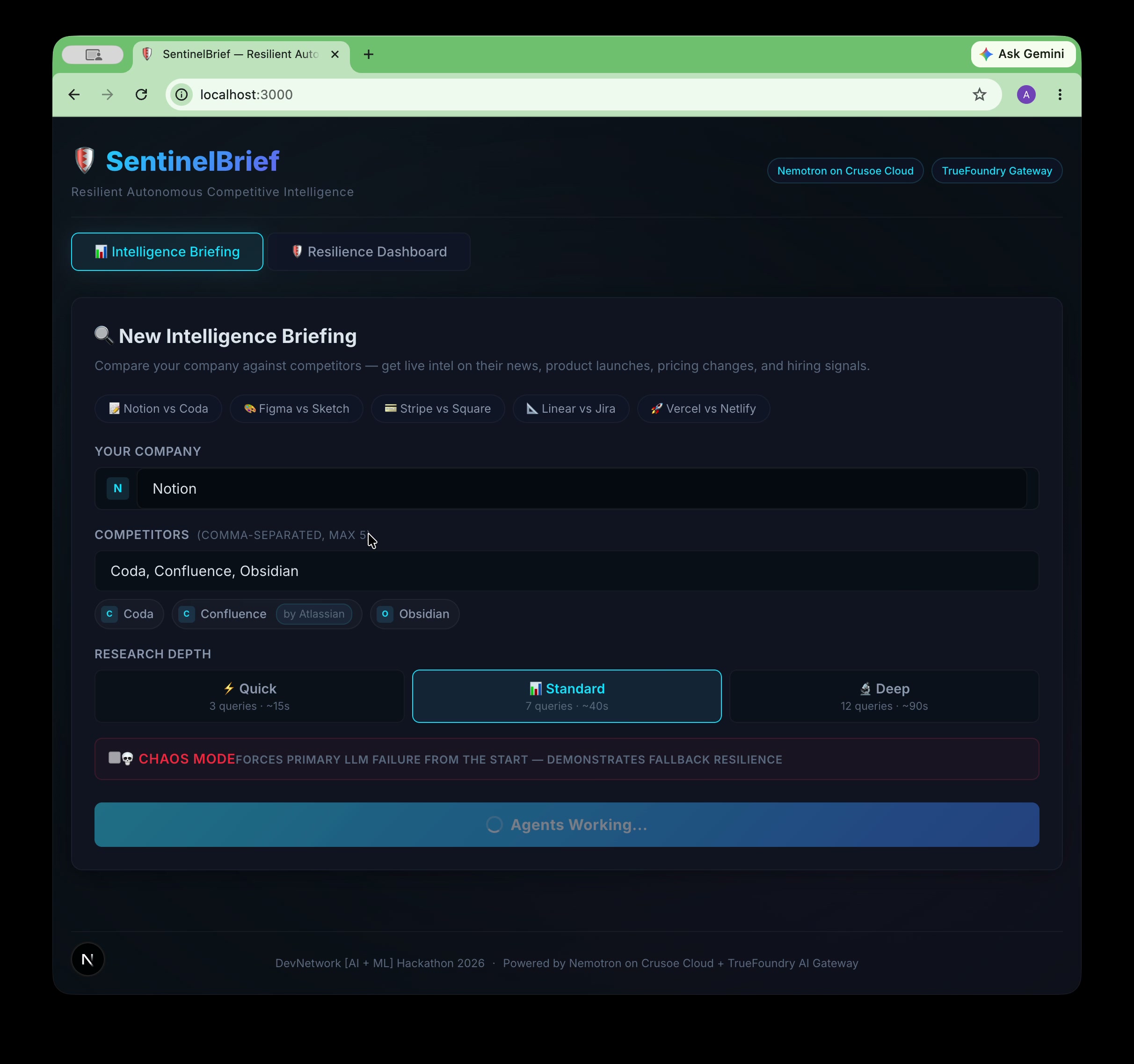
Notion vs Coda, Confluence, Obsidian. One click. Agents working. Parent company resolver handles Confluence → Atlassian.
-
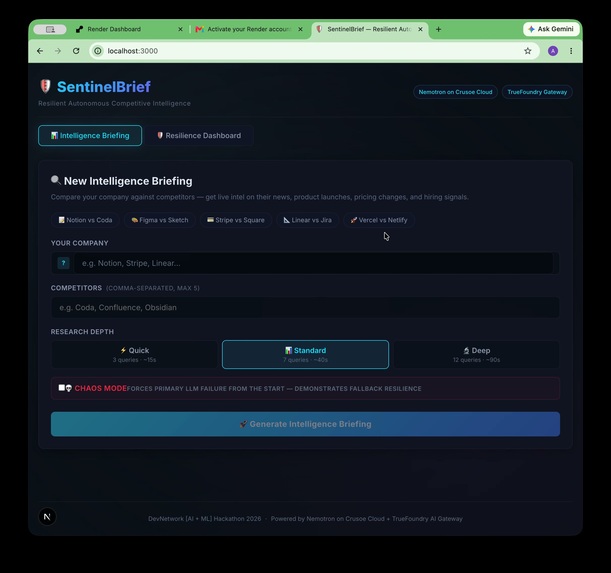
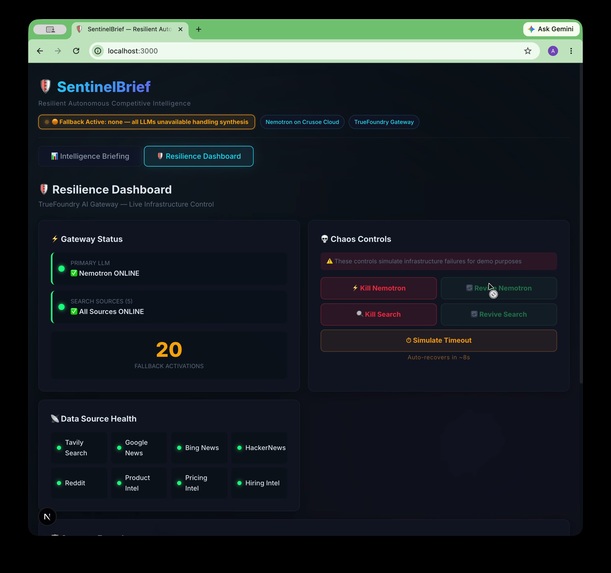
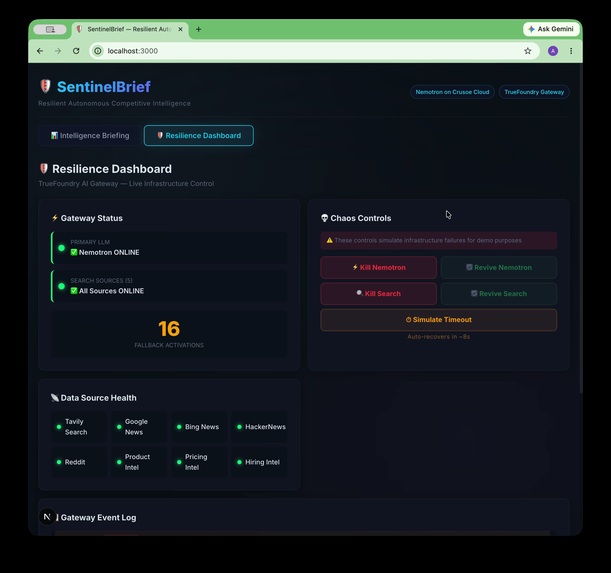
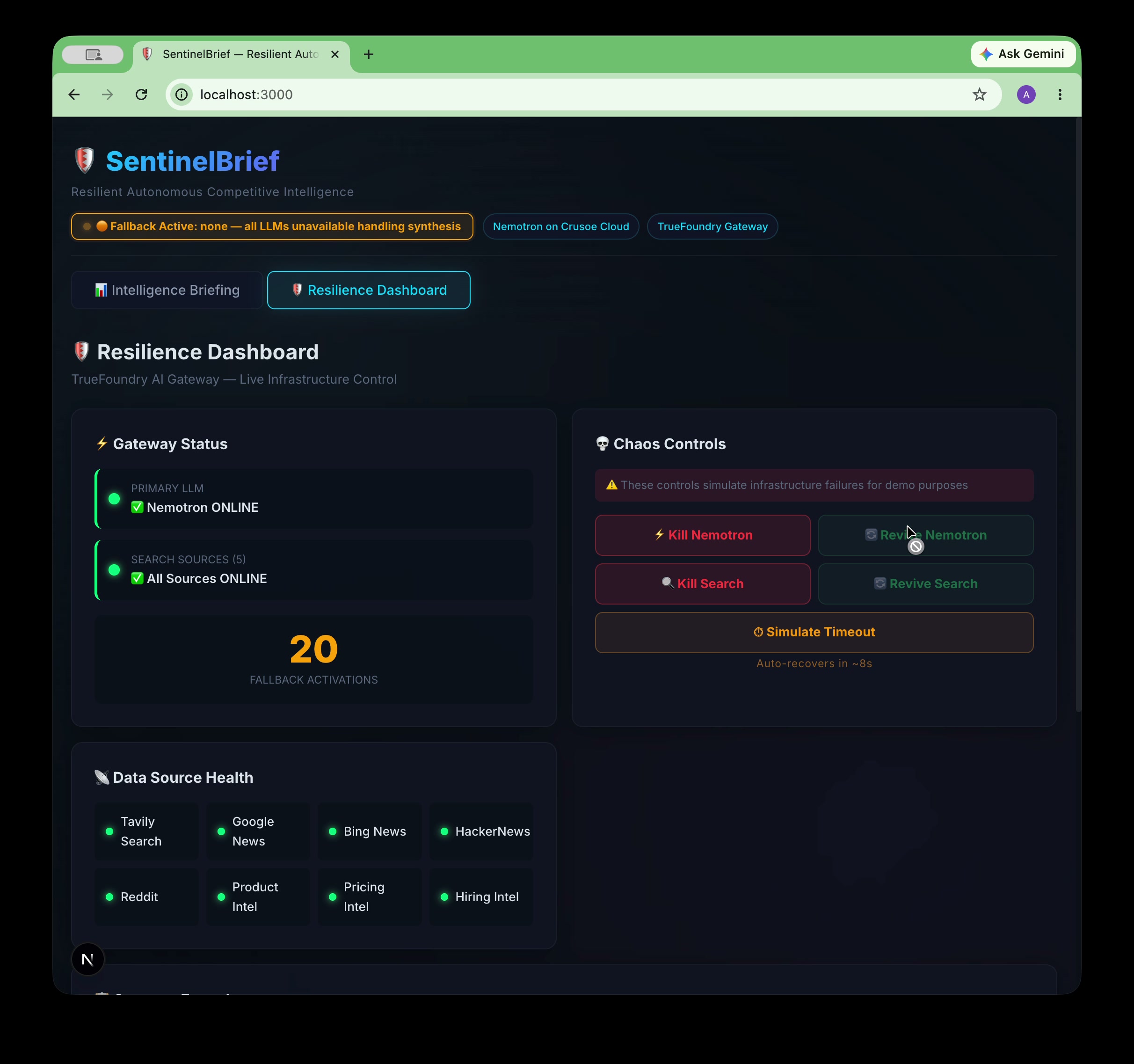
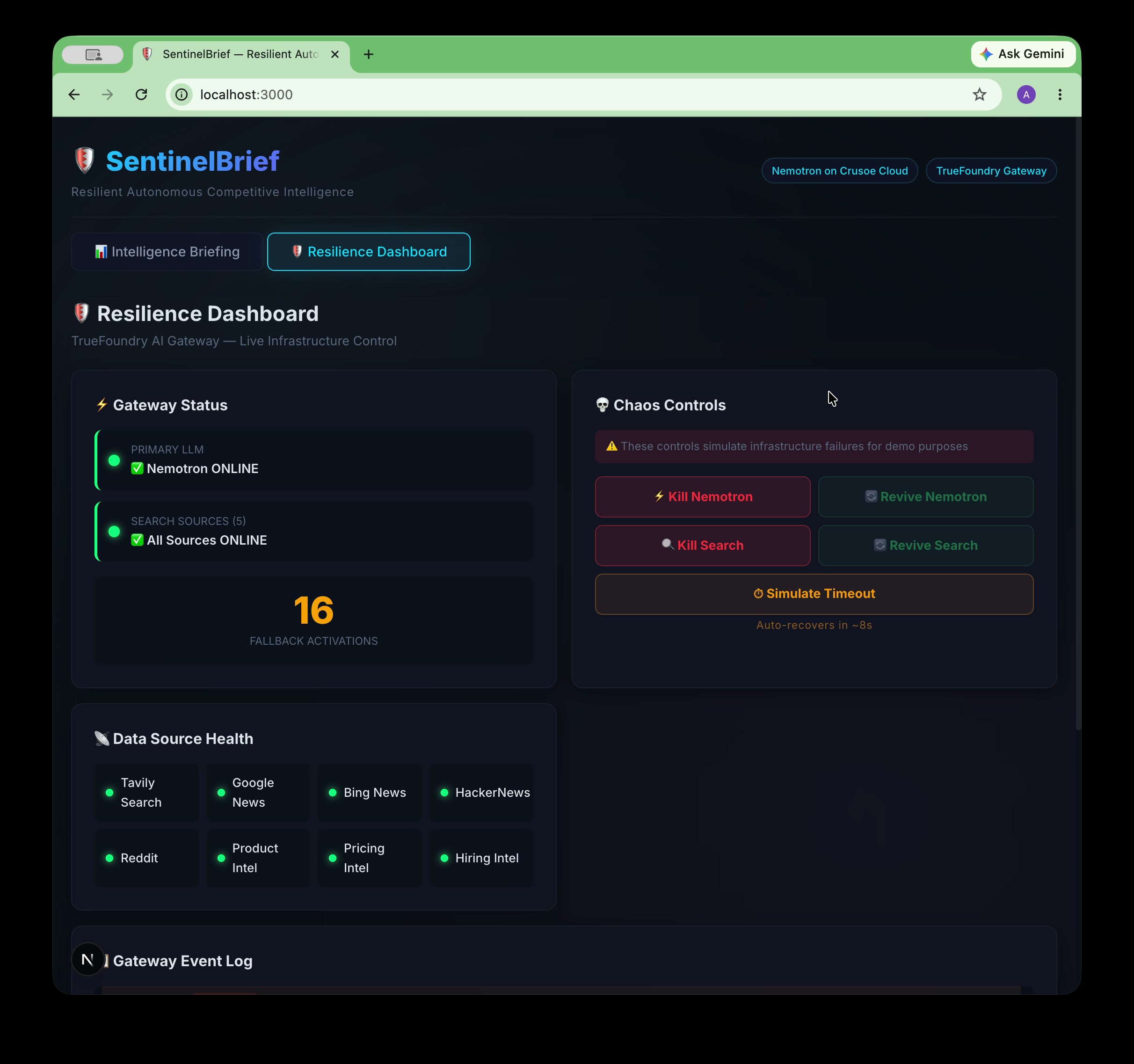
Full UI — Intelligence Briefing + Resilience Dashboard. CHAOS MODE forces LLM failure live to prove TrueFoundry fallback.
-
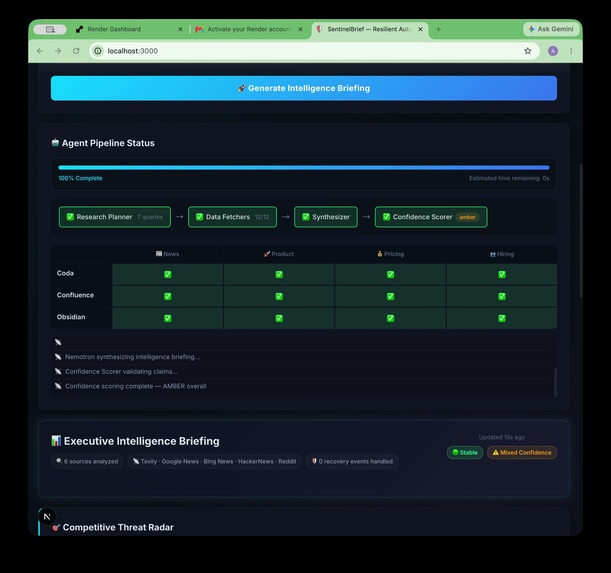
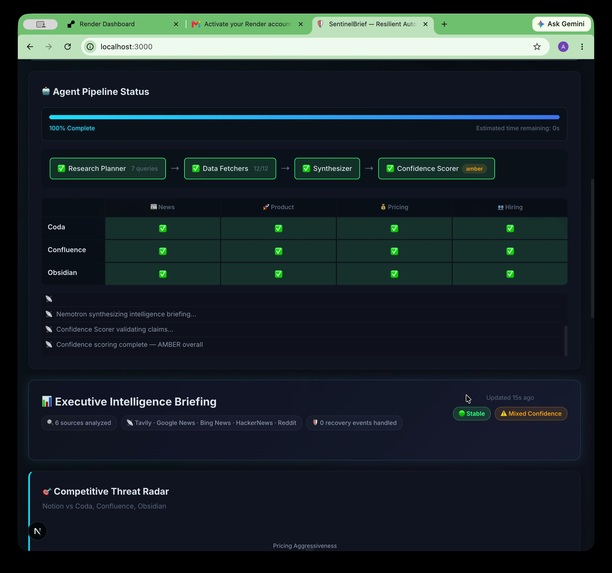
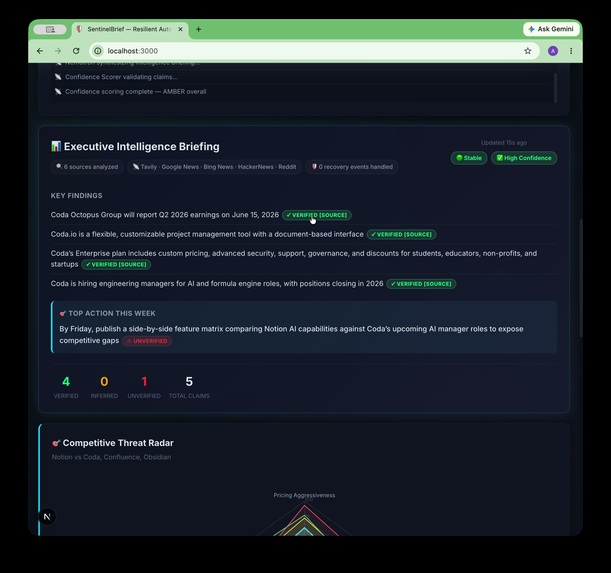
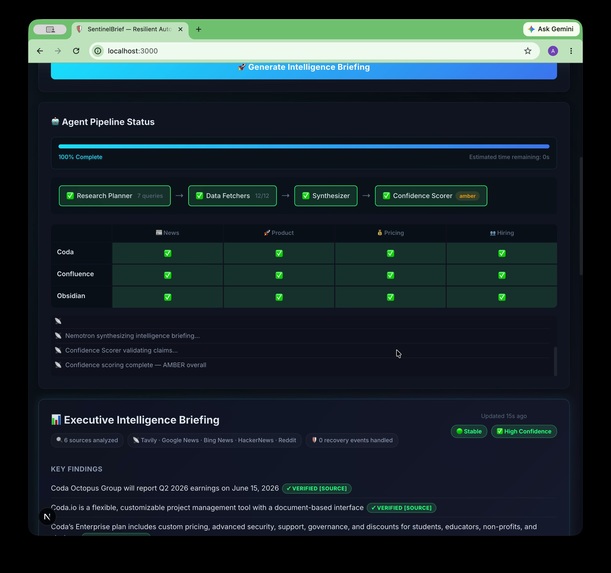
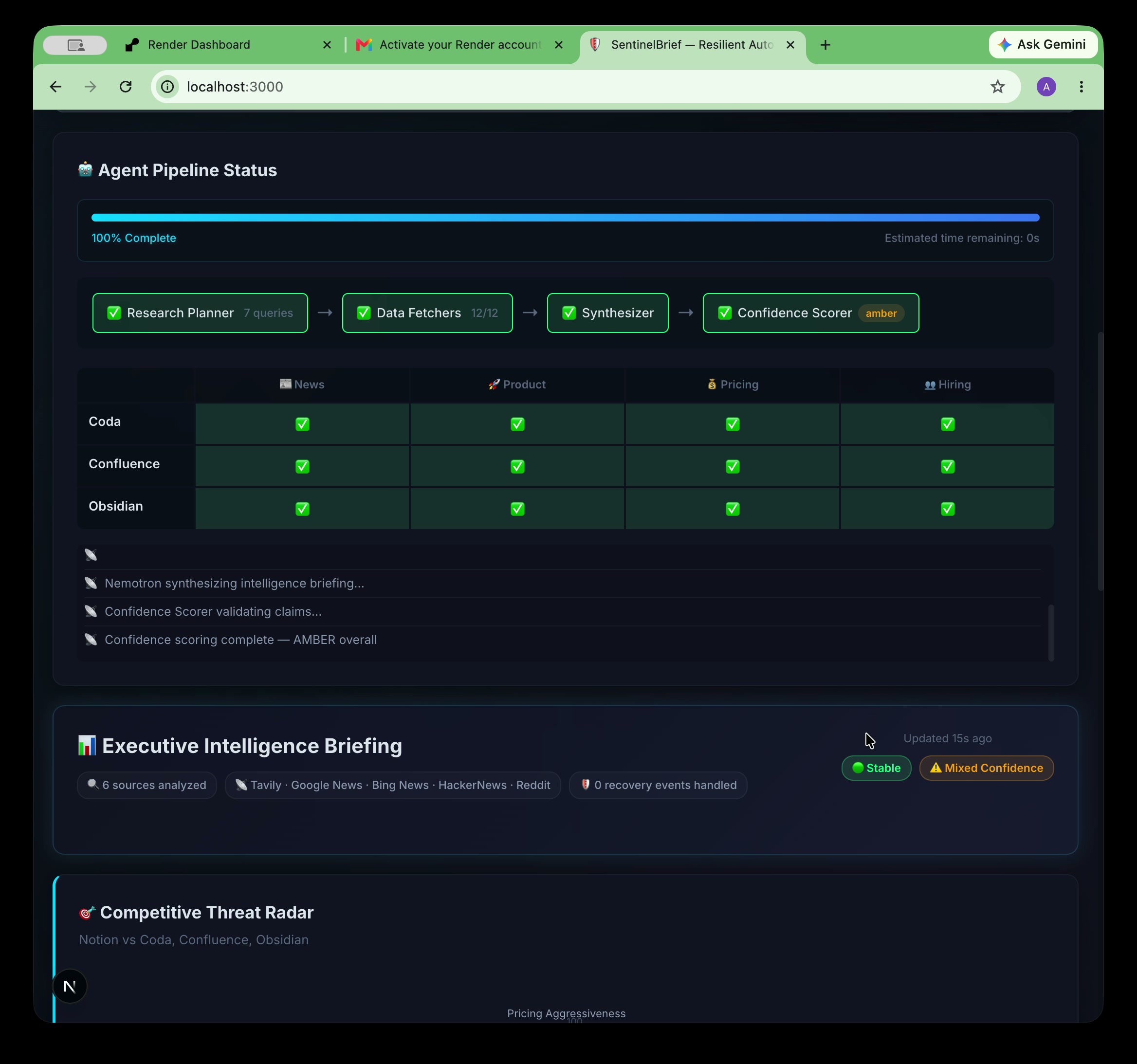
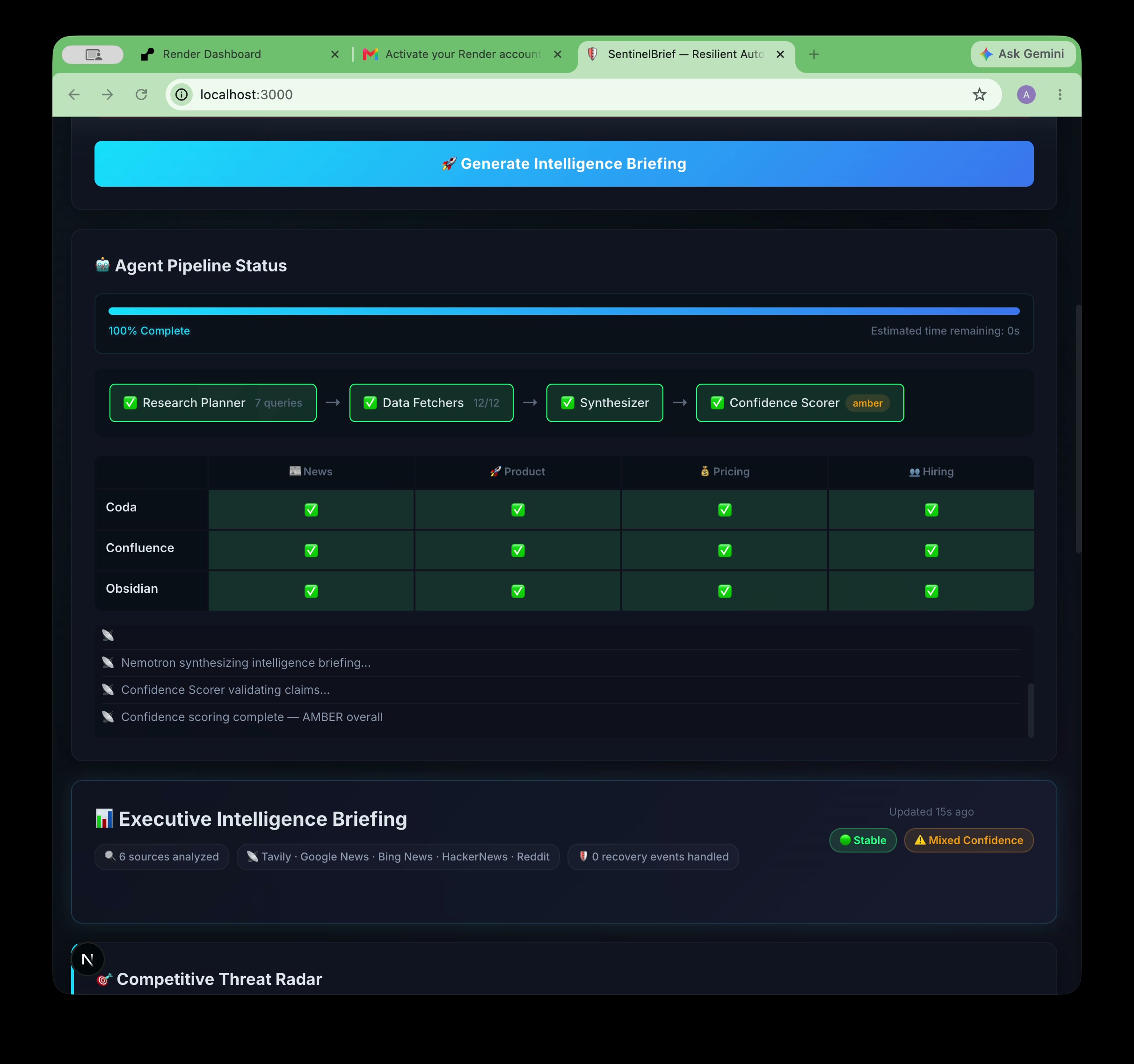
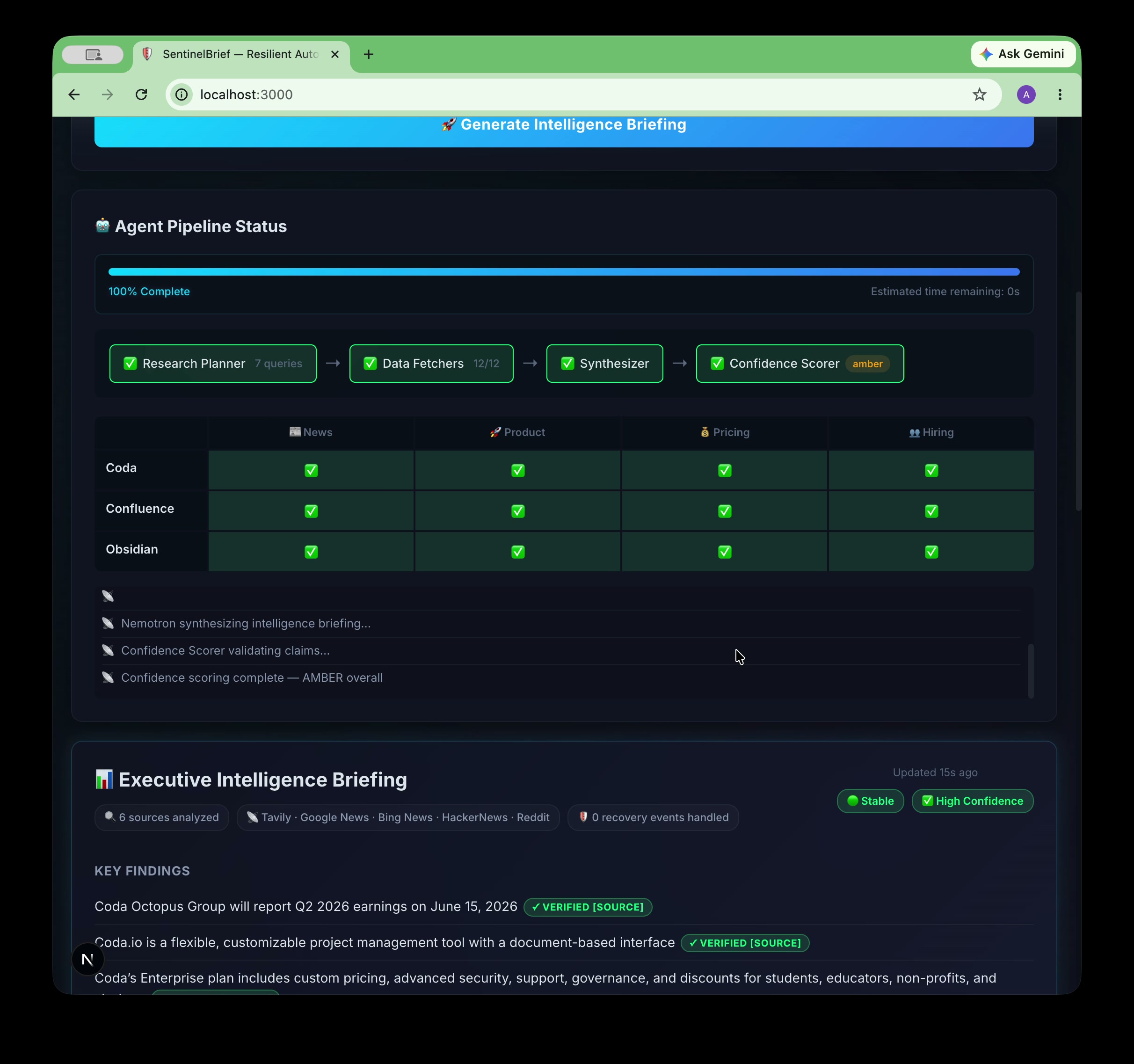
12/12 fetches done. Research Planner → Data Fetchers → Synthesizer → Confidence Scorer. 40s. Zero silent failures.
-
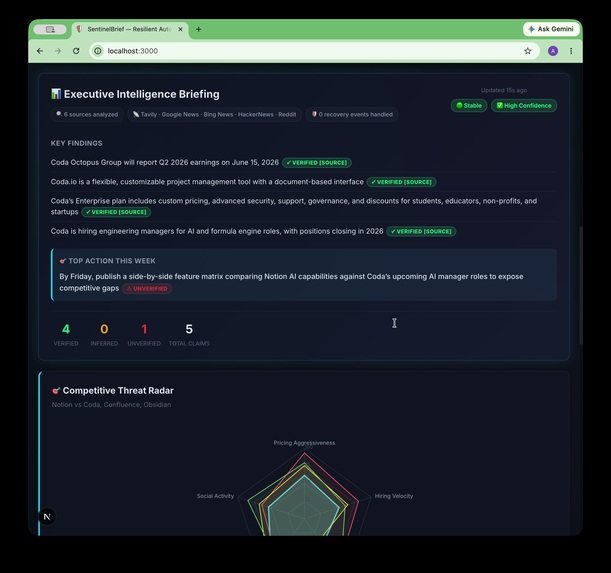
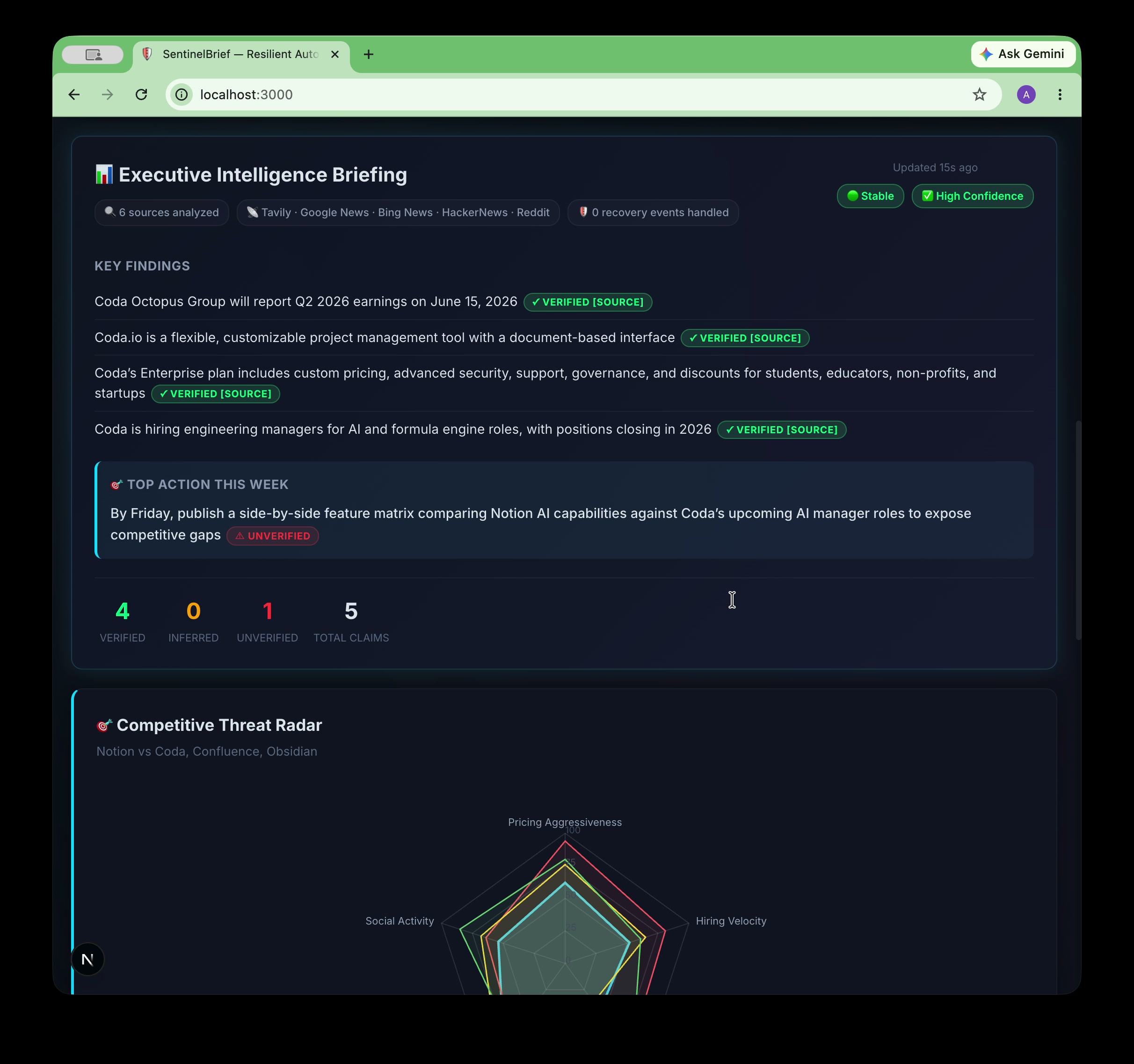
100% complete. 6 sources. Tavily · Google News · Bing · HackerNews · Reddit. Stable run. Mixed confidence flagged honestly.
-
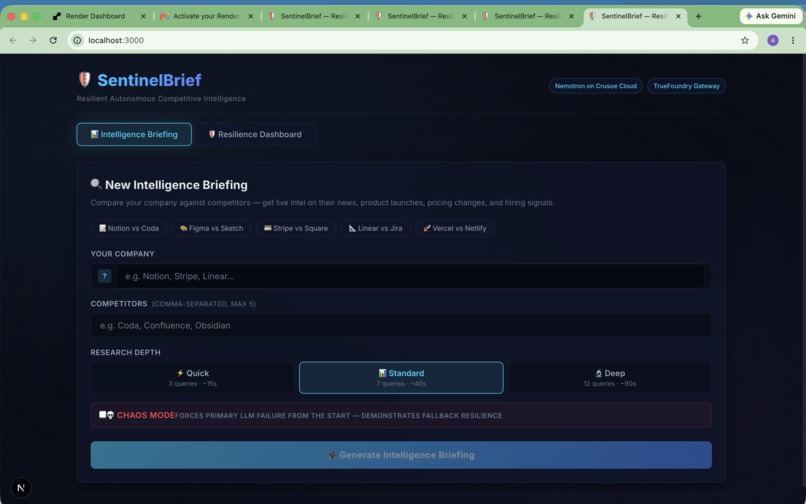
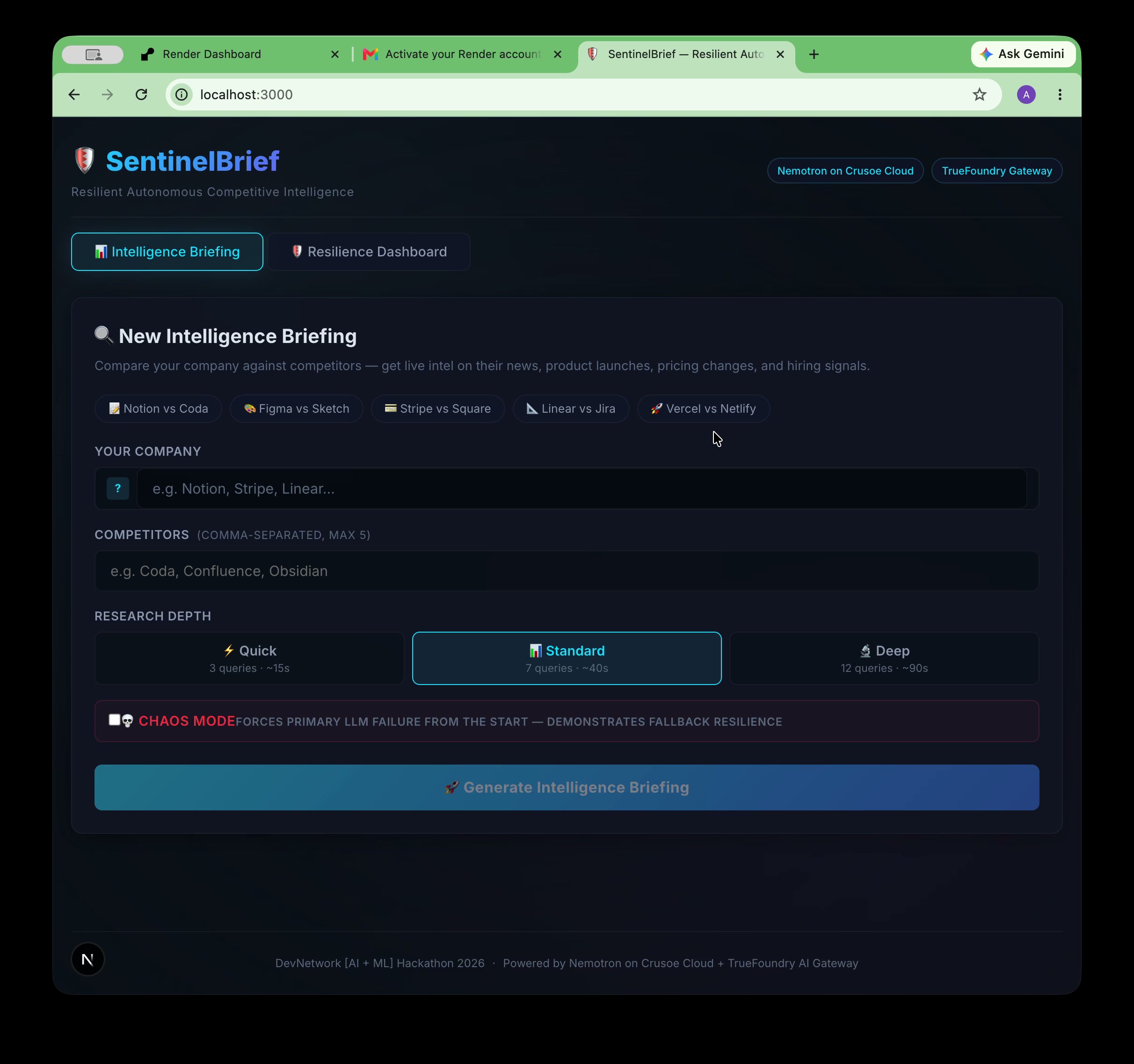
Meet SentinelBrief — enter a company, add competitors, pick depth. Autonomous CI powered by Nemotron on Crusoe Cloud.
-
-
-
-
-
-
Inspiration
Every founder I know spends 4–6 hours per week doing the same soul-crushing ritual: opening 15 browser tabs, scanning news sites, checking competitors' pricing pages, skimming Reddit threads, and trying to piece together a coherent picture of what's happening in their market. When they turn to AI agents for relief, they get something arguably worse — agents that fail silently. Partial output with no warning. Hallucinated claims with no sources. A crashed pipeline with no way to resume.
SentinelBrief was born from a simple frustration: why should competitive intelligence be either expensive, manual, or unreliable? I wanted to build an agent that was fast, verifiable, and — above all — one that never let you down without telling you why.
What it does
Give SentinelBrief a company profile and up to 5 competitors. It autonomously:
- Plans targeted research queries via a Nemotron-powered reasoning planner — choosing the right search terms so you get signal, not noise.
- Fetches intelligence in parallel across 5 independent sources — Tavily, Google News, Bing News, HackerNews, and Reddit — each with isolated timeout protection.
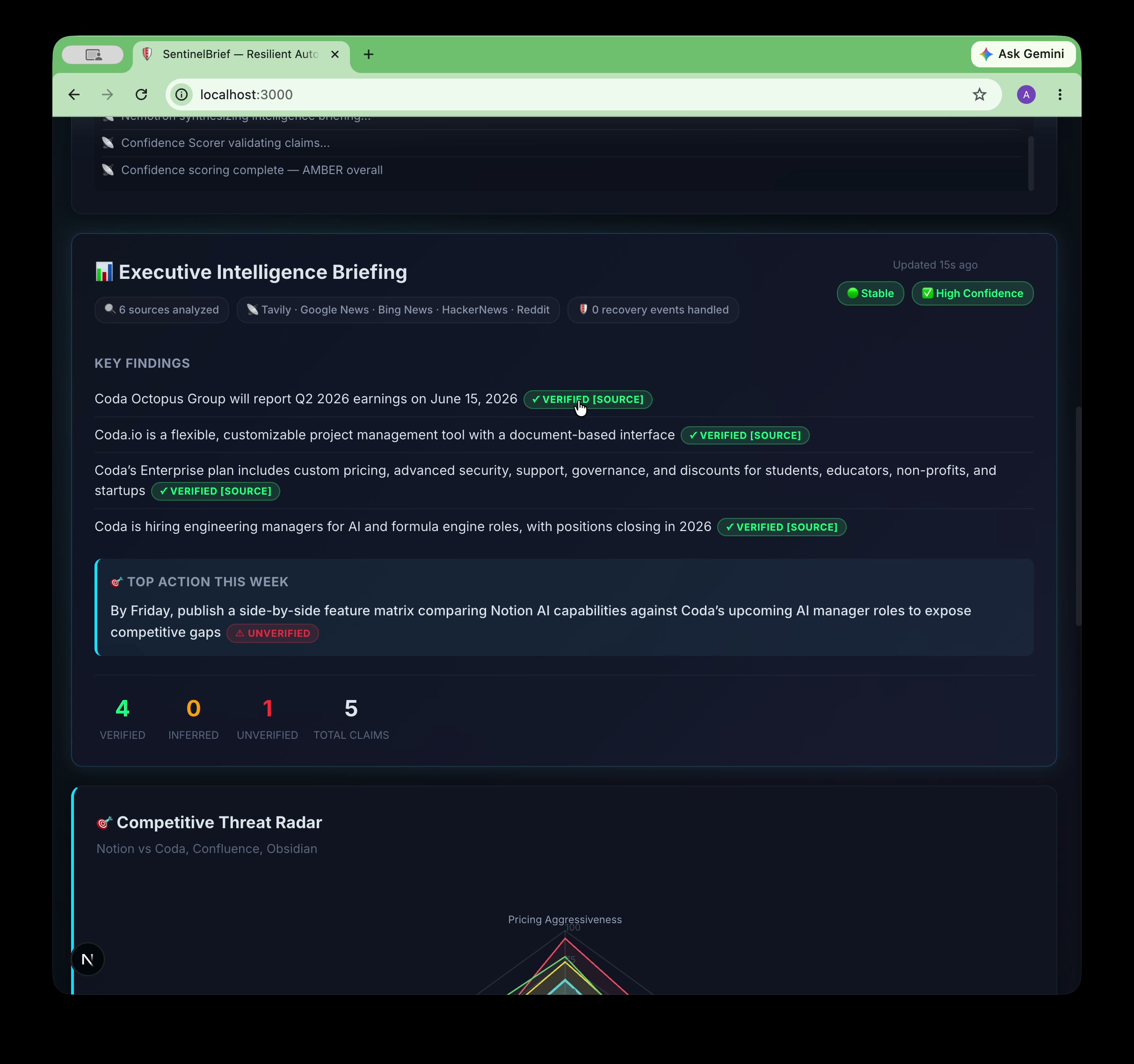
- Synthesizes findings into structured briefings where every factual claim carries a VeracityAI confidence tag:
[VERIFIED: url],[INFERRED], or[UNVERIFIED]— so you always know how much to trust what you're reading. - Scores competitive threats across 5 dimensions (Pricing, Hiring, Funding, Product, Social) and renders an interactive radar chart so you can see at a glance who's gaining on you and where.
- Recovers automatically from failures — if the pipeline crashes mid-run, it resumes from the last completed checkpoint rather than starting over.
The entire pipeline streams live to the UI via SSE, so you watch every agent node execute in real time with a progress bar.
How we built it
I designed SentinelBrief as a stateful multi-agent pipeline with crash resilience baked in from day one, not bolted on as an afterthought.
The Agent Pipeline
The architecture follows a clear directed graph:
$$\text{Planner} \rightarrow \text{5} \times \text{Parallel Fetchers} \rightarrow \text{Synthesizer} \rightarrow \text{VeracityAI Scorer} \rightarrow \text{Briefing}$$
- Research Planner — Nemotron-3-Nano-30B (running on Crusoe Cloud) generates prioritized, competitor-specific search queries before any fetching begins. Research depth scales from Quick ($n=3$ queries) to Standard ($n=7$) to Deep ($n=12$).
- 5-Source Parallel News Agent — Five independent fetchers (Tavily, Google News RSS, Bing News, HackerNews Algolia, Reddit) run concurrently via
asyncio.gather, each with a 14-second timeout. A single source failure doesn't take down the pipeline. Results are deduplicated by URL and ranked by source quality. - Specialized Agents — Three additional agents track product launches, pricing changes, and hiring signals. The hiring agent includes a parent company lookup so that searching "Confluence" correctly queries "Atlassian."
- Synthesizer Agent — All gathered intelligence is merged and fed to Nemotron with a strict prompt that enforces
[VERIFIED: url],[INFERRED], or[UNVERIFIED]tags on every single factual claim. - VeracityAI Scorer — A dedicated regex-based validation pass counts and validates all confidence tags, computing per-competitor scores and rendering color-coded badges (green / amber / red).
Resilience Layer
Every LLM call is routed through TrueFoundry AI Gateway, which provides automatic failover from Nemotron → GPT-4o, rate-limit protection, and a live event log. Checkpoint state is persisted to Upstash Redis with 24-hour TTL — if the pipeline crashes mid-run, it resumes from the last completed node, not from scratch.
Stack
| Layer | Technology |
|---|---|
| Frontend | Next.js 15 + React 19 + Recharts |
| Backend | FastAPI + Python 3.11 + async orchestration |
| LLM | Nemotron-3-Nano-30B on Crusoe Cloud |
| Resilience | TrueFoundry AI Gateway |
| State | Upstash Redis (checkpoints) |
| Database | Neon PostgreSQL |
| Deployment | Vercel (frontend) + Render (backend via Docker) |
Challenges we ran into
- Nemotron's non-standard response format. Nemotron-3-Nano returns output in a
reasoningfield rather thancontent. I had to build a custom content extractor that checks both fields transparently, or half my pipeline would return empty strings with no error. - Getting reliable structured output from an LLM. Convincing Nemotron to consistently emit
[VERIFIED: url]tags on every claim — not sometimes, not on the first few bullets — required multiple rounds of prompt engineering and a dedicated regex-based validation layer as a safety net. - Coordinating 5 parallel sources cleanly. Each of the five news APIs has different rate limits, response schemas, failure modes, and latency profiles. Building a unified async pipeline that isolates each source's failures while still producing a coherent merged result took significant architecture work.
- Parent company resolution. A search for "Confluence hiring" returns noise. A search for "Atlassian hiring" returns signal. Building a product-to-parent lookup system that works correctly across the frontend and backend — and handles edge cases like rebrands and subsidiaries — was more involved than expected.
- Normalizing LLM output to consistent $[0, 100]$ scores. The competitive threat radar chart requires scoring each competitor across 5 dimensions (Pricing, Hiring, Funding, Product, Social). Extracting structured numeric scores from free-form synthesis text, with sensible fallback defaults, required careful prompt design and a post-processing extraction pass.
Accomplishments that we're proud of
- Zero silent failures. Every error in the pipeline — a timed-out API, a failed LLM call, a malformed response — is caught, logged, and surfaced to the user. This was a design goal from day one and we held the line on it throughout.
- VeracityAI confidence tagging at scale. Getting a 30B reasoning model to reliably annotate every factual claim with a source-backed confidence tag across hundreds of claims per run required serious prompt engineering. Seeing it work consistently felt like a genuine breakthrough.
- Live chaos engineering demo. The Resilience Dashboard lets you kill Nemotron, kill search, or simulate a timeout mid-run and watch the system recover automatically via TrueFoundry Gateway fallback. It's one thing to say your system is resilient — it's another to prove it live in front of judges.
- 5-source parallel intelligence that holds together. Coordinating five APIs with different schemas, rate limits, and failure modes into a single deduplicated, ranked result — without any one source blocking the others — is something we're genuinely proud of architecting cleanly.
- Full checkpoint-resume on crash. Upstash Redis checkpointing means a mid-run infrastructure failure costs you seconds, not minutes. We built this expecting to rarely need it. We needed it constantly during development — and it saved us every time.
What we learned
- Silence is the worst failure mode an agent can have. An agent that returns 40% of the data and says nothing is more dangerous than one that crashes loudly. Every design decision in SentinelBrief was shaped by this principle.
- Prompt engineering is a first-class engineering discipline. Getting structured, verifiable output from an LLM at scale is not a one-shot task. It's an iterative loop of testing, failure analysis, and refinement — no different from debugging any other software component.
- Checkpoint-first design pays off immediately. We added Redis checkpointing expecting to use it in rare edge cases. We used it constantly. Designing for crash recovery from the start — rather than retrofitting it — was one of our best architectural decisions.
- Source diversity beats source depth. Five parallel sources with independent timeouts consistently outperformed any single high-quality source, even when individual sources returned sparse results. Redundancy is a feature.
- Reasoning models need custom handling. Nemotron-3-Nano's
reasoningvscontentfield distinction is a small thing that breaks everything if you miss it. Always read the model card before assuming OpenAI-compatible means behaviorally identical. - Chaos engineering surfaces hidden assumptions. Building the kill-switch dashboard forced us to handle every failure mode explicitly — and revealed several implicit assumptions baked in that would have caused silent failures in production.
What's next for SentinelBrief
| Phase | Timeline | Goal |
|---|---|---|
| 🚀 Beta Launch | June 2026 | Onboard 50 founders for weekly automated briefings |
| 💰 Monetize | Q3 2026 | Solo ($49/mo), Team ($199/mo), Enterprise ($999/mo) |
| 🔗 Integrations | Q4 2026 | CRM sync (Salesforce, HubSpot), Slack/Teams delivery, PDF export |
| 🧠 Deeper Intelligence | 2027 | Longitudinal trend analysis, patent monitoring, earnings call summarization |
Beyond the roadmap, the core vision is to make SentinelBrief the competitive intelligence layer that any B2B SaaS team can plug into their existing workflow — not another dashboard to check, but a briefing that finds you. The resilience architecture we built during this hackathon is the foundation that makes that kind of always-on, production-grade reliability possible.

Log in or sign up for Devpost to join the conversation.