-
-
List of responders
-
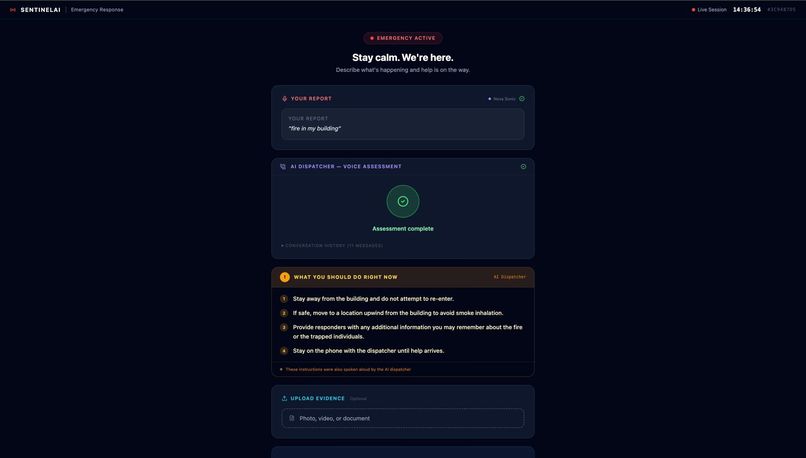
Guidelines provided to citizen by AI once information is gathered
-
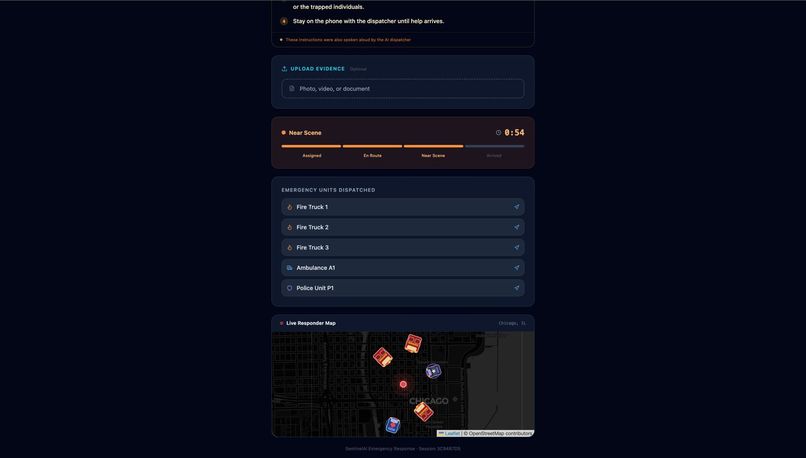
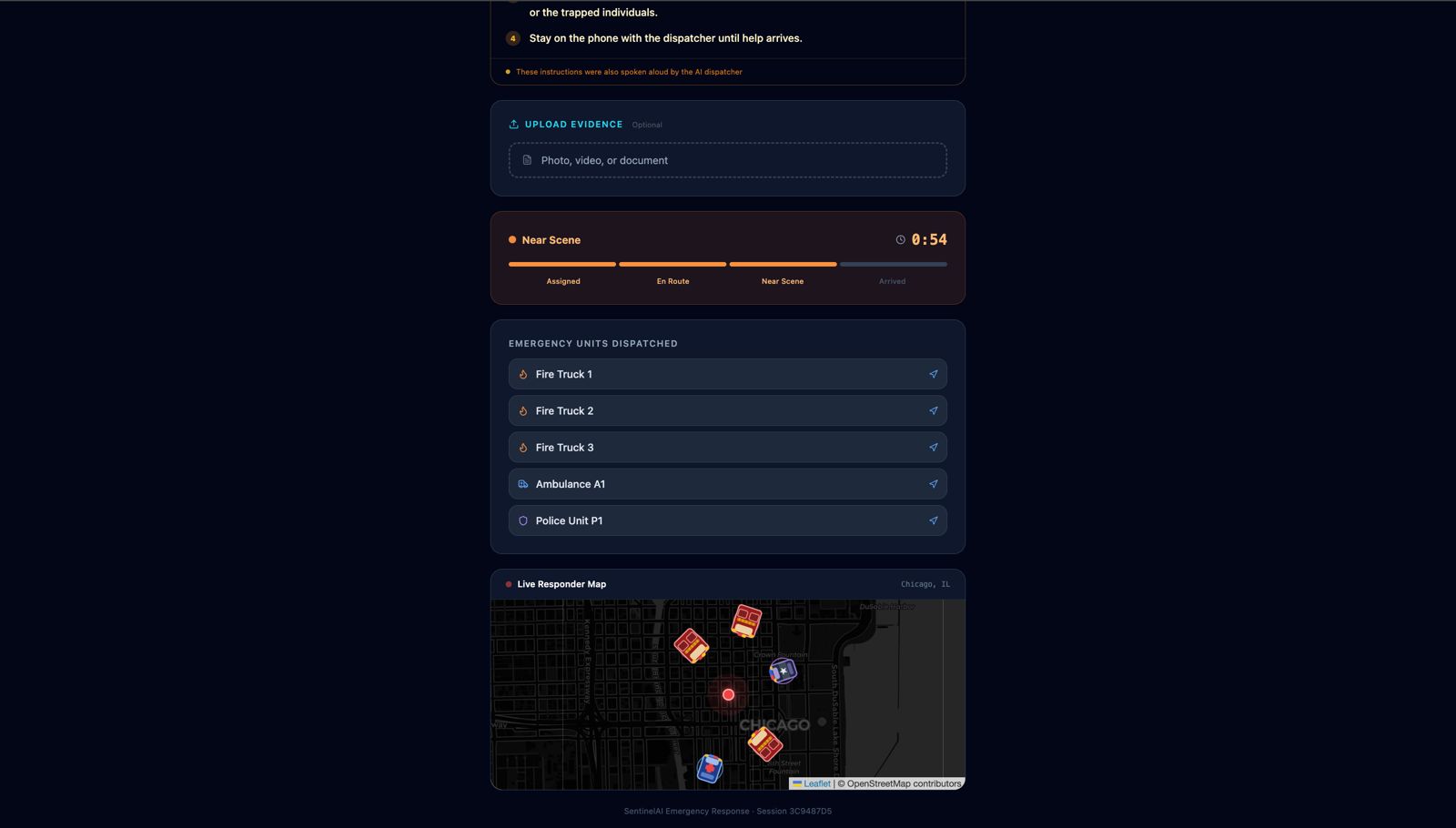
Live map integration and dispatch status for citizens
-
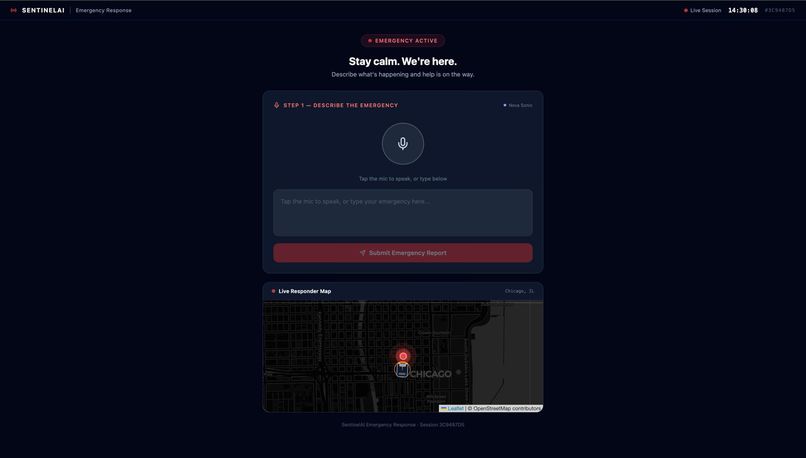
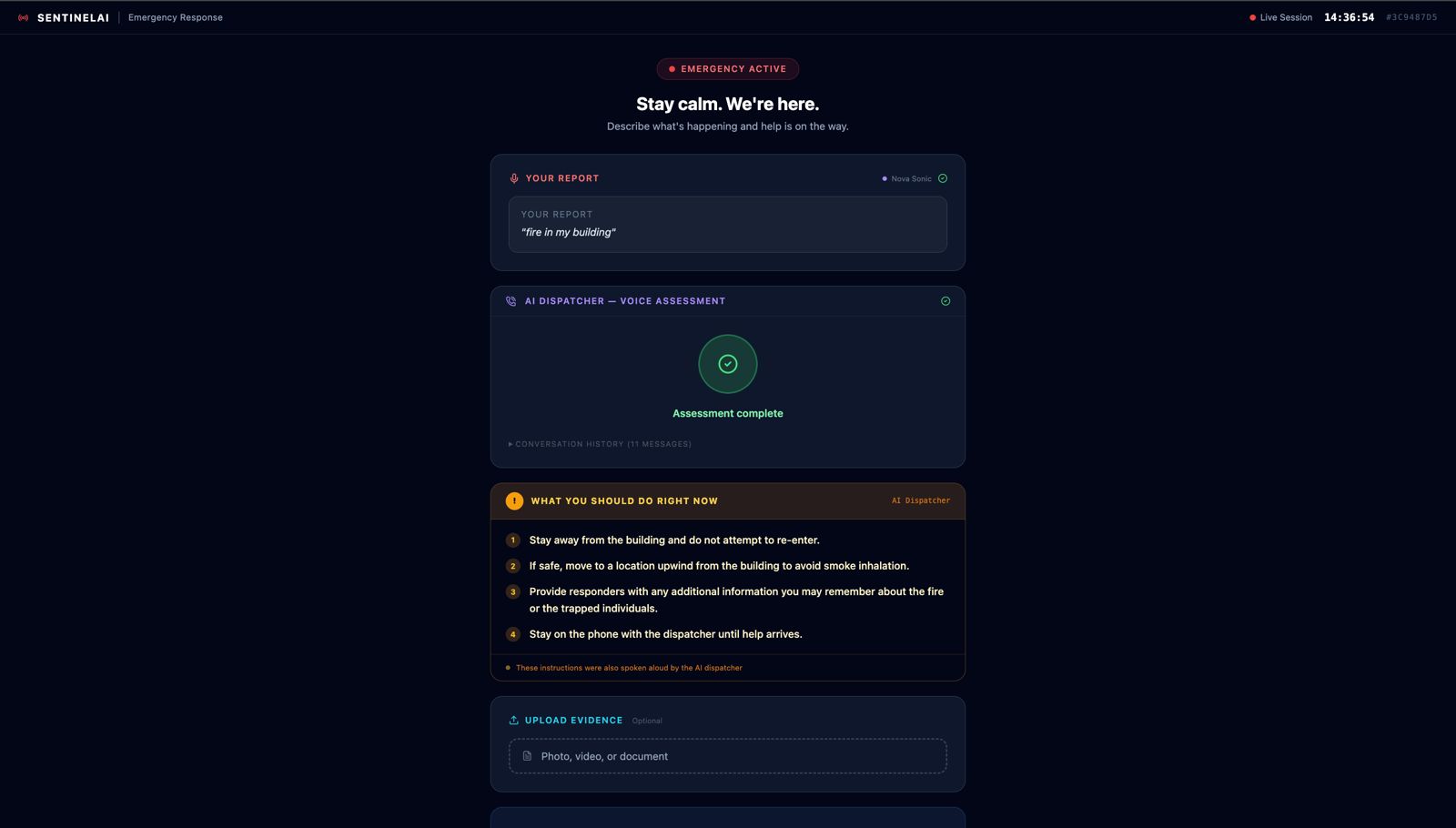
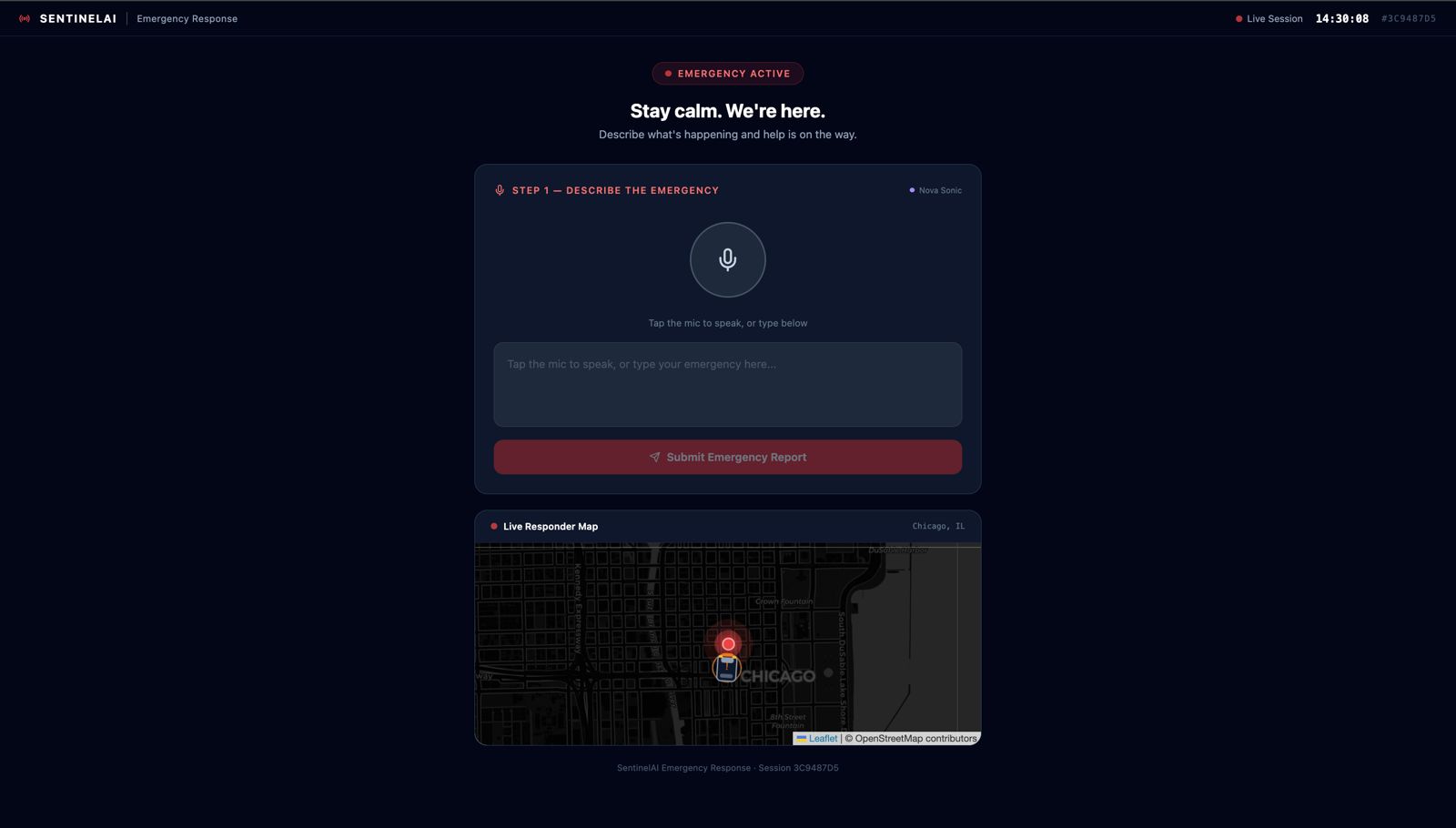
Describing the situation via voice command input
-
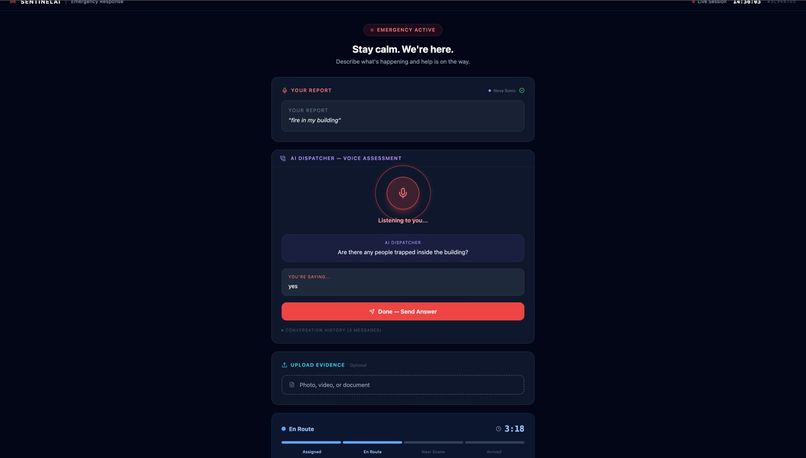
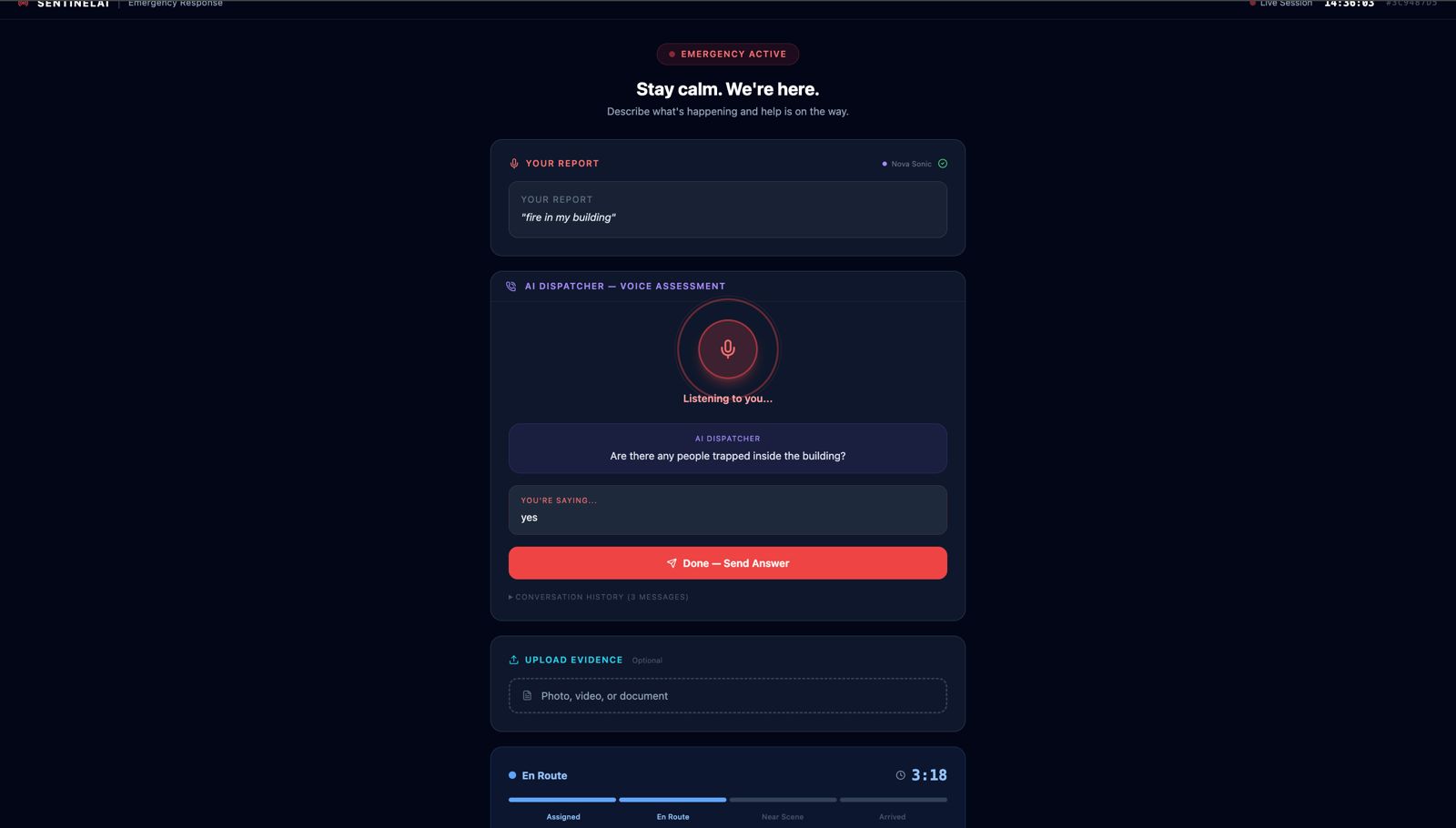
AI agent asking questions related to the scene
-
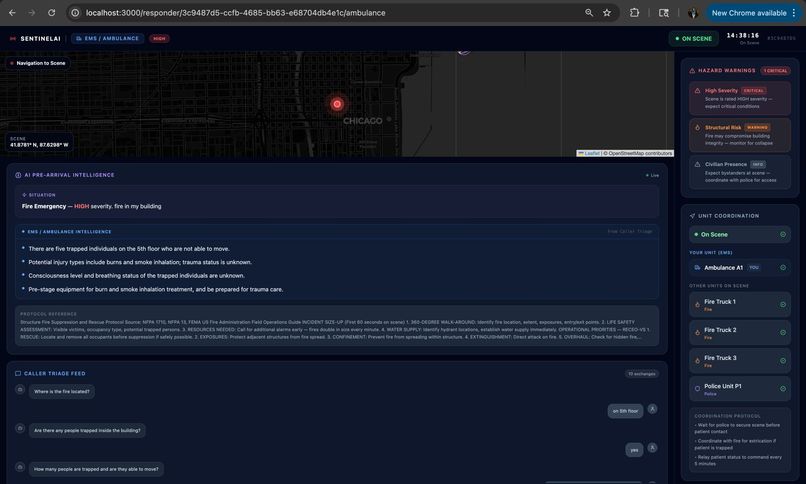
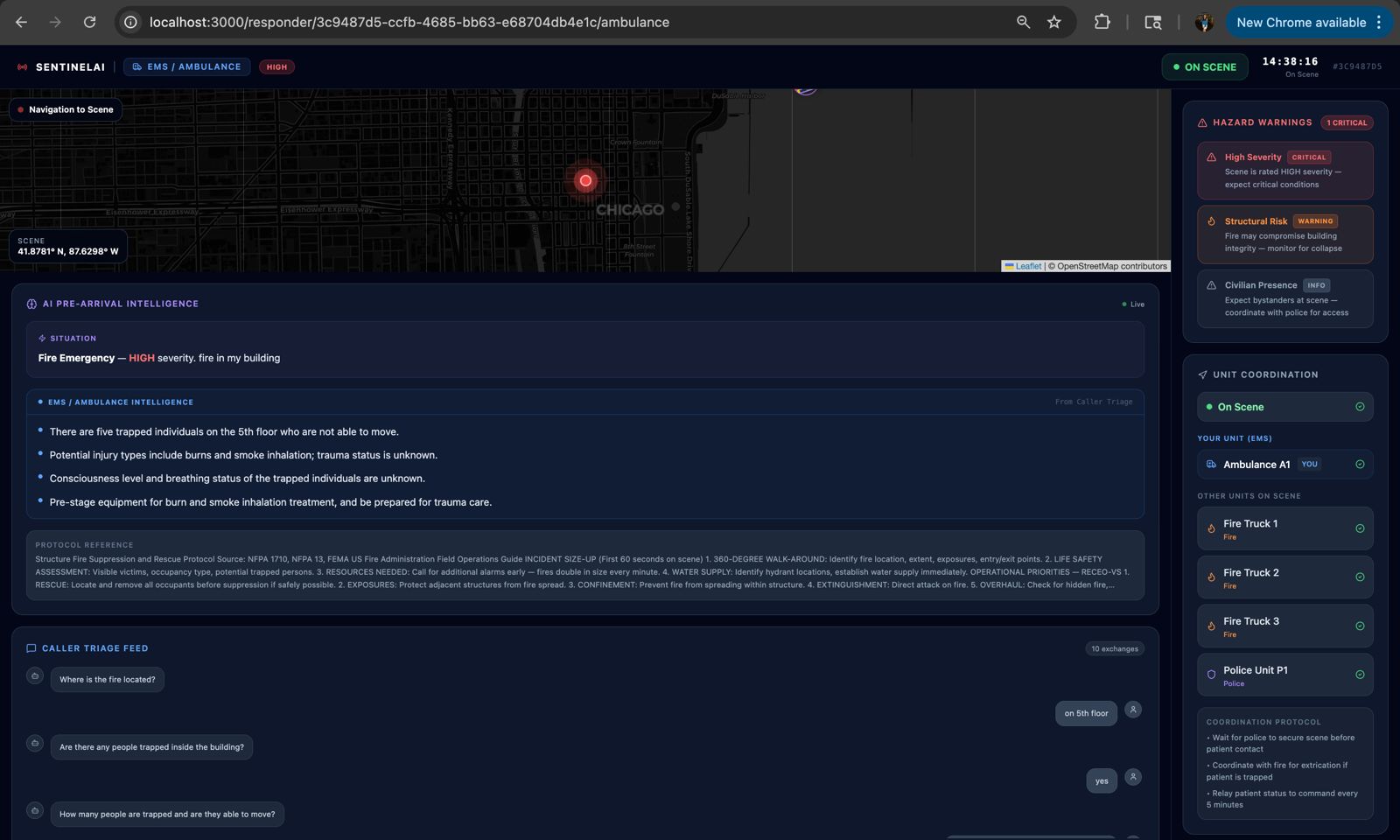
The UI that ambulance responders will see
-
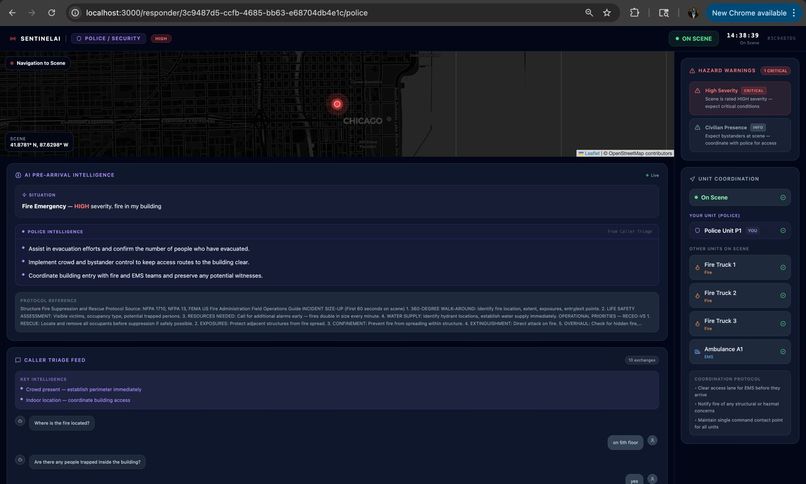
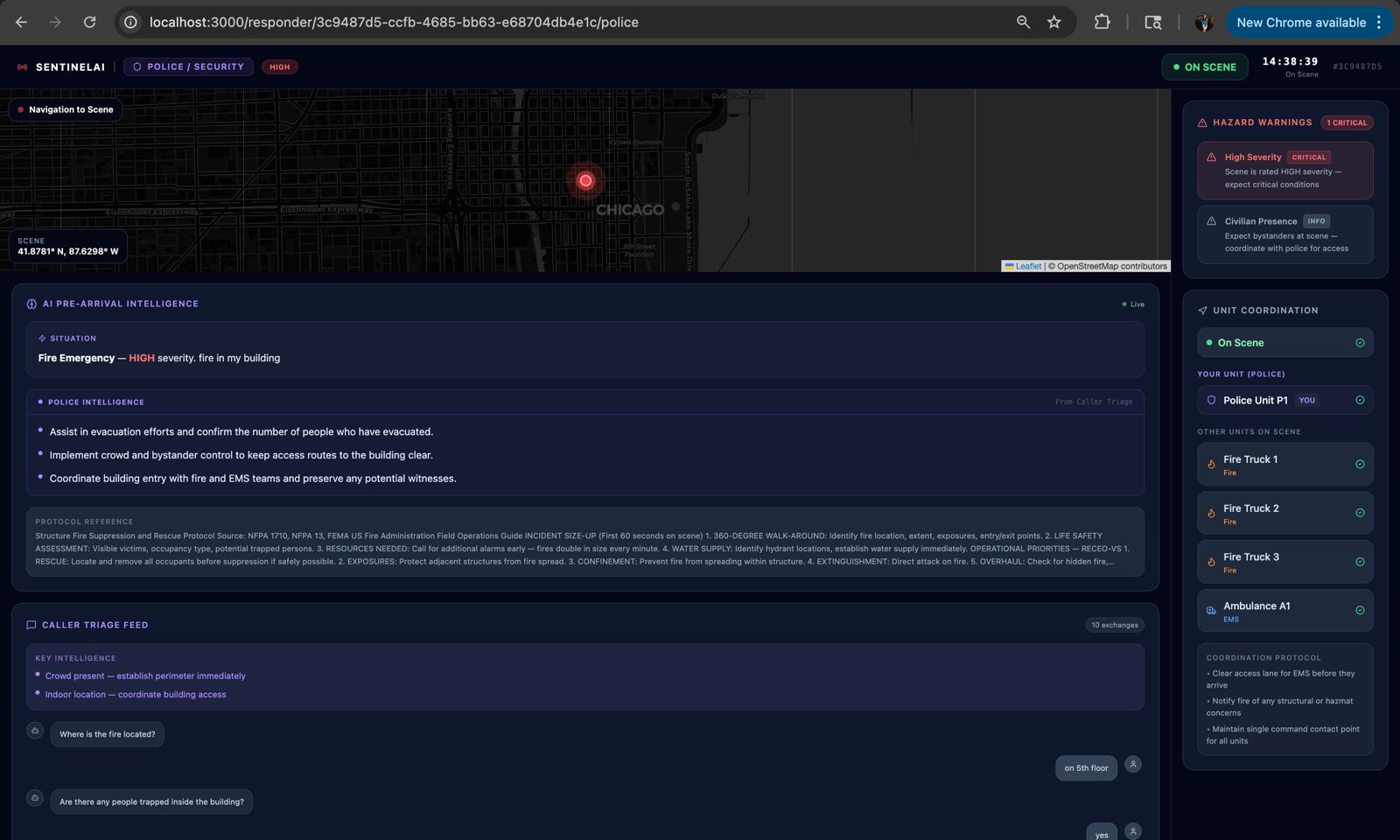
The UI that police responders will see
-
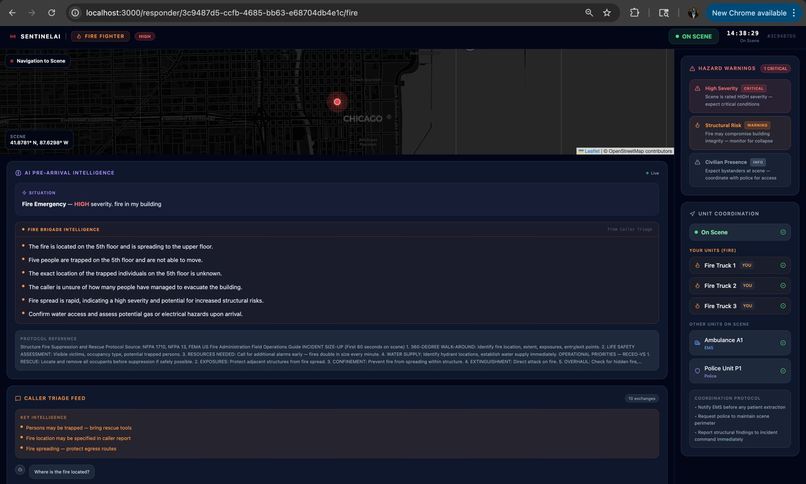
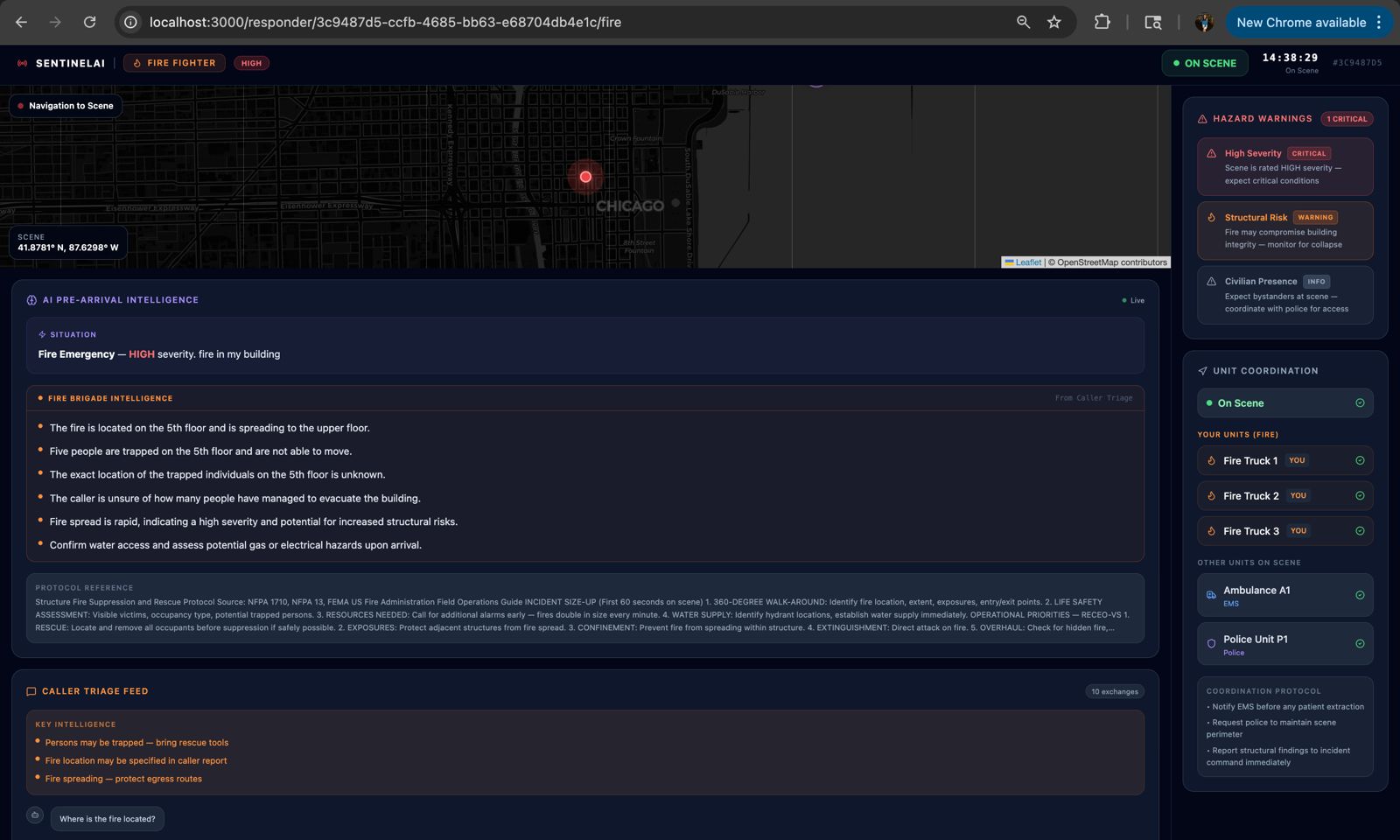
The UI that fire brigade responders will see
-
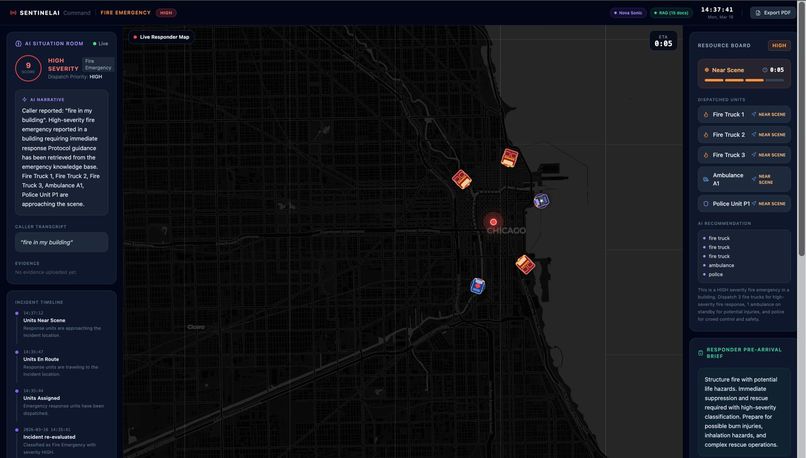
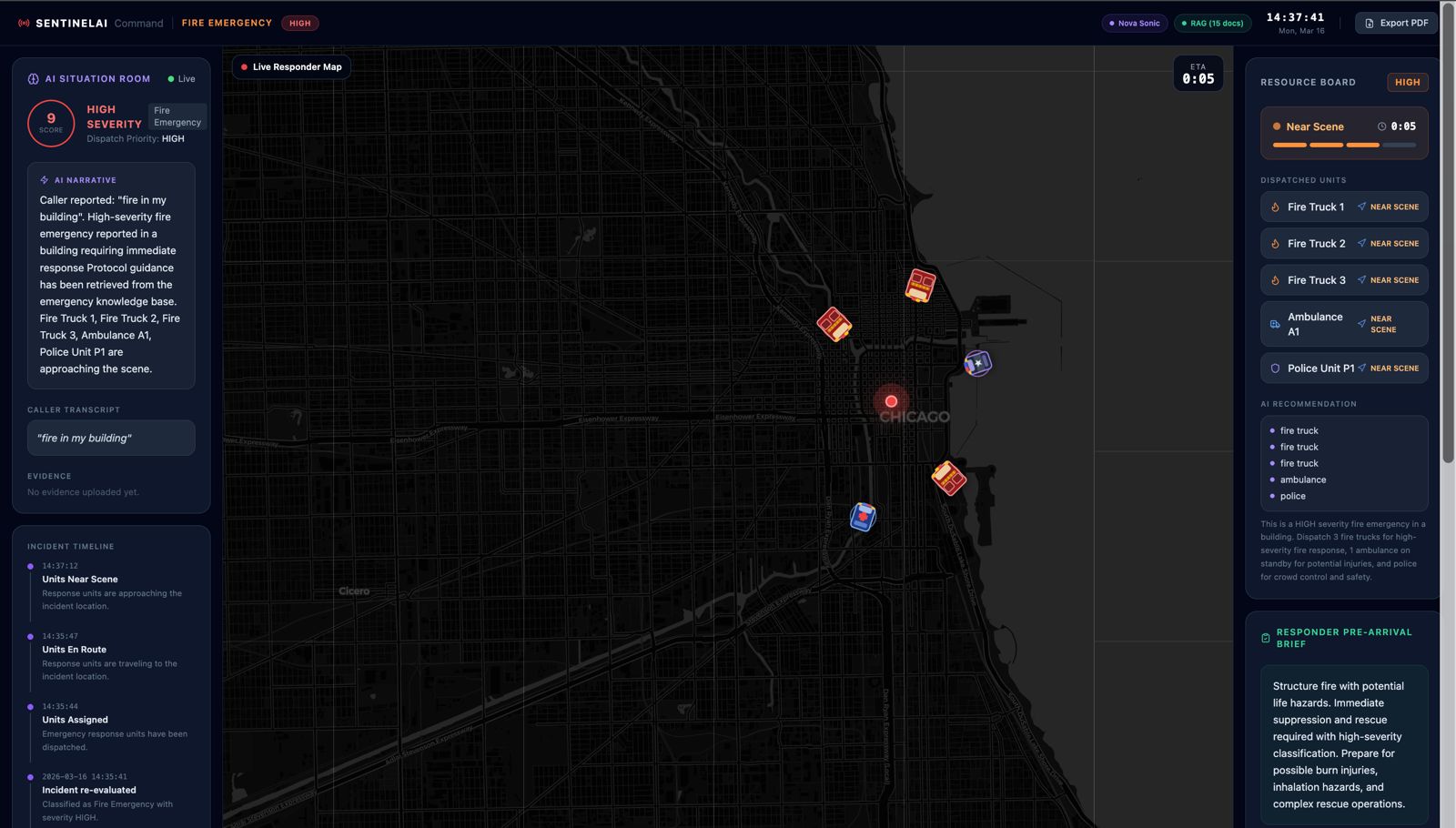
The command center which monitors everything
Inspiration
It started with a thought that wouldn't leave me alone. I noticed something that bothers me every time I hear about an emergency response: the responders arrive at the scene, and then they start figuring out what's happening. The fire truck pulls up and the crew looks around. The ambulance arrives and the paramedic runs in to assess. The police car stops and the officer steps out to understand the situation. All of that assessment time? That's seconds. And in emergencies, seconds are lives. The 911 operator knows everything, the caller described the fire on the third floor, there are two people trapped, one of them has asthma. But that information lives in the operator's head, scribbled on a notepad, maybe relayed over a radio in a rushed 10-second briefing. By the time the fire crew is actually climbing the stairs, they still don't fully know what they're walking into. I kept thinking: what if the responders already knew everything before they even stepped out of the vehicle? That's what inspired SentinelAI. Not a tool for the operator. Not a tool for the victim. A system that makes sure every single person responding to an emergency is fully briefed, in real time, before they arrive.
What it does
SentinelAI is a real-time AI emergency dispatch intelligence system that ensures every responder arriving at an incident is fully briefed before they step out of their vehicle. The moment a call comes in, a caller opens SentinelAI and describes the emergency by voice or text. From that point, the system takes over: Nova Sonic conducts a live voice triage conversation with the caller, asking targeted follow-up questions based on the incident type Nova Lite classifies the incident type, severity, probable cause and generates separate pre-arrival intelligence briefings for Fire Brigade, EMS, and Police Amazon Titan Embed retrieves the most relevant emergency response protocol from a 15-document knowledge base using semantic search The bystander receives spoken instructions on what to do right now while waiting for help Every responder dashboard updates live with role-specific intelligence, fire crews see trapped persons and entry points, EMS sees injury type and consciousness level, police see crowd control needs and access routes The system doesn't replace the dispatcher. It makes sure that everyone, the caller, the dispatcher, and all three response teams is operating from the same intelligence, at the same time, with no information lost in translation.
How we built it
SentinelAI is built across a FastAPI Python backend and a Next.js 14 frontend, with all AI running through Amazon Bedrock.
The AI pipeline works in three stages:
Stage 1 - Intake & Classification When a caller submits their emergency report, Nova Lite classifies it into incident type, severity, and probable cause. Simultaneously, Amazon Titan Embed Text v2 performs a cosine similarity search across 15 emergency protocol documents and attaches the most relevant protocol to the incident.
Stage 2 - Voice Triage (Nova Sonic) A bidirectional HTTP/2 stream is opened to Nova Sonic. Each audio chunk is signed using the STREAMING-AWS4-HMAC-SHA256-EVENTS scheme before transmission. Nova Sonic asks up to 4 adaptive questions derived from the incident type, and the caller responds by voice. The full conversation is transcribed and stored.
Stage 3 - Intelligence Generation Once triage is complete, Nova Lite processes the full conversation and generates four distinct briefings in a single structured prompt: Fire Brigade, EMS, Police, and Bystander. Each point is derived exclusively from what the caller said. The bystander instructions are immediately spoken aloud via the Web Speech API.
The responder dashboards are role-filtered, a fire responder sees fire-specific intelligence, an EMS responder sees casualty data. All pages poll the backend every 3 seconds and run a smooth local countdown synced to the server's authoritative ( \eta ) value, so the ETA displayed is identical across every open screen.
Challenges we ran into
The Nova Sonic Signing Problem This was the hardest technical problem in the entire project.
Every request to InvokeModelWithBidirectionalStream returned a validationException with no useful message regardless of what we sent. Empty body, correct body, different headers, the same 186-byte rejection every time.
After eliminating wrong frame structures, wrong content types, and wrong event field names, we read deep into the AWS SDK source code and found the root cause:
EVENT_STREAM_HASH = "STREAMING-AWS4-HMAC-SHA256-EVENTS"
This means the server requires every EventStream frame to carry its own cryptographic signature, not just the HTTP request. Each event must be signed using a chained HMAC where the signature of event $n$ depends on the signature of event $n-1$:
$$STS_n = \text{"AWS4-HMAC-SHA256-PAYLOAD"} \mid t_n \mid \text{scope} \mid \sigma_{n-1} \mid H(h_n) \mid H(f_n)$$
$$\sigma_n = \text{HMAC}(k_{sign},\ STS_n)$$
where $\sigma_0$ is the initial HTTP request signature, $h_n$ is the encoded date header bytes, and $f_n$ is the inner event frame. We had to implement the complete nested frame structure: an outer signed frame carrying an inner event frame, entirely from scratch in Python.
When the error finally changed from validationException to modelStreamErrorException, we knew the architecture was sound.
Designing for Panic
The caller-side UI is used by people in the middle of emergencies. Every design decision, button size, word choice, response time, spoken feedback had to account for someone who is frightened and not thinking clearly. Building for panic is a different discipline from building for normal users, and it shaped every frontend decision we made.
Accomplishments that we're proud of
Implemented Nova Sonic's full event-signing stack from scratch, no SDK wrapper, pure Python HTTP/2 with chained HMAC per event. This is something almost no public documentation explains end-to-end.
Role-differentiated AI briefings - a single Nova Lite call generates four distinct, caller-fact-derived intelligence packages. Every point is traceable back to something the caller actually said. No generic advice, no hallucinated details.
End-to-end voice pipeline - browser microphone → PCM encoding → Nova Sonic → base64 speech response → browser playback, all in real time, with graceful fallback to browser STT when Nova Sonic is unavailable.
Synchronized ETA across all UIs - the backend is the single source of truth for the countdown. Every frontend page resyncs to the server's ( \eta_{\text{seconds}} ) on every poll and runs a smooth local decrement between polls, so the timer is always identical regardless of when a page was opened.
RAG over 15 emergency protocols - Amazon Titan Embed Text v2 indexes protocols covering everything from cardiac arrest to HAZMAT to active threat response. The right protocol surfaces automatically for every incident.
What we learned
Nova Sonic requires a level of cryptographic implementation most developers have never needed. The STREAMING-AWS4-HMAC-SHA256-EVENTS signing scheme is not well-documented outside the SDK source code. Understanding it required reading SDK internals, implementing the math manually, and validating each component of the nested frame structure step by step.
AI is most useful when it reduces cognitive load at the worst possible moment. Responders arriving at an emergency are operating under stress. The value of SentinelAI isn't that it replaces their judgment - it's that they don't have to hold all the information in their head. It's already on the screen when they need it.
Structured prompting is an engineering discipline. Getting Nova Lite to generate four distinct, factually grounded, non-generic briefings from a single prompt required careful constraint design. The prompt explicitly instructs the model to derive each point from the caller's actual words and to omit any detail not mentioned. The quality of the output is a direct function of the quality of those constraints.
Real-time systems are unforgiving about state. The ETA sync bug - where different UIs showed different countdown values - came from independent local state. Resolving it required understanding the difference between UI state, server state, and the relationship between a 3-second poll and a 1-second local interval.
What's next for SentinelAI
Live audio routing through Nova Sonic - the full voice pipeline is implemented. The next step is streaming real caller audio directly through Nova Sonic for a genuinely conversational triage experience, replacing the current sequential STT approach.
Hospital pre-notification - when EMS is en route, SentinelAI should automatically generate and transmit a pre-arrival patient summary to the receiving hospital, so the trauma team is ready before the ambulance arrives.
Multi-incident command view - the dispatcher dashboard currently manages one incident at a time. A real command center needs to manage multiple concurrent incidents, prioritised by severity score ( s \in [0, 10] ) and resource availability.
Offline-capable responder app - responders in low-connectivity areas need their briefing cached on device. A Progressive Web App build with service workers would ensure the intelligence is always accessible even when the network drops en route.
Post-incident analytics — every triage conversation, response time, and outcome is data. Building a feedback loop where actual incident outcomes improve the triage model over time would make SentinelAI measurably better with every emergency it handles.
Built With
- amazon-iam
- amazon-nova-lite
- amazon-nova-sonic
- amazon-titan
- asyncio
- base64
- bedrock
- cosine-similarlity
- eventstream
- fastapi
- hmac-sha256
- http/2
- httpx
- lucide
- lucide-icons-backend-fastapi
- next.js
- pcm-audio
- pydantic
- python
- python-3.12
- rag
- sigv4
- tailwind
- tailwind-css
- typescript
- uvicorn


Log in or sign up for Devpost to join the conversation.