-
-
Incident Detection of Hallucination and Errors Agents Make
Inspiration
We're two students who love building on the technical side of AI. Like most people who've been playing with this stuff over the past year, we've spent a lot of time building agents — small ones, local ones, ones that run on our own machines. It's genuinely fun. You can spin up a customer support bot or a research assistant or a coding helper in an afternoon.
But the more we built, the more we noticed something weird: none of the agents we built ever felt good enough to actually ship.
There was always something. A weird hallucination. A constraint the agent ignored. A response that sounded confident but was wrong. We'd patch one thing, and another would break. And we realized we weren't alone in this. We started reading and found a stat that stuck with us:
88% of AI agents never reach production.
Companies build them. Demo them. Get excited about them. And then quietly shelve them because nobody trusts them not to embarrass the business in front of a real customer. The fear is the same fear we had with our own little agents — they fail in unpredictable ways, and there's no good system for catching, understanding, or preventing those failures.
Meanwhile, the industry is moving fast toward smaller, local models — Qwen, Gemma, Llama — because cloud API costs at scale are unsustainable. But local models fail more often than the big hosted ones. So the very shift that makes agents economically viable also makes the trust problem worse.
We wanted to solve this. Not the whole problem — that's bigger than two students at a hackathon. But a real piece of it. The piece that says: if your agent fails, the failure shouldn't be wasted.
Local AI agents fail constantly: with restricted environments, they ignore constraints, hallucinate content, and produce broken output. But today's observability tools stop at detection. Current tools show you what broke and leave the rest to you, the developer, to fix. We dreamed of building the layer that automates all of it, a system that not only catches failures but automatically learns from them, generates regression tests, and patches the agent's own architecture. Sentinel is that layer.
Why Local Agents Specifically
We chose to focus on local LLM agents because that's where the real production gap is. Cloud-hosted models are reliable but expensive. Local models are cheap and fast but more failure-prone. Companies want the cost benefits of going local, but they need a way to harden these agents before deployment. Sentinel is built for that exact moment — when a team is moving an agent from "works on my machine" to "we trust this with real users."
The agent runs entirely locally. The only thing that touches the cloud is Sentinel's reasoning brain (we use Gemini Flash) — and only when failures happen, not on every user request. Once an agent is mature, the cloud assistance becomes rare. Sentinel is training wheels for production agents, not a permanent dependency.
What it does
Sentinel is a tool you drop in alongside any local AI agent. It watches everything the agent does, catches failures the moment they happen, and automatically closes the loop between failure and fix so it doesn't happen again.
It works in four phases, in a closed loop:
Phase 1: Detection
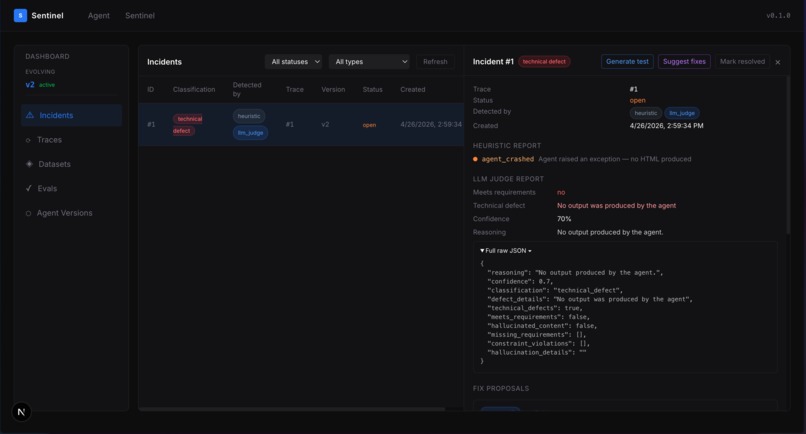
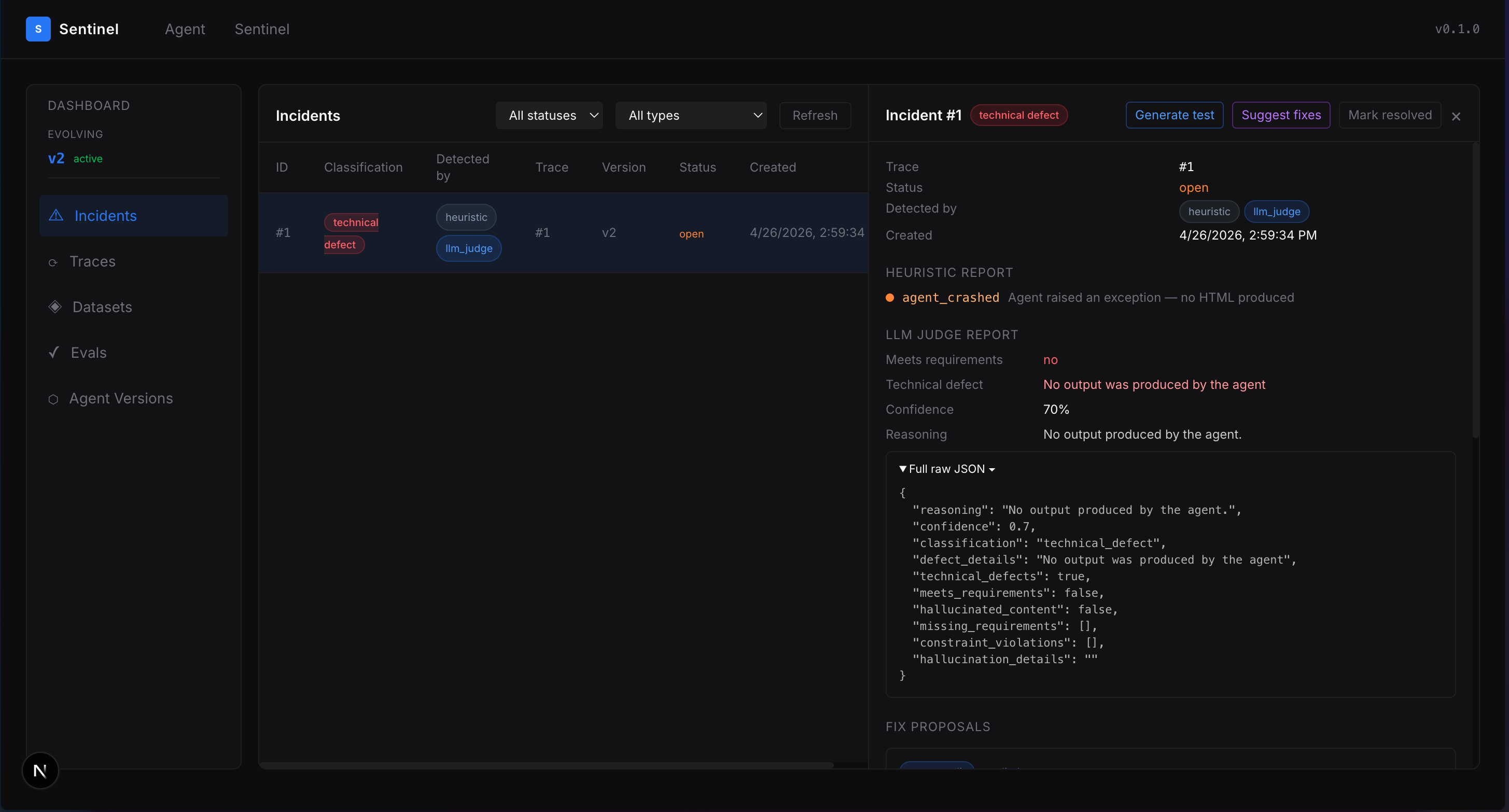
When an agent run fails on any customer use, Sentinel detects it using a combination of deterministic heuristics (forbidden tags, malformed HTML, output too short) and an LLM judge that reads the agent's own graph and prompts to understand what correct behavior looks like. Every run produces an incident, whether it passes or fails.
Phase 2: Generation
From that incident, Sentinel generates a family of test cases: variants of the failure pattern that probe the same issue from different angles to ensure this type of failure cannot happen again. These accumulate into a permanent regression dataset in LangSmith.
Phase 3: Correction
Then Sentinel proposes concrete fixes. It doesn't just prompt engineer around an agent; it generates real Python validation code, self-tests it against the original failure before proposing it, and produces structured diffs describing exactly what changes in the agent's graph. A guardrail node gets inserted between the generator and the output. A retry loop gets added that feeds specific error feedback back to the agent. These are architectural changes, not prompt suggestions.
Phase 4: Evaluation
Finally, Sentinel runs an eval gate: it sends every accumulated test case through the new agent version, scores each result using the same heuristics and judge from detection, and either promotes the new version or reverts to the parent if the pass rate drops below 80%.
The full loop: detect → test → fix → eval → promote.
How we built it
The production agent we model it on is a two-node LangGraph pipeline (spec parser → HTML generator) running a locally hosted model, instrumented with LangSmith for full trace capture.
The backend of Sentinel is FastAPI with PostgreSQL (via SQLAlchemy + asyncpg) and Redis. Detection runs as a fire-and-forget background task on every trace. Heuristics check for constraint violations deterministically, then an LLM judge evaluates the output against the agent's own graph and prompts for hallucination and requirement misses.
The fix suggestion engine is a pluggable strategy registry. Four strategies ship: PromptEditStrategy rewrites system prompts, CodeGuardrailStrategy generates real Python validators using BeautifulSoup and self-tests them before proposing, RetryWithValidationStrategy builds a validator plus a conditional retry loop, and ToolModificationStrategy proposes wrapper code around failing tool calls. Each strategy produces a structured FixDiff that Phase 7 can mechanically apply.
The correction phase applies diffs by deserializing the FixDiff, deep-copying the active agent's graph_json and prompts_json, mutating them (inserting nodes, rerouting edges, rewriting prompts), and saving a new Agent row with parent_version_id pointing at the old version. Immutable version history, full rollback capability.
The evaluation and regression testing re-runs the accumulated test suite against the new version, scores using the same detection stack, and either keeps the new version active or reactivates the parent.
The frontend is Next.js with three views: a developer portal, a consumer-facing agent interface, and a cinematic observability dashboard that walks through the four pipeline stages with real data.
Challenges we ran into
- Detecting hallucinations without false positives. Heuristics are great for constraint violations but can't catch hallucinated content. We needed the LLM judge to be agent-agnostic. It reads the agent's own
graph_jsonandprompts_jsonat runtime to derive evaluation criteria on the fly, rather than having anything hardcoded about HTML generation. Getting that context window right without overwhelming the judge took a lot of iteration. - Bridging two data models at merge time. The correction and evaluation were built with UUID primary keys, and the detection used integer PKs. Merging meant writing a UUID to int bridge layer in every database query. Not glamorous but genuinely painful.
- Self-testing generated code.
CodeGuardrailStrategygenerates Python validation functions using an LLM, then immediately execs and tests them against the original failing output before proposing. If the generated code doesn't catch the failure, the strategy fails gracefully and the engine moves to the next strategy. Getting that self-verification loop reliable — especially with LLM-generated code that sometimes uses wrong imports or wrong function signatures — took real work. - Representing agent architecture simply. The agent graph lives as JSON in the database. Making that JSON human-readable in the UI, and showing the diff between versions in a way that's visually meaningful rather than a raw JSON dump, required careful thought about what abstraction level to present.
Accomplishments that we're proud of
- The self-testing validator pipeline. When Sentinel generates a Python validator, it doesn't just trust the LLM — it runs the code, checks that it catches the original failure, verifies it produces actionable feedback, and only then proposes it. That's a small closed loop inside a larger closed loop, and it genuinely works.
- The full pipeline running end to end. An agent produces bad HTML, Sentinel detects the violation, generates 8 regression tests, proposes a guardrail node with real validator code, applies it to create a new agent version, runs the eval suite, and promotes. The agent is architecturally different after the loop than before. That's the demo and it actually works.
- Immutable version history. Every fix application forks a new agent version with a parent pointer. You can roll back to any previous version at any time. This is the kind of infrastructure that production AI systems need and almost nobody has.
What we learned
- LLM-generated code is more reliable than LLM-generated instructions. A prompt that says "never generate img tags" is a suggestion. A Python function that strips img tags and returns a validation error is a guarantee. The most impactful part of Sentinel isn't the detection or the eval — it's the moment where it stops trying to convince the LLM to behave and just writes code to enforce it.
- Observability for AI agents is fundamentally different from observability for traditional software. You can't just log inputs and outputs and call it done. You need to understand the agent's intent (what was it supposed to do?), the agent's architecture (which nodes ran?), and the semantic gap between them. That's why the judge reads the agent's own prompts — without that context, it can't tell the difference between a hallucination and a legitimate creative choice.
What's next for Sentinel
- Making it truly plug-and-play. Right now the agent needs to store its graph as JSON in our database. The next step is a lightweight SDK that instruments any LangGraph or LangChain agent with one decorator, automatically captures the graph structure, and starts feeding Sentinel without any schema changes.
- Expanding the fix strategy library. The four strategies we ship are the beginning. Fine-tuning-based fixes, retrieval-augmented examples, multi-step reasoning chains — any of these could be a strategy that plugs into the same registry.
- Cross-agent pattern matching. When multiple agents fail with similar patterns, Sentinel should recognize that and generate fixes that address the root cause across all of them, not just the individual instance.
Built With
- alembic
- asyncpg
- beautifulsoup4
- css
- docker
- fastapi
- gpt-4o-mini
- langchain
- langgraph
- langsmith
- next.js
- openai
- postgresql
- python
- react
- redis
- redis-to-go
- sqlalchemy
- tailwind
- typescript

Log in or sign up for Devpost to join the conversation.