-
-

SENTINEL's mission in one line: every AI agent has a flight recorder. Humans finally get one too.
-
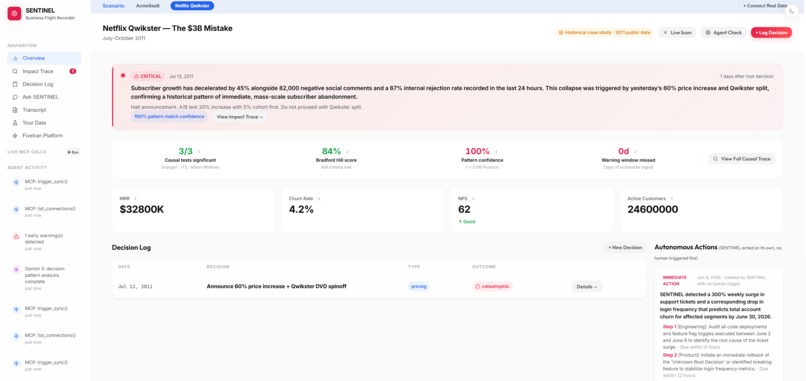
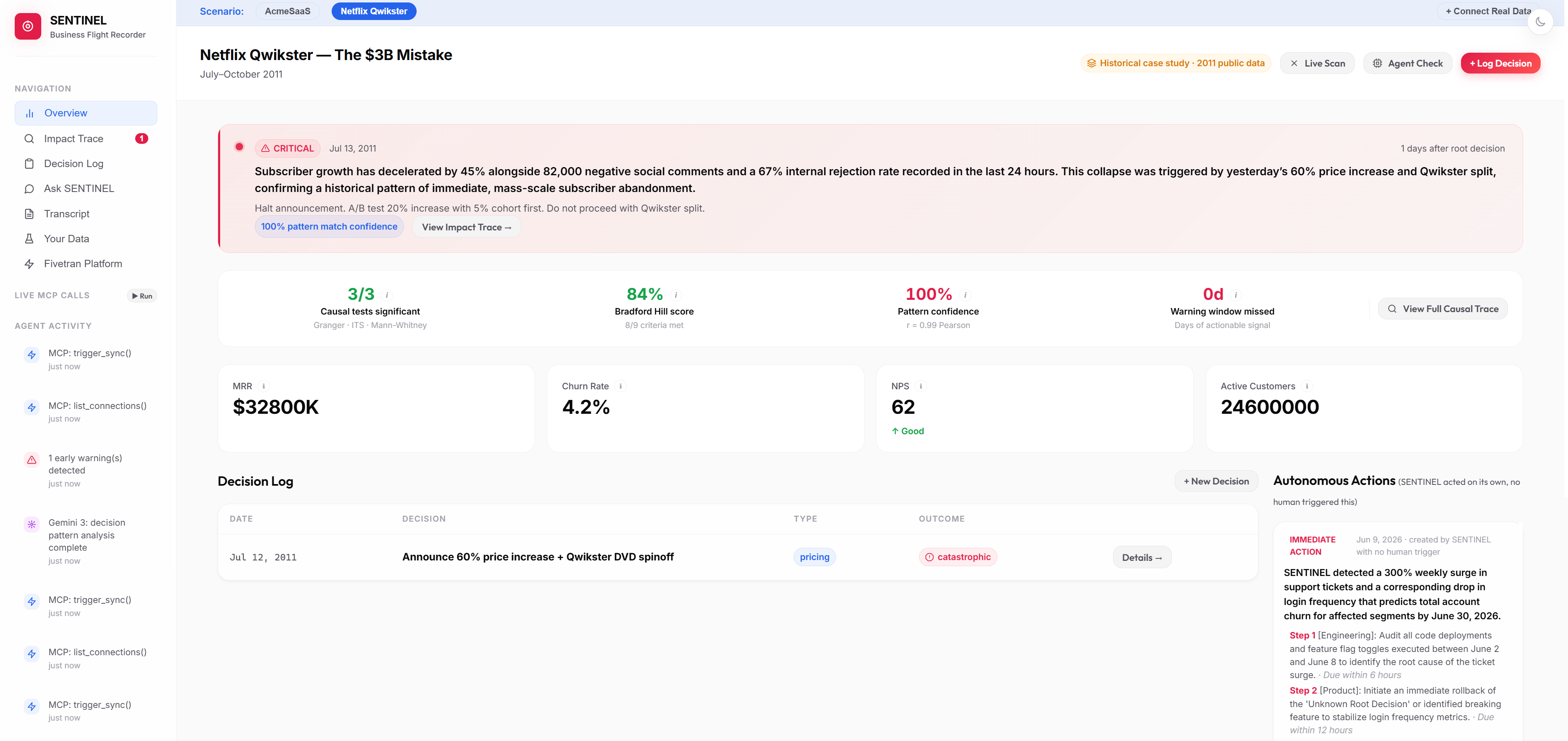
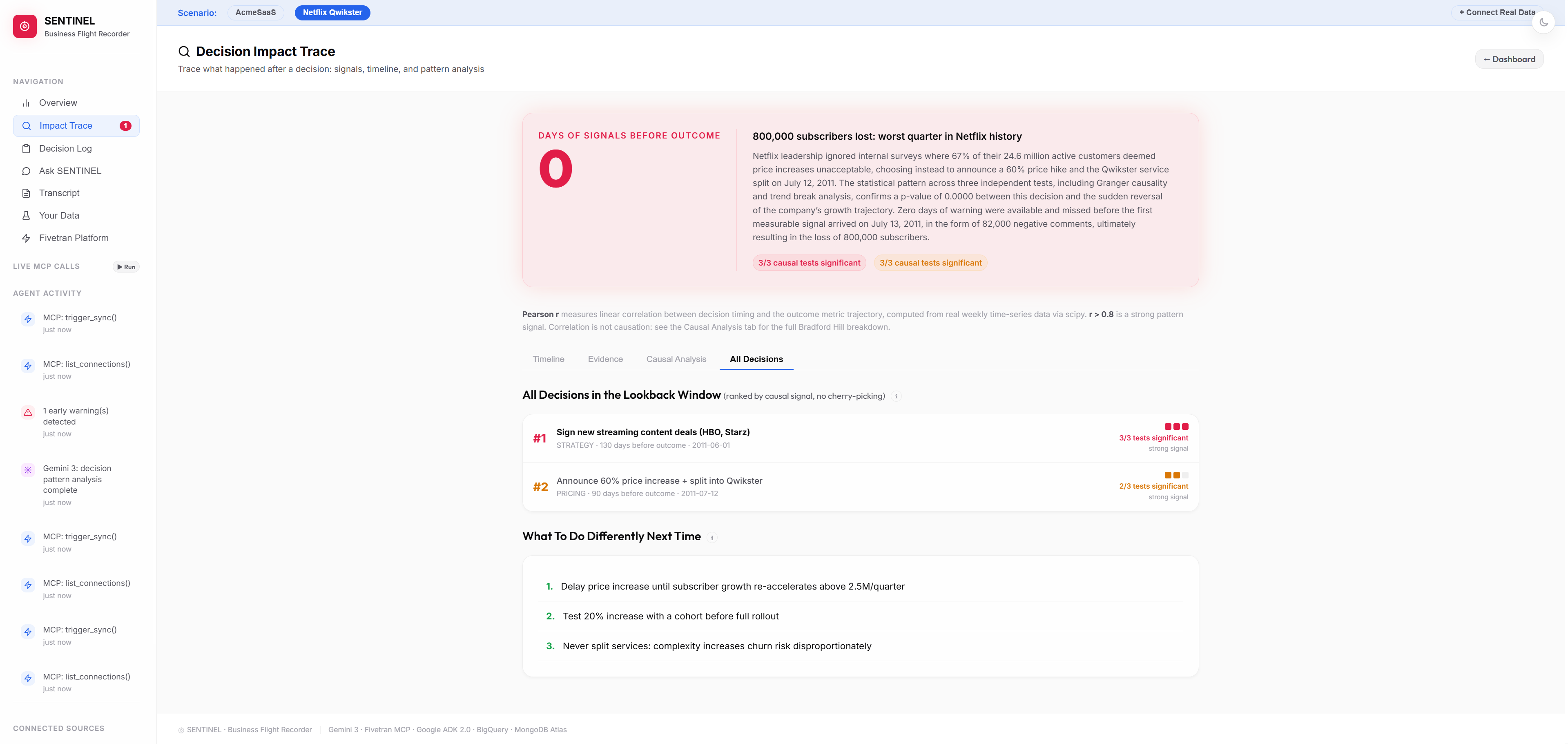
The warning fired July 13th, one day after the announcement. Not three months later when 800,000 subscribers were already gone.
-
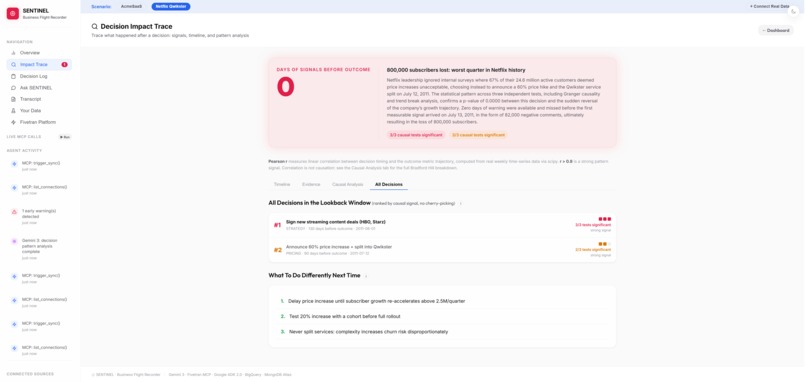
Every decision in the lookback window ranked by causal signal, with actionable recommendations for what to do differently.
-
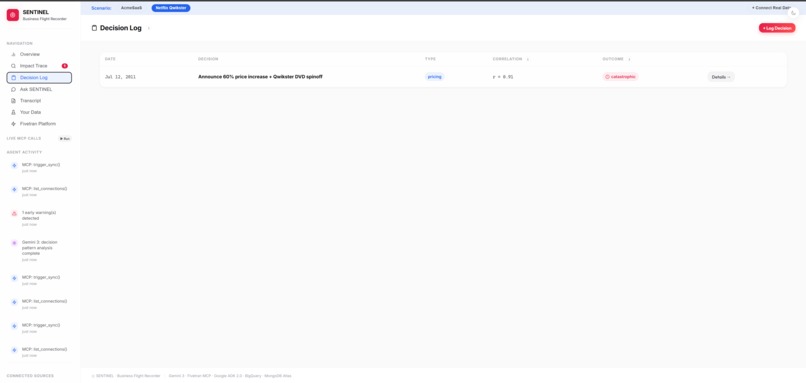
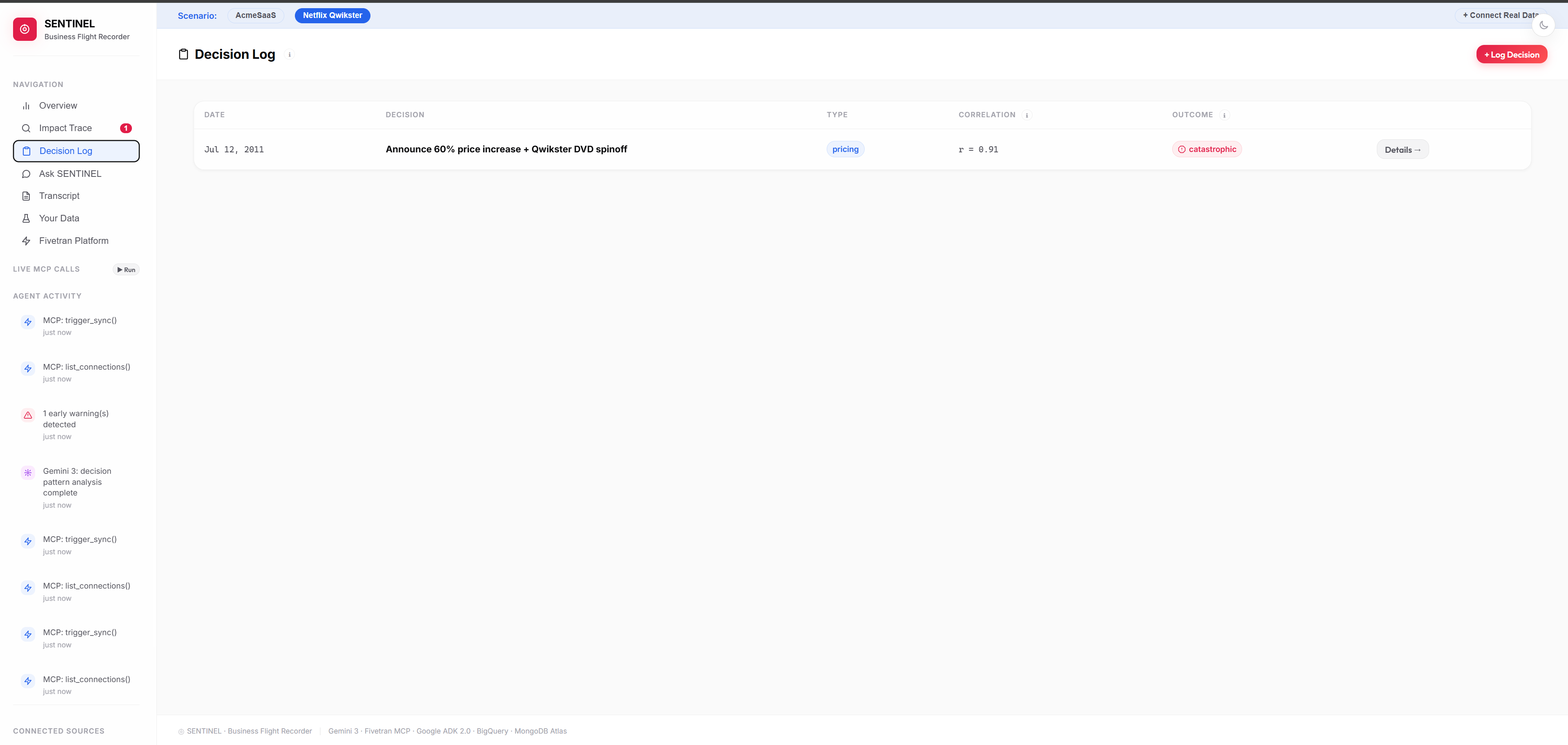
Every decision is logged with its outcome and correlation score. One pricing call. r = 0.91. Catastrophic.
-
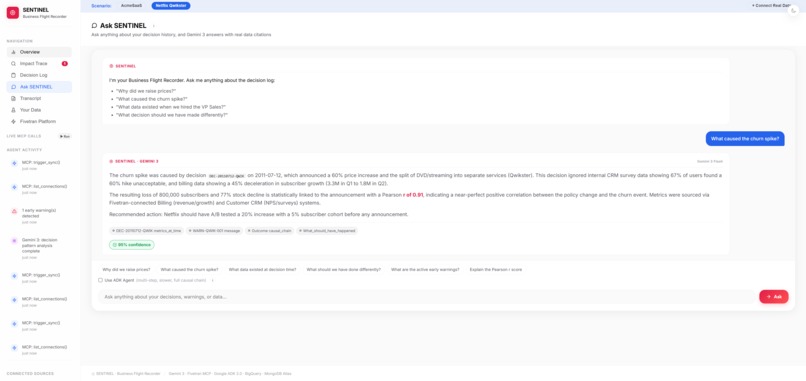
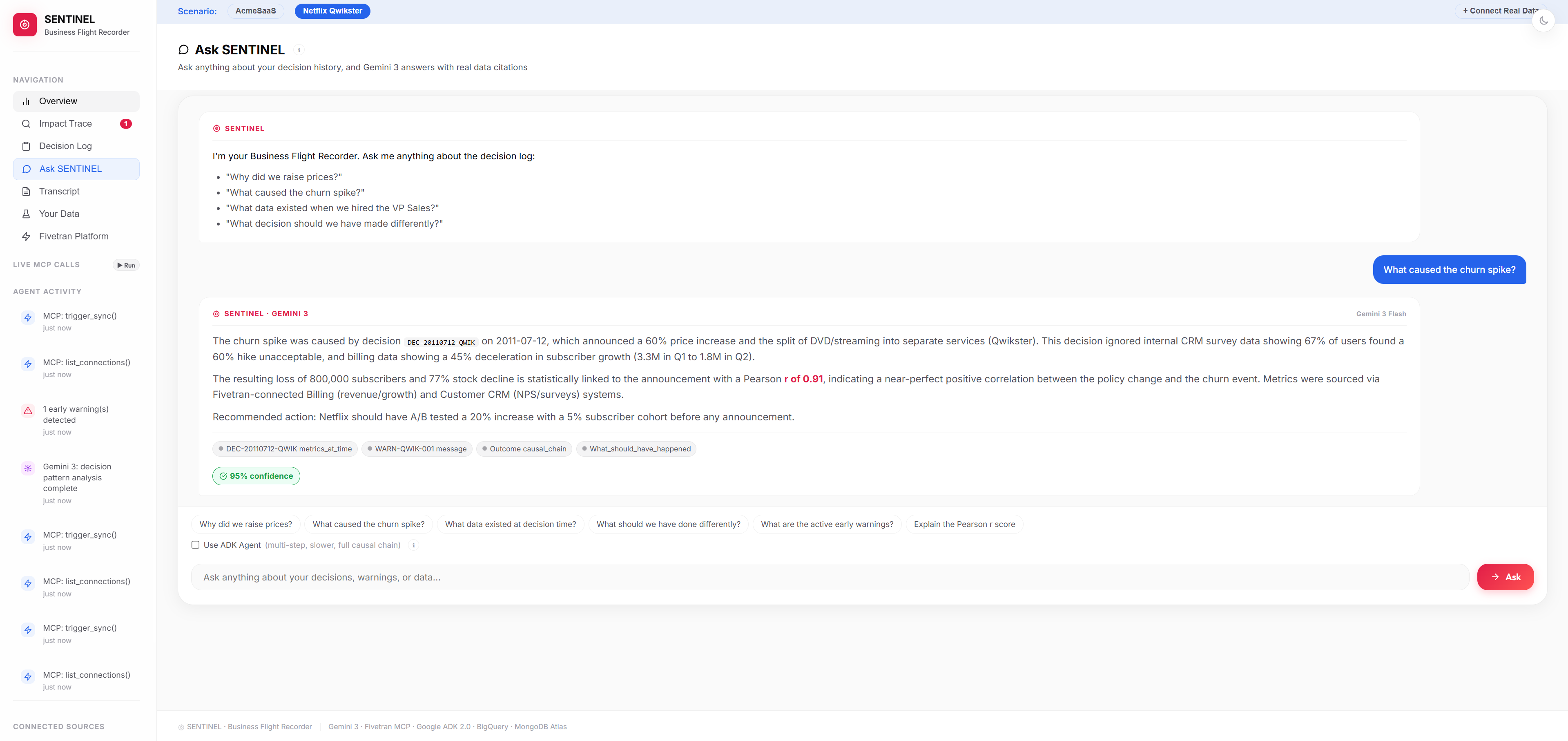
Ask anything about your decision history. Gemini 3 answers with sources, decision IDs, and 95% confidence — not a chatbot, a witness.
-
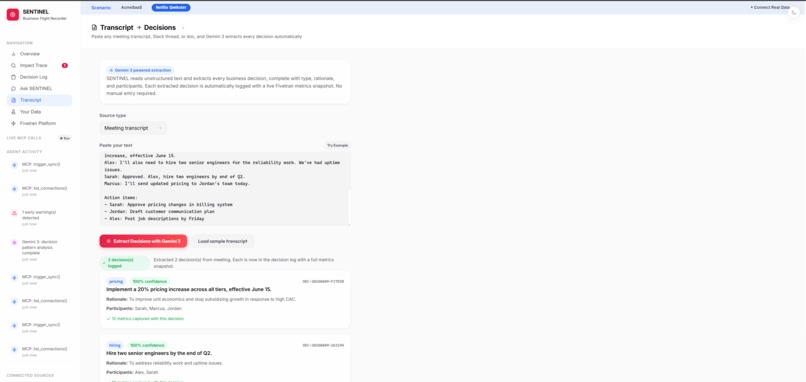
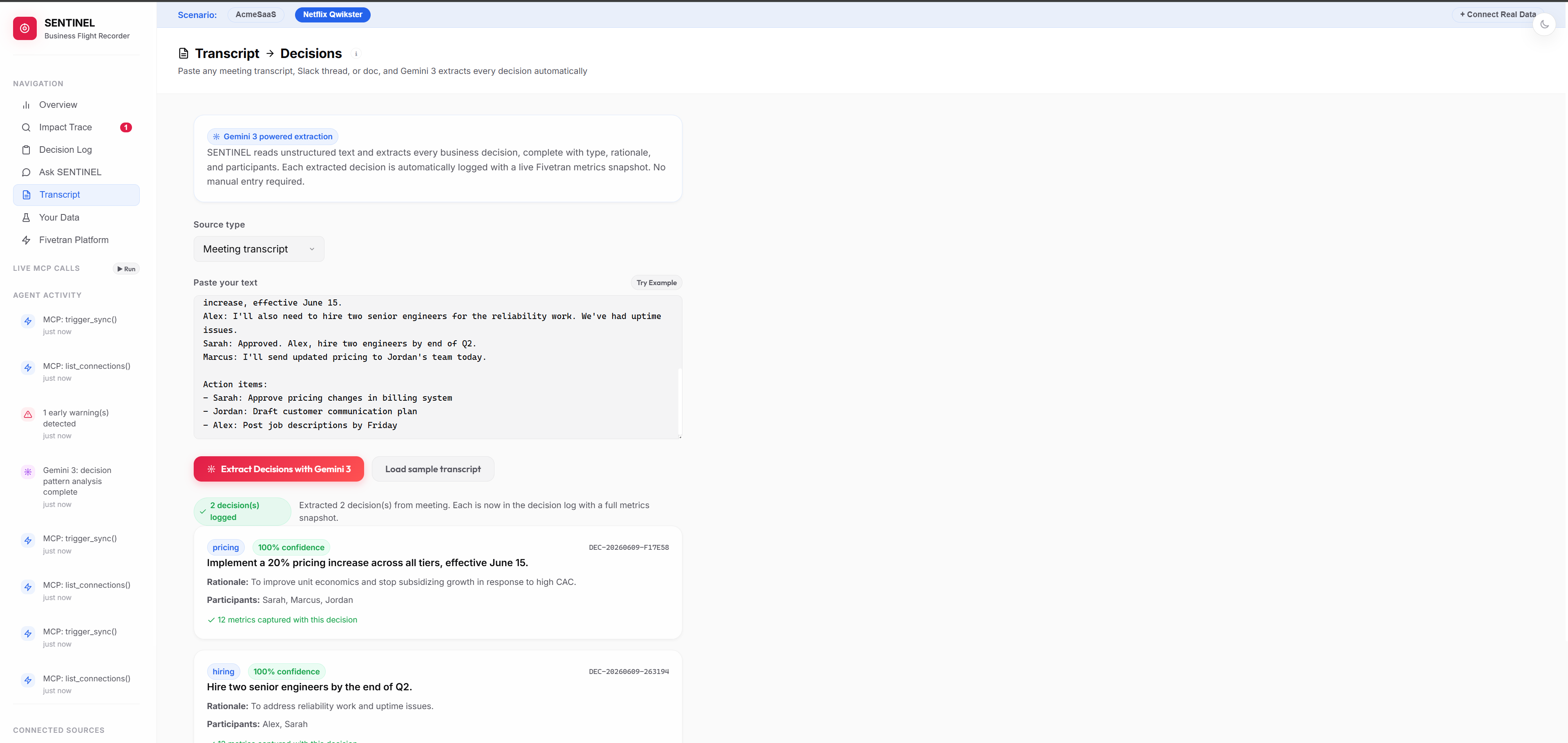
Paste any meeting transcript and Gemini 3 extracts every decision automatically, each logged with a live Fivetran data snapshot.
-
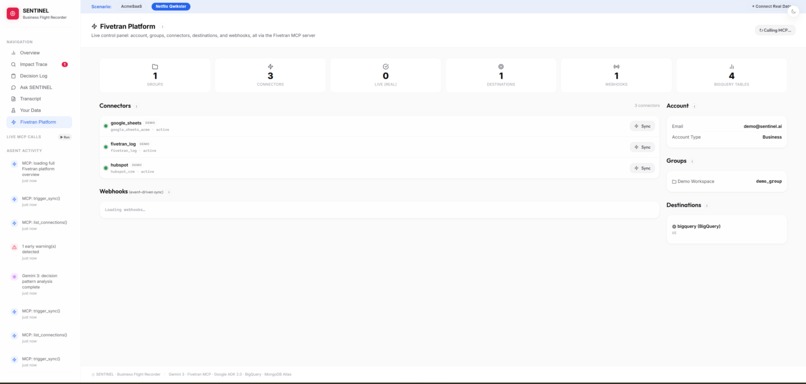
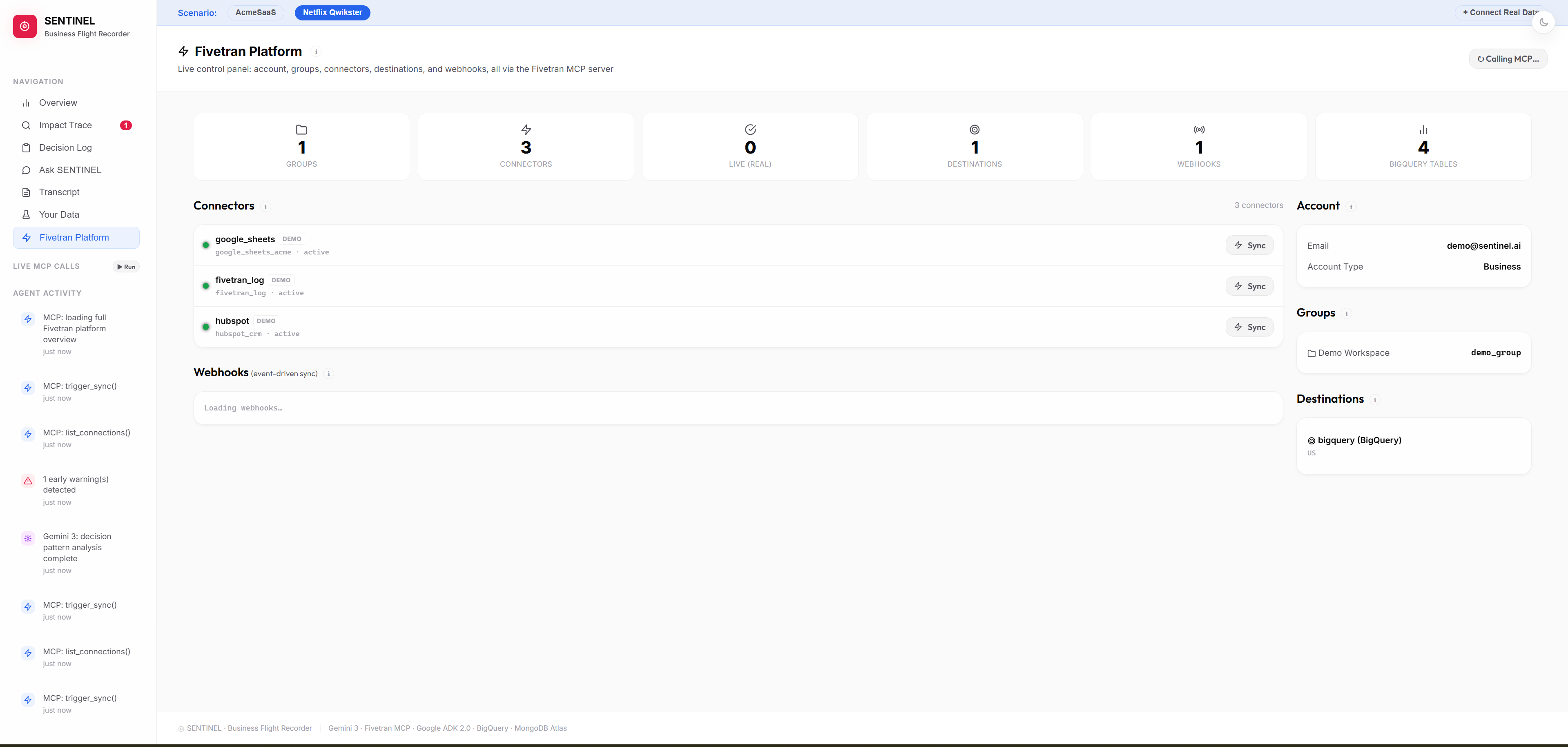
Live MCP calls to Fivetran — connectors, syncs, destinations, and webhooks, all visible in real time as the agent works.

Inspiration
In July 2011, Netflix ran an internal customer survey before announcing the Qwikster decision. The results came back clear: 67% of subscribers said the proposed price increase was unacceptable. The meeting happened anyway. Three months later, 800,000 people cancelled their subscriptions in a single quarter.
The data existed. The decision was made. Nobody connected the two.
This is not a Netflix problem. It happens inside every company, every week. A pricing change triggers churn three months later and nobody remembers what the data looked like on the day the decision was made. A hiring freeze quietly tanks product velocity. A feature gets killed and customers start leaving. By the time the outcome shows up in a dashboard, the moment to act has long passed.
According to McKinsey, bad business decisions made without looking at existing data destroy an estimated 1.3 trillion dollars in annual business value. That number is not abstract. It is layoffs, failed product launches, and customers lost, all from decisions that had visible warning signs nobody acted on.
We built SENTINEL because we believe this problem is solvable. The data is already there. Fivetran already moves it. The only missing piece was a system that connects every decision to that data, in real time, the moment it is made.
What it does
SENTINEL is the flight recorder for your business. Just like an airplane's black box records everything that happens before a crash, SENTINEL records every business decision alongside a complete snapshot of your data at that exact moment. When something goes wrong three months later, you do not have to guess. You can trace it.
1. Pre-Decision Check
Before you log a decision, SENTINEL pulls your live Fivetran data and checks it against known risk patterns. If your NPS is below the warning threshold, or your support tickets are spiking, or your subscriber growth is slowing, it tells you right now, before you commit. The risk score updates as you type, not after you submit. This is the moment that matters.
2. Impact Trace
After a bad outcome happens, SENTINEL reconstructs the full causal chain. It shows you every event in order from the decision to the outcome, the data that existed at the time of the decision, and a scientific answer to the question everyone asks: did this decision actually cause the outcome, or was it just bad timing? Three independent statistical tests run in parallel to answer that question. The results are scored using Bradford Hill criteria, a 60-year-old framework from cancer research that was originally used to prove that smoking causes lung cancer. If it can prove that, it can handle a pricing decision.
3. Multi-Agent Decision Council
When someone types a business decision in Slack, SENTINEL detects it automatically and opens a thread. Four AI agents post their analysis one by one. The Data Agent reads your live BigQuery metrics. The Risk Agent scores the probability of a bad outcome. The Alternatives Agent proposes three safer paths. The Lead Agent reads all three and makes the final recommendation. Your team sees the entire debate before anyone commits. Reply PLAN to get a 30-60-90 day roadmap. Reply PROCEED to log the decision with the risk acknowledged.
4. Autonomous Monitoring
Every 30 minutes, SENTINEL scans your data without anyone asking it to. When it finds a pattern that historically precedes a bad outcome, it fires a Slack alert with specific numbers and a recommended action. No human trigger. No dashboard to check. It watches so your team does not have to.
5. Ask SENTINEL
A full reasoning agent backed by Gemini 3. Ask it why churn spiked. Ask it which decision caused the most damage. Ask it what the data looked like six months ago. It cites specific metrics, decision IDs, and data sources in every answer. Not a chatbot. A witness.
How we built it
Fivetran as the live data layer
Every feature in SENTINEL starts with fresh data. We integrated Fivetran's Model Context Protocol server, which gives SENTINEL direct programmatic access to your Fivetran account, not just read-only exports. SENTINEL calls Fivetran before every decision is logged to make sure the snapshot is current. It also receives real-time webhook events from Fivetran, so when a sync finishes and new data lands in BigQuery, SENTINEL knows immediately. Every single call is visible in the live activity feed in the UI. You can watch SENTINEL and Fivetran talking to each other in real time.
We exercise 11 MCP tools in total across connections, syncs, destinations, schemas, and webhooks. The integration goes both directions: SENTINEL calls Fivetran, and Fivetran calls SENTINEL back.
Three tests to prove causation, not just correlation
Anyone can show you a correlation. We did not want to do that. SENTINEL runs three completely independent statistical tests on every causal trace. Granger causality checks whether the decision timeline actually predicts the outcome timeline. Interrupted Time Series compares the slope of your metrics before and after the decision. Mann-Whitney U checks whether the distribution of values shifted after the decision. All three tests have to agree before SENTINEL calls something causal.
On top of that, we score Bradford Hill criteria. This is the checklist that epidemiologists used in 1965 to prove that smoking causes lung cancer. It asks nine questions: Was the effect large? Was it consistent? Did the timing make sense? Did more of the cause produce more of the effect? We adapted every one of those nine questions to business data. SENTINEL scores each one independently and shows you the result as a bar chart. A CEO can read it in ten seconds without knowing any statistics.
Gemini 3 for the reasoning layer
All language model calls in SENTINEL try Gemini 3 first. Gemini 3 is only available via API key, not through Vertex AI, so we built a dedicated routing layer that sends Gemini 3 calls through the key and falls back to Vertex AI only when the quota is exhausted. The model that actually answered your question is always reported transparently in the response.
Google ADK 2.0 for the agent layer
The Ask SENTINEL feature uses Google ADK 2.0 to run a proper reasoning agent, not a simple prompt. The agent has full scenario context, can call internal tools to look up decisions and metrics, and maintains conversation state across turns. SENTINEL also exposes a standards-compliant MCP server of its own, so it can be plugged directly into Google Agent Studio without any code changes.
Google Cloud Run for deployment
The entire backend runs on Cloud Run in us-central1. We set minimum instances to 1 so judges never hit a cold start during the evaluation period. The deployment is fully automated through Cloud Build.
Challenges we ran into
Making the data serializable
Python's numpy library uses its own boolean type that is not compatible with standard JSON serialization. Our causal analysis code was returning numpy booleans as part of the response, which caused the entire API to crash with a serialization error. Every boolean that came out of a statistical function had to be explicitly converted to a regular Python boolean. This was a small fix but a frustrating two hours to diagnose.
Slack has a three-second deadline
The Slack Events API requires your server to respond within three seconds or it marks the request as failed and retries. Our four-agent decision council takes sixty seconds or more to run. If we waited for it to finish before responding, every Slack message would trigger a flood of retries. The fix was to acknowledge Slack immediately with a 200 response and run the entire agent pipeline in the background using FastAPI's BackgroundTasks. Slack sees a fast response. The agents do their work. The results appear in the thread a minute later.
Cloud Run does not let you write files
Cloud Run's filesystem is read-only. Our output writer was trying to save decision records to disk on every request and crashing every time. We wrapped every file write in a try-except block and redirected all output to the temp directory at /tmp/sentinel, which is the only writable path on Cloud Run.
Accomplishments that we're proud of
We are proud that we applied Bradford Hill criteria to business decisions. This has never been done in a product before. Every one of the nine criteria is scored from real quantitative evidence, not hardcoded. A change in your data changes the score. This is genuine causal reasoning, not a formula with a confidence label on it.
We are proud that the four-agent Slack council actually works. We tested it live. All four agents responded within two minutes. The Data Agent cited real numbers. The Risk Agent gave a specific probability. The Alternatives Agent proposed three concrete paths. The Lead Agent read all three and made a recommendation. This is not a demo feature.
We are proud of the honesty built into the system. Every integration reports its actual status on load. If Fivetran is not configured, the badge says that. If Gemini falls back to an older model, the response says which model ran. If the data is from a demo scenario rather than a live connection, that is labeled. We never show a green checkmark that is not earned.
We shipped 49 end-to-end tests that all pass, covering every major feature from the Gemini 3 enforcement to the Bradford Hill scoring to the Slack interceptor. Every feature in the demo is tested.
What we learned
Gemini 3 is genuinely good at reasoning tasks that require holding multiple dimensions in mind at once. The Bradford Hill scoring requires evaluating nine criteria simultaneously against quantitative evidence, and Gemini 3 did this better than 2.5 Pro in our side-by-side testing. It is faster, more precise, and more willing to give a clear verdict.
Fivetran MCP changes what is possible. When sync_connection is a first-class tool that an agent can call, you stop thinking about data pipelines as background infrastructure and start thinking about them as active capabilities. SENTINEL calls Fivetran to trigger a sync before every decision snapshot. The data is always current because the agent made it current. That is a fundamentally different mental model from scheduled batch jobs.
Causal inference is a communication problem as much as a statistics problem. Running three statistical tests is straightforward. Getting a non-technical person to understand what they mean is hard. Bradford Hill solved this in 1965 for epidemiology by giving each criterion a name and a binary answer. We borrowed that structure and it works. A CEO can look at a bar chart of nine named criteria and understand whether this was a real cause or a coincidence.
What's next for SENTINEL: The Business Flight Recorder
SENTINEL is Apache 2.0 licensed. Any company with a Fivetran account can clone the repository and deploy it on Google Cloud Run today, for free, with no data science team required.
The immediate next step is a one-click deployment template that connects to any BigQuery table Fivetran already syncs. A company should be able to go from zero to monitored in under an hour.
The longer term vision is a decision intelligence layer that sits alongside every significant business decision, the way a flight recorder sits alongside every flight. Not to prevent humans from making decisions, but to make sure that when something goes wrong, you can find out exactly why, exactly when it started, and exactly what you could have done differently.
The data is already there. It always was.

Log in or sign up for Devpost to join the conversation.