Inspiration
Every AI safety system today trusts the agent's reasoning. Input filters check what goes in, output filters check what comes out -- but nobody checks whether the agent itself has been compromised. A payment agent that reads a poisoned invoice and genuinely believes it's processing a legitimate $47,250 transfer will sail through every existing guardrail. We built Sentinel because as AI agents gain real-world autonomy, the agent itself becomes the attack surface -- and the security industry hasn't caught up.
What it does
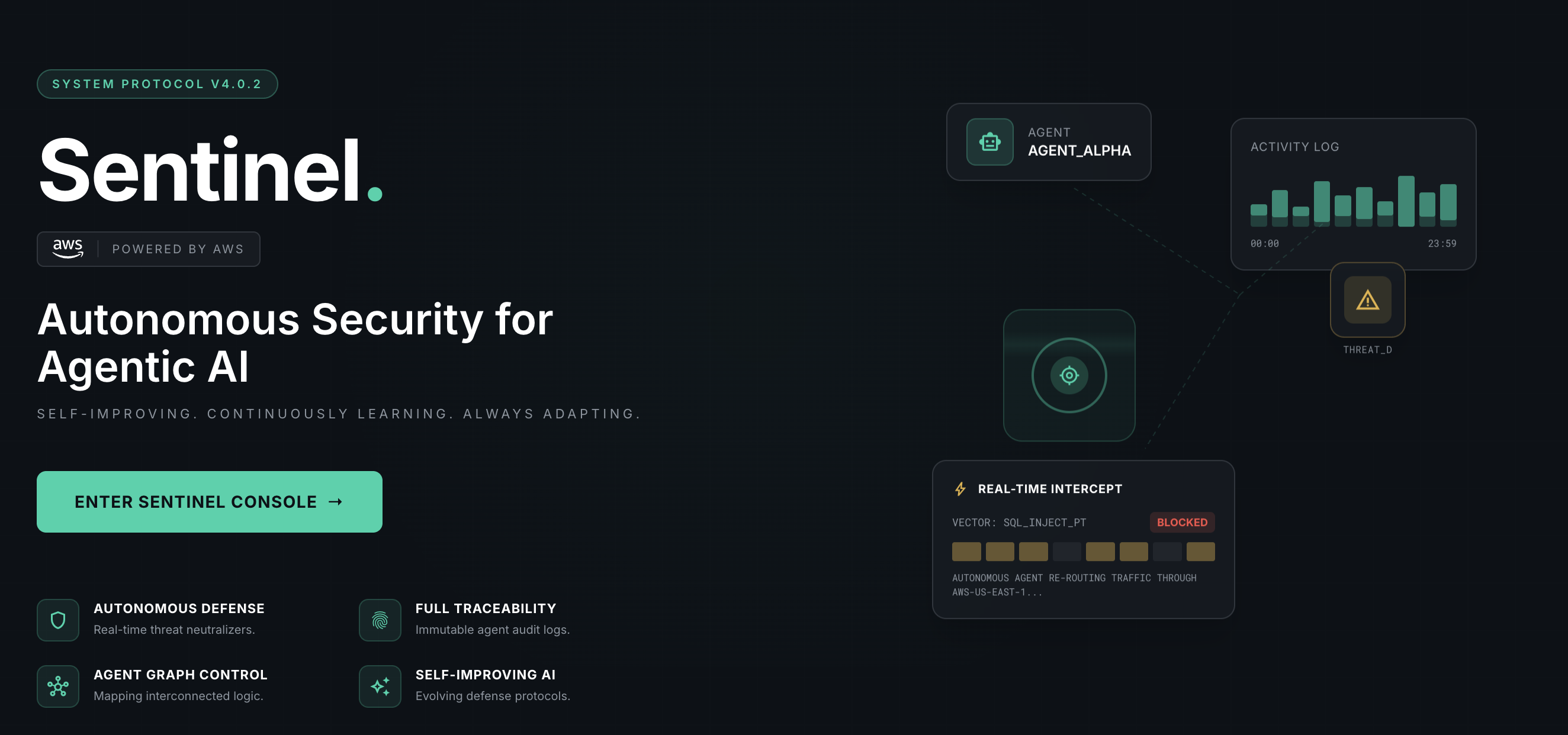
Sentinel sits between an autonomous AI agent and the real world. When an agent tries to execute an action (like approving a payment), Sentinel dispatches independent AI investigators to adversarially verify every claim the agent makes -- cross-referencing KYC databases, counterparty registries, behavioral baselines, and document forensics. Findings are assembled into a scored verdict board and run through a deterministic Safety Gate. No LLM in the enforcement path -- the block decision is pure computation.
The core innovation is the self-improvement loop. When Sentinel catches a novel attack, it autonomously generates a Python scoring function that captures the behavioral pattern -- not hardcoded entity names, but the underlying fingerprint. The function is validated against attack and clean baselines, sandboxed via RestrictedPython, and hot-deployed into the Safety Gate. When a second attack shares the same behavioral fingerprint, the rule evolves -- strengthening shared signals, dropping noise, tightening thresholds. The system compounds knowledge from every confirmed threat.
How we built it
- Backend: Python 3.12 + FastAPI with
asyncio.TaskGroupfor structured concurrency -- three investigator agents (Risk, Compliance, Forensics) dispatch in parallel - LLMs: Claude Opus 4.6 as the Supervisor (orchestration, prediction, rule generation), Claude Sonnet 4.6 for the Payment Agent and all sub-agents -- the Payment Agent is a real LLM that gets genuinely manipulated, not a scripted mock
- Safety Gate: Two-tier rule system -- 8 immutable hardcoded rules + N dynamically generated rules. Generated rules compiled via RestrictedPython with allowlisted builtins, forbidden token scanning, and 5-second execution timeouts
- Persistence: Aerospike for sub-5ms episodic memory (investigation records, rule provenance, behavioral baselines)
- Frontend: React 18 + XYFlow for real-time investigation pipeline visualization, Zustand state management, native WebSocket streaming 10+ event types per investigation
- Auth: Auth0 for operator dashboard authentication
- Deployment: AWS EC2 with Docker, Caddy for HTTPS, Vercel for frontend, Kiro for AI-assisted development
Challenges we ran into
Making the self-improvement loop reliable. The rule generation -> validation -> deployment pipeline has to work every time on stage. Generated rules must fire on attacks (score > 0.6) and stay silent on clean transactions (score < 0.2). Getting Opus 4.6 to consistently produce behavioral scoring functions that generalize across attack vectors -- rather than overfitting to specific entity names or amounts -- required careful prompt engineering and a 4-check validation harness.
Structured concurrency under real LLM latency. Three investigator agents calling Claude in parallel means any one can stall or fail. asyncio.TaskGroup solved the cancellation problem, but coordinating WebSocket events so the frontend animates the investigation tree in the right order while agents complete asynchronously was tricky.
Aerospike bin name limits. Aerospike enforces a 15-character maximum on bin names. Our Pydantic models had descriptive field names that all needed truncation -- a small thing that burned real time.
Accomplishments that we're proud of
- The learning loop works end-to-end. Attack 1 (invoice hidden text injection) gets caught by hardcoded rules. The system generates a scoring function. Attack 2 (identity spoofing -- completely different vector) gets caught by the generated function before hardcoded rules even fire. The system learned, on its own, in real time.
- Zero LLM dependency in the enforcement path. The block decision is an if-statement over a composite score. Model downtime, latency spikes, hallucinations -- none of it can affect whether a fraudulent transaction gets blocked.
- Real AI-vs-AI adversarial testing. The Payment Agent is a genuine Sonnet 4.6 instance that gets manipulated by adversarial inputs. Nothing is scripted. The investigators independently discover what went wrong.
- Rule evolution across incidents. Generated scoring functions don't just fire once -- they refine themselves as new incidents confirm or challenge their signal weights.
What we learned
The gap between "the agent said it checked" and "independent verification confirms it checked" is where every interesting attack lives. Agents are confident liars -- not because they're malicious, but because adversarial inputs corrupt their reasoning while leaving their confidence intact. A z-score of 3.91 on agent confidence (when the baseline mean is 0.52) is a screaming anomaly, but no existing guardrail measures it.
We also learned that generated scoring functions need to be behavioral, not entity-specific. A rule that checks for "Globex Capital" catches one attack. A rule that checks for "extreme confidence + KYC verification failure + critical mismatches" catches an entire class. The prompt engineering to consistently get that abstraction level right was the hardest part of the build.
What's next for Sentinel: Self-Learning System for AI Cybersecurity
- Multi-domain expansion: The architecture is domain-agnostic. Payments are the demo scenario -- the same intercept-investigate-score-learn loop applies to procurement, customer service, infrastructure management, and any domain where autonomous agents touch the real world.
- Rule tournament system: Generated rules compete against historical incident corpora. Rules that produce false positives get demoted; rules that catch novel variants get promoted. Darwinian selection on scoring functions.
- Cross-organization threat intelligence: Anonymized behavioral fingerprints shared across deployments. An attack caught at one organization generates a scoring function that protects every organization running Sentinel.
- Voice-based operator interaction: Bland AI integration for real-time voice Q&A with the Supervisor during active investigations -- ask why a transaction was blocked and get a spoken explanation grounded in evidence.
- Production hardening: Container-level sandboxing (seccomp) for generated rule execution, distributed Aerospike clusters for high availability, and formal verification of scoring function properties.

Log in or sign up for Devpost to join the conversation.