-
-
Patient UI
-
Patient data running using prompt
-
Patient Output decision
Inspiration
Hospital early warning systems have a 90% false alarm rate. Clinicians ignore alerts — a phenomenon called alert fatigue that directly causes patient deaths. The core problem: rule-based systems add up vital sign numbers and fire when a threshold is crossed, but they can't read nurse notes, understand that a beta-blocker is masking septic tachycardia, or recognise that an SpO₂ of 91% is normal for this COPD patient but the 4-hour downward trend is not.
We asked a simple question: what if the alert explained WHY a patient is deteriorating, not just THAT they are? Generative AI can reason over unstructured clinical text, medication side-effect profiles, and vital sign trajectories simultaneously — something no decision tree can replicate. SENTINEL was built to put that reasoning directly into the hands of bedside nurses and rapid response teams.
What it does
SENTINEL is an MCP (Model Context Protocol) server exposing 6 AI-powered clinical tools through the Prompt Opinion multi-agent platform:
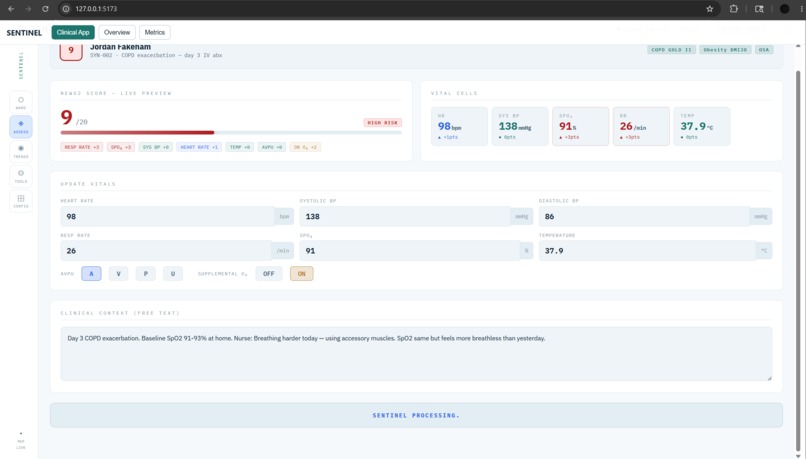
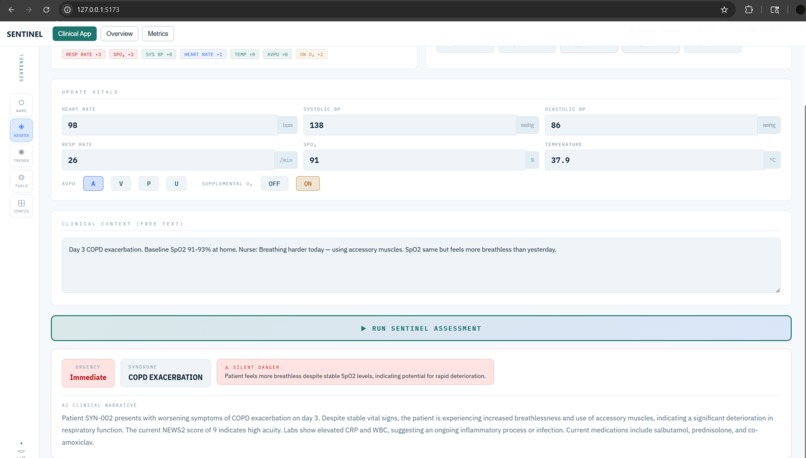
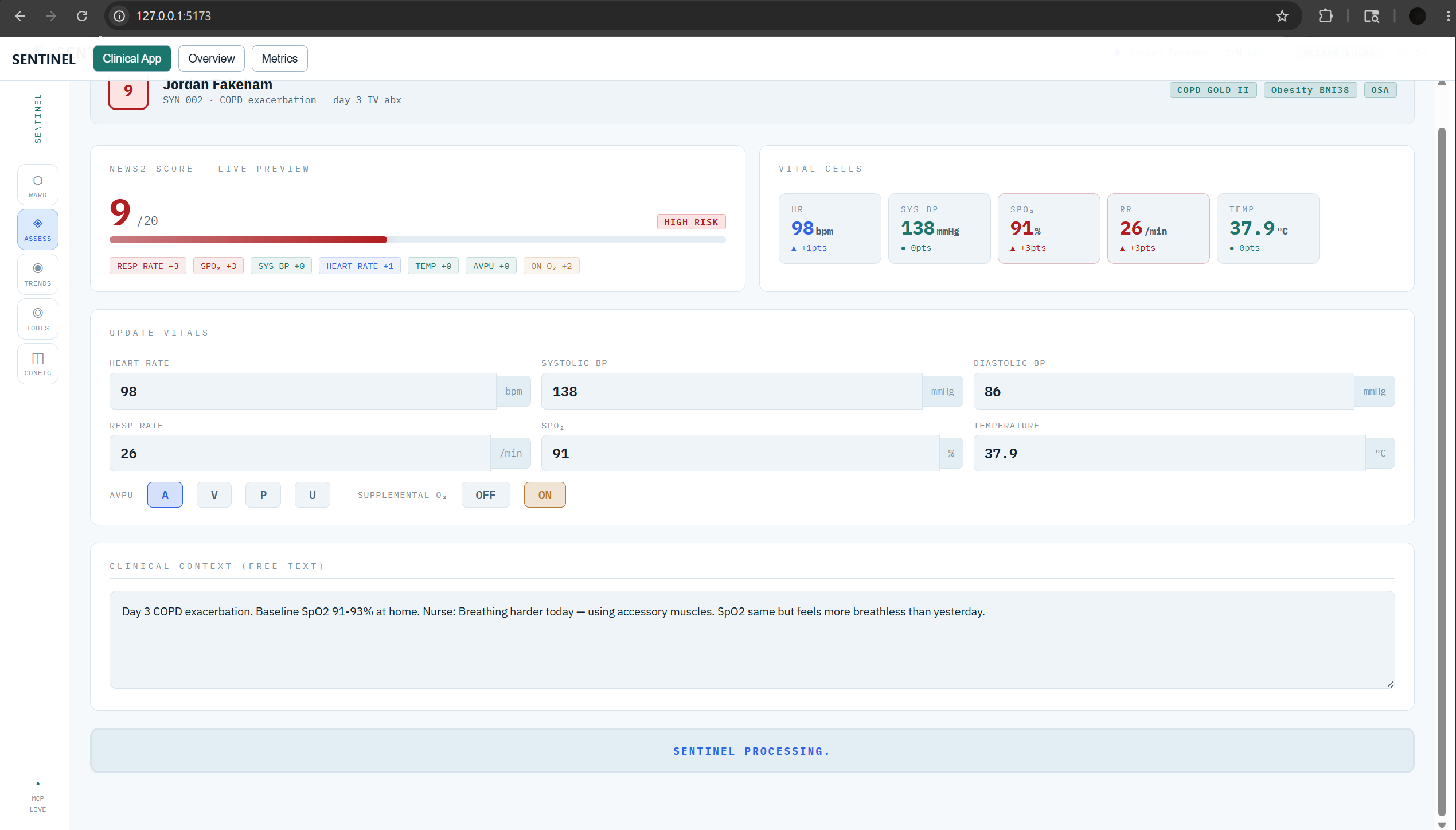
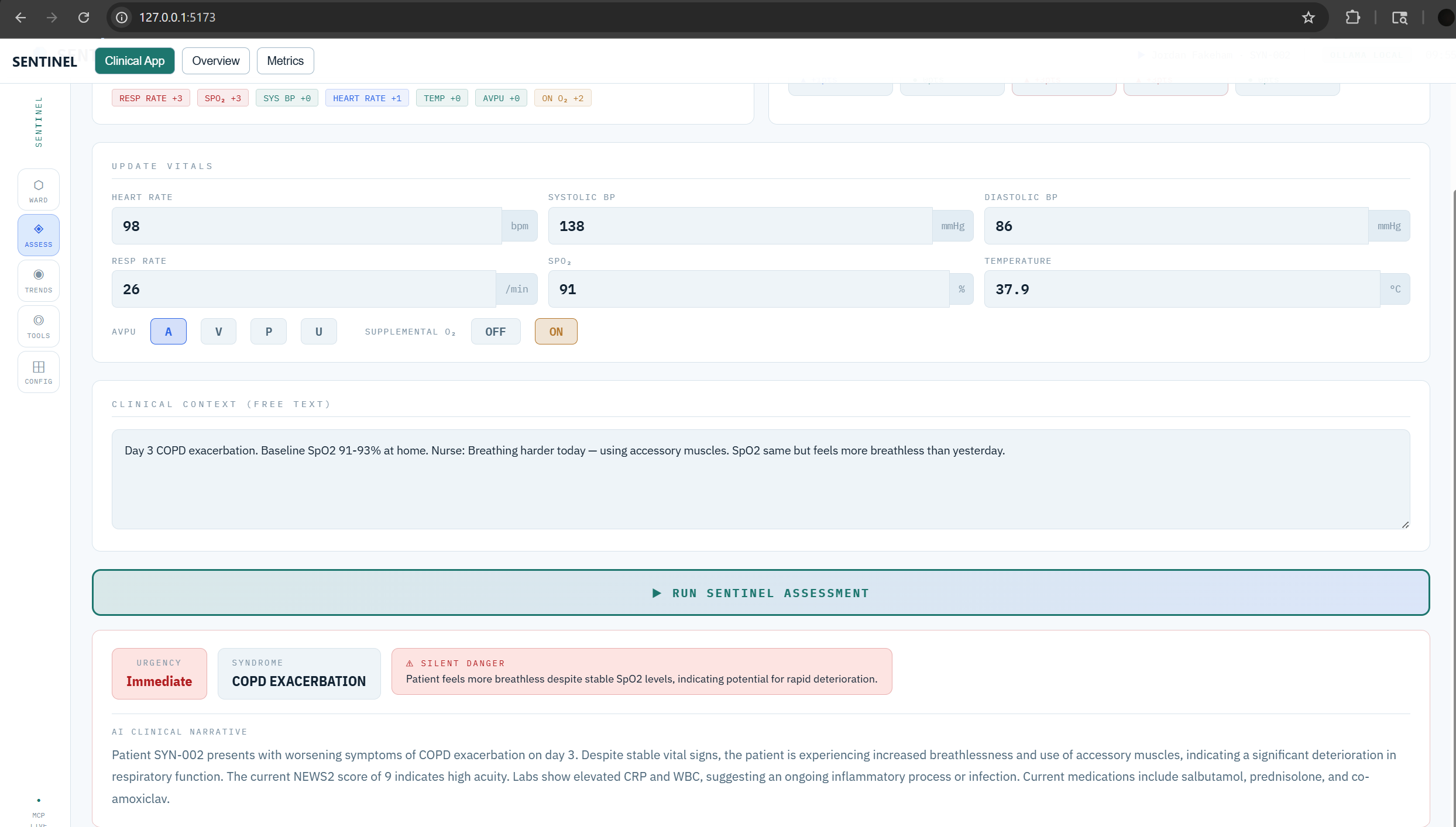
assess_deterioration_risk — Computes a standard NEWS2 early warning score, then applies AI clinical reasoning to produce a narrative explanation of WHY the patient is concerning — detecting masked presentations, silent danger patterns, and syndrome identification that threshold-based systems miss entirely.
analyze_vital_trends — Takes a time-series of vital sign readings and characterises trajectory using chain-of-thought reasoning: IMPROVING / STABLE / SLOW_DETERIORATION / RAPID_DETERIORATION. Catches the patient whose vitals are each "just below" the threshold but whose 4-hour trend is a classic septic response.
generate_clinical_alert — Produces a structured SBAR (Situation-Background-Assessment-Recommendation) escalation call tailored to the receiving clinician's role. A rapid response team gets different language than a charge nurse or ICU fellow.
suggest_intervention_pathway — Evidence-based next steps for the detected syndrome, adjusted for available unit resources. Immediate actions, investigations, medications to hold, and ICU escalation triggers.
create_handoff_brief — A 60-second shift change summary synthesising vitals, clinical concerns, recent interventions, and pending tasks. Information loss at handoff causes 80% of serious medical errors.
screen_medication_conflicts — Reviews active medications against real-time clinical status — not drug-drug interactions, but clinical-status conflicts that require reasoning (e.g., bisoprolol masking septic tachycardia, NSAIDs in AKI).
How we built it
Backend — MCP Server (Python): Built with the MCP Python SDK using stdio transport, making it natively invokable from any Prompt Opinion agent. The server routes each of the 6 tools to the optimal AI model based on what that tool needs: llama3.3:70b for clinical assessment (best open-source clinical accuracy at 65.7%), deepseek-r1:14b for trend analysis (best chain-of-thought reasoning), phi4:14b for medication screening (efficient, validated in clinical extraction), and qwen2.5:14b for handoff briefs (128k context window).
AI Backends: Three modes via a single environment variable — Anthropic Claude Sonnet 4 (cloud, best quality), Ollama local inference (HIPAA-compatible, zero data leaves hospital network), or Auto (Ollama first, Anthropic fallback). The Ollama integration uses httpx for async HTTP calls to the local inference server.
Synthetic Data: A dedicated generator (synthetic_data_ollama.py) creates physiologically realistic patient scenarios using a physics-based vital sign model across 5 clinical syndromes. Optionally uses a small local Ollama model to generate richer nurse observation narratives. All patient names are explicitly synthetic (e.g., "Alex Synthetic"), all IDs prefixed SYN-.
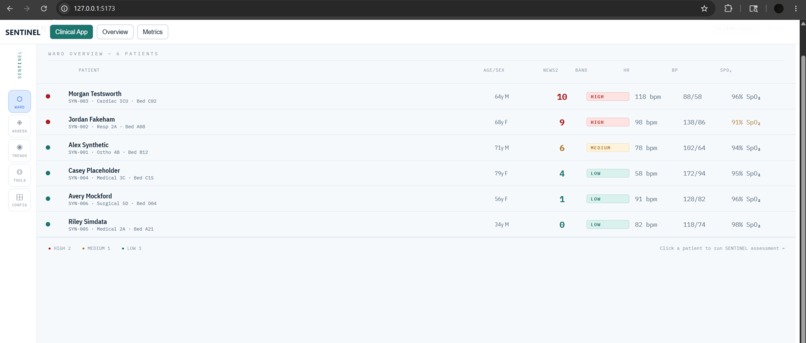
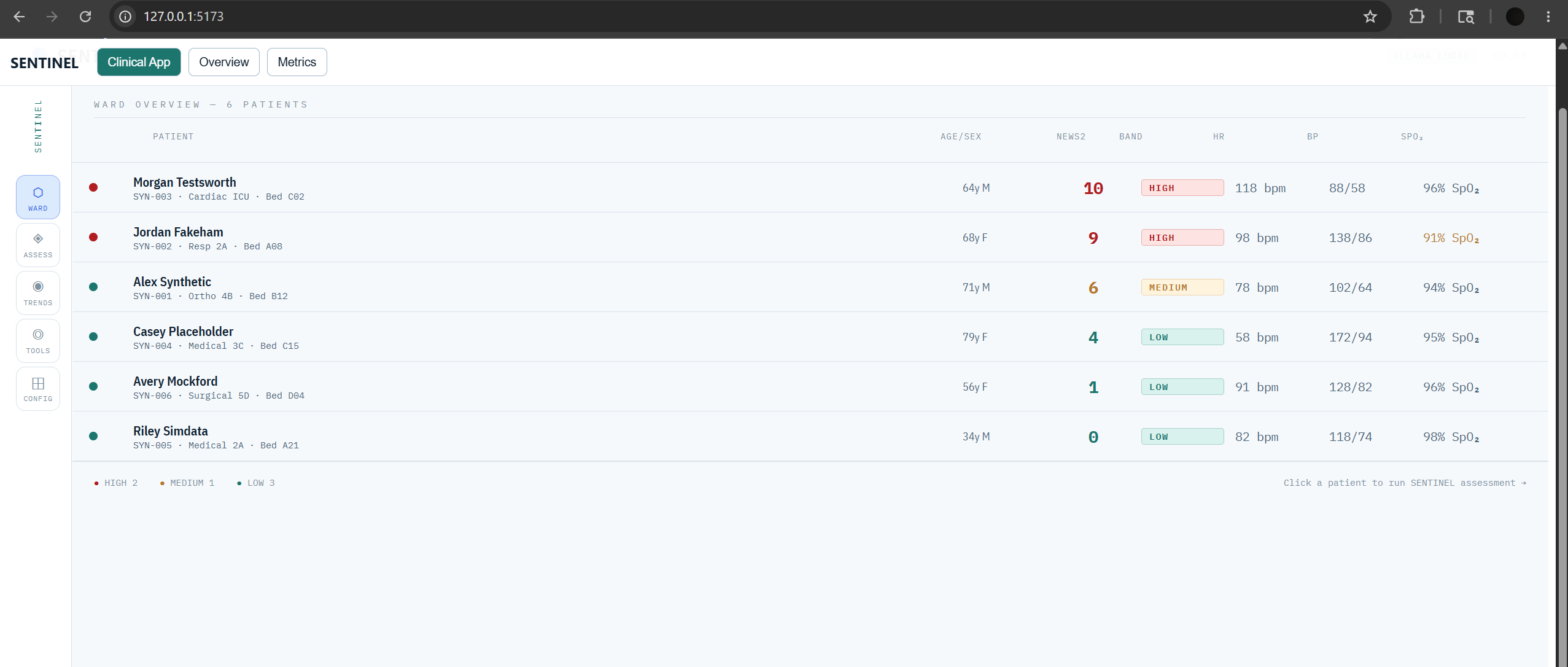
Frontend — React Clinical Dashboard: Built in React with Recharts for vital sign trend visualisation. Design follows real ICU monitoring system aesthetics (IBM Plex Mono for numbers, deep navy with clinical status semantics). Five screens: Ward overview, Patient assessment, Vital trends, Clinical tools, and Configuration.
Infrastructure: Docker + docker-compose for full stack deployment including automatic Ollama model pulling. Marketplace manifest in JSON following Prompt Opinion's MCP registry schema.
Challenges we ran into
JSON reliability across small models — Getting smaller Ollama models (7B–14B parameters) to return clean, parseable JSON consistently for clinical reasoning was the hardest technical problem. We solved it with strict system prompt engineering, low temperature (0.1), and robust try/catch fallback that degrades gracefully rather than crashing.
Tool-to-model routing without latency spikes — Each of the 6 tools has a different cognitive demand. Routing assess_deterioration_risk to a 70B model and screen_medication_conflicts to a 14B model required building a model availability checker that polls the Ollama /api/tags endpoint asynchronously, with automatic fallback to lite models when preferred models aren't available.
Clinical specificity vs sensitivity balance — The hardest clinical design decision: a system that alerts on everything is useless. We had to design prompts that would correctly NOT escalate an improving DKA patient (SCN-005) while catching a masked sepsis presentation (SCN-001). Tuning this required multiple prompt iterations and the addition of an explicit confidence_note field in the assessment output.
Stateless MCP architecture — MCP servers communicate over stdio and are stateless by design. Implementing trend analysis — which requires comparing multiple time points — without any persistent state meant all historical data must be passed in each tool call. We designed the vital_series input schema to carry the complete history in a single request.
Prompt Opinion marketplace integration — The MCP protocol is young and Prompt Opinion's marketplace schema required careful alignment of tool input/output schemas with their discovery and invocation expectations.
Accomplishments that we're proud of
The bisoprolol scenario works — Our flagship test case (SCN-001): a post-op patient on bisoprolol with a NEWS2 score of 3 (LOW risk by traditional scoring). SENTINEL consistently identifies this as early sepsis, flags the beta-blocker as masking tachycardia, and marks it as silent_danger: true. A traditional system would send this patient home or delay escalation by hours.
Fully offline clinical AI — The Ollama integration means SENTINEL can run entirely on a hospital's own hardware with no data leaving the network. This is architecturally necessary for real-world healthcare deployment. We validated this works end-to-end with llama3.3:70b on a local GPU.
Complete submission — Working MCP server, synthetic data generator with Ollama narrative enhancement, Prompt Opinion marketplace manifest, Docker deployment stack, React clinical dashboard, and all 6 tools returning well-structured, clinically appropriate outputs. No placeholders.
The specificity test passes — SCN-005 (recovering DKA patient) correctly receives a LOW urgency assessment with "Monitor" classification and no escalation recommendation. A clinical AI that over-alerts is not clinically useful. We're proud that SENTINEL knows when NOT to escalate.
Real benchmark grounding — Every impact claim in the submission is sourced: 90% false alarm rate, AUROC comparisons from JAMA Network Open (n=362,926, 2024), −28% mortality reduction from BMC Medical Informatics meta-analysis (2025). The project is built on documented clinical evidence, not general AI promises.
What we learned
Clinical AI's hardest problem is specificity, not sensitivity — It's easy to build a system that alerts on everything. Building one that clinicians will actually trust means demonstrating that it correctly doesn't escalate stable patients. We redesigned our evaluation scenarios specifically to test this after realising all our initial test cases were deteriorating patients.
Prompt engineering for clinical JSON is a discipline in itself — Temperature, explicit JSON-only instructions, field-level constraints ("max 180 words", "Immediate|Urgent|Monitor" enums), and fallback parsing all matter. A poorly structured clinical prompt produces confident-sounding clinical nonsense, which is worse than no output.
The MCP protocol is genuinely powerful for healthcare agents — The ability for a Prompt Opinion orchestrator to call assess_deterioration_risk, get a syndrome back, then conditionally call suggest_intervention_pathway or generate_clinical_alert based on the result — without any code changes — is a real architectural win for clinical workflow automation.
Ollama model selection matters more than model size — deepseek-r1:14b outperforms llama3.3:70b on the trend analysis task because the chain-of-thought training aligns with trajectory reasoning. Routing by cognitive task type, not just model size, is the right design pattern.
The narrative IS the product — We initially focused on the NEWS2 score and structured outputs. User feedback during development consistently pointed to the narrative_reasoning field as the most valuable output. The number tells you what; the narrative tells you what to do about it.
What's next for SENTINEL MCP — Proactive Clinical Deterioration Intelligence
HL7 FHIR integration — Connect SENTINEL directly to FHIR-compliant EHR systems (Epic, Cerner) so vital signs flow in automatically rather than requiring manual input. This transforms SENTINEL from a decision-support tool into a continuous monitoring agent.
Fine-tuned medical model — Fine-tune a 7B–14B base model on synthetic clinical deterioration scenarios to improve the narrative reasoning quality for the Ollama local path, closing the gap with Claude Sonnet 4.
A2A multi-agent clinical network — Build specialist A2A agents (pharmacy agent, radiology agent, lab agent) that SENTINEL can delegate to via Prompt Opinion's agent-to-agent protocol. The deterioration assessment becomes the orchestrator that pulls in specialist knowledge.
Prospective validation study — Partner with a simulation hospital or clinical informatics team to run SENTINEL against de-identified historical ICU data and measure sensitivity/specificity against actual adverse event outcomes.
Regulatory pathway — Prepare a FDA 510(k) pre-submission strategy positioning SENTINEL as a Class II Clinical Decision Support Software device under the 21st Century Cures Act framework — the pathway that allows clinician-facing, non-autonomous decision support to reach real hospital floors.
Built With
- anthropic
- claude
- deepseek-r1:14b
- docker
- dockercompose
- httpx(async)
- ibm-plex
- javascript
- json-rpc
- llama3.2:3b
- llama3.3:70b
- mcp
- medllama3:8b
- ollama
- phi4:14b
- python3.11
- qwen2.5:14b
- react18
- recharts
- typescript

Log in or sign up for Devpost to join the conversation.