-
-
assessment greeting
-
assessment complete
-
recruiter dashboard
-
result overview for recruiter
-
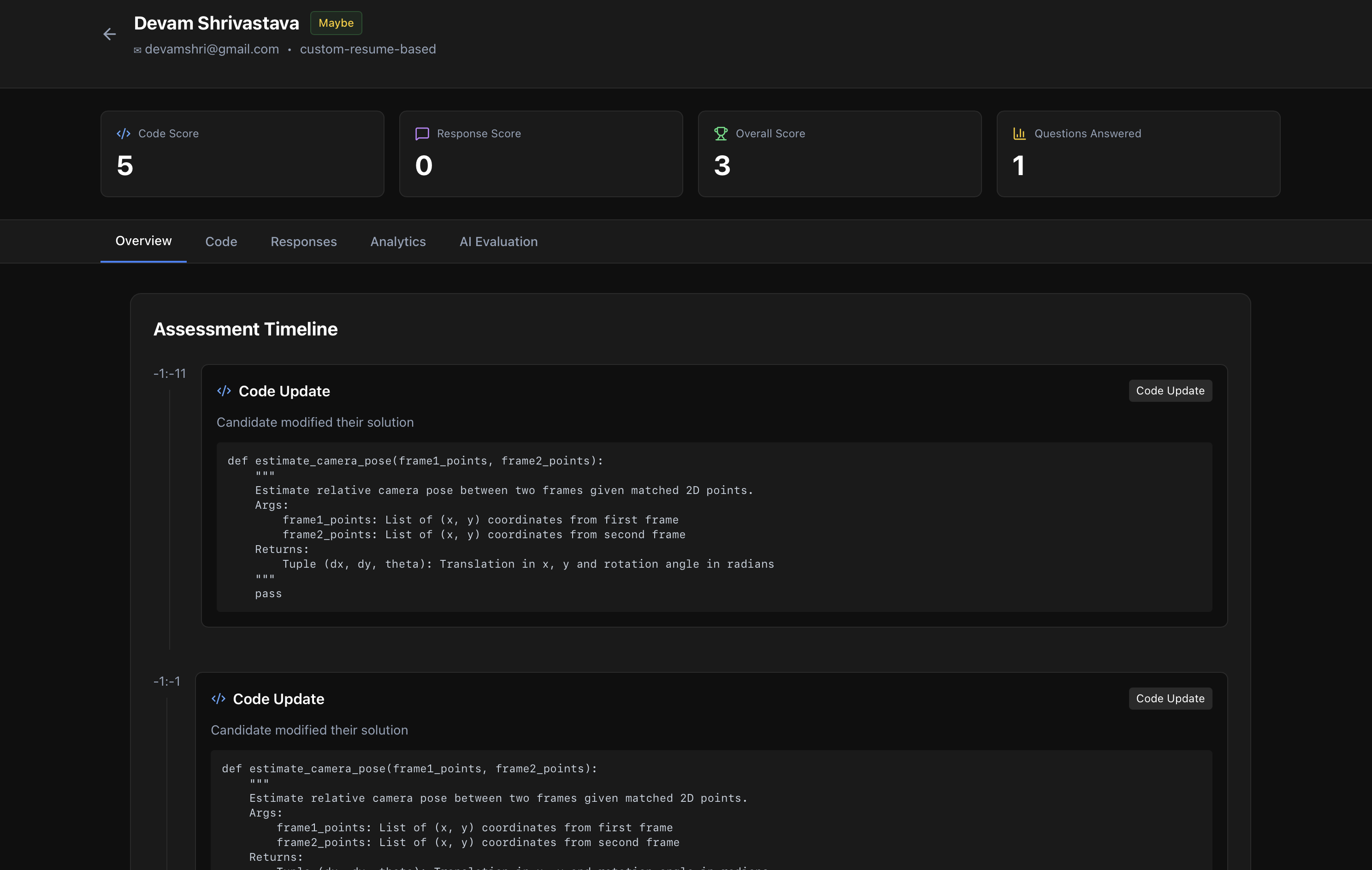
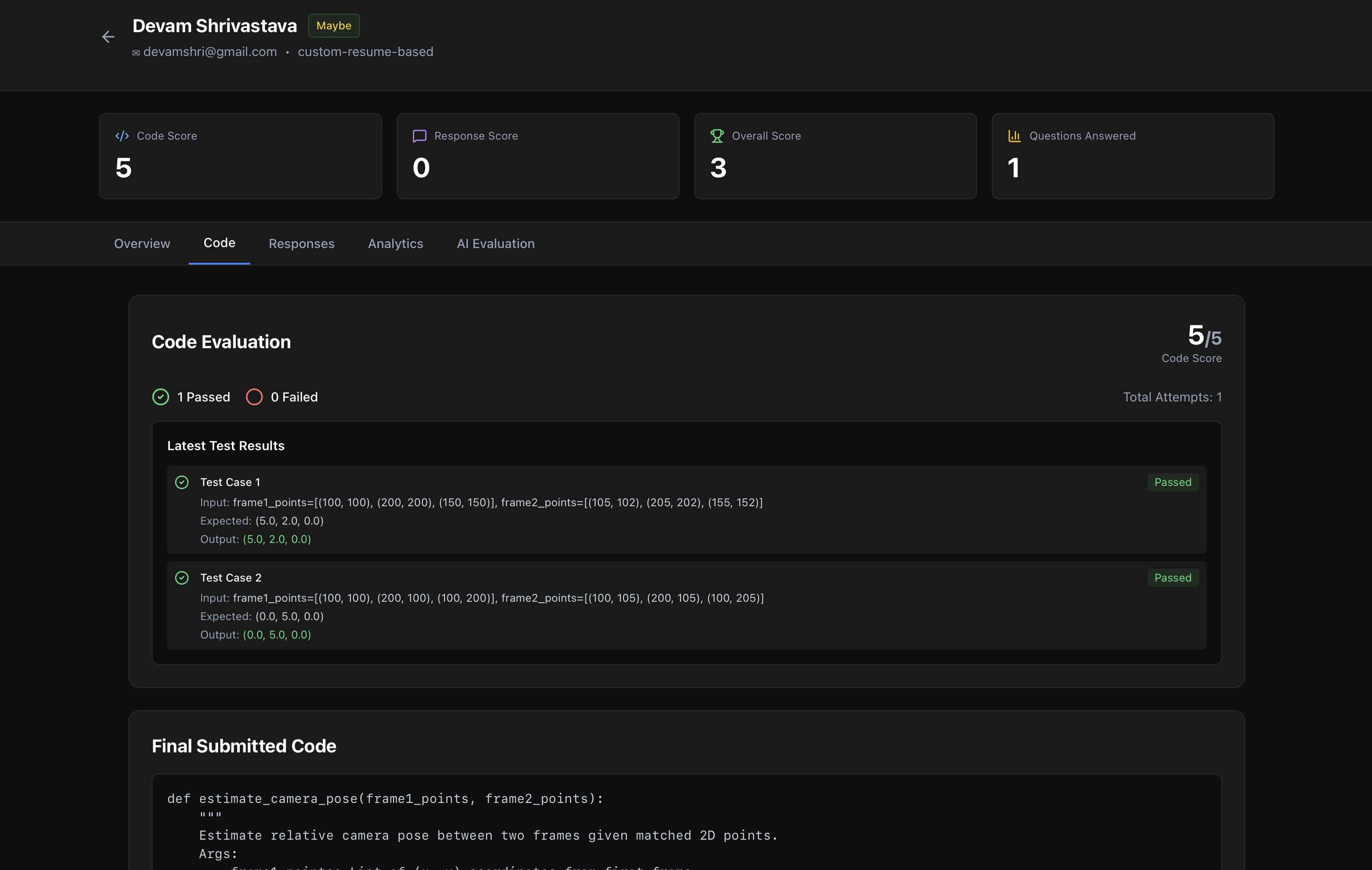
code overview for recruiter
-
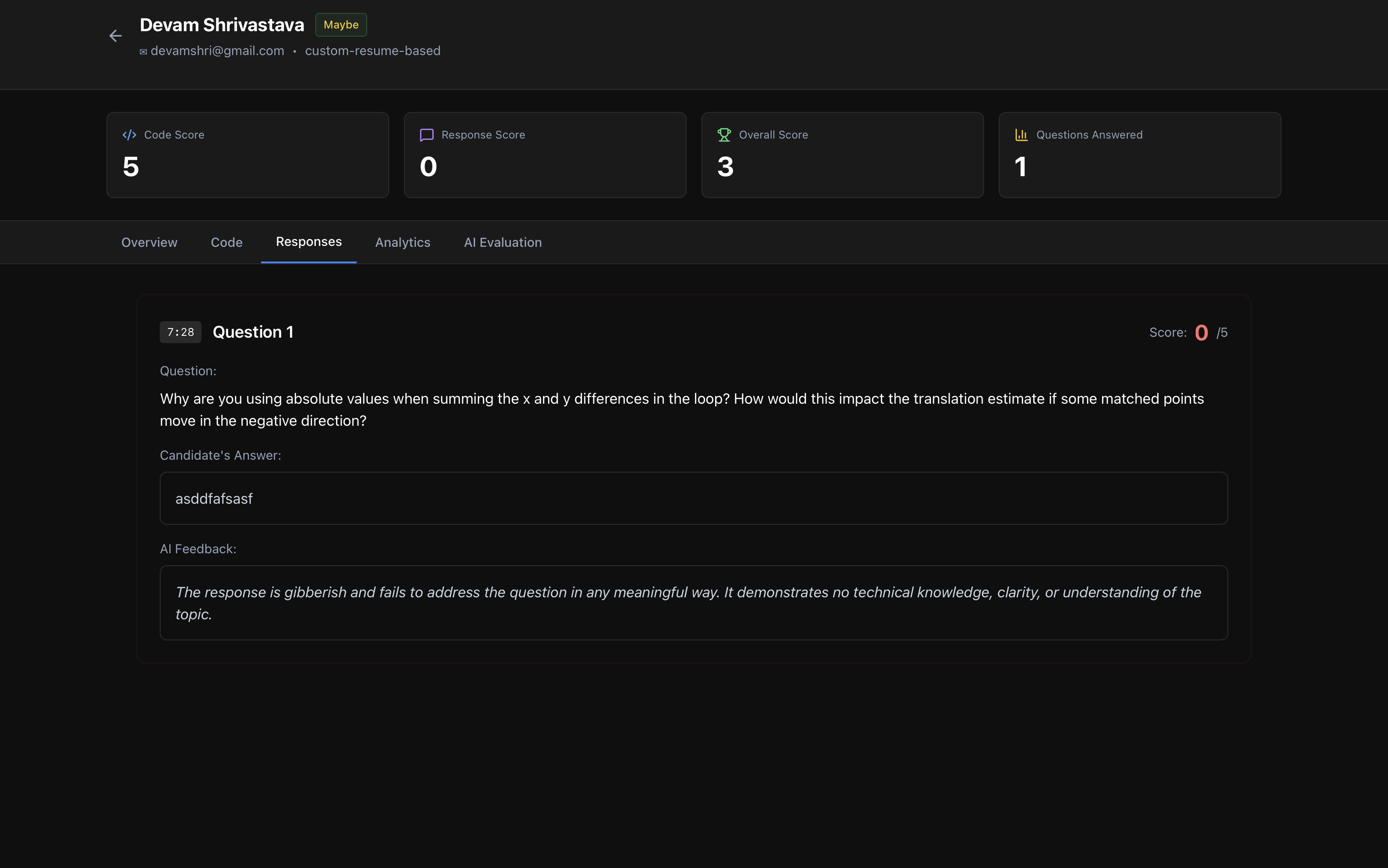
responses overview for recruiter
-
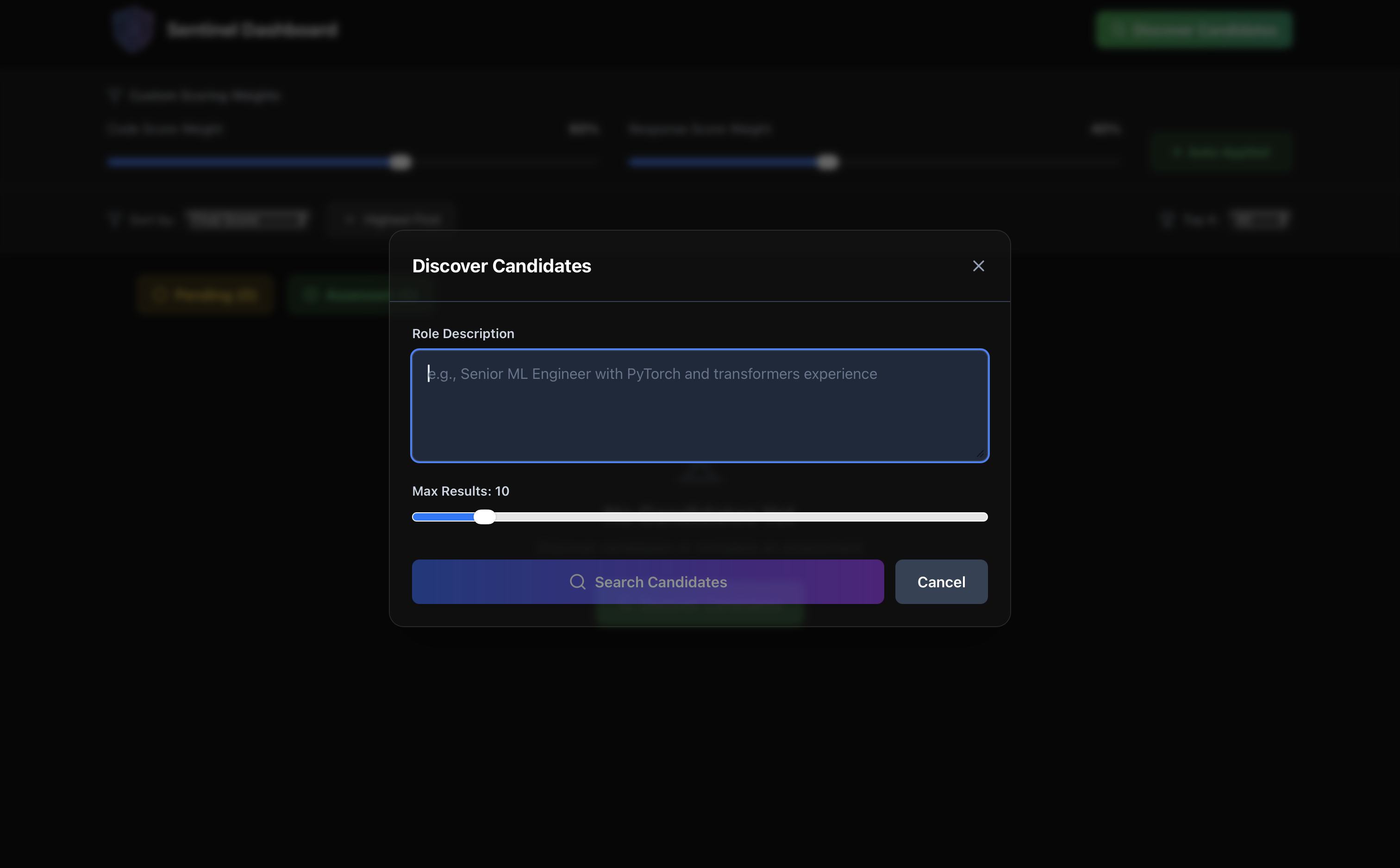
discover/search for candidates
-
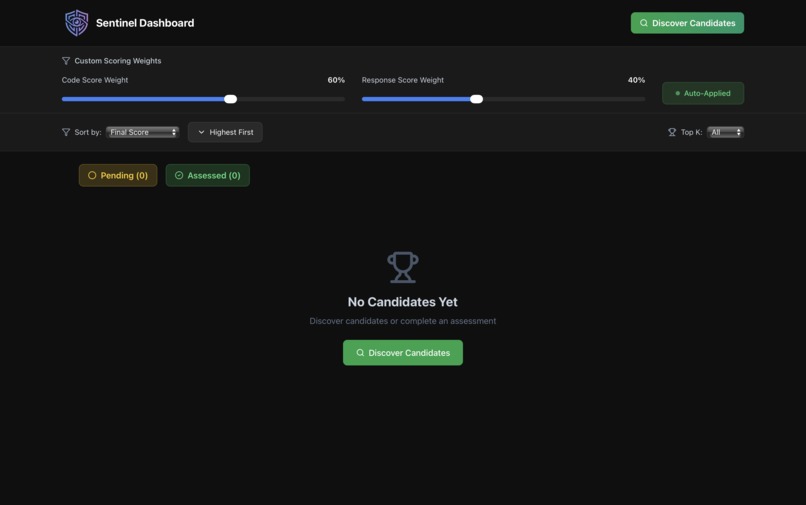
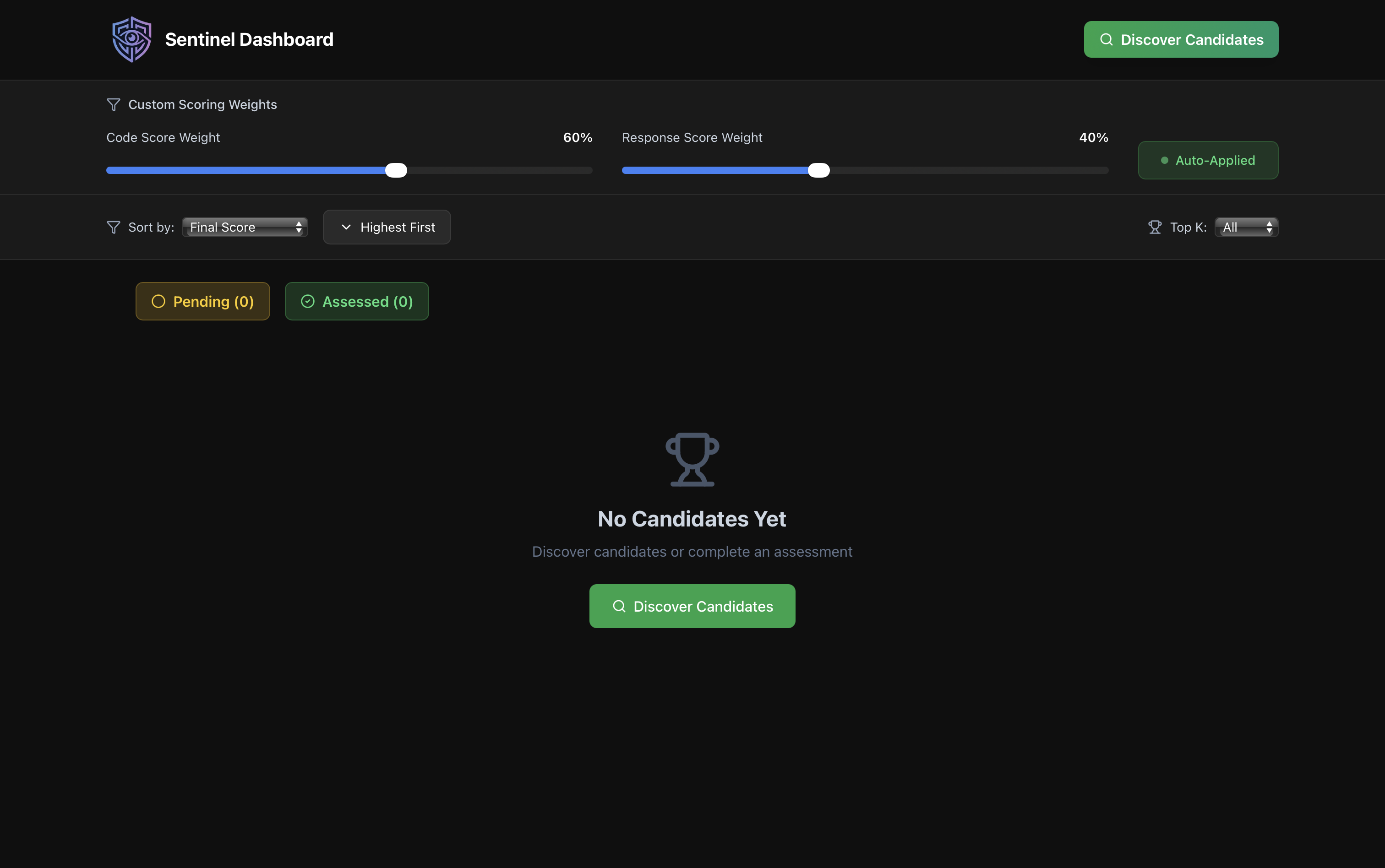
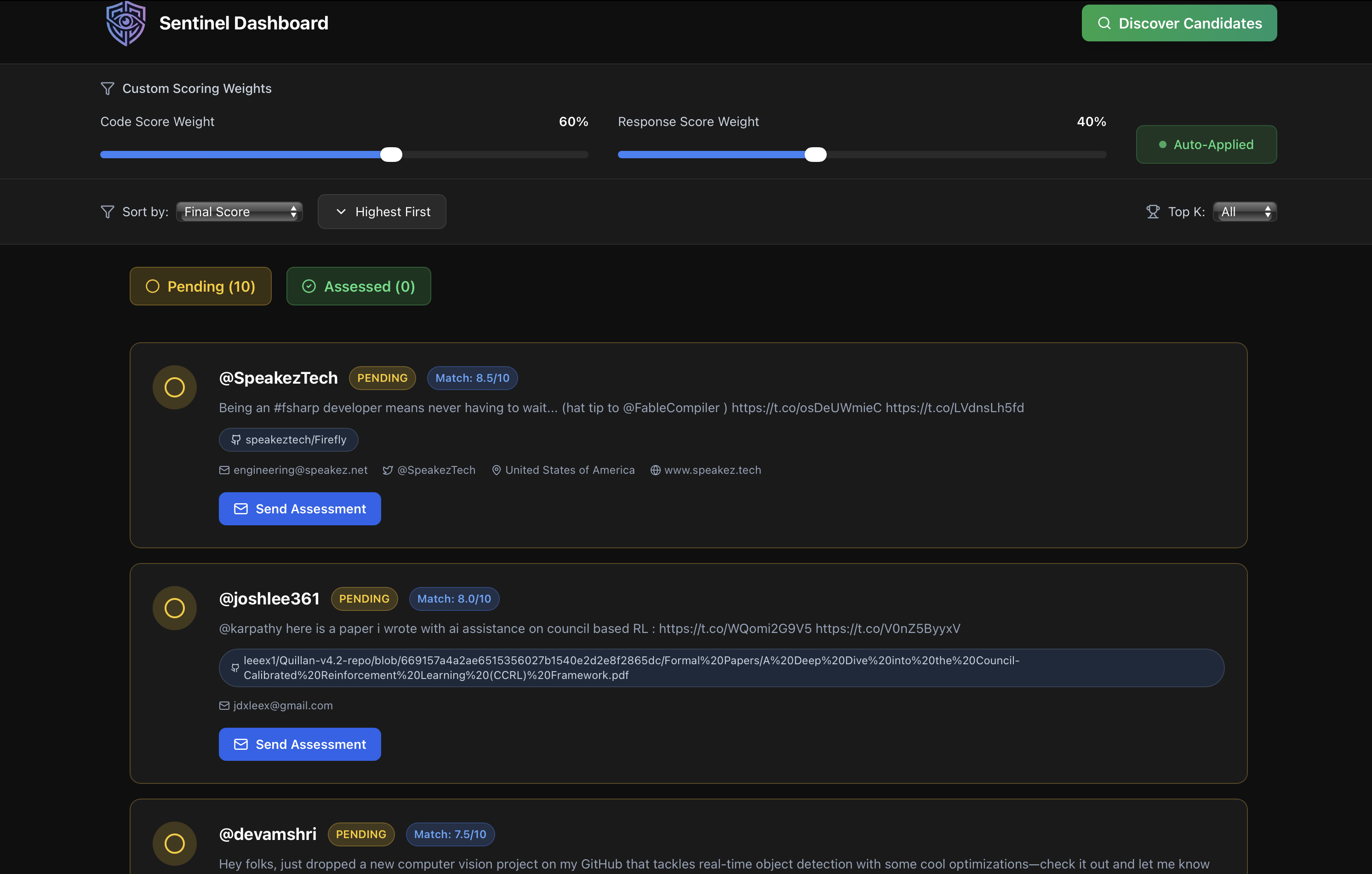
pending candidates
-
assessment page
-
keystroke analytics for recruiter
-
automatic hiring decision analytics for recruiter
-
hint
-
challenge question
-

landing page

Sentinel: AI-Powered Technical Assessment Platform
Inspiration
The technical hiring process is fundamentally broken. Recruiters waste hours searching LinkedIn with crude keyword filters, missing talented developers who are actively building and sharing their work on platforms like X (Twitter). Meanwhile, candidates face generic LeetCode problems that reveal nothing about how they actually think, adapt, or solve real problems under realistic constraints.
We asked ourselves: What if AI could discover candidates where they naturally exist—on X—based on what they're actually building and discussing? What if every assessment was personalized to the candidate's unique background? What if we could understand not just what answer they give, but how they approach problems when stuck, how they respond to feedback, and how they communicate their reasoning?
With Grok's advanced reasoning capabilities and the power of reinforcement learning, we saw an opportunity to completely reimagine technical hiring—from organic discovery to adaptive assessment to comprehensive evaluation.
Sentinel was born from one core belief: AI should augment human judgment, not replace it. Let machines handle the discovery, monitoring, and analysis—so recruiters can focus on connecting with exceptional people.
What it does
Sentinel is an end-to-end AI-backed recruitment platform that transforms every stage of technical hiring:
Organic Candidate Discovery
Instead of keyword matching on LinkedIn, Sentinel discovers candidates where top developers actually share their work—X (Twitter):
How it works:
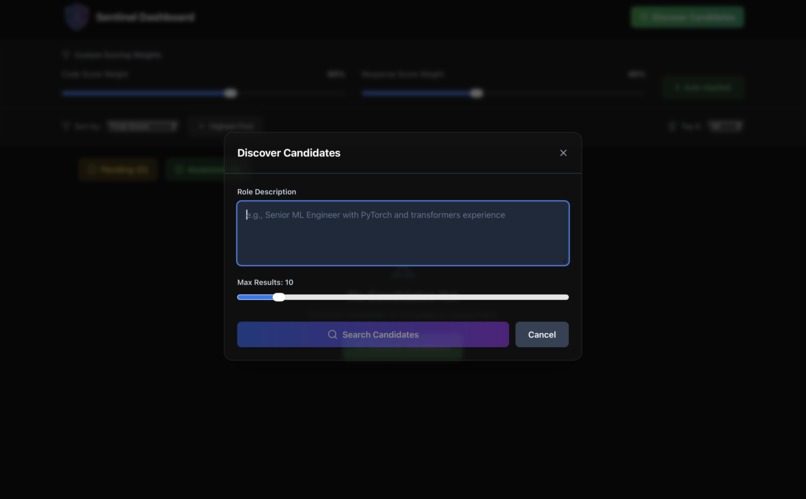
- Natural Language Search: Recruiter describes the role: "Senior ML engineer with PyTorch experience"
AI-Powered Query Generation: Grok analyzes the job description and extracts technical keywords.
Progressive X Search Strategy (3 Levels):
- Level 1: Specific queries requiring GitHub links:
"Senior ML Engineer PyTorch" github.com -is:retweet - Level 2: Broader queries without GitHub requirement:
"PyTorch developer" -is:retweet - Level 3: Primary keywords only:
"PyTorch" -is:retweet - Automatically adjusts breadth and early-terminates when target candidate count reached
- Level 1: Specific queries requiring GitHub links:
Multi-Source Profile Enrichment:
- Extracts GitHub profiles from X posts and bios
- Expands shortened t.co URLs to find hidden GitHub links
- Batch fetches detailed bios from X (100 users per request)
- Mines GitHub commit history to extract emails:
- Exploits the .patch file in the commit history to find the author's email
- Pulls X handles, company, location, blog from GitHub profiles
AI-Powered Relevance Ranking: Grok evaluates each candidate based on:
- Post content and technical depth
- GitHub activity and contributions
- Match quality with job requirements
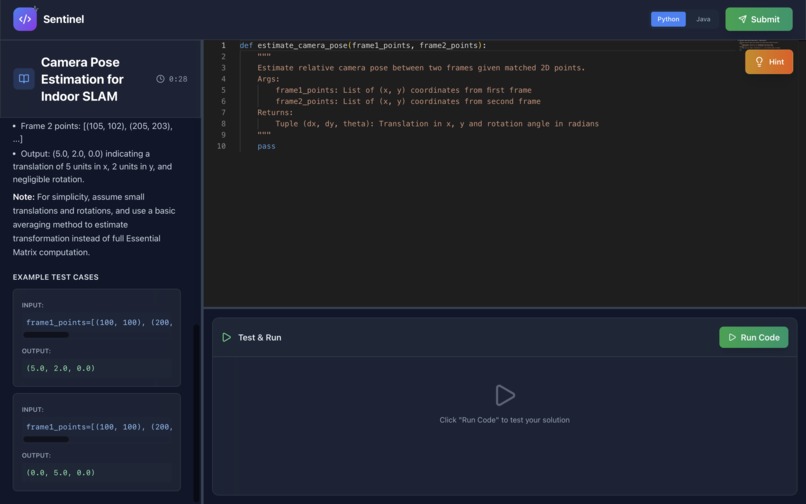
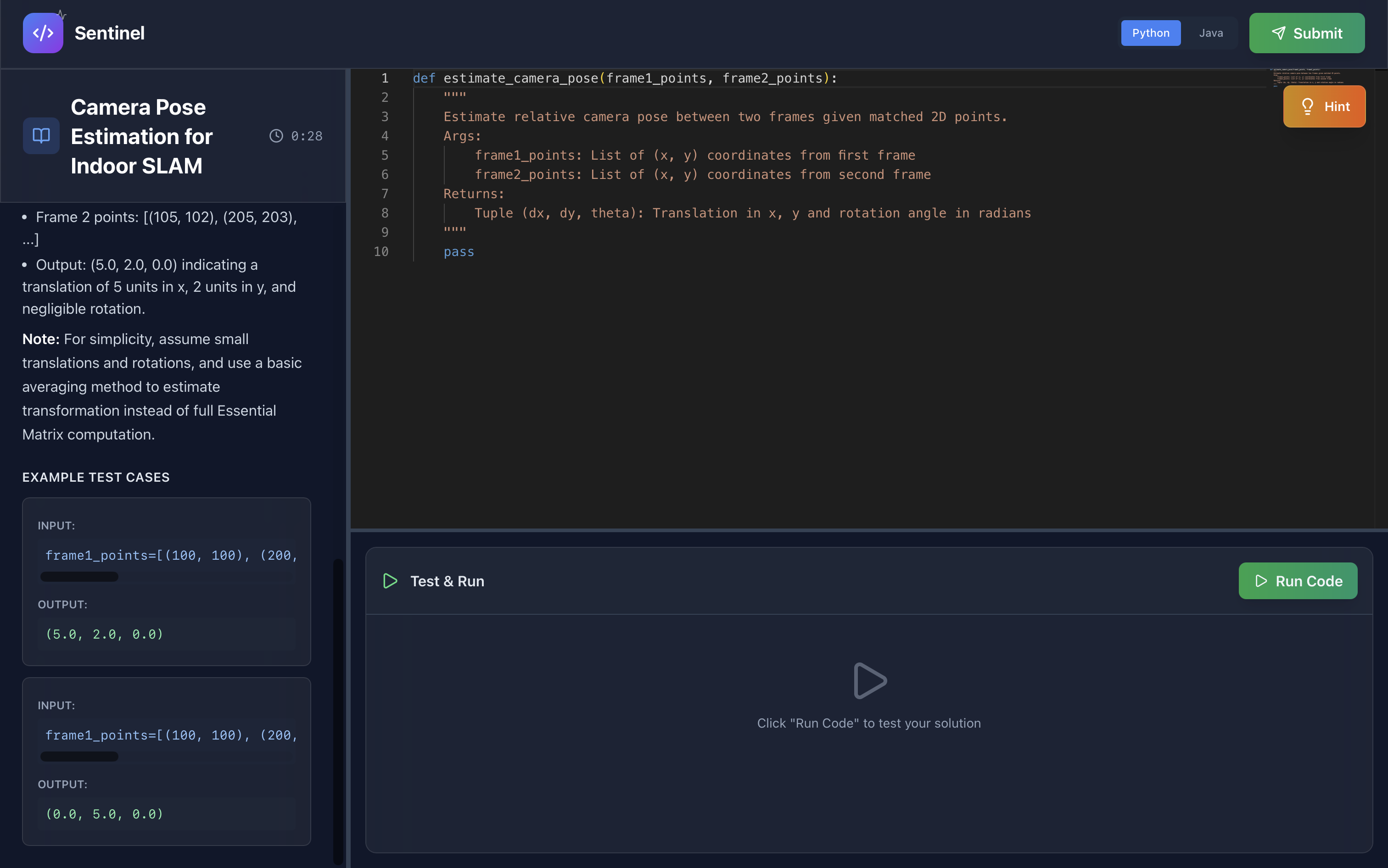
Resume-Based Assessment Generation
Every candidate gets a unique coding problem matched to their exact background:
The Flow:
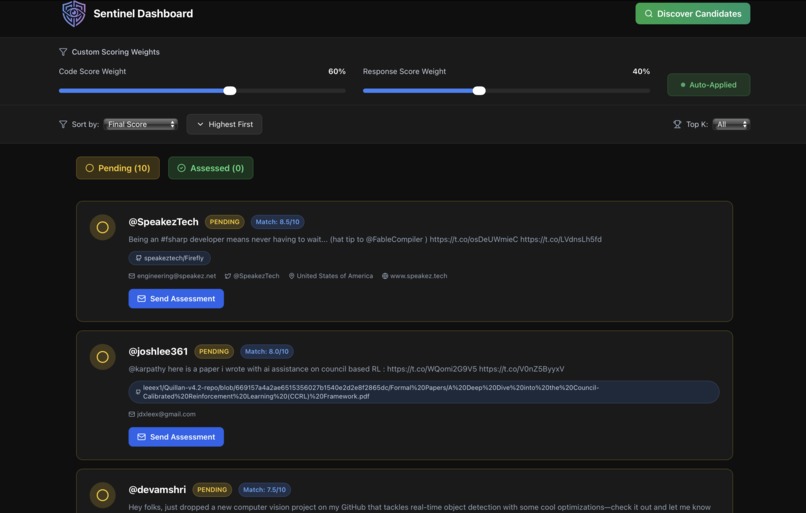
- Recruiter clicks "Send Assessment" on any discovered candidate
- System generates unique token and creates assessment link.
- Automated Email Delivery:
- Sexy HTML email with gradient header and personalized greeting.
- Supports Gmail, Outlook, SendGrid, AWS SES via SMTP
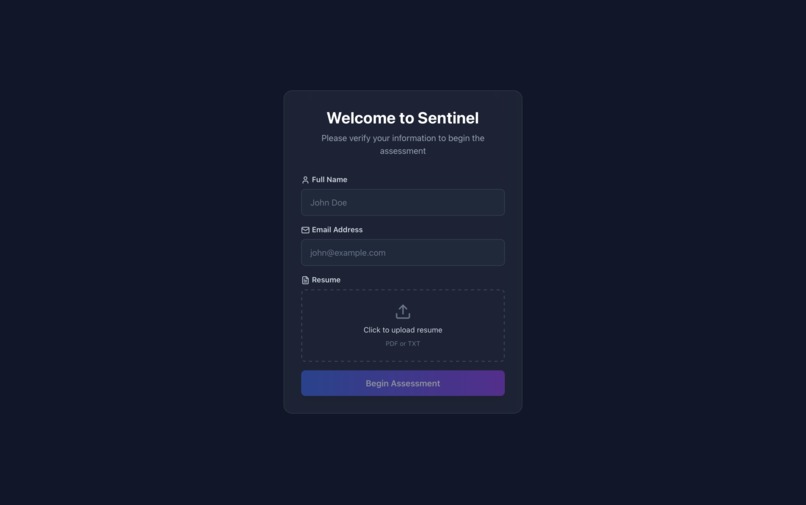
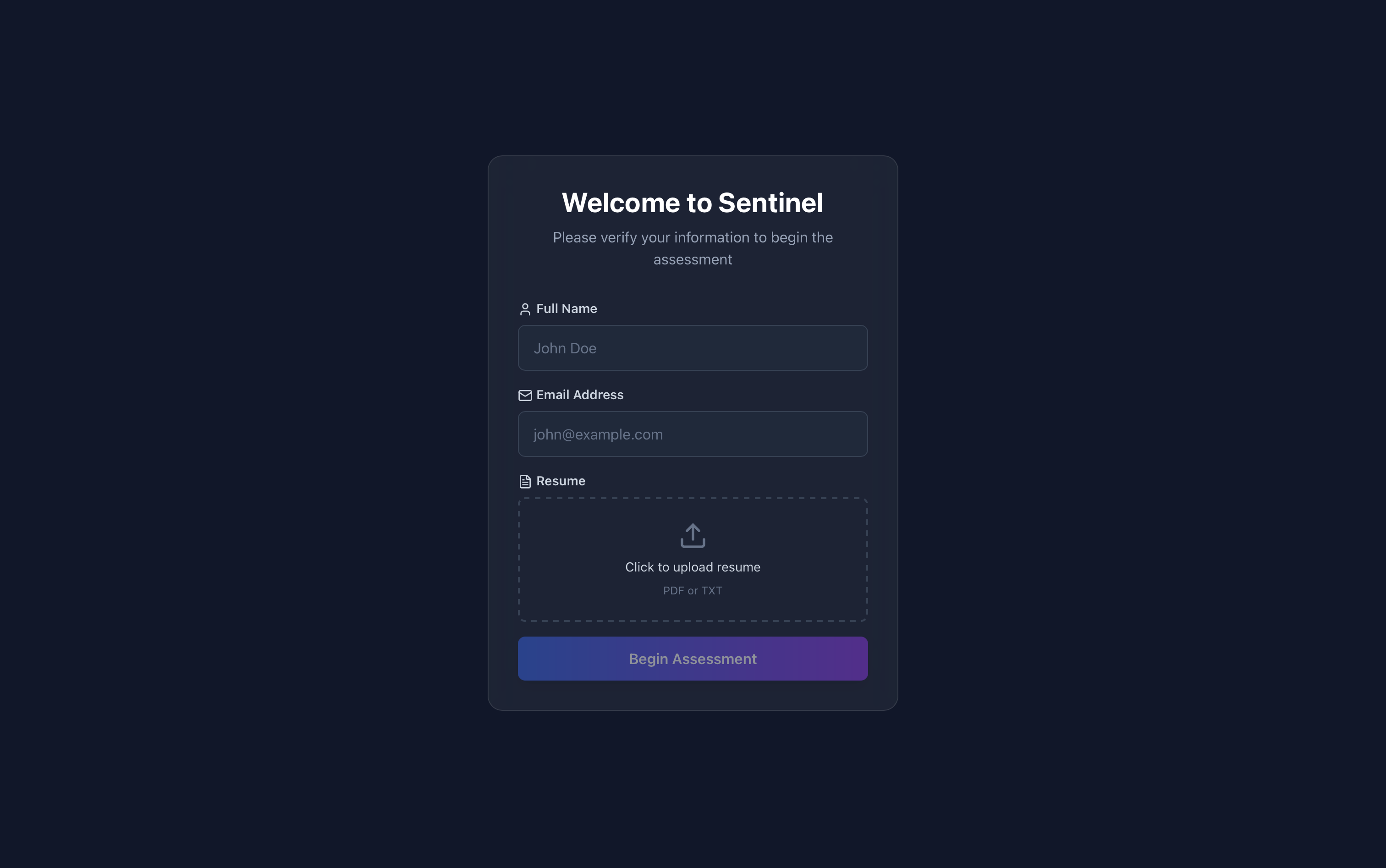
- Candidate opens link → Verification Page (
AssessmentTokenPage):- Enters full name and email
- Uploads resume (PDF/TXT supported, up to 4000 chars extracted)
- Token verified against backend before proceeding
- Grok analyzes resume and generates custom problem:
- Problem title matching their experience level (junior/mid/senior)
- Problem description using technologies from their resume
- Difficulty level, topics, and reasoning for selection
- Candidate redirected to assessment with personalized problem loaded
Example: A candidate with React + AWS experience gets a problem about optimizing a real-time dashboard with caching.
Reinforcement Learning Assessment Engine
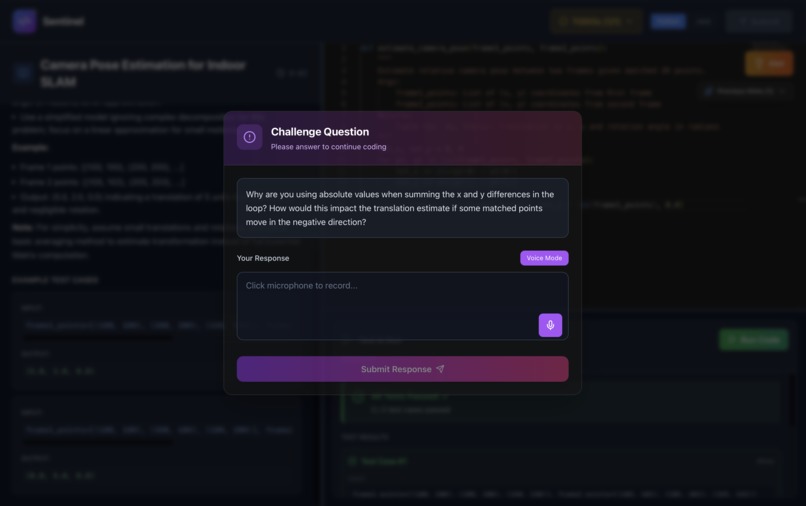
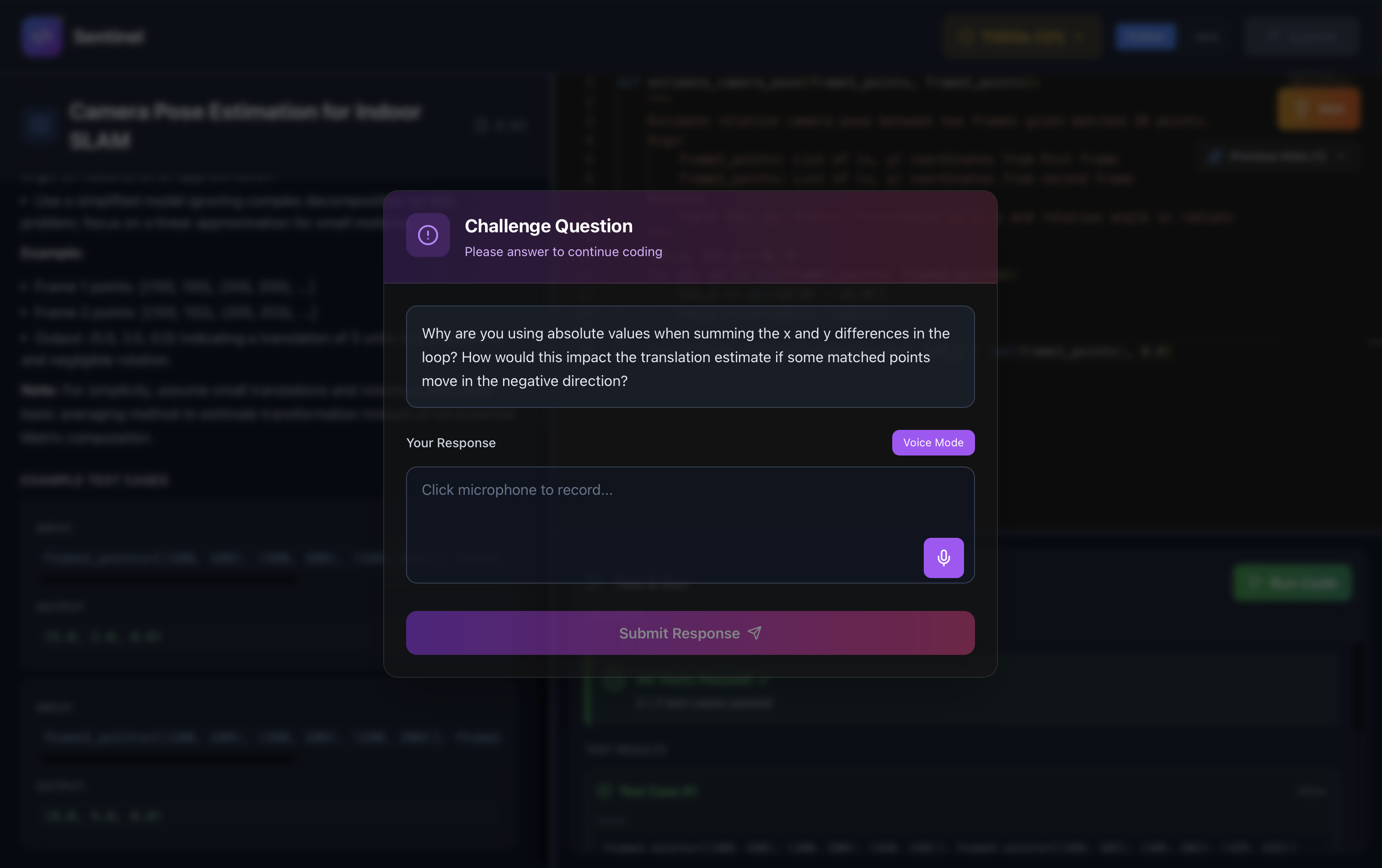
Challenge Question System:
Smart Monitoring: Checks code every 15 seconds for substantial changes (multiple lines of meaningful new code)
Context-Aware Generation: Grok performs line-by-line diff and generates SPECIFIC questions:
- "Why did you choose HashMap over TreeMap?"
- "How would you optimize this for 1M requests/second?"
- "Walk me through your debugging process for this edge case"
- "Explain the tradeoffs of your approach vs using a heap"
Questions added as TODO items that must be completed before submission
Text responses captured and analyzed separately for communication score
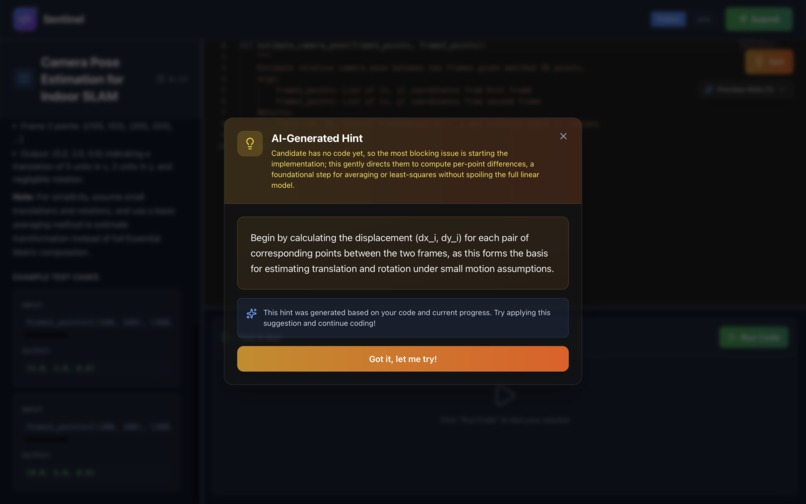
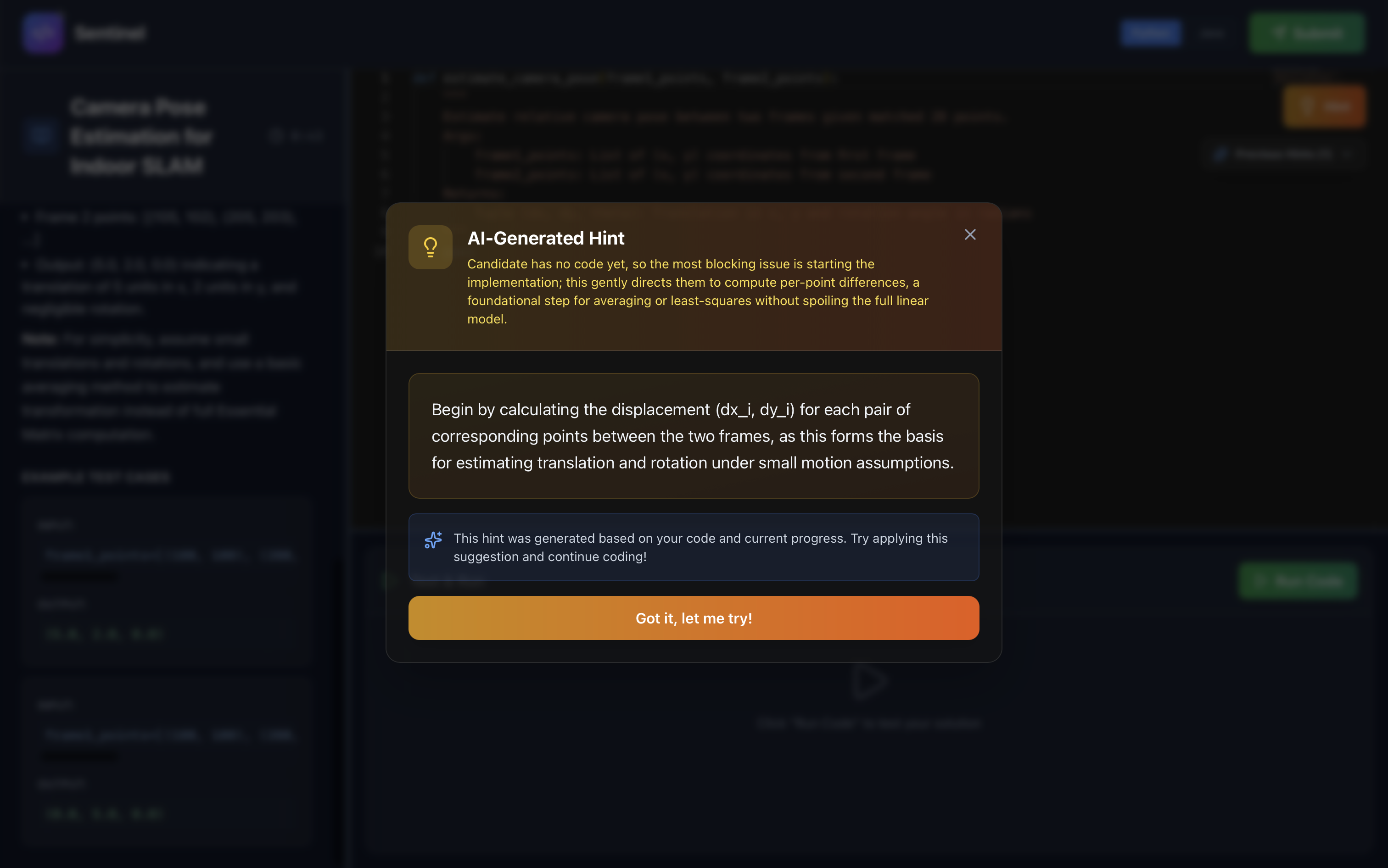
Hint System:
- Context-aware: Grok analyzes current code to provide relevant hints
- All hints tracked and factored into evaluation
Real-Time Code Execution:
- Run Python/Java code against test cases
- Detailed output with pass/fail status
- Error detection
- Execution timeout handling
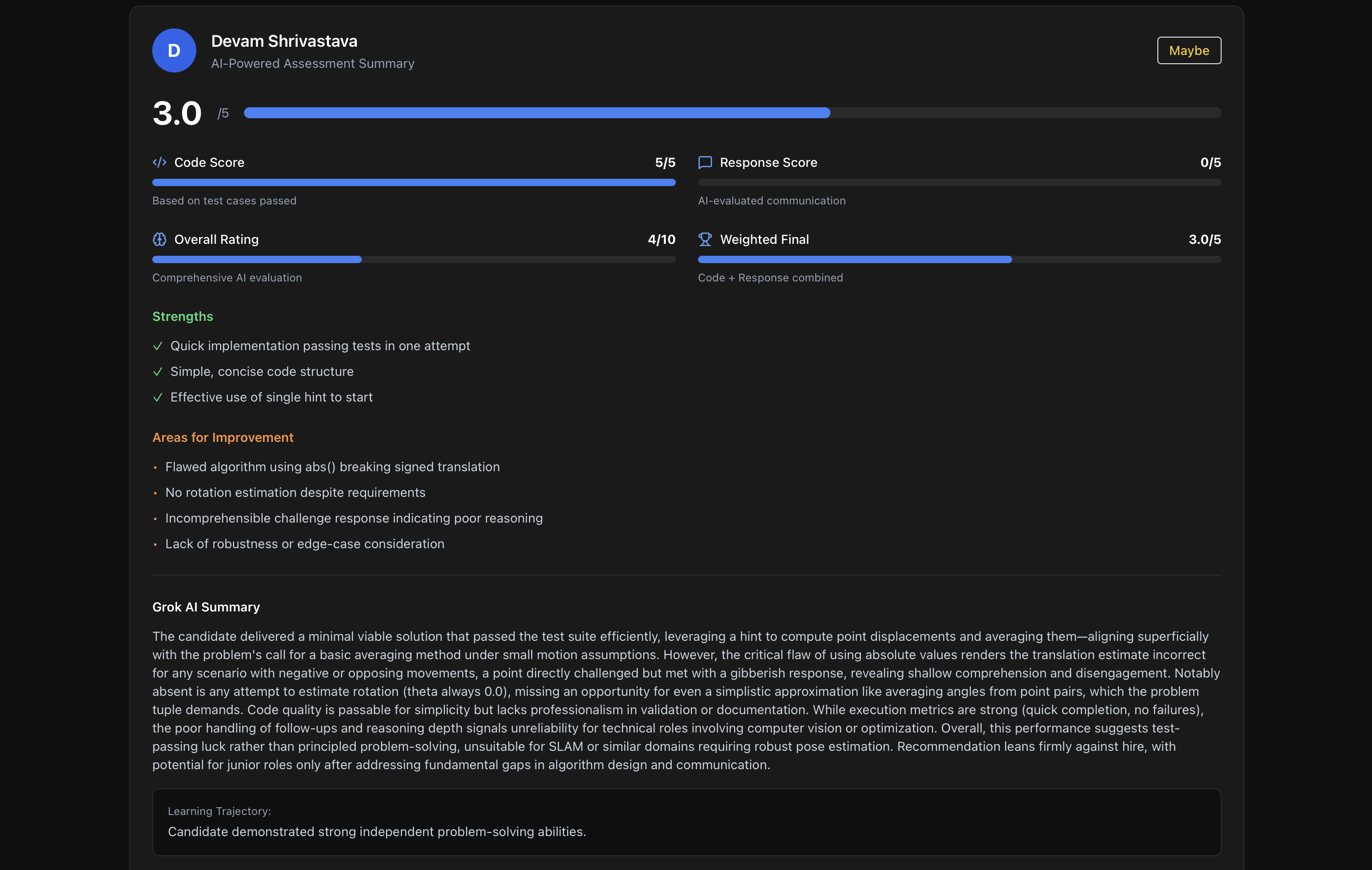
Dual-Dimensional Evaluation
Traditional assessments only measure code correctness. Sentinel evaluates code quality AND communication:
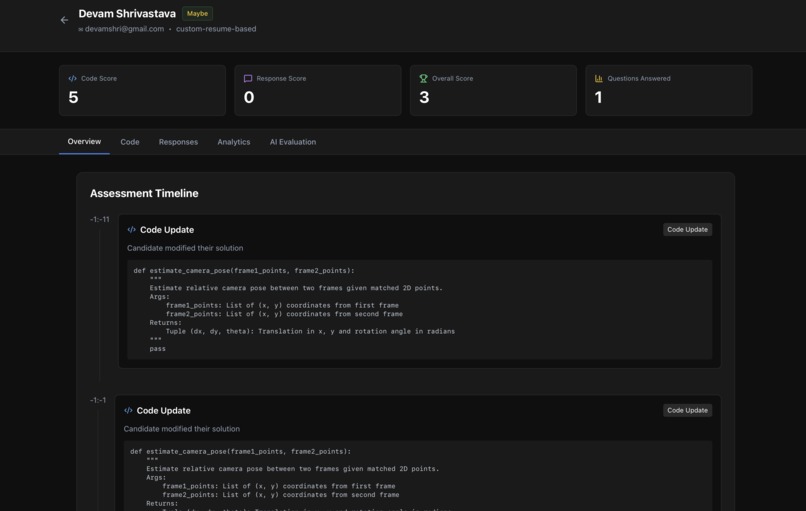
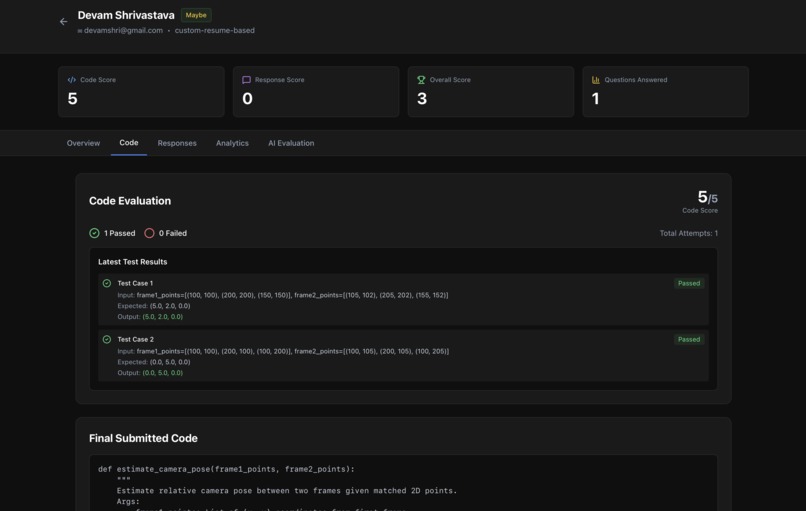
Code Score:
- Test cases passed vs total
- Algorithm efficiency and time complexity
- Code readability and structure
- Edge case handling
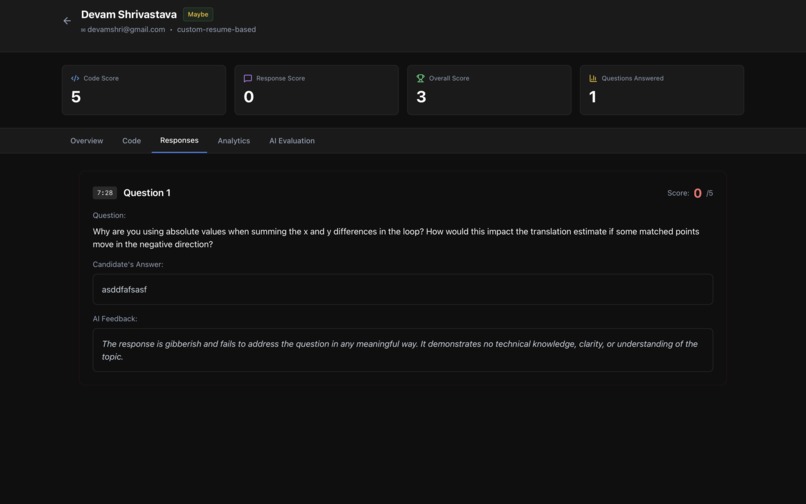
Response Score:
- Grok AI analyzes all challenge question responses individually for:
- Technical accuracy and correctness
- Depth of understanding and reasoning
- Clarity of explanation
- Communication effectiveness
- Averages scores across all challenge responses
Weighted Final Score:
- Default: 60% code, 40% response (recruiter-adjustable)
- Dynamic recalculation in real-time
Hiring Recommendation Thresholds:
- ≥ 4.5: "Strong Hire" (top 10% candidates)
- ≥ 3.5: "Hire" (solid performer)
- ≥ 2.5: "Maybe" (borderline, needs discussion)
- < 2.5: "No Hire" (below bar)
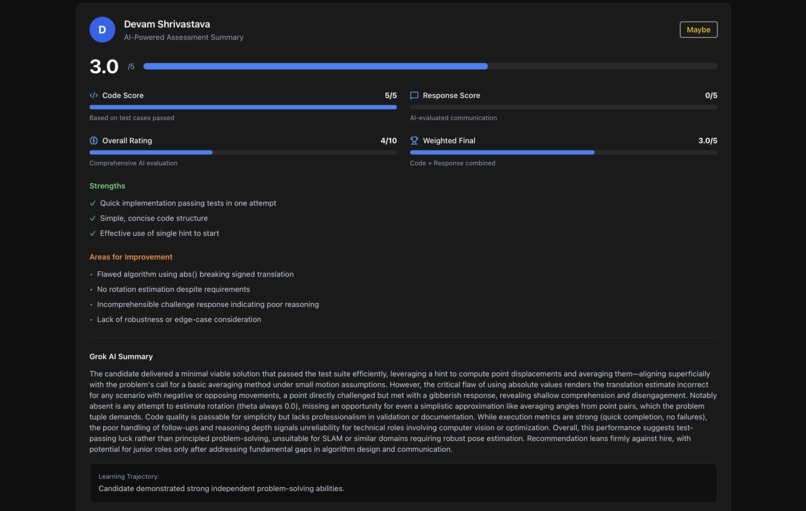
Comprehensive AI Evaluation Report:
- Recommendation: Strong Hire / Hire / Maybe / No Hire (with confidence %)
- Overall Rating: 1-10 scale
- Technical Evaluation:
- Problem understanding
- Algorithm choice
- Code quality assessment
- Correctness analysis
- Debugging ability
- Adaptability Analysis:
- Performance on challenge questions
- Ability to generalize solutions
- Depth of technical reasoning
- Communication Assessment:
- Clarity of explanations
- Responsiveness to feedback
- Discussion of tradeoffs
- Execution Metrics: Time to complete, hints used, iterations
- Strengths & Weaknesses
- Grok Detailed Feedback
Complete Workflow
End-to-End in 8 Steps:
- Discover → Recruiter enters job description, gets 50-100+ ranked candidates with emails/GitHub
- Review → Browse discovered profiles with X posts, GitHub links, social media
- Invite → Generates unique token and sends email
- Verify → Candidate clicks link, enters name/email, uploads resume
- Generate → Grok analyzes resume and creates custom problem matched to background
- Assess → Candidate codes with Monaco editor, monitoring active every 15s, challenge questions auto-generate
- Complete → All TODOs answered, code submitted, immediate dual-score evaluation
- Decide → Comprehensive report available with dual scores, AI insights, code evolution timeline, hiring recommendation
Tech Stack
Frontend
- React + TypeScript for type-safe component architecture
- Vite for sub-second HMR and optimized production builds
- TailwindCSS for responsive, glassmorphic design system
- Monaco Editor (VS Code's editor) for professional code editing experience
Backend
- FastAPI for high-performance async Python APIs
- Grok AI via xAI SDK (grok-beta, grok-4-1-fast-reasoning models)
- X API via xdk for candidate discovery from Twitter/X
- GitHub REST API for profile enrichment and email extraction
- PyPDF2 for PDF resume parsing
- Pydantic for request/response validation
Challenges we ran into
1. X API Rate Limits (450 requests / 15 min)
Problem: Detailed searches burn through rate limits fast when checking multiple queries.
Solution:
- Progressive broadening strategy (start specific, gradually broaden)
- Batch user lookups (100 usernames per request saves 99 API calls)
- Early termination when target candidate count reached
2. GitHub Email Extraction (80% hide public emails)
Problem: Most developers don't expose emails on their GitHub profile.
Solution:
- Scan commit history across user's repositories (up to 5 repos)
- Extract from
commit.author.emailmetadata (first 5 commits per repo) - Filter out noreply addresses (
*@users.noreply.github.com) - Fallback to email from GitHub profile if available
3. Real-Time RL Monitoring Without Latency
Problem: Tracking every keystroke would crush performance and UX.
Solution:
- Debounced code change logging (2-second delay after typing stops)
- Client-side event buffering with periodic batch uploads
- React refs instead of state for high-frequency updates (avoids re-renders)
- Background processing for analytics and snapshots
- Fixed 15-second monitoring interval (not continuous)
4. Consistent JSON Responses from Grok
Problem: LLMs sometimes return JSON wrapped in markdown (`json), with extra text, or malformed.
Solution:
- Explicit prompt instructions: "Return ONLY a JSON object, no markdown, no explanation"
- Regex extraction:
re.search(r'\{.*\}', response, re.DOTALL)to extract from any format - Validation layer with Pydantic to catch malformed data
- Graceful fallbacks when parsing fails
5. Balancing Adaptive Hints vs Assessment Integrity
Problem: Hints should help stuck candidates without giving away the solution.
Solution:
- Context-aware generation: Grok analyzes current code to provide targeted hints
- All hints tracked and factored into final evaluation
- Hints require explicit request
Accomplishments that we're proud of
True End-to-End AI Integration: Grok powers certain critical decisions—JD parsing, candidate ranking, resume analysis, question generation, hint creation, challenge generation, and comprehensive evaluation. It's not "AI-assisted," it's AI-native.
Organic Candidate Discovery from X: Built a working system that discovers developers based on their actual activity on X/Twitter, not resume keywords. Watching it find PyTorch contributors, extract GitHub profiles, and mine commit history for emails was awesome.
Production RL System: Implemented a full contextual bandit with 9-dimensional state space, 7 actions, epsilon-greedy exploration, real-time weight updates, and training data collection. This isn't a research paper—it's running in production.
Resume-Based Personalization: Each candidate gets a completely unique problem generated by analyzing their actual resume. The problems use technologies they've worked with and match their experience level. This is genuinely novel.
Comprehensive Evaluation Reports: Grok analyzes the entire assessment session—code evolution, hints used, challenge responses, execution attempts—and generates detailed reports with specific strengths, weaknesses, and hiring recommendations.
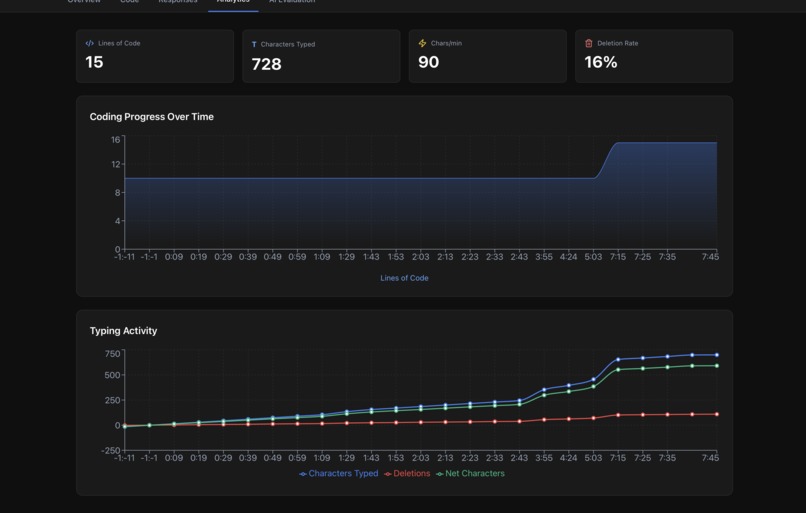
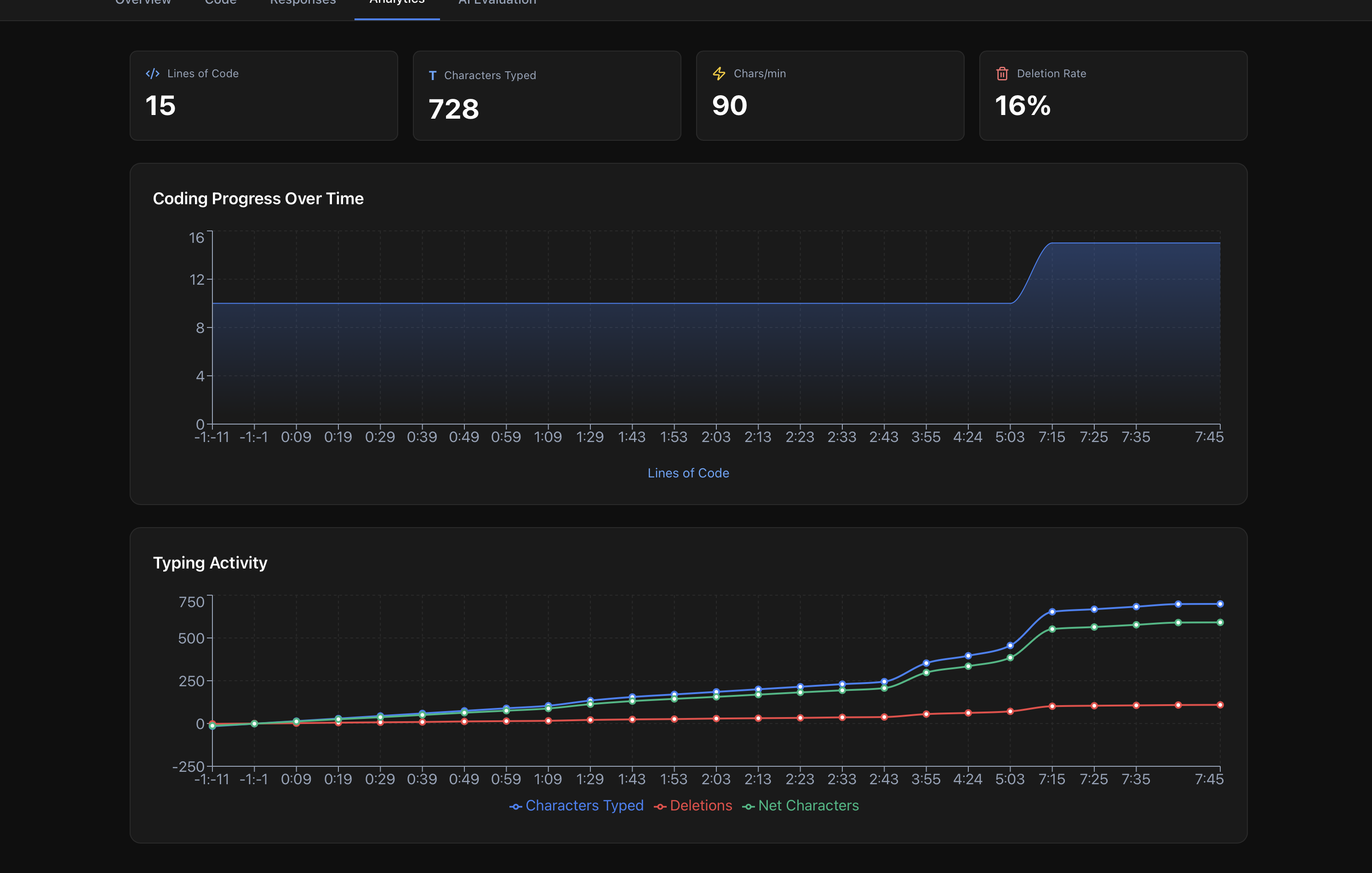
Detailed Behavioral Analytics: Built comprehensive tracking system that captures:
- Characters typed vs deleted (reveals backtracking patterns)
- Keystroke count and typing velocity
- Code snapshots every 10 seconds with timestamps
- Code complexity evolution over time
- Lines written and meaningful changes
Smart Challenge Generation: Context-aware TODO system that detects meaningful code changes (10+ lines, new data structures, algorithmic shifts) and generates specific, targeted follow-up questions—not generic prompts. The 30-second cooldown prevents spam while the 15-second monitoring interval ensures responsiveness.
What we learned
Grok Excels at Complex Multi-Step Reasoning: It's exceptional at analyzing unstructured data (resumes, code, discussion responses), generating structured JSON with proper prompting, and providing nuanced evaluation. We used grok-beta for creative tasks and grok-4-1-fast-reasoning for structured outputs.
X is an Untapped Goldmine for Technical Recruiting: Developers actively share their work, discuss technologies, and link to GitHub. Posts mentioning tech + GitHub = high-quality signals. This channel is vastly underutilized by recruiters.
Prompt Engineering is Critical: Explicit formatting ("Return ONLY JSON"), temperature tuning (0.3 vs 0.7), regex extraction, and validation layers transform inconsistent LLM outputs into reliable structured data. We iterated 20+ times on key prompts.
React + FastAPI is Great for AI Apps: FastAPI's async support handles concurrent Grok calls beautifully. React hooks make complex state management elegant. TypeScript catches integration bugs before runtime.
What's next for Sentinel
- Team Collaboration: Multiple recruiters can review, comment, and discuss assessments with real-time updates
- Webhook Notifications: Real-time alerts via Slack/Discord when candidates complete assessments
- Multi-Language Support: JavaScript, Go, Rust, C++, TypeScript execution environments
- Interview Scheduler: Integrated calendar for seamless post-assessment interviews
Built With
- fastapi
- github
- grok
- monaco
- pydantic
- python
- react
- recharts
- smtp
- sqlite
- tailwind
- typescript
- vite
- xai
- xdk

Log in or sign up for Devpost to join the conversation.