-

Banner
-
Overview
-
Splash Screen
-
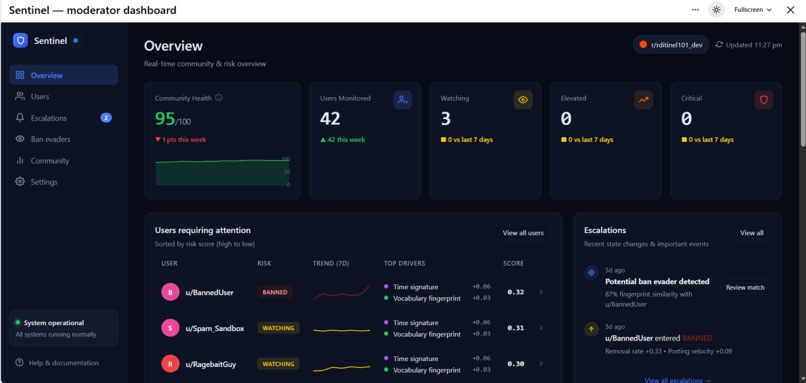
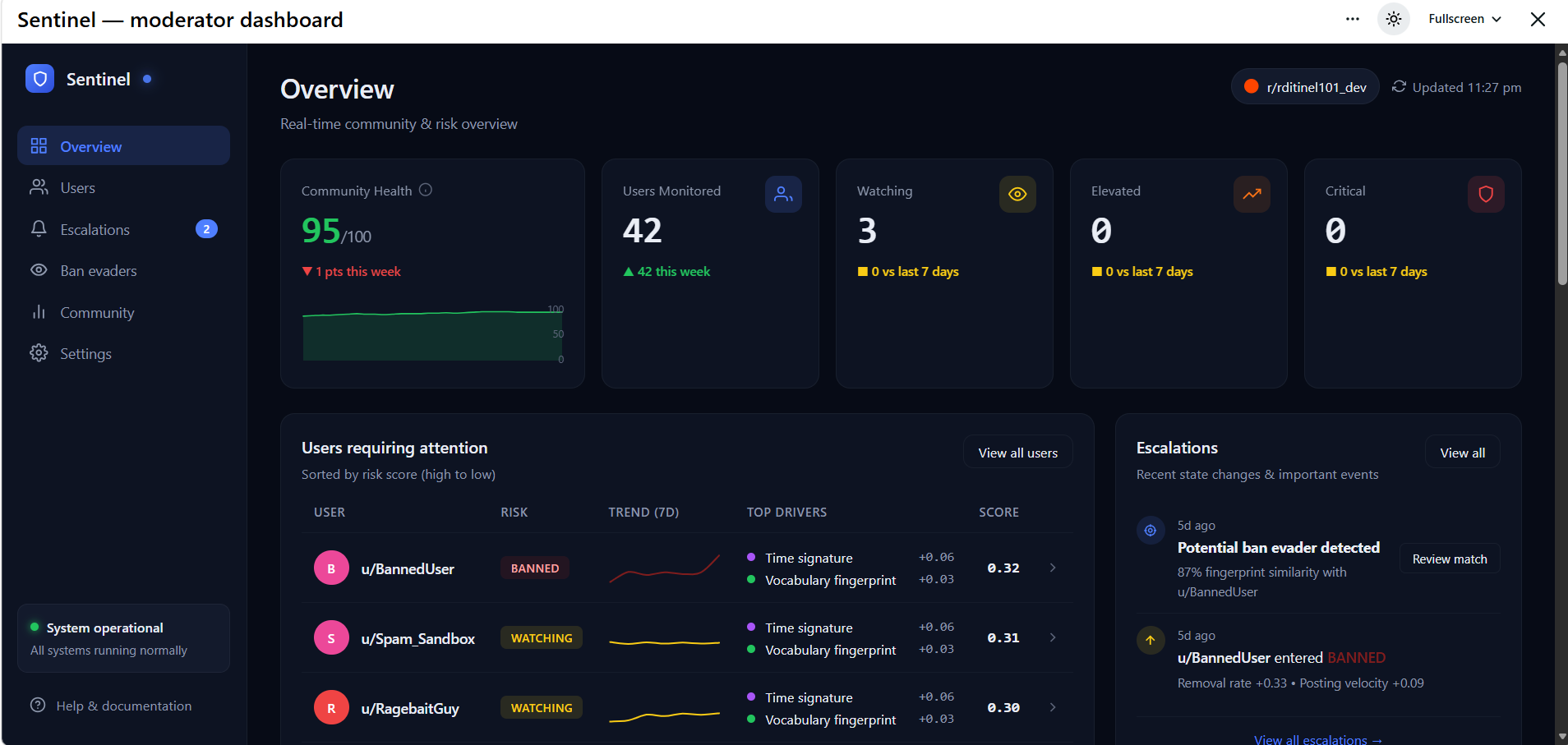
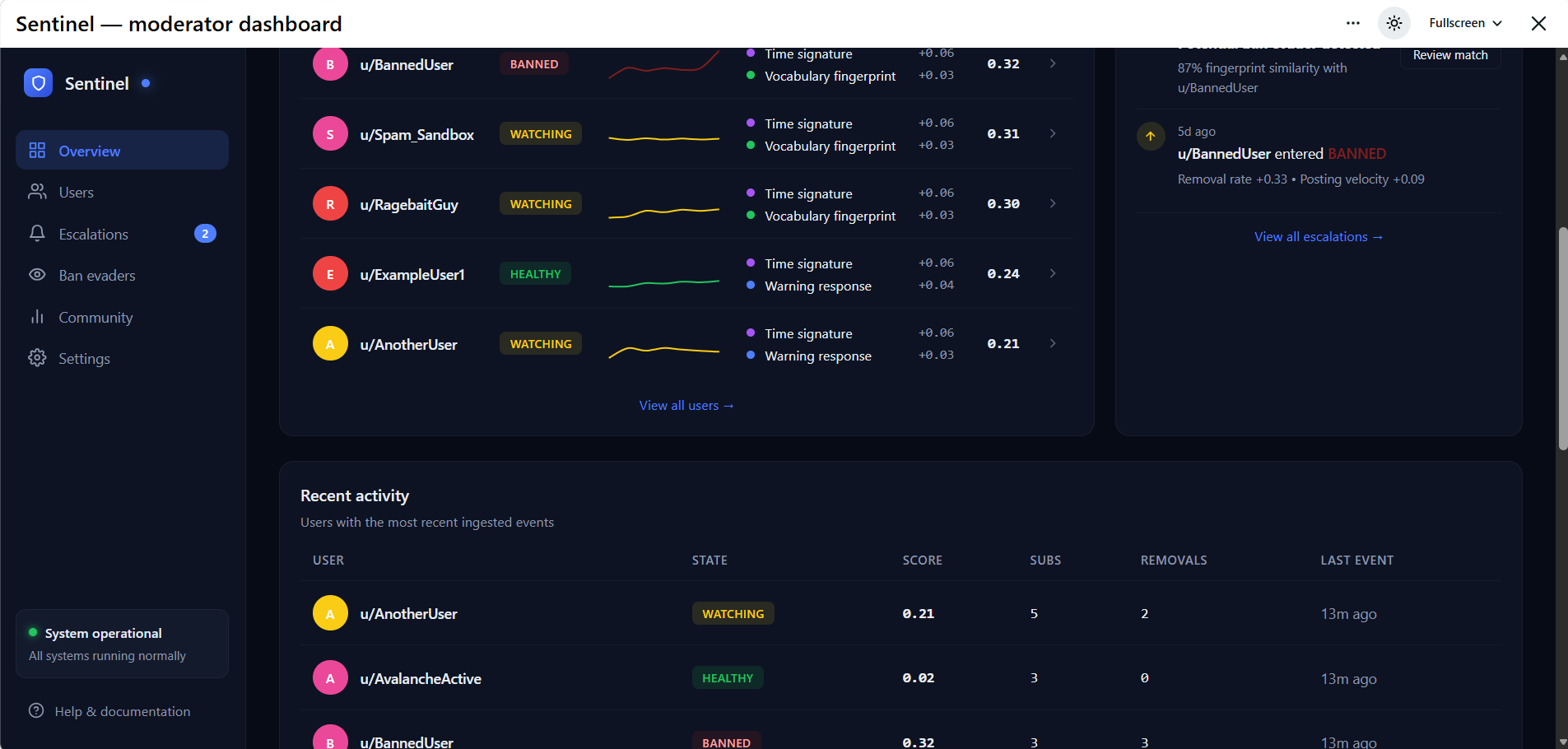
Dashboard with historical seeded user data
-
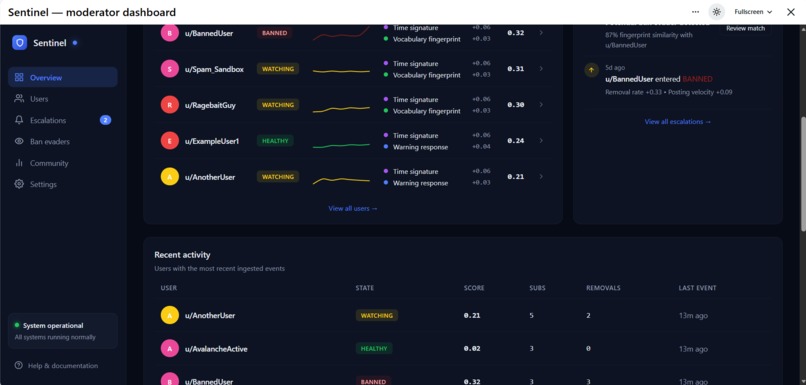
Scores calculated on the basis of 30 days historical seeded data
-
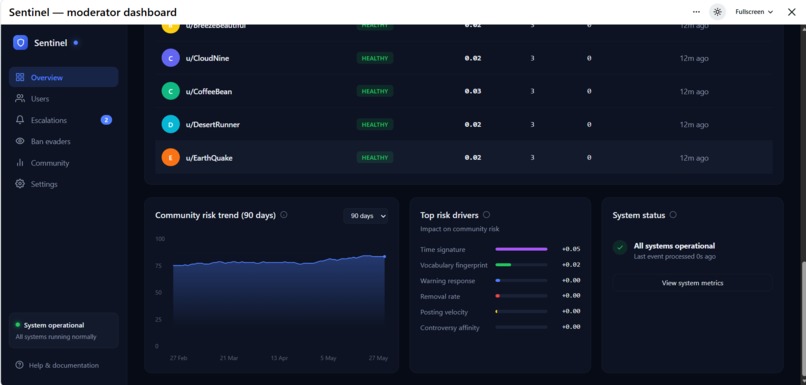
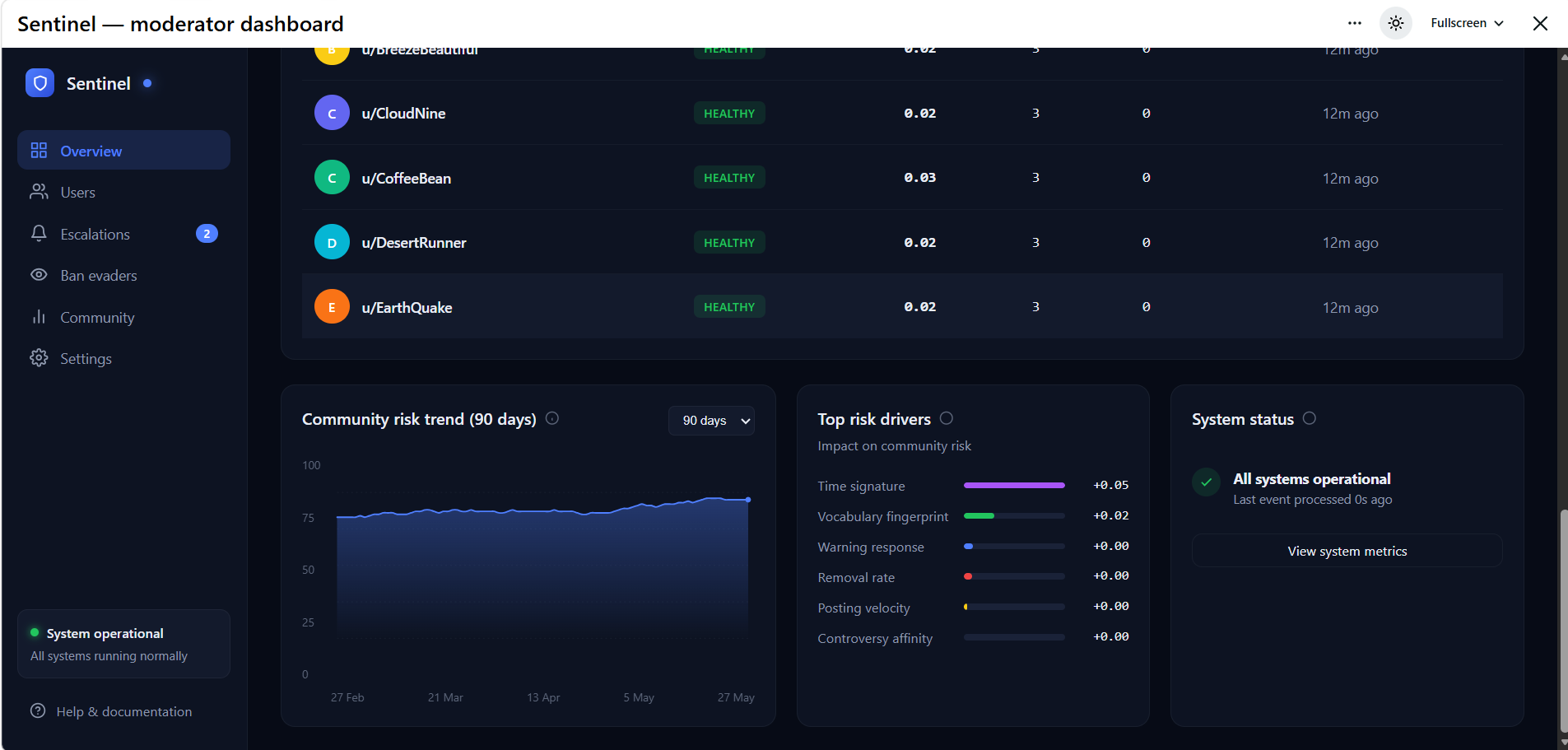
Risk Drivers
-
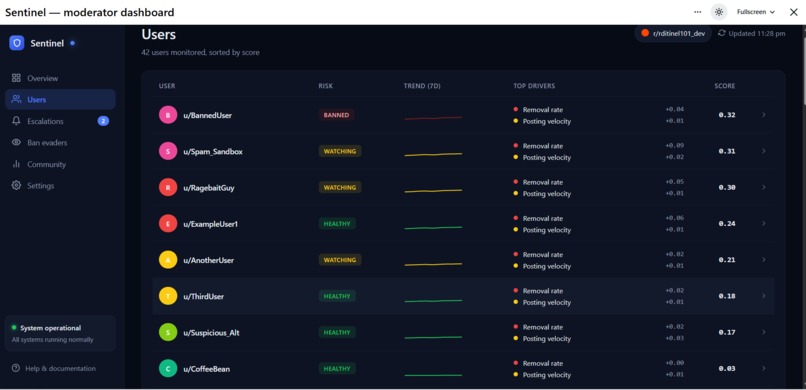
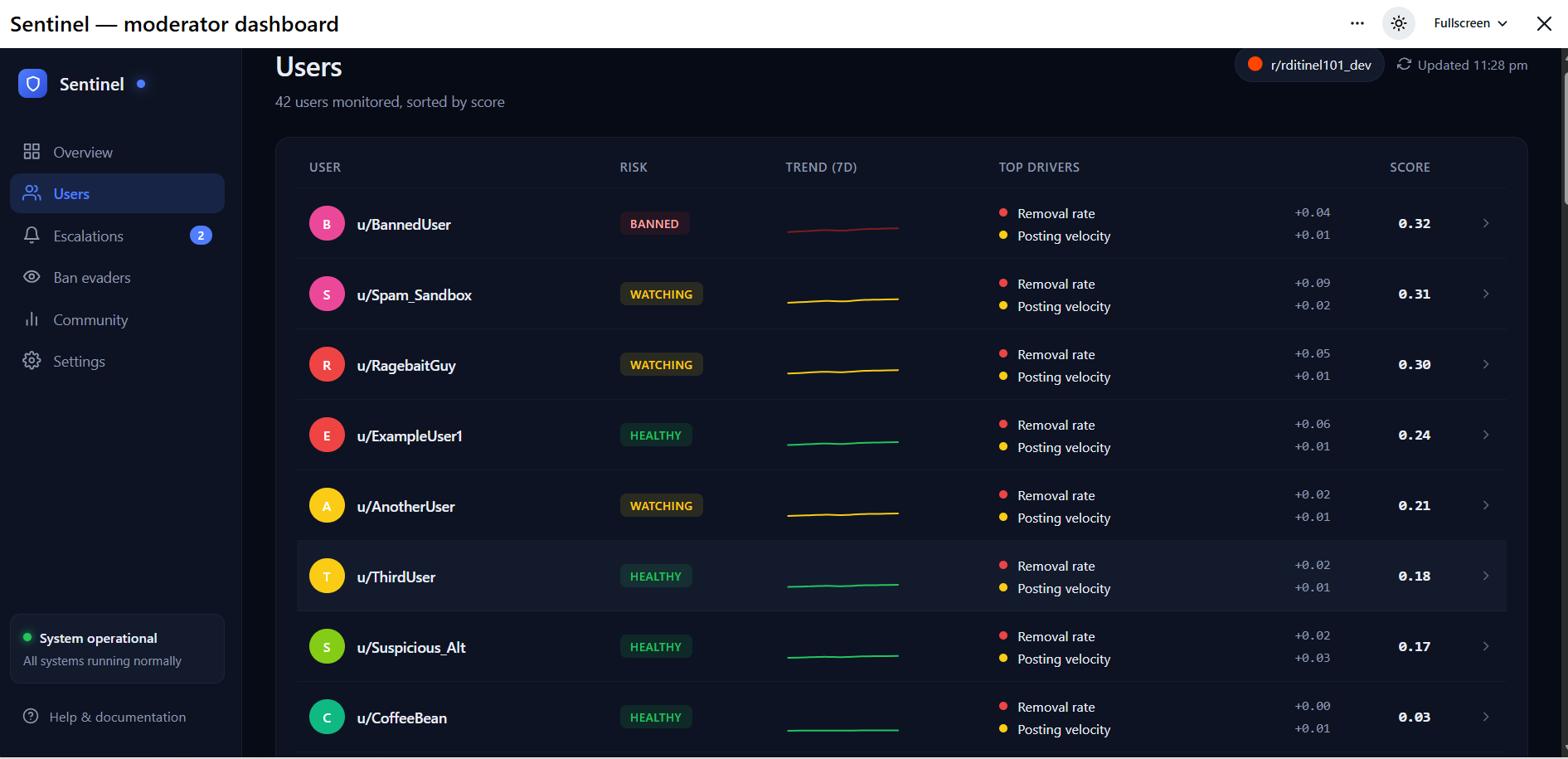
Users
-
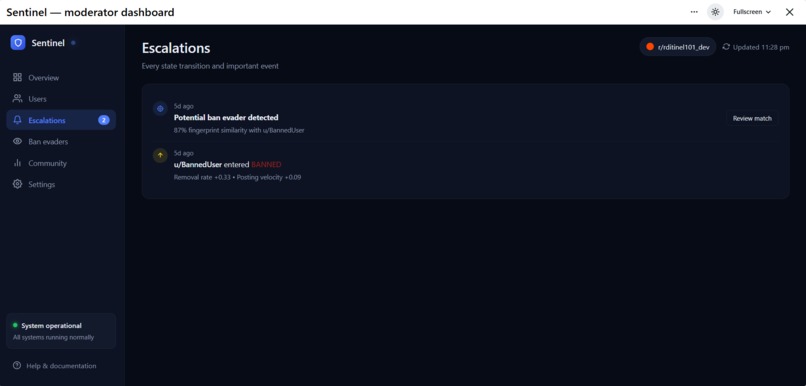
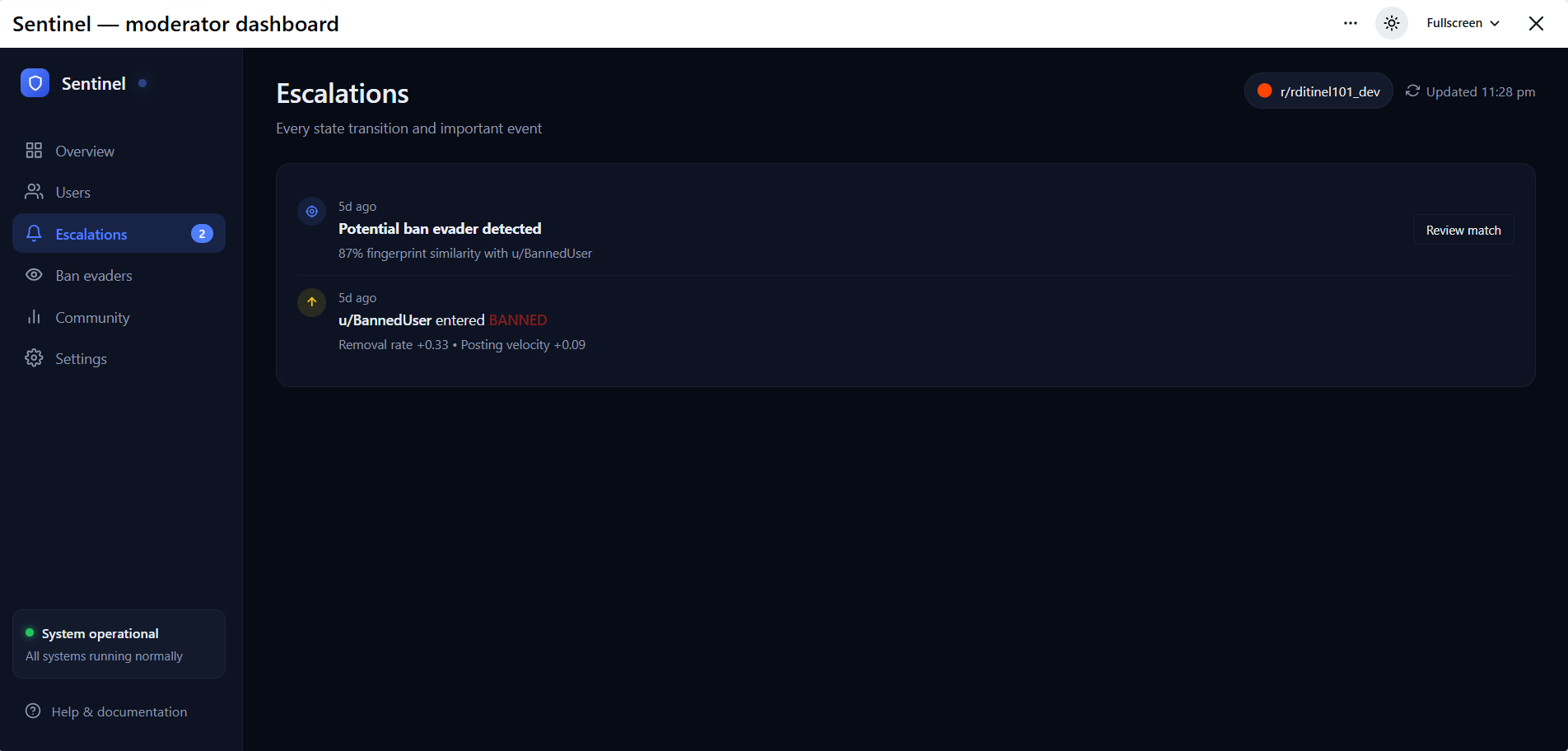
Escalation Notification
-
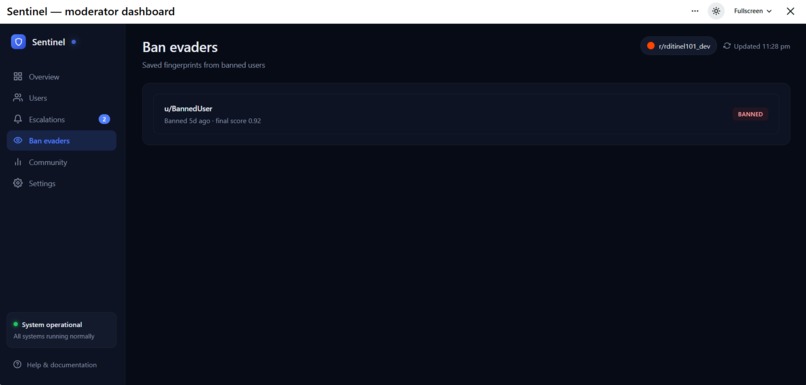
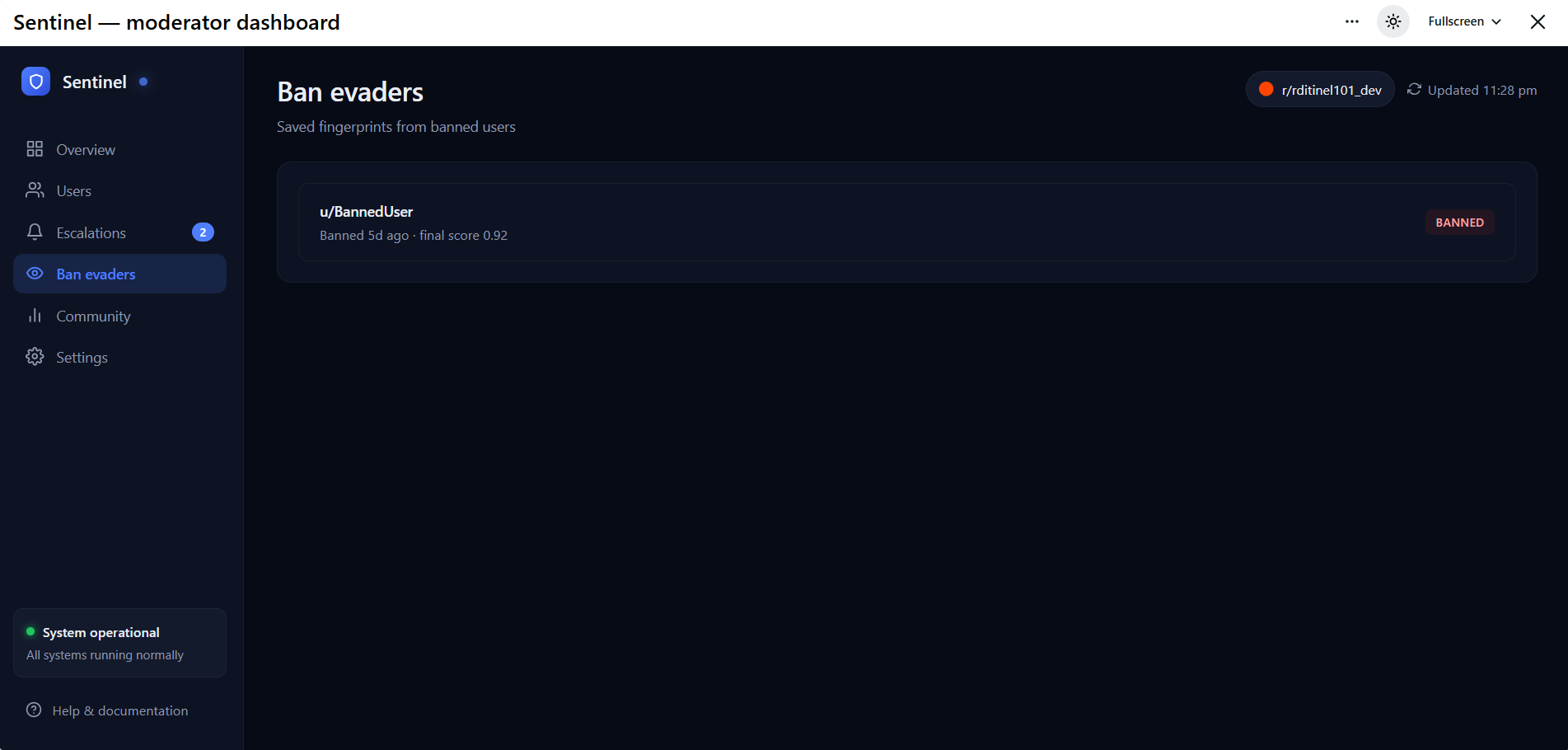
Ban Users and Evaders
-
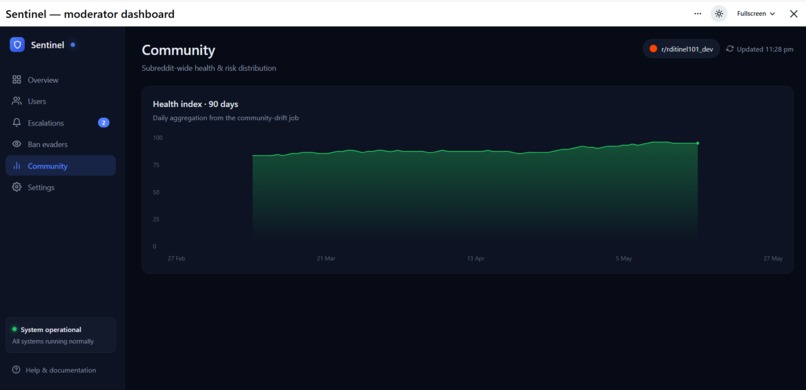
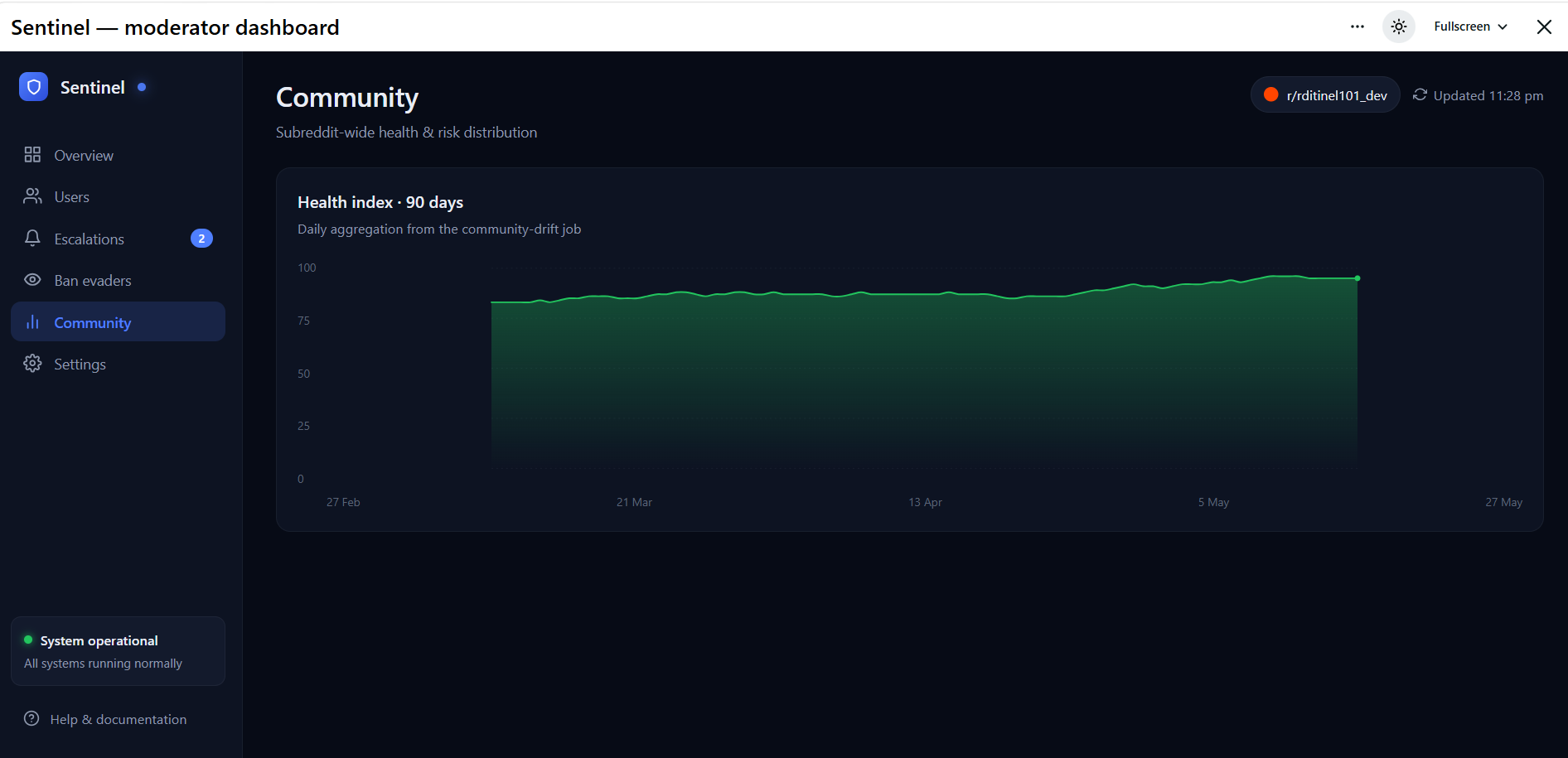
Community Health Index
-
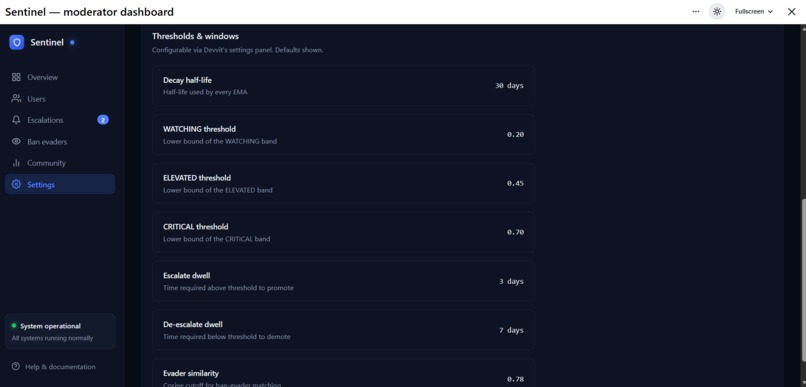
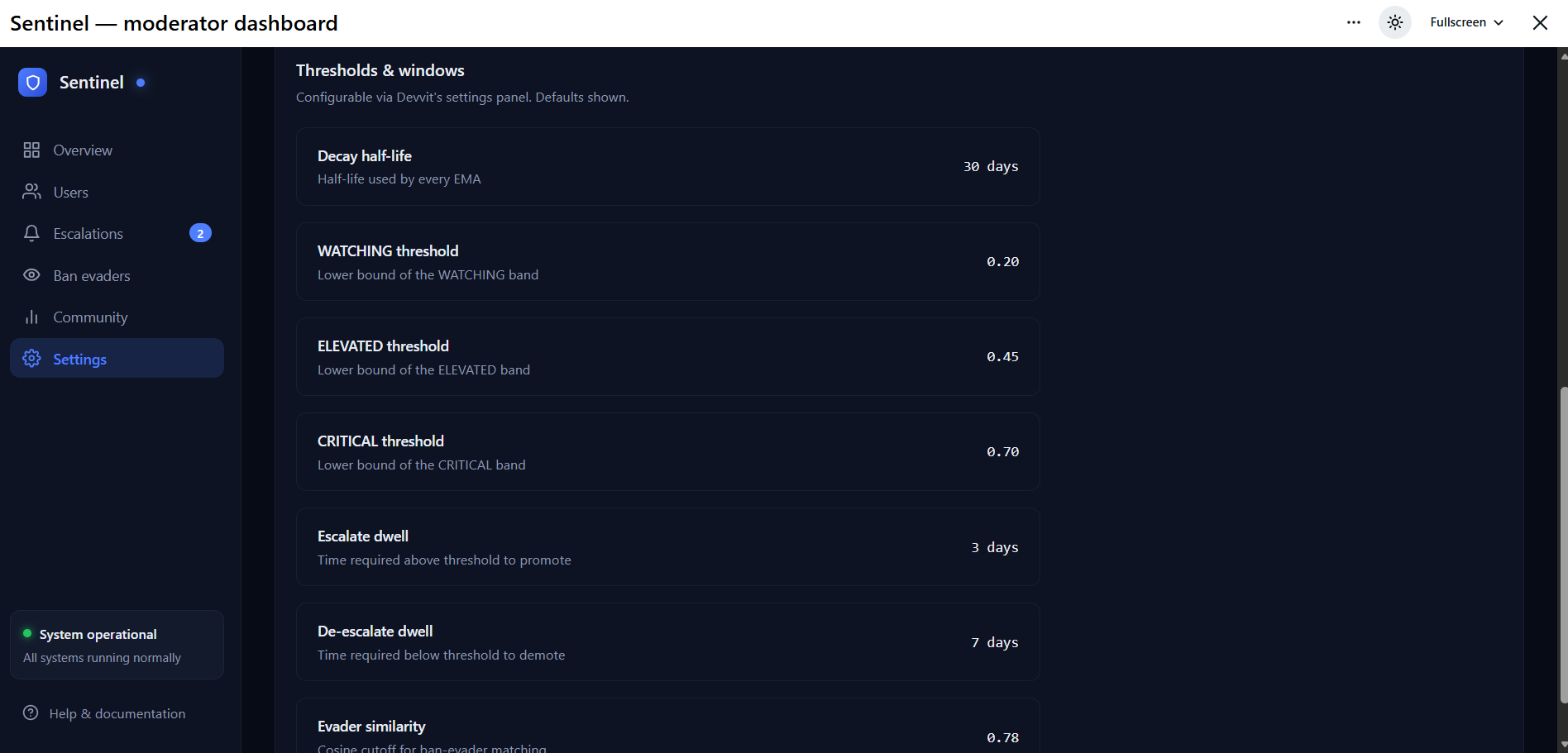
Settings

Sentinel
Inspiration
Every mod team has the same frustration: the queue catches rule-breakers after the damage is done. By the time a user gets banned, they've already poisoned a thread or run a weeks-long harassment campaign that never surfaced because each individual post was borderline.
The real problem isn't identifying bad content — Reddit's report system handles that reasonably well. The problem is identifying users whose behavior is trending toward bad before they cross the line. A user who had 10% of their posts removed six months ago and now has 60% removed is a completely different risk profile than one who's been at 60% since day one. The trend is the signal. The snapshot is noise.
That's what Sentinel is: a trajectory tracker, not a content filter.
What I Built
Sentinel maintains a six-dimensional behavioral feature vector for every user, updated in real time as events fire:
| Feature | What it measures |
|---|---|
removalRate |
EMA of mod-removed content over time |
warningResponse |
Did removal rate go up or down after a mod warning? |
controversyAffinity |
How often does the user engage on flagged/locked threads? |
velocity |
Posting rate — rising activity often precedes rising risk |
timeSignature |
Concentration of posting hours — scripted accounts cluster tightly |
vocabularyFingerprint |
TF-IDF distinctiveness vs subreddit baseline (character n-grams) |
Every feature is an exponentially-weighted moving average with a configurable half-life:
$$EMA_t = \alpha x_t + (1 - \alpha) EMA_{t-1}$$
where \( \alpha = 1 - 2^{-1/\text{halfLife}} \). With a 30-day half-life, a removal from a year ago contributes \( 2^{-365/30} \approx 0.00006 \) to today's score — effectively zero, without any explicit pruning. A user clean for a year but deteriorating for two weeks shows a rising score, not a flat one masked by their long history.
The six features are weight-summed into a single composite score \( s \in [0, 1] \):
$$s = \sum_{i} w_i \cdot f_i, \qquad \sum_i w_i = 1$$
Weights are chosen so no single feature can trigger an alert alone — the maximum single-feature contribution is \( 0.30 \) (removalRate), well below the WATCHING threshold of \( 0.20 \) when all others are zero. Real risk requires multiple axes rising together.
A hysteretic state machine (HEALTHY → WATCHING → ELEVATED → CRITICAL → BANNED) requires a score to stay above a threshold for 3 days before escalating, and below for 7 days before de-escalating. This kills false positives from one-off bad weeks.
When a user is banned, their hour-of-day histogram and character n-gram TF-IDF vector are saved as a fingerprint. New accounts are cosine-similarity matched against every saved fingerprint — ban evaders tend to keep their posting schedule and writing style even after changing usernames.
How I Built It
The architecture is deliberately minimal: a plain Node HTTP server, a single router switch, one ingest pipeline that every trigger funnels into, and pure functions for all the algorithms. No framework, no ORM, no external APIs.
Devvit triggers / menu / scheduler
↓
router.ts (URL switch)
↓
ingest.ts (single chokepoint)
↓
core/features.ts → core/score.ts → core/state.ts
↓
storage/ (Redis via Devvit client)
↓
alerts.ts (dedup-aware modmail / modnotes)
The dashboard is two vanilla TypeScript SPAs — no React, no framework beyond esbuild. A single h() DOM builder and typed fetch wrappers share the same ApiEndpoint constants as the server, so a renamed route is a compile error on both sides simultaneously.
The test suite covers every algorithm module with pure-function tests — no mocks, no Redis, no network. 82 tests run in under 600ms.
Challenges
The EMA responsiveness problem. A 30-day half-life means \( \alpha \approx 0.023 \). One removal pushes removalRate from 0 to ~0.023 — invisible in the dashboard during testing. The fix was a blended scoring approach: during early activity the score mixes the EMA-based composite with a direct removal ratio, with the direct weight fading as history accumulates:
$$s_{\text{blended}} = s_{\text{EMA}} \cdot (1 - w_d) + \frac{\text{removals}}{\text{totalEvents}} \cdot w_d$$
where \( w_d = \max(0,\ 0.6 - \frac{n - n_{\min}}{80}) \). This makes the system immediately responsive to obvious patterns while preserving long-term trajectory tracking.
Devvit's event taxonomy is messier than the docs suggest. onPostDelete fires for both user self-deletes and as a secondary event alongside onModAction → removelink. Without deduplication, every mod removal was being double-counted. The fix required classifying the source field:
source = "USER"→ self-delete: ingested as a weak signal (observation weight 0.3)source = 0 / undefined→ mod-removal secondary: skipped to avoid double-counting
Self-deletes and mod-removals now have genuinely different weights in the algorithm. A user who cleans up their own posts is a weaker signal than one whose posts are being removed by mods.
The hysteresis dwell vs. immediate feedback tension. The 3-day escalation dwell is correct for production — it prevents a single bad day from flagging a long-standing contributor. But during testing it made the system look broken: 3 posts removed, score clearly elevated, state still HEALTHY. The solution was to bypass the dwell for high-confidence scores (\( s \geq 0.35 \)) so obvious cases commit immediately, while borderline scores still wait out the window.
No confirm() in Devvit's webview sandbox. The reset button silently did nothing because confirm() always returns false inside Devvit's iframe. Replaced with a two-tap confirmation pattern — first tap changes the button label, second tap within 4 seconds executes.
What I Learned
The most interesting insight is how much signal is already in the data mods can already see — no LLM, no sentiment analysis, no external enrichment needed. The combination of removal rate trend, warning response, and posting rhythm is surprisingly predictive. The academic literature on community moderation backs this up: a user's response to enforcement is the dominant predictor of future violations, which is why warningResponse carries the second-highest weight (0.22) in the composite score.
I also learned that "decay on read" is a genuinely elegant pattern for this kind of system. Instead of running a daily batch job to update every user's score, each user's EMA is lazily decayed forward when their record is read. Redis cost scales with active users, not population size — a subreddit with 100,000 members but only 500 active in the last month pays for 500 records, not 100,000.
Built With
- api
- devvit
- esbuild
- node.js
- redis
- trigger
- typescript

Log in or sign up for Devpost to join the conversation.