-
-
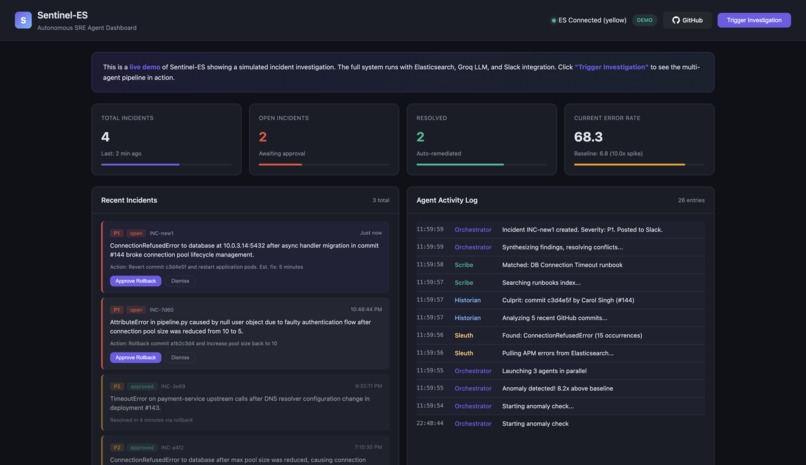
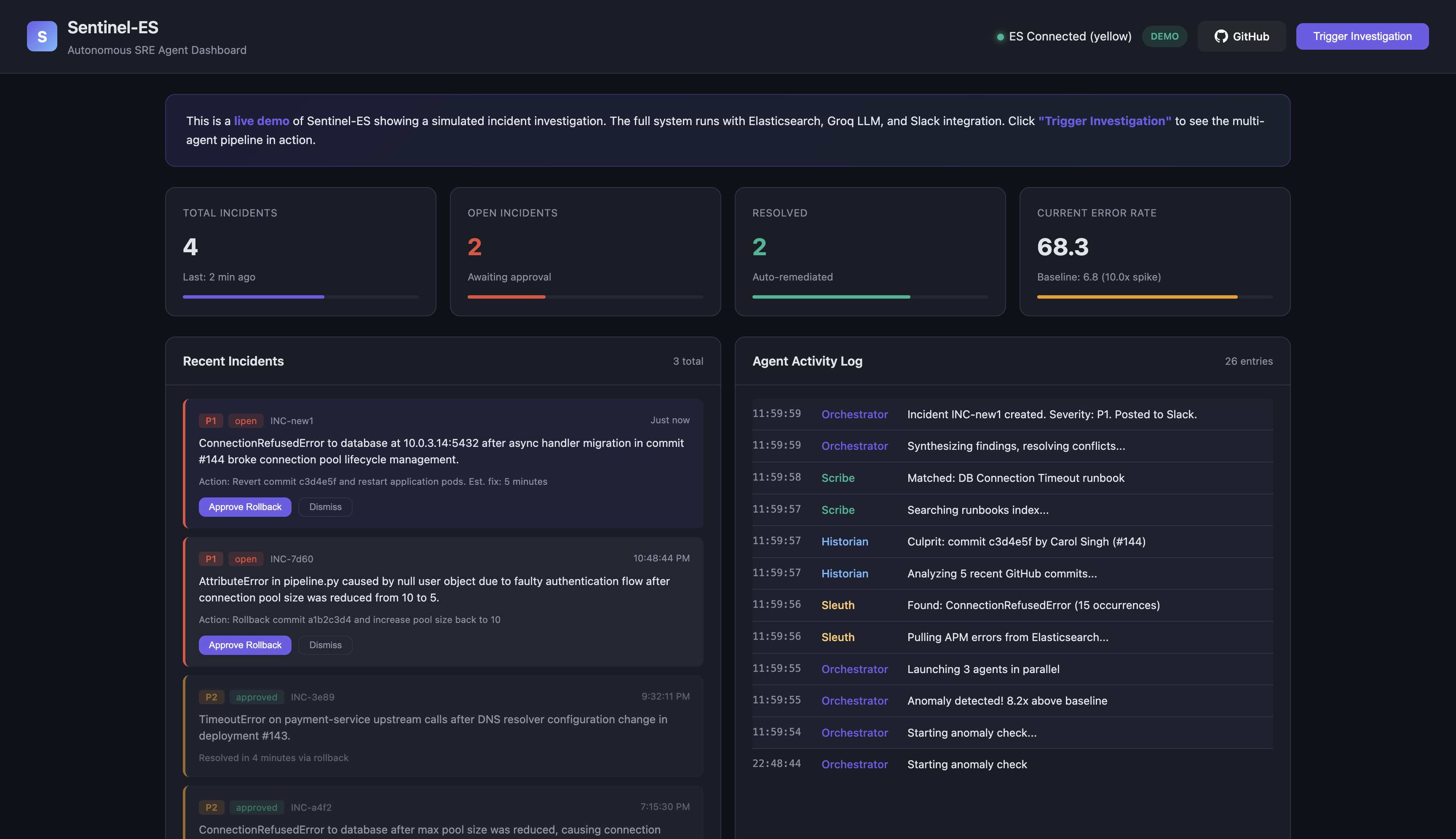
Live incident investigation dashboard
-
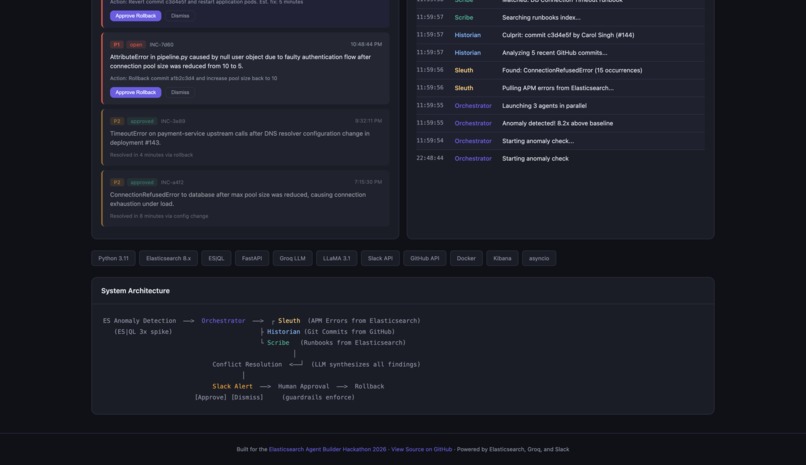
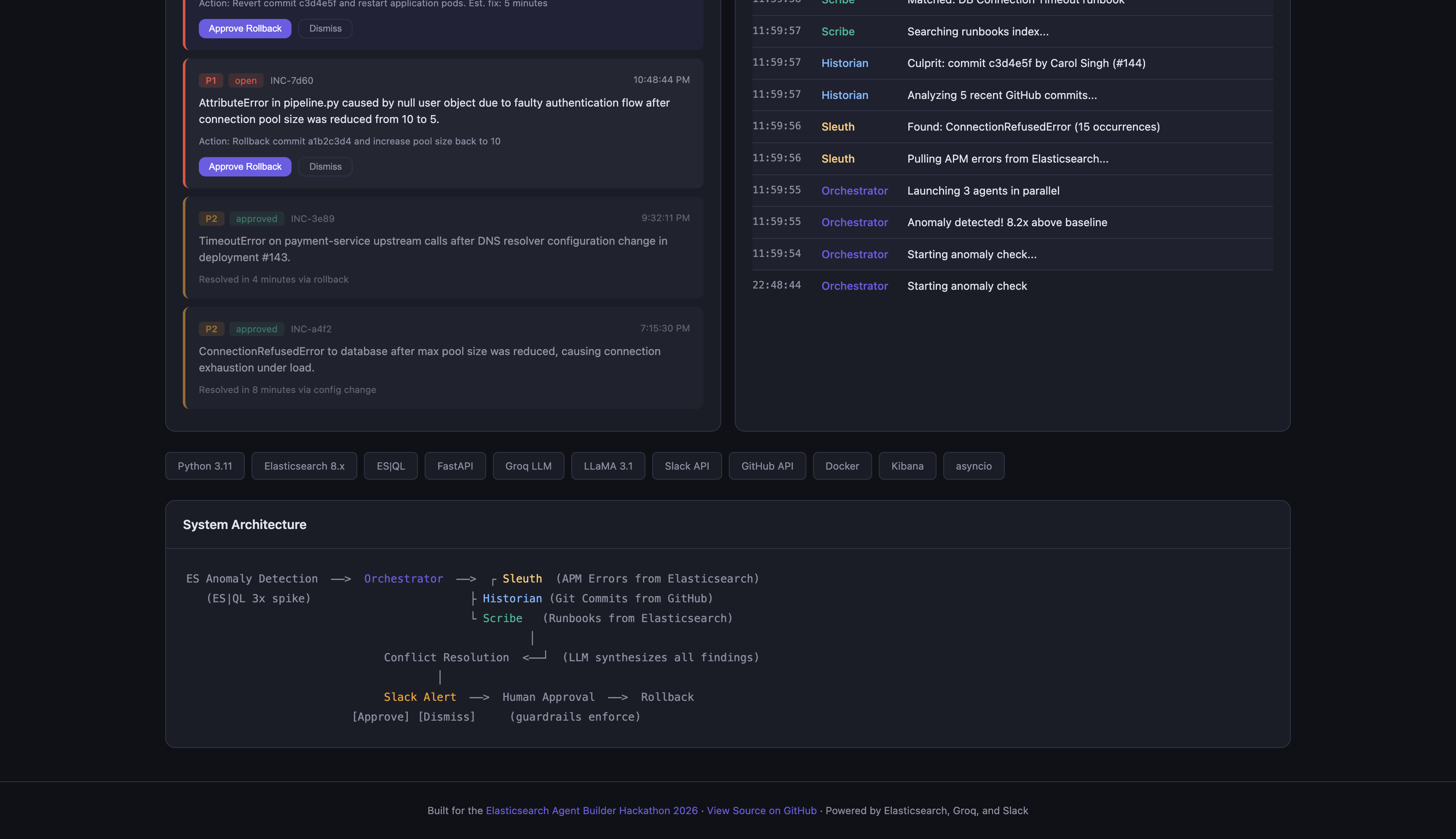
Architecture and tech stack
-
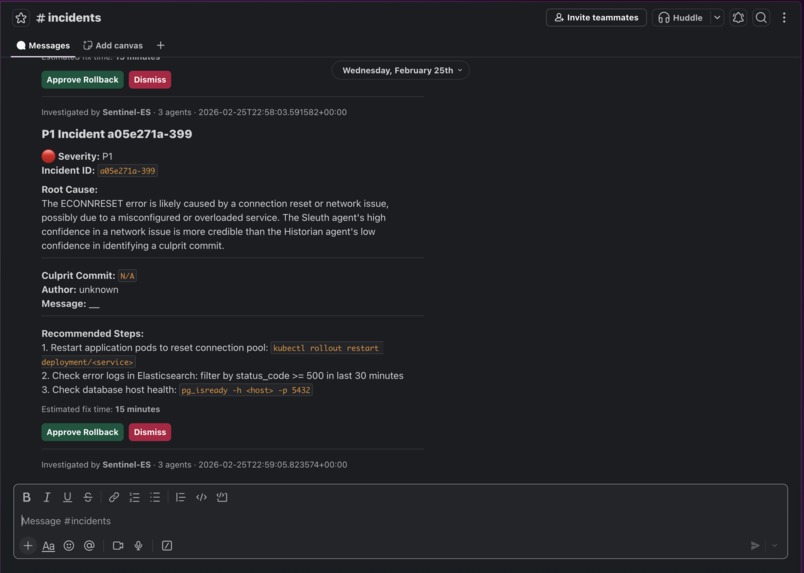
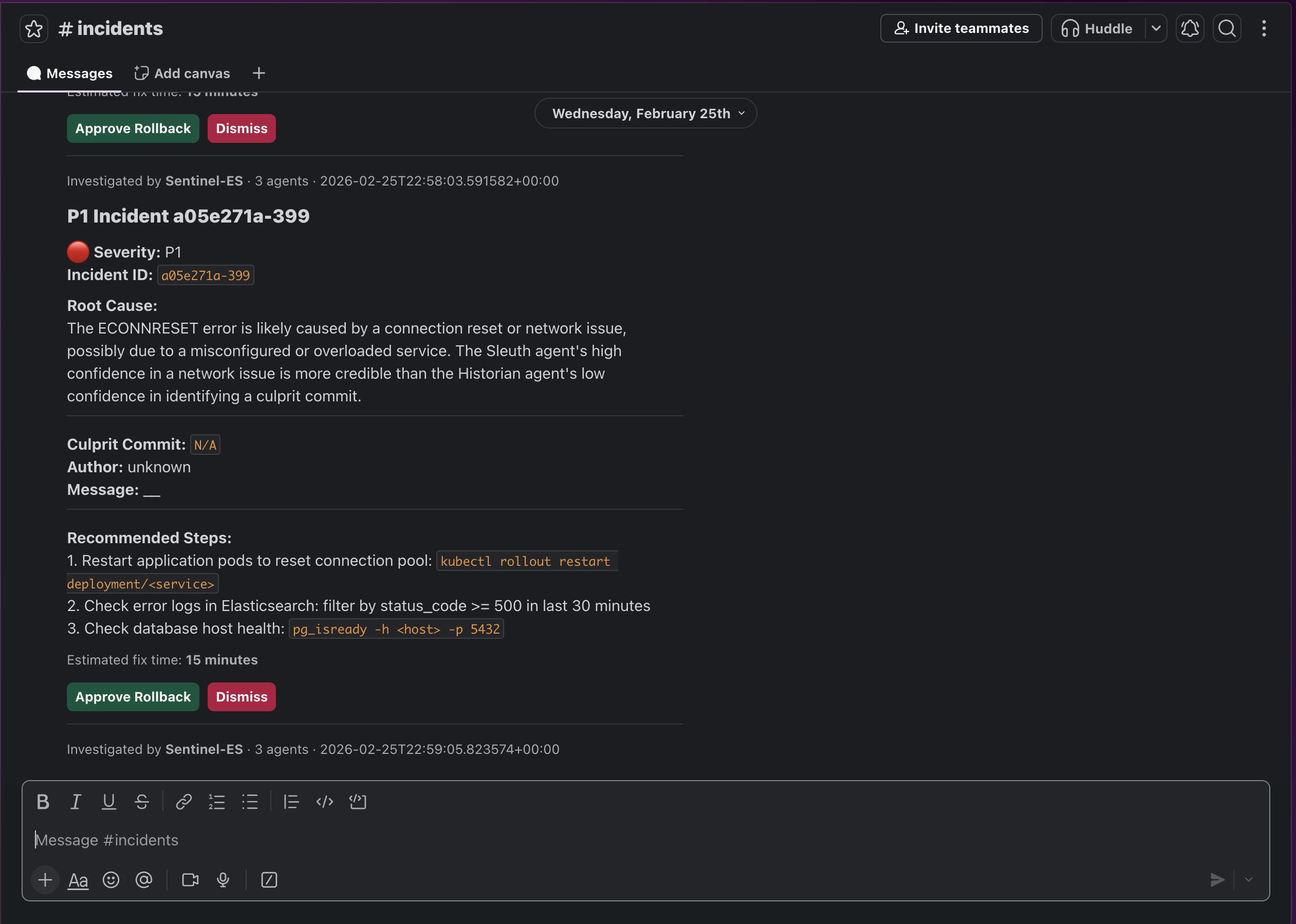
Slack alert with remediation
-
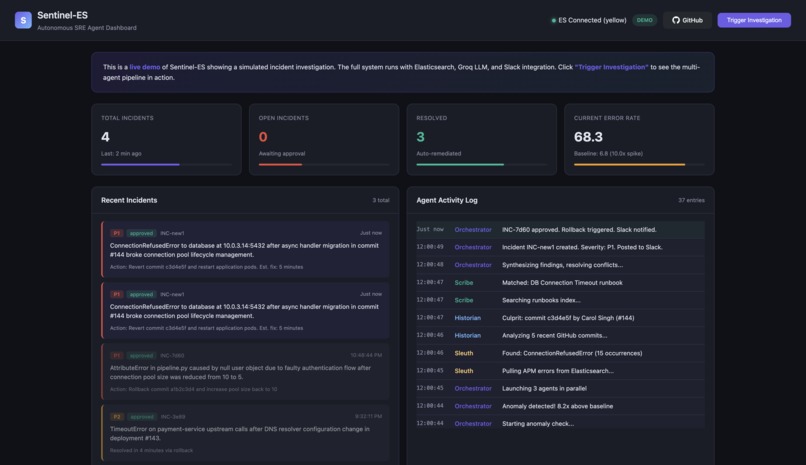
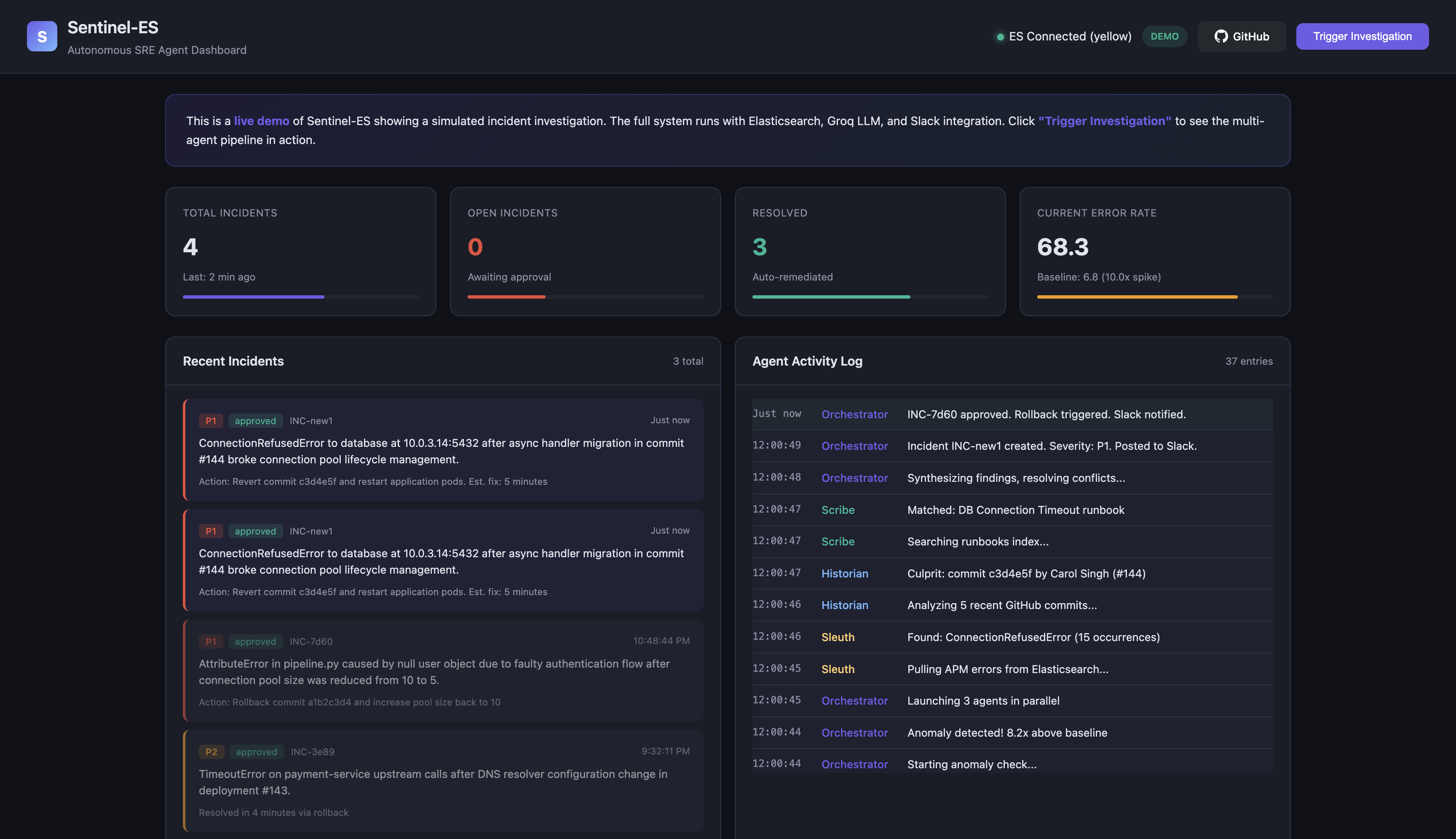
Rollback approved, incident resolved
Inspiration
SRE teams are drowning in alerts. Studies show 70% of alerts are noise, and when a real incident hits, engineers spend 15 to 30 minutes just context-switching between dashboards, logs, git history, and runbooks before they even understand what went wrong. We wanted to build something that does all of that investigation automatically in under 3 seconds and hands the engineer a clear answer with a single button to fix it.
What it does
Sentinel-ES is a multi-agent system that acts as an autonomous SRE. When HTTP 500 errors spike beyond 3x the baseline, it kicks off three specialist AI agents in parallel:
- The Sleuth pulls error patterns from Elasticsearch APM data and identifies the root cause
- The Historian analyzes recent git commits and pinpoints which deployment likely broke things
- The Scribe searches internal runbooks and produces step-by-step remediation instructions
An Orchestrator agent then synthesizes all three findings, resolves any disagreements between agents, and posts a rich incident report to Slack with "Approve Rollback" and "Dismiss" buttons. Nothing destructive happens without a human clicking approve.
How we built it
We started with a local Elasticsearch 8.x cluster running in Docker, seeded with realistic synthetic metrics, APM errors, and runbook documents. The anomaly detection layer uses ES|QL to compare rolling time windows of error rates.
Each agent is a Python class built on top of the Groq LLM API (llama-3.1-8b-instant, free tier). They all inherit from a shared BaseAgent that handles prompt formatting, LLM calls with automatic fallback, in-memory state, and activity logging.
The orchestrator runs agents in parallel using asyncio.gather, then feeds all their findings into one final LLM call that acts as a "conflict resolution" step, similar to how a real incident commander would weigh different opinions.
Everything is exposed through a FastAPI backend with a live web dashboard, Slack integration via Incoming Webhooks, and a background poller that checks for anomalies every 60 seconds.
Challenges we ran into
Getting the agents to return consistently structured JSON from the LLM was tricky. We had to carefully craft system prompts and add robust parsing with fallbacks for when the model wraps its response in markdown code blocks or adds extra text.
Coordinating three agents that depend on each other's output (the Historian and Scribe both need the Sleuth's findings) while still running as much in parallel as possible required careful orchestration of the async pipeline.
We also had to handle the ES|QL compatibility layer gracefully. Not all Elasticsearch deployments support ES|QL, so we built automatic fallback to standard aggregation queries.
What we learned
The biggest lesson was that multi-agent systems need a clear hierarchy. Having the Orchestrator act as an "incident commander" that synthesizes and resolves conflicts between specialist agents produced dramatically better results than just concatenating their outputs.
We also learned that human-in-the-loop is not optional for production SRE tooling. Our guardrails module that blocks destructive actions and requires approval for P1 incidents gave us confidence that the system would be safe to use in a real environment.
What's next
We want to add incident memory so the system learns from past investigations and gets smarter over time. We also plan to integrate with PagerDuty for on-call routing and add automatic draft PR creation for rollbacks.
Built With
- asyncio
- docker
- elasticsearch
- es|ql
- fastapi
- github-api
- groq
- httpx
- kibana
- llama
- python
- slack-api
- uvicorn

Log in or sign up for Devpost to join the conversation.