
Inspiration
I was awake at 2am watching the Iran-US conflict unfold in real time when I noticed something that genuinely unsettled me. BBC was reporting that Iran denied any attack on the port. At the exact same moment, NDTV was reporting that Iran claimed full responsibility. Both articles were being shared by thousands of people simultaneously. Neither article mentioned the other existed.
Nobody was lying. But someone was wrong. By morning, millions of people had formed an opinion based on whichever version they happened to read first.
I kept thinking about that gap. The window between when a false narrative forms and when a fact-checker catches it is where the real damage happens. Sentinel was built to close that window.
What it does
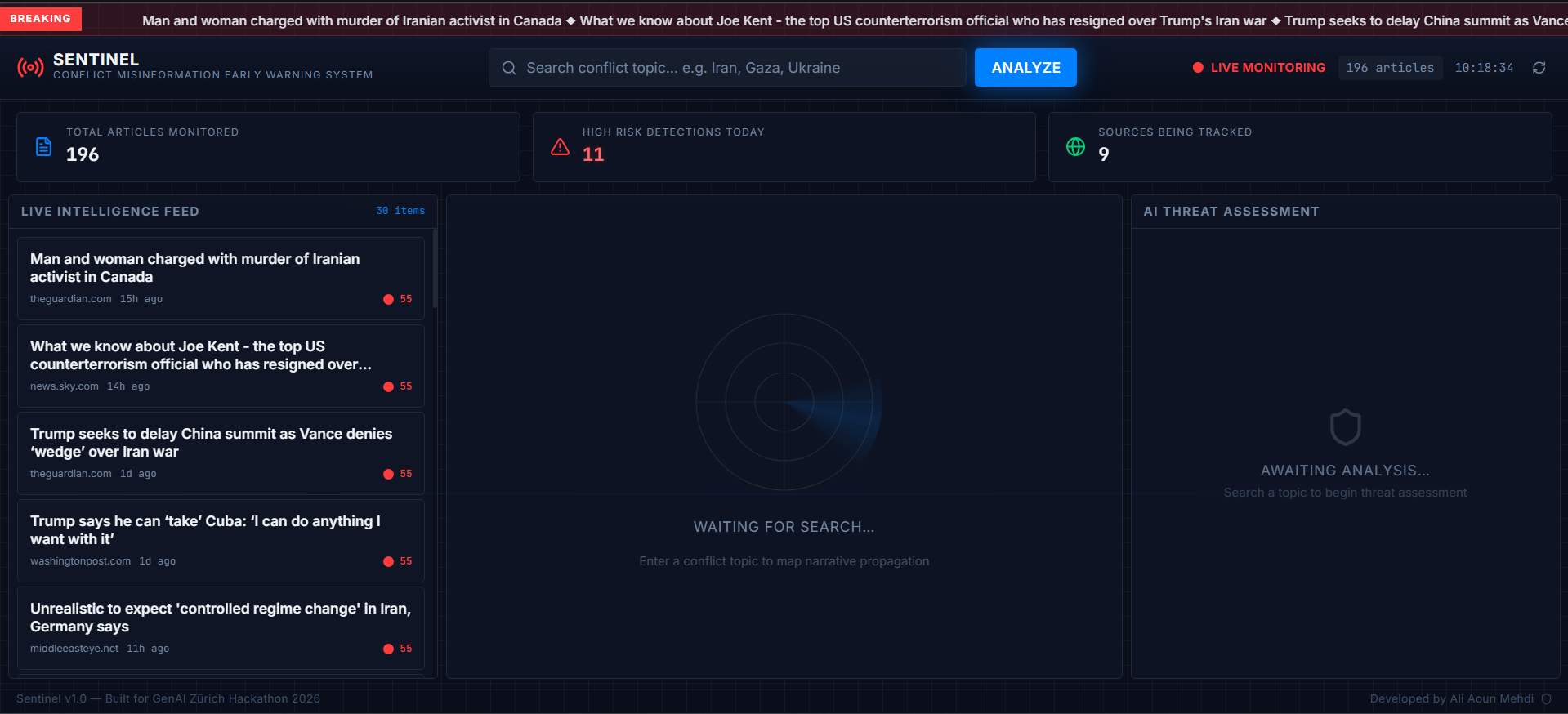
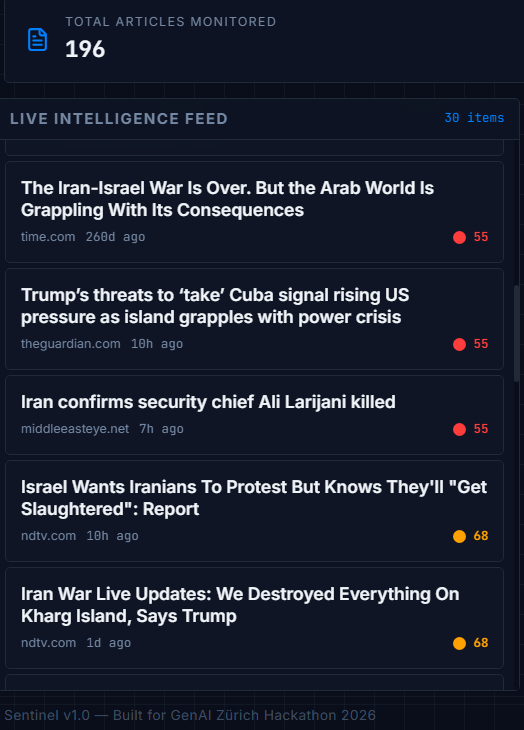
Sentinel watches 12 global news sources simultaneously and alerts you the moment a misinformation pattern starts forming around any conflict topic.
You open the dashboard and type a topic — Iran, Gaza, ceasefire, Ukraine — and within 30 seconds you receive a complete intelligence report showing:
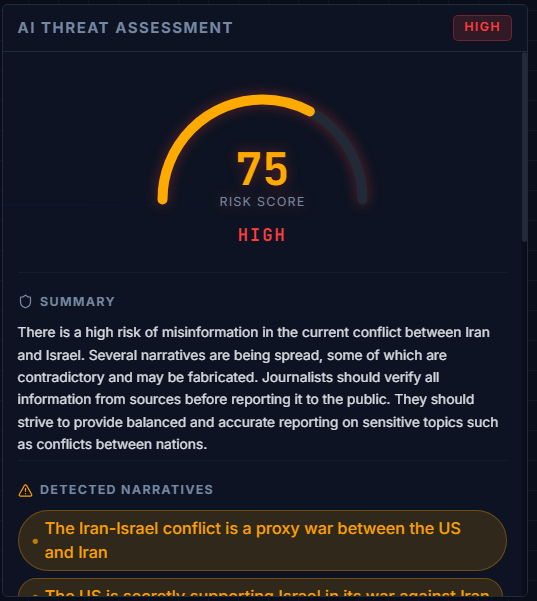
- Misinformation risk score from 0 to 100 with severity levels LOW, MEDIUM, HIGH, and CRITICAL
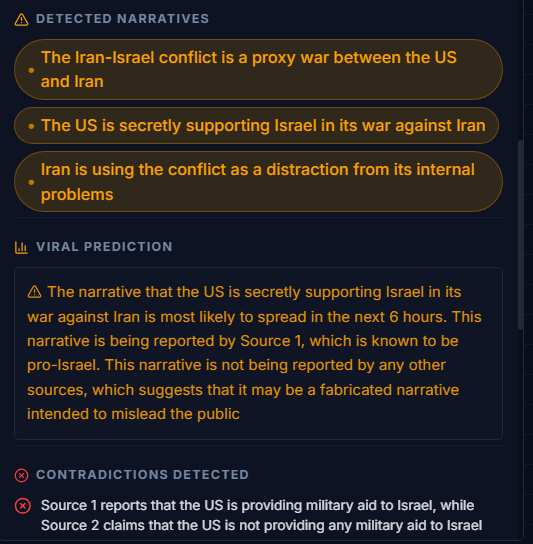
- Contradiction detection — specific outlets reporting opposite facts on the same event
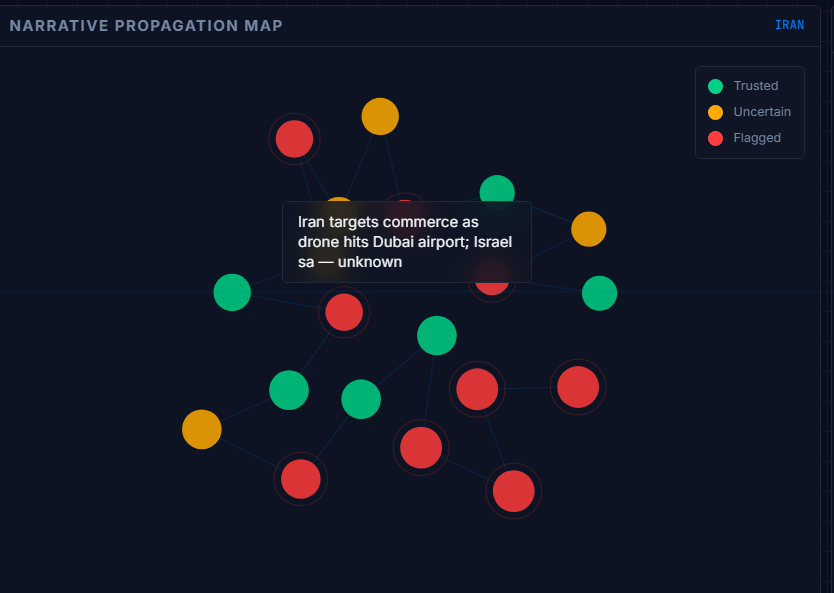
- Narrative traction assessment — which story is gaining the most spread and why
- Journalist verification actions — exactly where to focus fact-checking effort
- Story development timeline — how the narrative evolved article by article
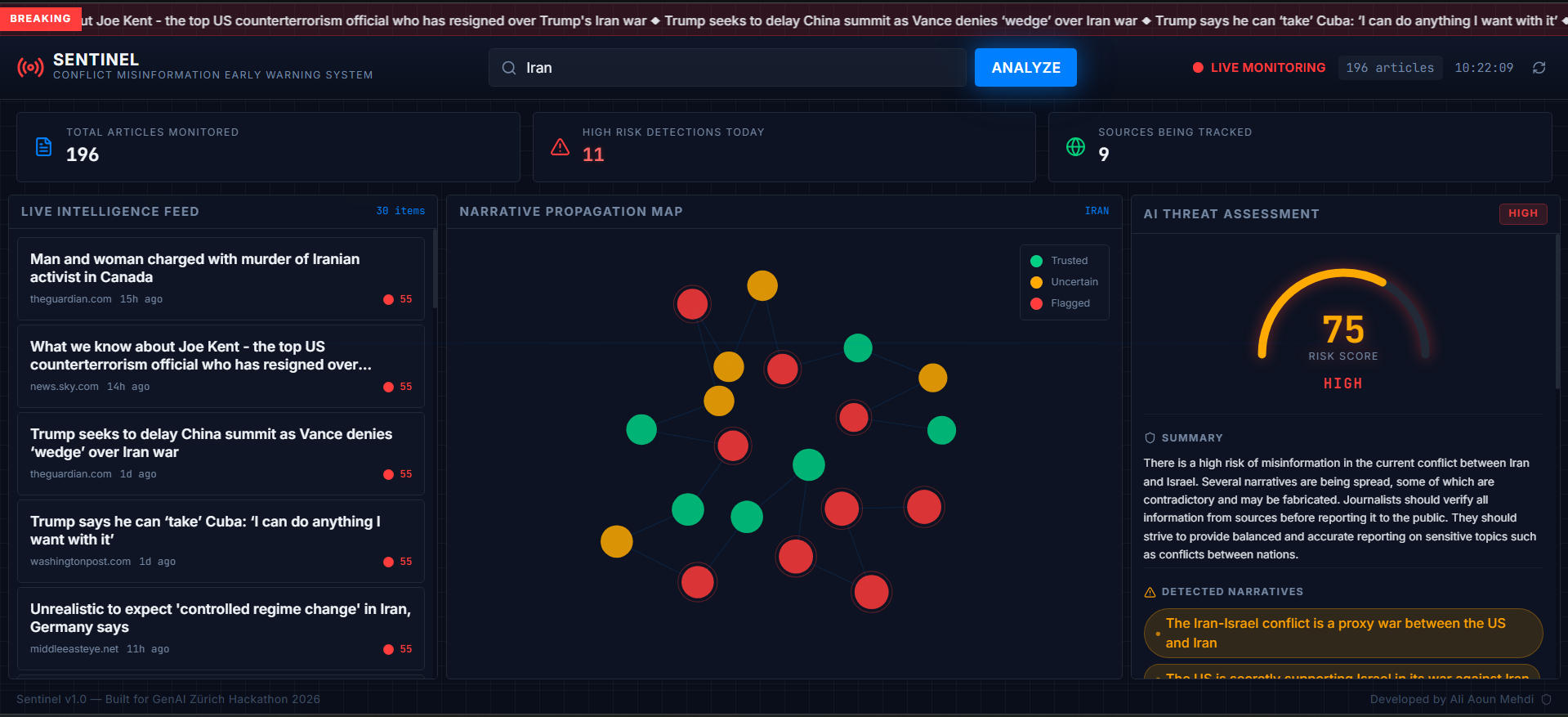
- Semantic network graph — D3.js visualization of how stories travel between sources
- Exportable intelligence report — ready for immediate newsroom use
Try it yourself right now at sentinel-checker.lovable.app
How I built it
Data collection — Apify
We built and deployed a custom Sentinel RSS Actor on Apify that scrapes 10 global news sources every 30 minutes. The Actor is triggered programmatically via the Apify Python SDK. Sources include BBC, Al Jazeera, Guardian, Washington Post, NPR, Sky News, NDTV, Middle East Eye, DW, and Time Magazine. Every article arrives as clean structured JSON with title, summary, source, link, and publication time.
Semantic storage — Qdrant
Each article is converted into a 384-dimensional vector using sentence-transformers/all-MiniLM-L6-v2 from Hugging Face and stored in Qdrant Cloud running in Frankfurt. When you search a topic, Qdrant finds the 15 most semantically related articles using cosine similarity. This is not keyword matching — it finds articles about the same event even when they use completely different vocabulary, which is exactly what makes cross-source contradiction detection possible.
AI analysis — Featherless AI
The 15 matched articles are sent to Mistral-7B via Featherless API. A structured prompt extracts factual claims from each source, identifies where those claims directly contradict each other, scores misinformation risk, assesses narrative spread trajectory, and generates journalist recommendations — all returned as validated JSON.
Backend and frontend
A FastAPI backend deployed on HuggingFace Spaces serves 6 REST endpoints with a background auto-refresh task running every 30 minutes to keep data fresh. The React dashboard built with Lovable displays everything across three panels — live intelligence feed, D3.js force-directed network graph, and animated threat assessment gauge.
Challenges I ran into
Building a custom Apify Actor from scratch meant learning the Apify SDK, debugging RSS XML parsing across 10 different feed formats, and handling sources that block scraping with 404s and connection failures. Each feed had slightly different structure for titles, links, and timestamps.
The Qdrant Python client silently changed a method name between versions — .search() was replaced by .query_points() — which caused a confusing error that took over an hour to diagnose because the error message pointed nowhere near the actual problem.
The most stressful moment was an automated security email from Apify hours after my first GitHub push. My API token was in the code and their scanner caught it immediately. I had to rotate the token, move all credentials to HuggingFace Space secrets as environment variables, and audit everything I had pushed.
Accomplishments I am proud of
When I searched Iran, Sentinel returned a risk score of 75 out of 100 marked HIGH and correctly identified that sources were publishing directly contradictory facts about military activity in the region. It named the specific narratives being pushed and assessed which one had the strongest spread trajectory. That assessment matched what appeared in broader coverage over the following hours.
The system now fetches fresh data automatically every 30 minutes using my own custom Apify Actor — no stale data, no manual refresh needed. The entire pipeline from Actor trigger to Qdrant storage to API response is fully automated.
What I learned
The combination of Apify and Qdrant does something neither can do alone. Apify solves the hardest part of any AI application — getting clean, fresh, real data from the messy real world. Qdrant turns that data into something you can reason about semantically rather than just search through literally. Featherless AI made it possible to run powerful LLM inference without expensive API costs, which was critical for keeping the whole system running on free-tier infrastructure.
Sentinel does not tell you what is fake. It tells you where the contradictions are and where the risk is highest. That distinction matters enormously — a system that confidently labels things as true or false creates a different kind of misinformation problem.
What's next for Sentinel
The most important missing piece is social media. Narratives often originate on Twitter or Reddit hours before any outlet picks them up. Adding Apify social media scrapers would let Sentinel catch misinformation at its actual source rather than after it has already spread to news outlets.

Log in or sign up for Devpost to join the conversation.