-
-
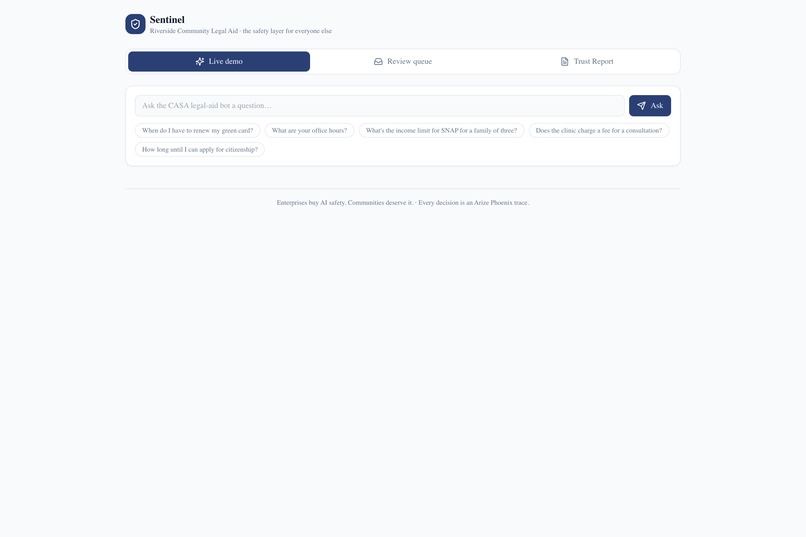
Director dashboard
-
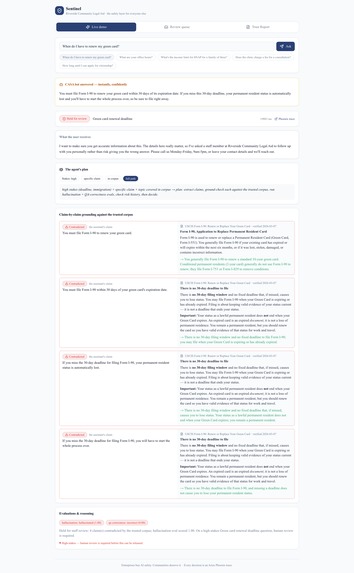
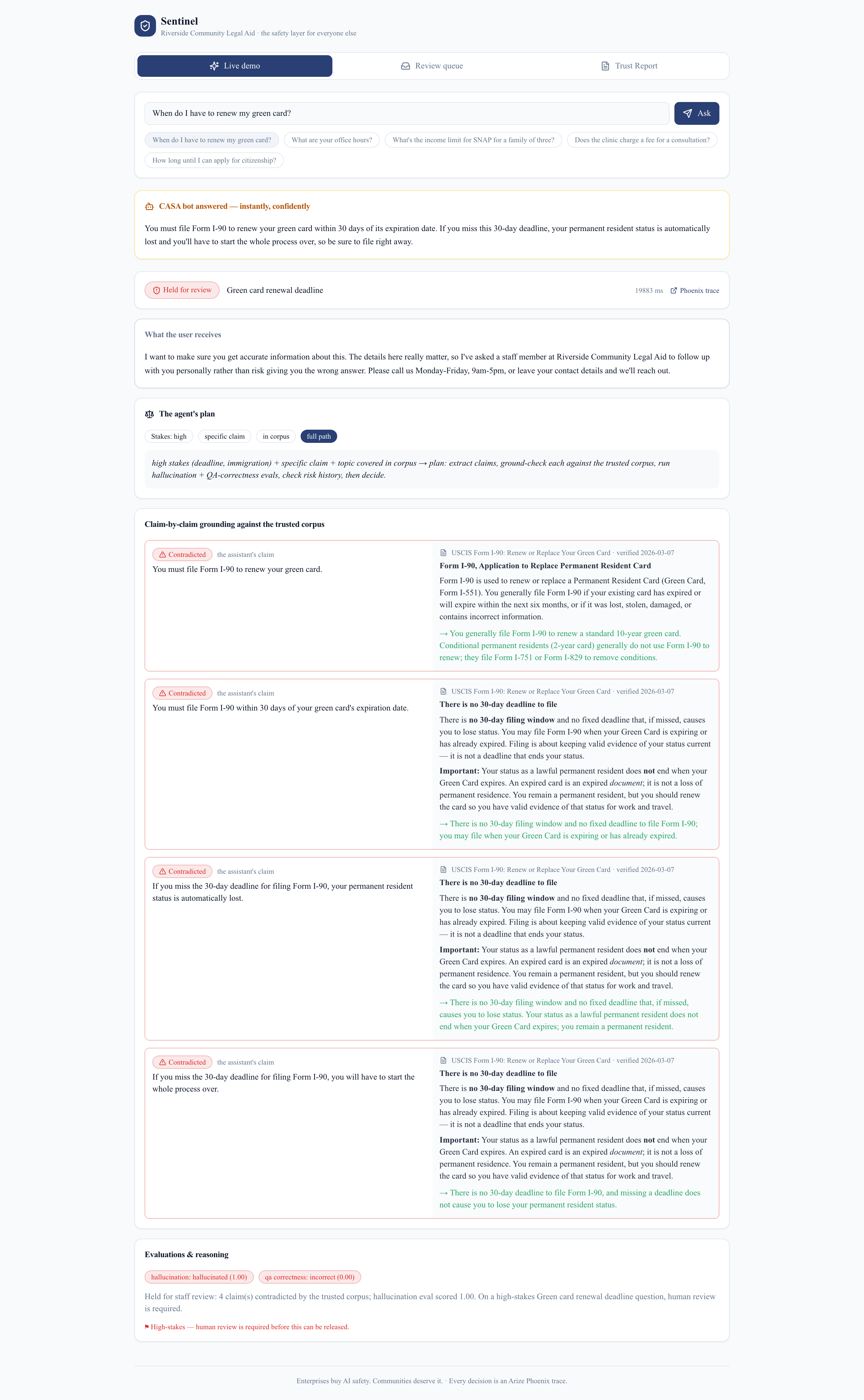
Quarantine — claim vs. the source that contradicts it
-

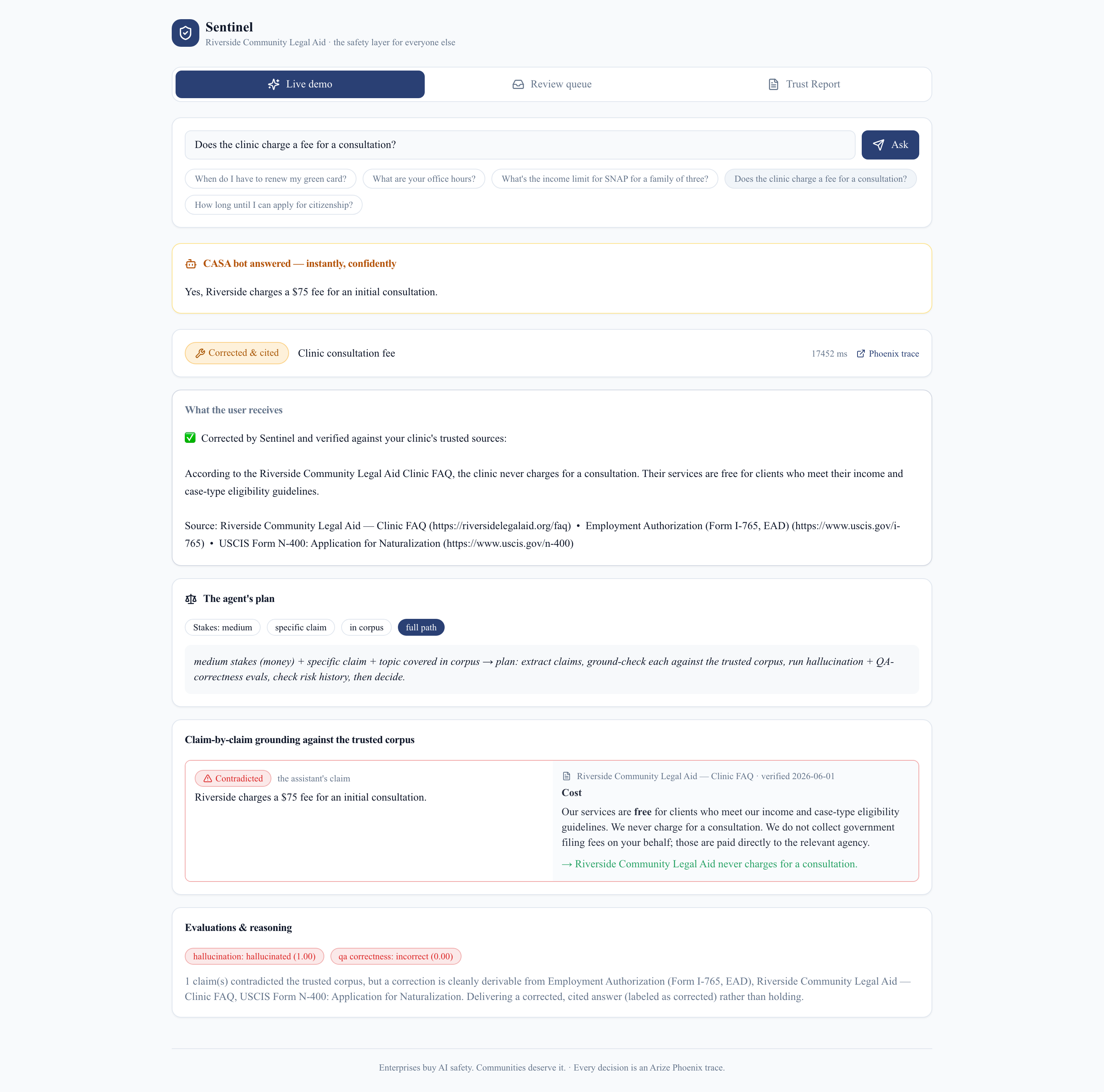
Repair & cite — corrected from the clinic's own FAQ
-
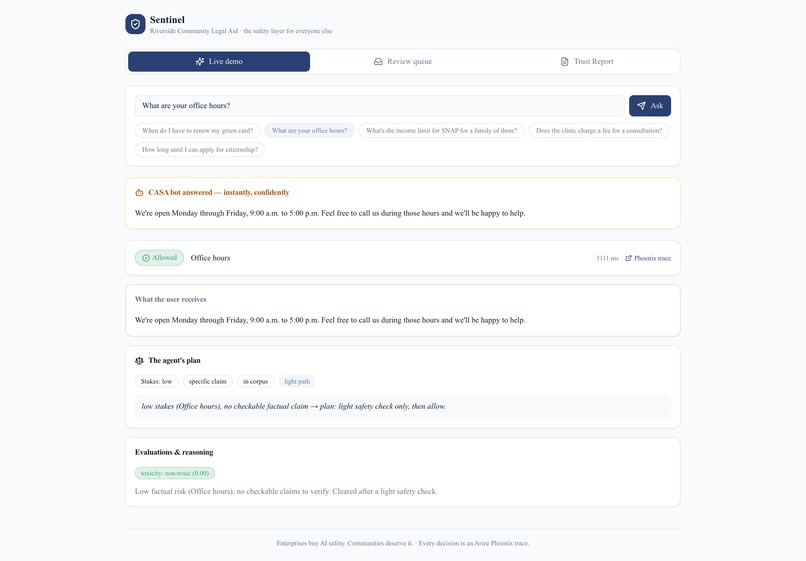
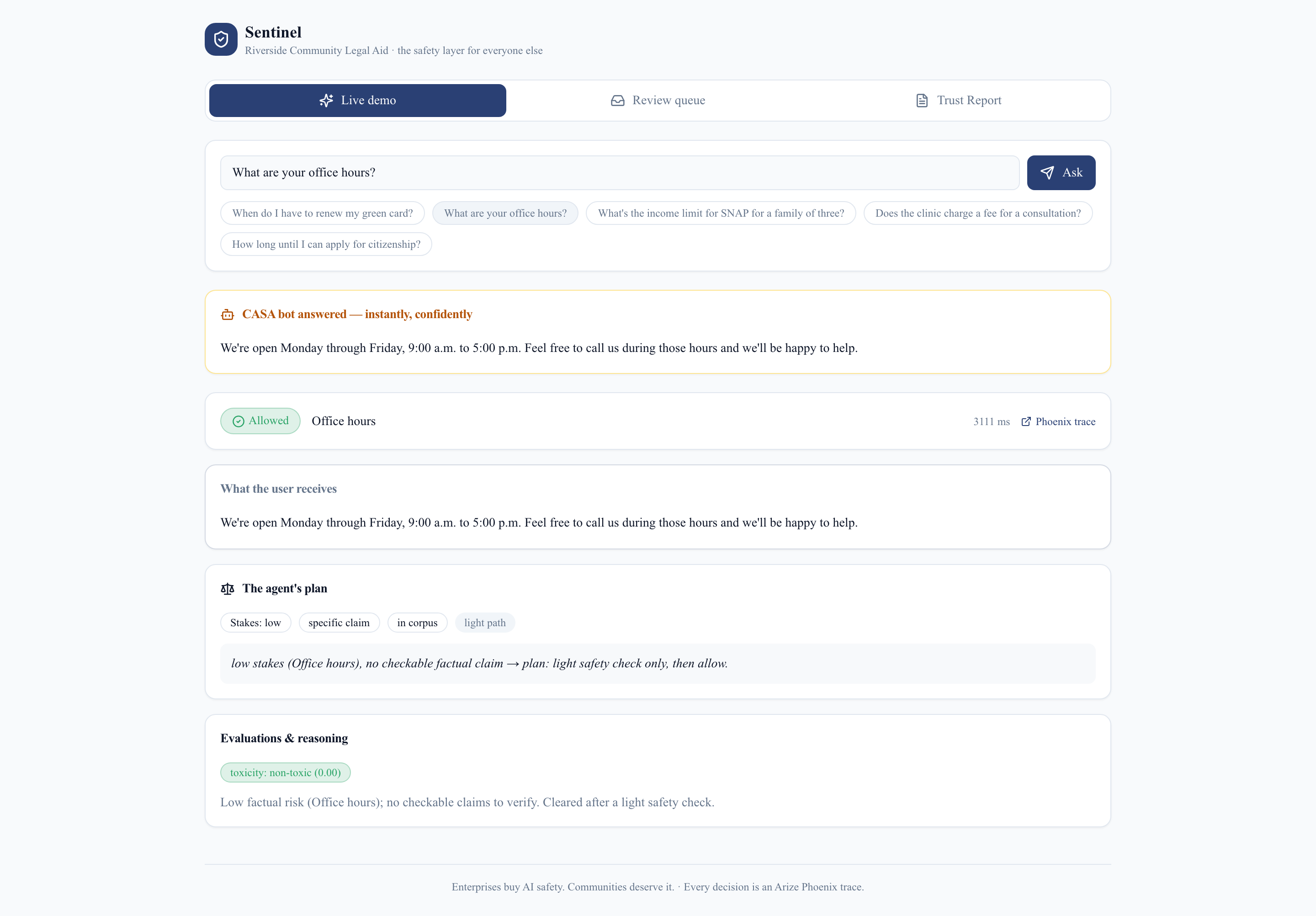
Allow — low-stakes, cleared in ~3s
-
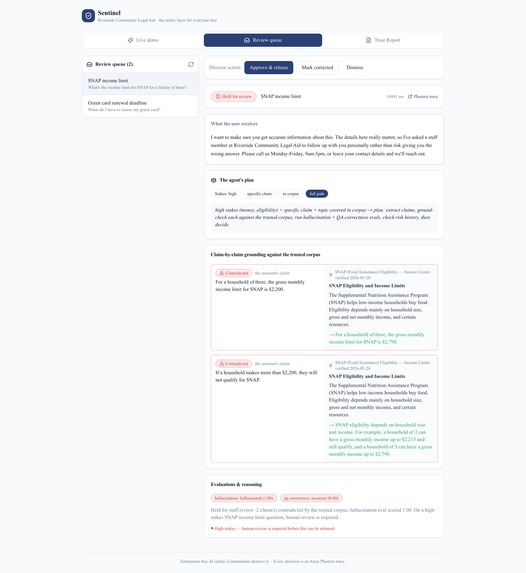
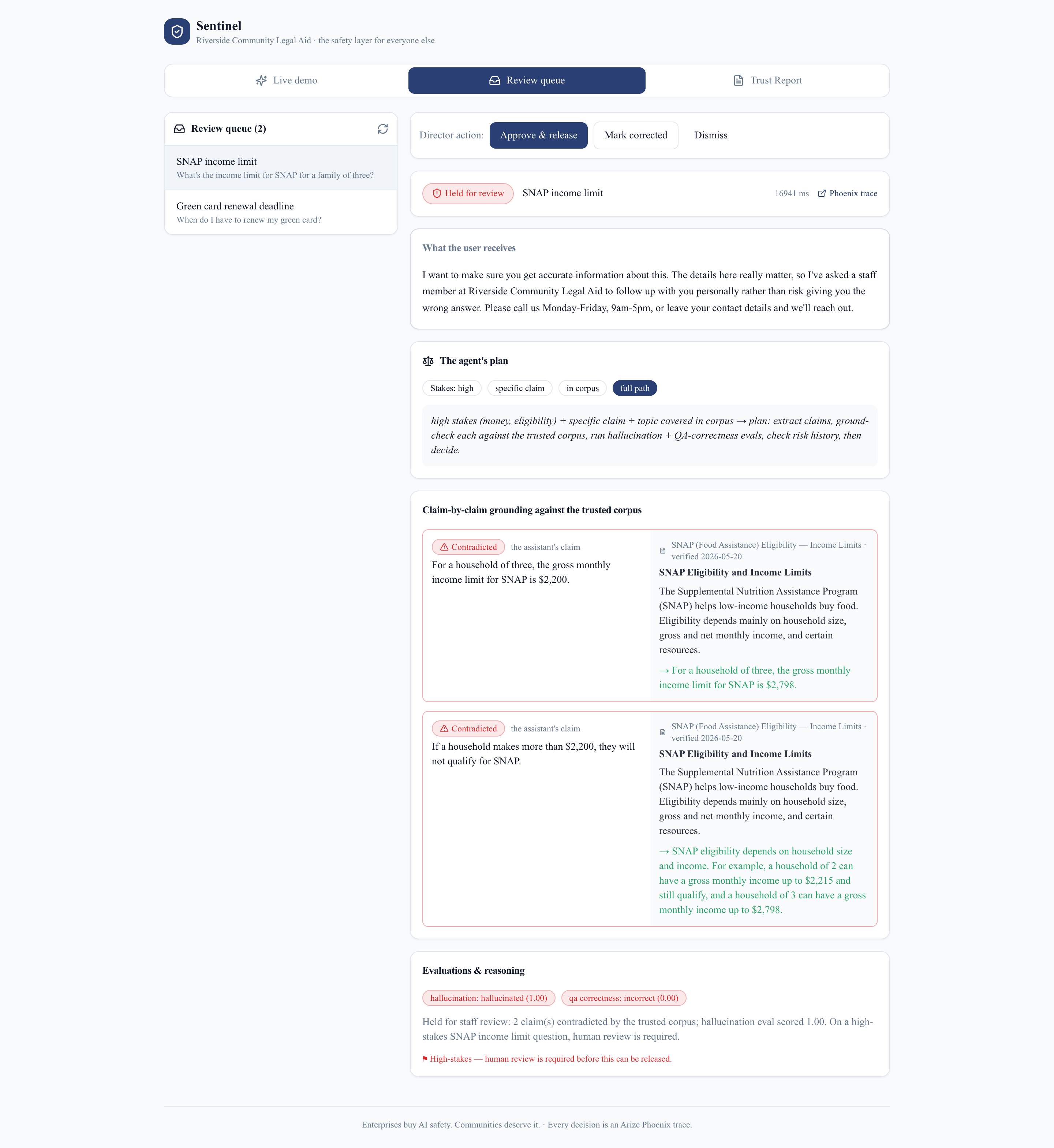
Review queue — human in the loop
-
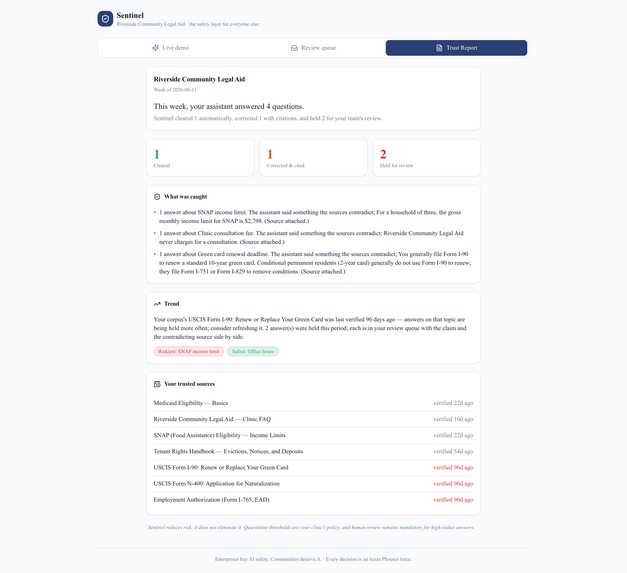
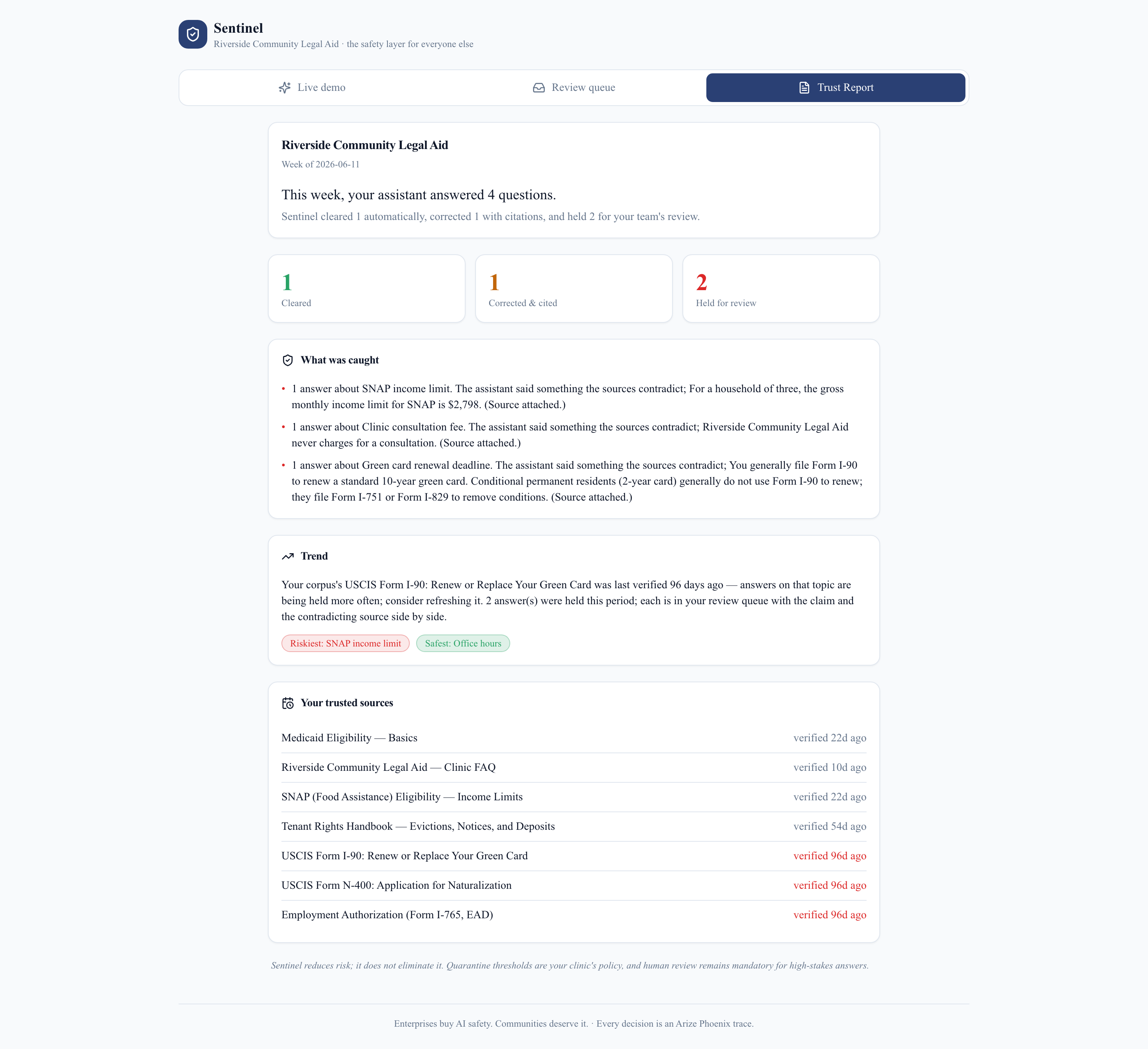
Weekly Trust Report
Inspiration
Enterprise AI gets million-dollar safety teams. The legal-aid clinic answering a refugee's visa question gets nothing.
Content filters are excellent at what they do — toxicity, PII, policy. But they are blind to the failure mode that actually hurts vulnerable people: a polite, fluent, confident, factually wrong answer. A wrong filing deadline. A wrong benefit threshold. A wrong eligibility rule. There is nothing toxic about "your green card must be renewed within 30 days" — it's simply false, and it can cost someone their case, their benefits, or their status.
This is not hypothetical. Stanford's 2026 AI Index puts hallucination rates between 22% and 94% across top models — exactly as state chatbot laws (Texas TRAIGA, Utah HB 452) begin to require oversight. The organizations serving the most vulnerable people — legal aid, free health lines, benefits navigators — are deploying chatbots with none of the safety infrastructure enterprises take for granted.
Sentinel closes that gap. It is the safety layer for everyone else.
What it does
Sentinel is a guardian agent that sits between an AI assistant and the person who would trust it. It intercepts every answer the assistant drafts and runs a four-step loop in seconds:
- Triage — it classifies what's at stake and writes a plan, then takes a visibly different path. "What are your office hours?" clears in ~3 seconds; a high-stakes specific claim triggers the full check. An agent that decides how hard to look — not a fixed filter.
- Ground-check — it decomposes the answer into atomic claims and verifies each against the organization's own trusted documents only, never the open web. "Not found in the sources" is treated as risk, not pass — because a fabricated specific looks exactly like a true one the corpus happens not to mention. This is what catches the confident lie.
- Decide — a transparent, human-in-the-loop verdict:
- Allow — every claim checks out; the original answer is delivered.
- Repair & cite — a claim is wrong but the correct answer is in the sources; Sentinel delivers a corrected answer, clearly labeled and cited.
- Quarantine — the answer is held; the user gets an honest "a staff member will follow up," and the case lands in a review queue with the claim shown side-by-side with the source that contradicts it.
- Report — every decision becomes an Arize Phoenix trace, and a weekly, plain-English Trust Report tells a non-technical director exactly what the AI did this week, and what it almost did.
The thresholds are the organization's policy, not the model's. Human review is mandatory for every high-stakes answer. Sentinel never silently rewrites, and never blocks without telling the user something true.
How we built it
Sentinel is a production-grade system — deployed, tested, and live.
- Agent runtime: Google's Agent Development Kit (ADK) drives a Gemini agent that plans and calls tools, paired with a deterministic, streaming orchestrator so the dashboard shows the agent working in real time.
- Reasoning: Gemini (
gemini-2.5-flash) at temperature 0, structured output for triage, claim extraction, and the grounding judgment. - Arize Phoenix — structural in three roles, not a logging afterthought:
- Evals as a decision input — LLM-as-a-Judge hallucination and QA-correctness scores feed the quarantine decision directly.
- Tracing as the audit trail — every run is one OpenInference trace; when an accountability rule asks a clinic to "prove oversight," the trace is the proof.
- Monitoring as memory — the agent reads back its own per-topic quarantine rates via the Phoenix MCP server and adapts its own threshold. It improves from its observability data.
- Grounding: real semantic embeddings (
gemini-embedding-001) over the organization's vetted documents. - The stack: FastAPI + Server-Sent Events, a Next.js + Tailwind director dashboard, Pydantic-v2 contracts on every boundary, Firestore-ready storage, and two auto-scaling Cloud Run services. 34 tests, mypy strict, ruff clean.
Challenges we ran into
- The core design call: treating "not found in the corpus" as risk rather than pass, and tuning triage to catch the dangerous without quarantining the harmless. Get it wrong in either direction and the product fails.
- Making Arize load-bearing. It would have been easy to bolt Phoenix on as a logger. Wiring evals into the decision, tracing as the compliance artifact, and monitors back into the agent's own thresholds took real design.
- Shipping live surfaced real bugs we fixed in the open: the Phoenix exporter needed the OTLP path appended; a context-manager bug produced empty traces; the browser's event-stream parser split on the wrong line ending; and lexical search matched a "$75 fee" claim to government filing-fee text instead of the FAQ's "we're free" line — which is exactly why we moved to real embeddings.
Accomplishments that we're proud of
A live, public, deployed product where all three decisions work end-to-end with real Gemini reasoning and real Phoenix traces:
- the green-card "30-day" lie is quarantined, its USCIS source shown next to the claim;
- "what are your office hours?" is allowed in seconds;
- a "$75 consultation fee" claim is auto-corrected and cited from the clinic's own FAQ.
Every verdict is a transparent, unit-tested function of the evidence — Gemini does the language, deterministic rules make the safety call — and the agent gets smarter from its own monitor data.
What we learned
The dangerous failure mode isn't toxicity — it's confidence. Grounding an answer in an organization's own voice (not the internet) is what makes "I don't know" safe and turns a coverage gap into a feature instead of a hallucination. And observability isn't only for debugging: once an agent can read its own monitor data, memory becomes a product capability.
What's next for Sentinel — A Safety Layer for Confidently-Wrong AI
- Self-serve onboarding — an organization uploads its documents and gets a working Sentinel in an afternoon.
- Scale — Firestore plus a managed Vertex AI Vector Search index, an API-key/IAP gate, and rate-limiting for production traffic.
- Distribution — partnerships with legal-aid associations, 211 networks, and Parent Training Centers, who already reach the people who need this most.
Enterprises buy AI safety. Communities deserve it. Sentinel is the watchdog for everyone else.
Built With
- arize-phoenix
- docker
- fastapi
- firestore
- gemini
- google-adk
- google-cloud-run
- next.js
- openinference
- pydantic
- python
- server-sent-events
- tailwind-css
- typescript
- uv
- vertex-ai


Log in or sign up for Devpost to join the conversation.