-
-
Sentinel-Workflow
Inspiration
1.19 million people die from car accidents each year. Over 35 million suffer severe, long-term disabilities. Millions more suffer life-altering injuries that never make headlines. In such high stakes environments, every second counts. Yet emergency response still depends on delayed reports, fragmented information, and human interpretation. Sentinel changes that. By separating always-on anomaly detection from semantic reasoning, Sentinel transforms continuous video streams into structured, actionable incident intelligence in real time. No waiting. No ambiguity. No lost minutes. Because in high-stakes environments, the difference between life and death isn’t seconds. It’s whether someone knew—and acted—in time.
What it does
Sentinel is an AI system that turns live traffic camera footage into real-time incident alerts and structured reports. Instead of waiting for someone to call 911 or manually monitor dozens of screens, Sentinel continuously watches roadway video, detects abnormal patterns like sudden stops or collisions, and determines whether an accident has likely occurred. When it detects a high-risk event, it automatically analyzes the scene, generates a structured incident summary, and sends it to operators for immediate dispatch, saving critical minutes when every second can mean the difference between life and death.
How we built it
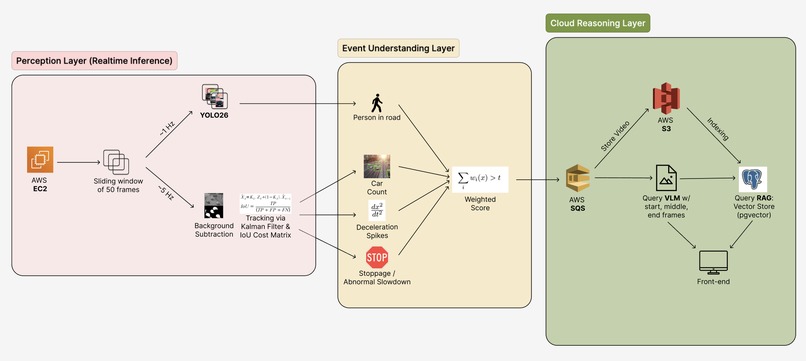
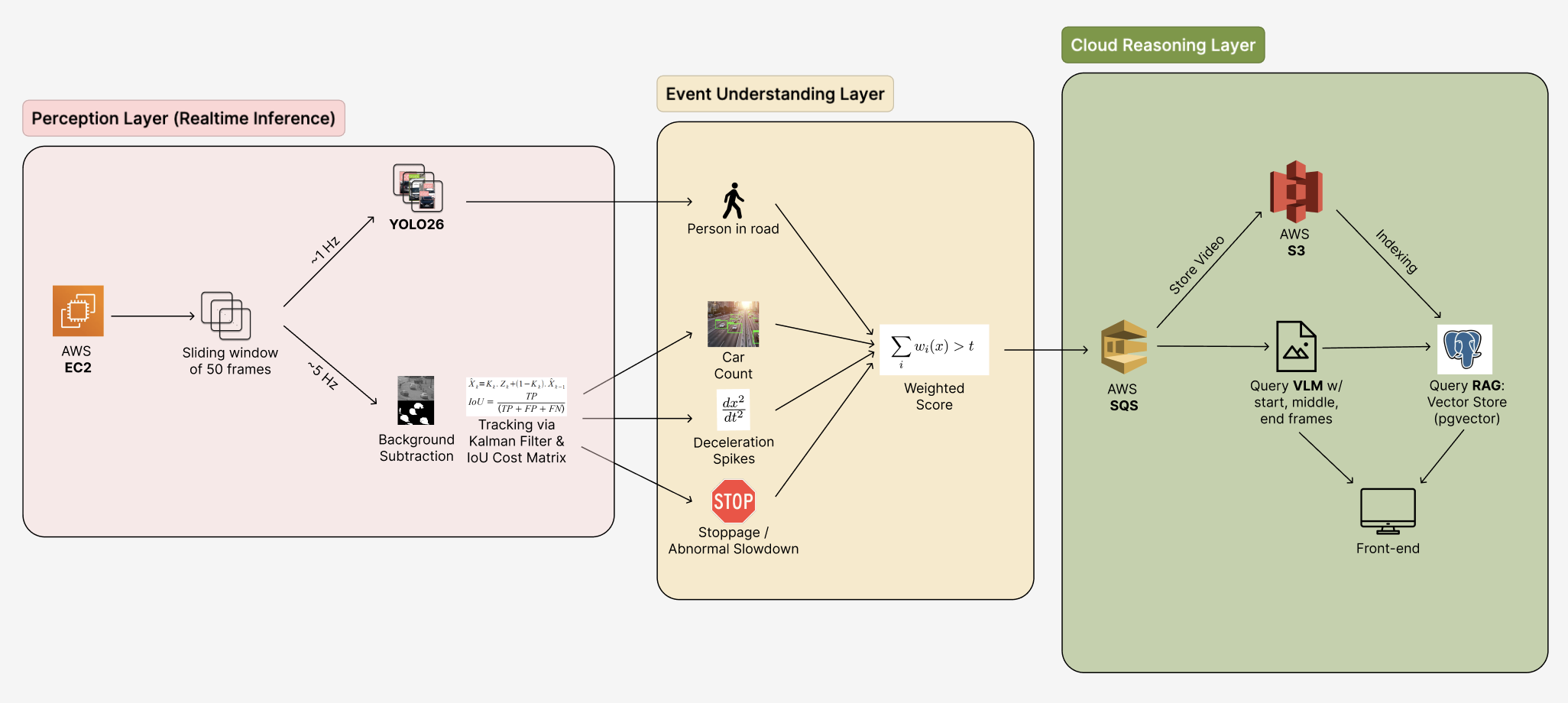
We built Sentinel as a three-layer pipeline: real-time perception, event understanding, and cloud reasoning.
1. Perception layer (real-time inference)
We first run a motion-first pipeline on each stream. Instead of relying only on object detection, we use MOG2 background subtraction and connected components to find motion blobs, then track them with a Kalman filter and IoU matching. That gives us stable velocity and acceleration for all things that move, even in low light or glare. We also run YOLO26 at ~1 Hz for person and vehicle counts, and keep processing constant at ~5 FPS so we stay responsive without overloading the system.
2. Event understanding layer
We next turn detections into incident signals. Each track yields kinematics (velocity, acceleration), which we combine to yield several indicators: deceleration spikes, “stopped in lane” persistence, scene shockwaves (median speed drop + density rise), YOLO person detection, and car density increase. Each indicator has an assigned weight, with the weighted sum compared to a threshold. When it crosses, we treat it as an “incident candidate” and send it to the cloud.
3. Cloud reasoning layer
Event candidates are then sent to AWS SQS, which delivers them to the cloud layer. From there, one path stores the relevant sliding window (~50 frames) into S3, while another triggers VLM and RAG queries: we sample key frames (start, middle, end) from a sliding window for semantic event classification and retrieve relevant policy docs from the vector store. VLM outputs and RAG context are then sent to the React frontend, which shows live cameras and analysis results.
Challenges we ran into
Most of the challenges we faced came from the gap between ideal computer vision pipelines and real-world constraints. Initially, we planned on using a YOLO + BoT-SORT tracking setup, but we quickly discovered that this approach was not practical given time and resource constraints (high GPU and latency requirements + poor video conditions). Highway cameras also produced many adversarial edge cases such as glare, shadows, and tiny distant vehicles that made exact modeling extremely difficult. Beyond modeling, the systems work itself was difficult: stabilizing the HLS ingestion with OpenCV, load-balancing inference across EC2 instances, and preventing runaway inference costs required significant engineering effort. Furthermore, infrastructure and RAG constraints forced us to consider pragmatic tradeoffs, since vector search tools like OpenSearch weren’t free and every other unnecessary model or VLM call increased our monetary overhead. Ultimately, the hardest part was tuning our first-stage CV trigger: designing a robust binary incident vs. non-incident decision under inconsistent conditions while minimizing false positives required lots of experimentation and tuning with various weights and indicators.
Accomplishments that we're proud of
We’re proud that we didn’t just stack models together and built a system that genuinely works. Implementing the motion-blob pipeline (MOG2 + connected components + Kalman tracking) was a major breakthrough for us. It gave us velocity and acceleration signals independent of computationally-expensive detection models, and it ended up being more robust under glare and low light than our original approach.
We’re also proud that we were willing to rethink our architecture. Our initial YOLO + tracking-every-frame design was overambitious and didn’t hold up under real-time and cost constraints. Instead of doubling down, we redesigned the pipeline around lightweight motion signals and selective escalation. That shift made the system faster and more reliable without sacrificing performance.
Most importantly, we’re proud that Sentinel it’s a working, end-to-end product. It ingests live video, surfaces structured incidents, and delivers explainable results. It’s something that could realistically be deployed and make a tangible impact, not just a demo that works in controlled conditions.
What we learned
Through building Sentinel, we learned about the importance of grounding ambitious ideas in the reality of deployment.
It’s easy to design something that looks great on paper: a giant multimodal model reasoning over every frame, dense object detection everywhere, full-scene semantic understanding at all times. But in the real world, cost, latency, and hardware limits quickly become the bottleneck. Video in the real world is noisy and unpredictable, and systems have to handle that reliably.
We initially built a large YOLO + BoT-SORT pipeline that ran detection and tracking on every frame. The idea was straightforward: if we could accurately track vehicles in real time, we could reason about incidents on top of that. In reality, however, it struggled to hold up. Even locally, FPS dropped to 1, tracks were unstable, and glare caused false positives. If it struggled on our own machines, scaling it in the cloud would have been way too expensive.
So, we changed the design. Instead of running heavy models continuously, we shifted to a motion-based pipeline that uses lightweight signals to flag potential incidents and only escalates those flagged cases to more powerful models. We didn’t sacrifice accuracy; rather, we just made the structure more efficient.
Sentinel ultimately taught us that building for the real world is less about model size and more about system design under constraints.
What's next for Sentinel
Moving forward, we want to move our prototype to become a production-ready system. That means expanding beyond a few test streams and validating Sentinel across more diverse camera feeds, such as different lighting conditions, weather, traffic density, angles, etc.
We also plan to improve the event understanding layer by learning the weights and thresholds directly from labeled data rather than tuning them manually. That would allow the system to adapt across deployments while keeping the motion-based architecture intact.
On the cloud side, we want to make the reasoning layer smarter and more configurable: better incident classification, clearer summaries, and tighter integration with policy documents or response workflows. Instead of just detecting events, Sentinel should determine the most optimal step to pursue next.
Longer term, we’re interested in expanding beyond road incidents into broader infrastructure monitoring, such as stalled vehicles, obstructions, pedestrian risks, and other anomalies on the road. The ultimate goal is to build a scalable video intelligence system that cities or operators can actually rely on.
Built With
- amazon-ec2
- amazon-sqs
- amazon-web-services
- aws-ec2
- aws-sqs
- bot-sort
- kalman-filter-tracking
- mog2
- mog2-background-subtraction
- node.js
- numpy
- opencv
- pgvector
- postgresql
- python
- pytorch
- rag
- rag-pipeline
- react
- typescript
- vision-language-models-(vlm-api)
- vlm
- yolo26
- yolov8/yolo26


Log in or sign up for Devpost to join the conversation.