SENTINEL — Resilient AI Orchestration Infrastructure
Inspiration
Every team building AI products faces the same unspoken risk: what happens when your LLM provider goes down?
We've all seen the headlines — OpenAI outages, Claude rate limits, cloud model brownouts. Most teams discover this problem in production, with real users, at the worst possible time. The standard response is either hard-coded retry logic buried in application code, or worse — a crashed product and an angry user base.
We asked a simple question: why doesn't AI infrastructure have the same resilience patterns that traditional software infrastructure has had for decades?
Circuit breakers, fallback routing, health scoring, observability — these are solved problems in backend engineering. But in the LLM world, they barely exist. SENTINEL is our answer.
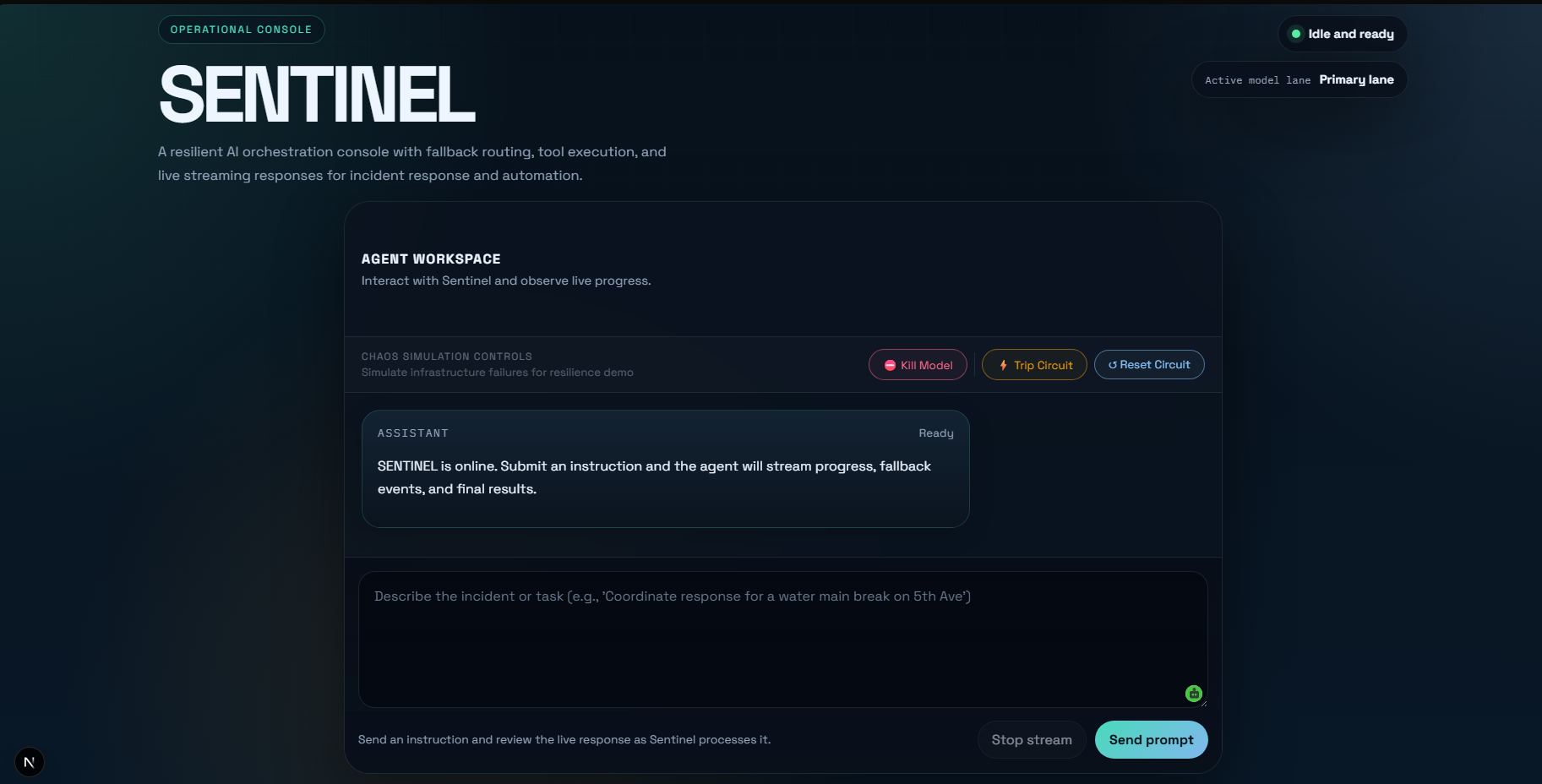
What It Does
SENTINEL is a resilient AI orchestration console that sits between your application and your LLM providers. It handles:
- Automatic fallback routing when a primary model fails
- Circuit breaking that stops hammering a broken provider after repeated failures
- Live streaming responses with real-time status updates during failover events
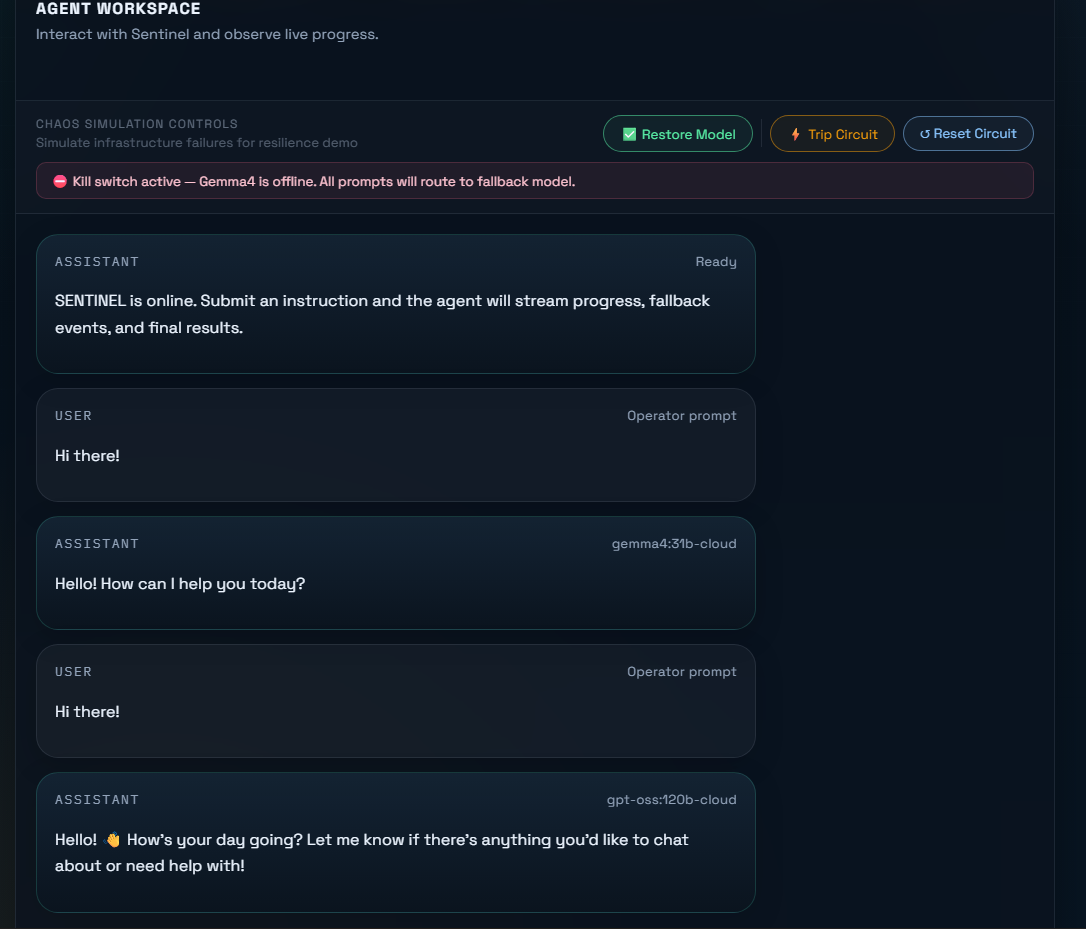
- Kill switch simulation for controlled chaos injection and resilience testing
- Tool execution with per-tool circuit breakers via MCP
- Full observability — every request, provider switch, and failure is logged
The user never sees a crash. They see a response.
How We Built It
Backend
The backend is built on FastAPI with an async-first architecture throughout. We used LangGraph to model the orchestration flow as a stateful graph — primary model attempt, conditional fallback routing, tool execution, and result logging all as explicit graph nodes.
The orchestration flow follows this decision path:
$$ \text{Request} \rightarrow \begin{cases} \text{Primary Model} & \text{if circuit closed and kill switch off} \ \text{Fallback Model} & \text{if circuit open or kill switch active} \ \text{Error} & \text{if both providers fail} \end{cases} $$
The circuit breaker tracks failure rate over a rolling window. Once failures exceed the threshold $f \geq f_{\text{threshold}}$, the circuit opens:
$$ \text{State} = \begin{cases} \text{CLOSED} & f < f_{\text{threshold}} \ \text{OPEN} & f \geq f_{\text{threshold}} \ \text{HALF-OPEN} & t_{\text{elapsed}} \geq t_{\text{recovery}} \end{cases} $$
Where $t_{\text{recovery}}$ is the cooldown period before the circuit attempts recovery. In our implementation, $f_{\text{threshold}} = 5$ and $t_{\text{recovery}} = 30$ seconds.
Provider health and all request logs are persisted via SQLAlchemy async ORM backed by SQLite, with a Postgres-ready architecture for production.
Streaming is implemented via Server-Sent Events (SSE), with a custom event bus and streaming manager that emits typed events:
status— live progress updatestoken— streamed response chunkscompletion— final result with provider metadataerror— failure details
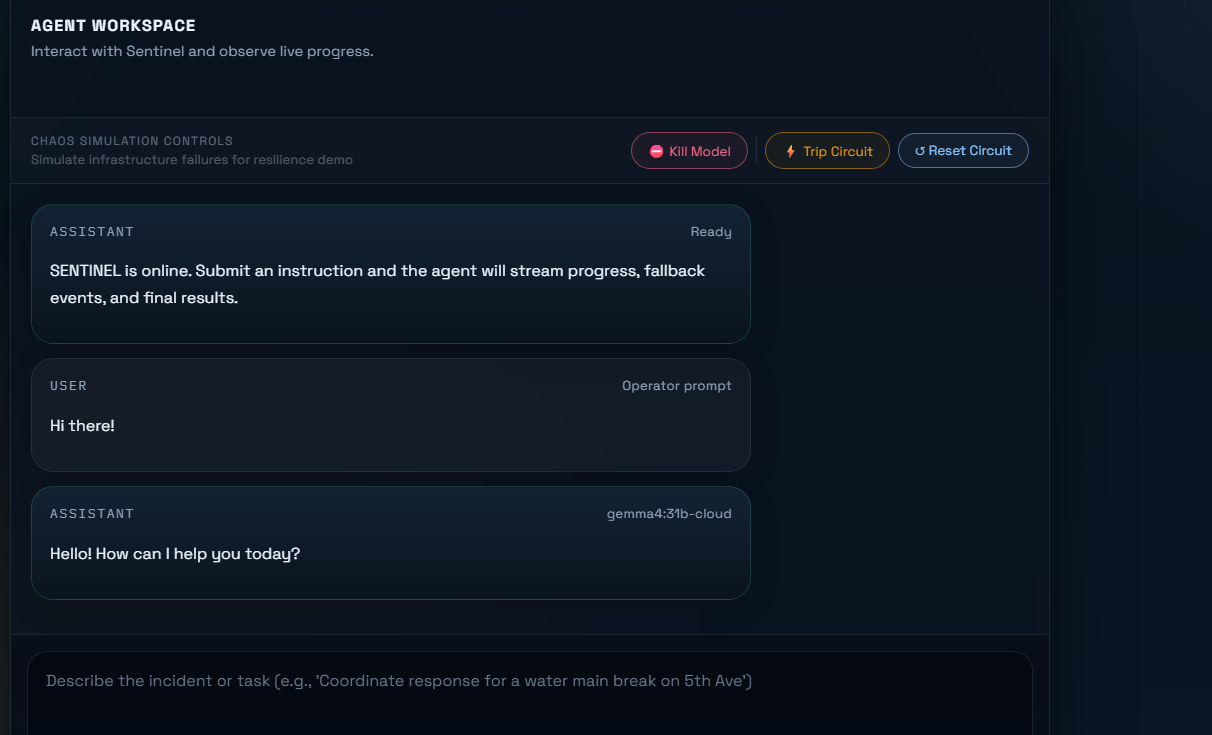
Frontend
The frontend is built in Next.js with TypeScript. The chat
interface consumes the SSE stream in real time, rendering markdown
responses with full support for tables, code blocks, and math via
react-markdown, remark-gfm, remark-math, and rehype-katex.
The Chaos Simulation Controls panel gives judges and operators direct visibility into the resilience layer — kill switch, circuit trip, and circuit reset — all wired to live backend state.
Future Prospects
SENTINEL is evolving beyond provider-level failover into a fully resilient AI infrastructure layer for autonomous agents.
The next major focus is MCP resilience orchestration. Modern AI agents rely heavily on MCP tool servers for web search, file access, calculations, external APIs, and enterprise integrations. A single unstable tool server can disrupt an otherwise healthy workflow.
To address this, SENTINEL is being extended with per-tool circuit breakers directly inside the MCP execution layer. When a tool server starts failing, timing out, or behaving inconsistently, SENTINEL will automatically isolate that tool, stop routing traffic to it, and either fallback to an alternative service or gracefully continue execution without interrupting the rest of the agent pipeline.
This architecture enables:
- Fault isolation at the tool level instead of full workflow failure
- Automatic recovery and health re-evaluation of failed MCP servers
- Intelligent fallback routing between equivalent tools
- Reduced retry storms and infrastructure overload during outages
- Continuous agent productivity under partial system degradation
The long-term vision for SENTINEL is to become a generalized high-availability orchestration layer for AI systems — combining provider resilience, tool resilience, observability, chaos testing, adaptive routing, and autonomous recovery into a single operational platform for production-grade AI infrastructure.
Built With
- fastapi
- nextjs
- ollama

Log in or sign up for Devpost to join the conversation.