-
-
Landing page
-
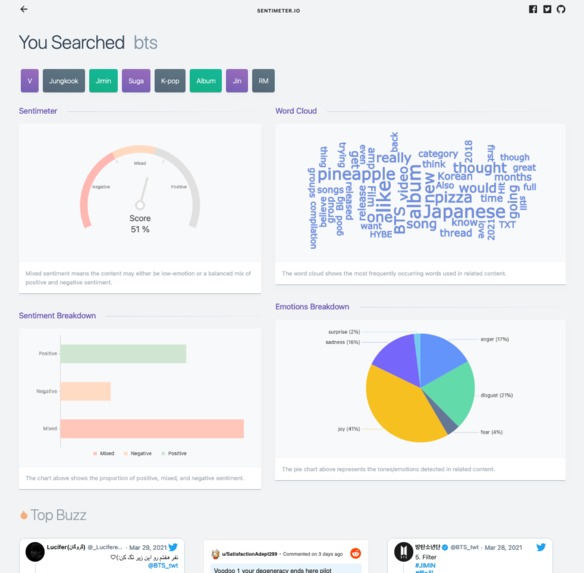
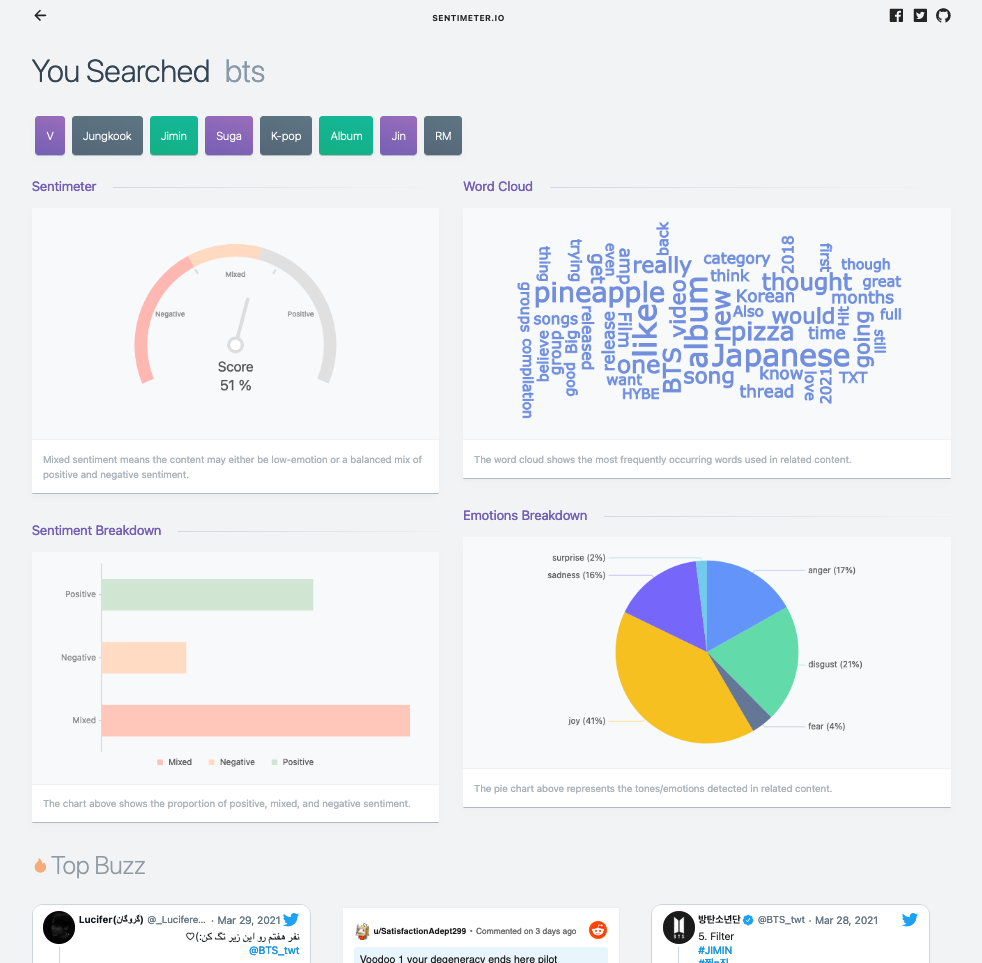
Dashboard - Visualizations
-
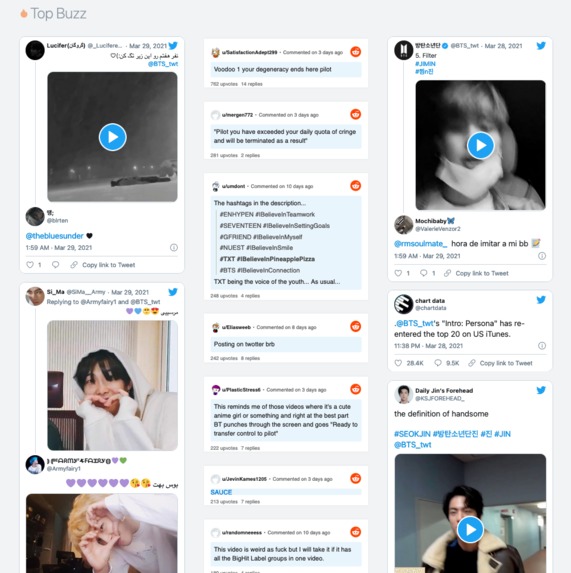
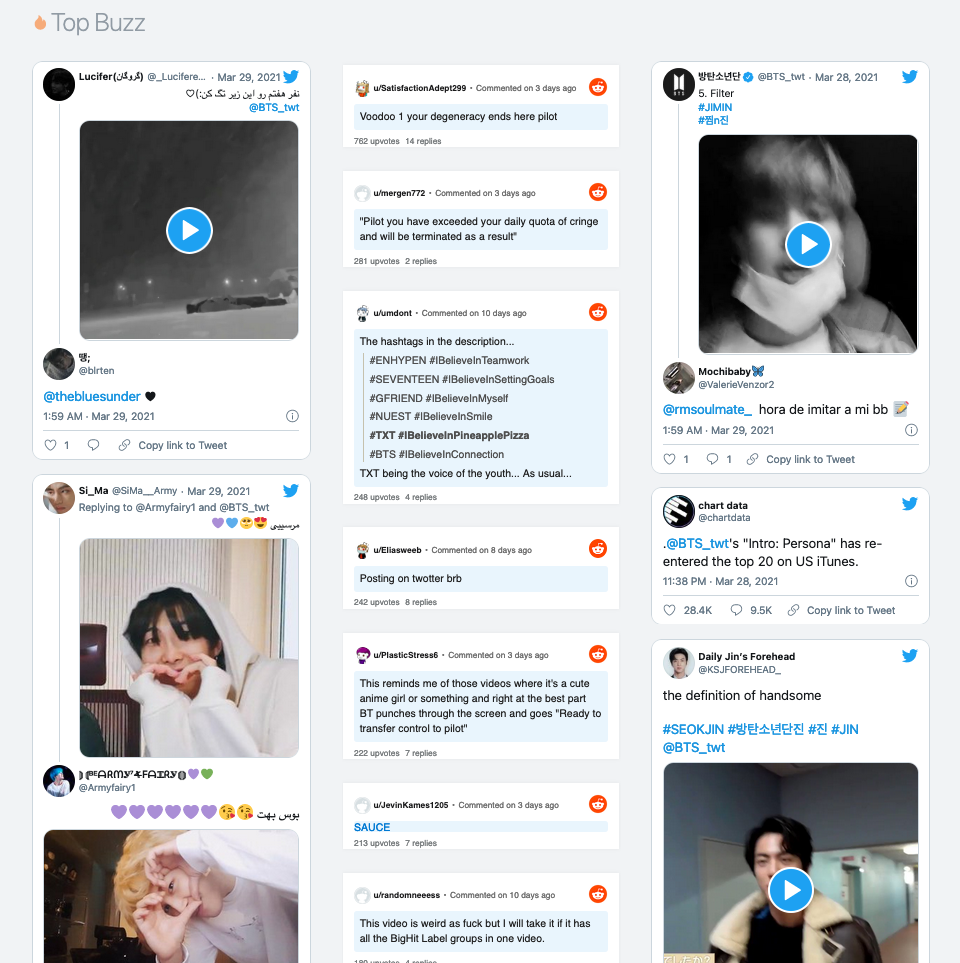
Dashboard - Buzz
Demo
Sentimeter. PS: don't search too fast!
Introduction
Echo chambers are a well-known phenomenon in the age of social media and algorithms. We are often misled to believe that our little corner of the internet comprising of like-minded figures and feedback-looped content, is a fair representation of what the rest of the internet thinks. In light of this, there have been calls for new tools that mediate our online experience and help take us beyond the confines of our echo chambers. One such tool that has recently exploded in popularity is Ground News (https://ground.news), a website and browser extension that uses web data to identify the political leanings of news articles and popular accounts.
As a team, we thought it would be interesting to see if we could aggregate web data to similarly produce a bird's-eye view of what the Internet was thinking, saying, and feeling about any given topic. Rather than political leaning, we wanted to focus on a more personal, but equally volatile metric — emotional sentiment. We decided to leverage natural language processing using the Google NLP API and Google AutoML platform to analyze this.
And so Sentimeter was born: web application that aims to give you a visually engaging unbiased overview of what the internet's latest opinion and attitude is towards a given topic.
What it does
Sentimeter scrapes the web for opinions across top social media websites on the Internet, and assesses them for their overall sentiment and emotion. Using Google's AutoML platform and a labelled dataset from SemEval-2018 Task 1, we trained a model to evaluate emotions from a given text. We also leveraged the Google NLP for sentiment analysis - to evaluate whether the text is positive, mixed, or negative in tone.
By keying in a search term on the homepage or search bar, our web application will display the relevant sentiment, emotions, related trends, and buzzing tweets and comments in the form of useful and interactive charts:
Sentiments and Emotions: Our webpage would then display the sentiments - whether the Internet as a whole feels positive, negative, or mixed about the topic - as well as the emotions - whether the Internet feels anger, joy, sadness, disgust, surprise, or fear regarding the topic.
Word Cloud: We also display the most frequently appearing words in the form of a word cloud to let users know what words are normally mentioned in conjunction with the topic.
Top Buzz: Further down the page, we display the top buzzing comments from social media sites for users to gain an overview of the most popular opinions across the Internet.
Related Topics: We also provide suggested top related search topics to let users continue exploring any related topics.
How we built it
Given the importance of presenting a balanced summary of the most popular and relevant opinions across the Internet, our application has to pull a large number of comments and subsequently **analyze their sentiments and emotions. Thus, our backend service has to be able to retrieve and assess the emotions and sentiments of such data rapidly to provide a timely response to the frontend to present the information.
We therefore built our backend service using Golang and our frontend using React.js. Golang was chosen for its high parallelism and scaling abilities, while React provided a reactive framework with a vast ecosystem of libraries for our needs.
To run the sentiment analysis, we leveraged the Google Natural Language API for sentiment analysis. However, there was no similar API available for emotional analysis. To achieve this, we trained our own emotional categorization model using Google AutoML and deployed it to serve predictions on our data. For the word cloud, we utilized nltk, a Python natural language library for tokenization.
For the data visualization, we leveraged a popular library antv for the display of key insights. Paired with React, we designed and built clean and effective user interfaces with word clouds, pie charts, and various other diagrams.
Finally, we deployed our frontend and backend services onto separate virtual machine instances hosted on the Google Compute Engine.
Challenges we ran into
One challenge we ran into was with the speed and performance of our backend service. Both our sentiment analysis and emotional analysis endpoints can only evaluate a single input with each call, as opposed to evaluating an entire batch or list of inputs. Given the large number of comments and tweets we are analyzing, this meant that we had to be able to fire a large number of API requests. Initially, we planned to use Python and Flask to design our backend. However, we found that the performing parallel tasks (in this case sending API requests) with Python was highly limited and took twelve minutes to evaluate five hundred comments - an unacceptable loading time for any web application. Instead, we decided to migrate to Go halfway through the week and more specifically, utilize their goroutines. By spinning up a lightweight goroutine for every API call we made, we eventually achieved speeding up the response time by almost 300 times!
Another limitation was the training of our NLP emotion categorization model on Google AutoML using a labelled dataset from SemEval-2018 Task 1. Given the complexity of NLP training, each iteration of training took upwards of five hours - we had to find the right balance between dataset size and training time. This also left us a very limited number of opportunities to train and evaluate our model. To overcome this, we tuned the number and types of emotional labels that we used to optimize the training as well as obtain the best-performing model.
Accomplishments that we're proud of
We also used Google Cloud extensively in this project, which gave us a lot of experience for the many functionalities provided by both the Google Cloud console and its API services. Specifically, we are especially proud of finding new use cases for the Google NLP API for sentiment analysis and for the Google AutoML API for multi-label classification - especially as we had little machine learning and NLP experience prior. We also got to learn about and work with the incredibly powerful nltk library for NLP.
What we learned
We learnt how to design, build and deploy a web application! More interestingly, we also learnt to aggregate data from across the Internet, as well as improve the speed and parallelism of our backend to be able to support what we wanted to achieve. We also gained experience with many different types of APIs and Google Cloud Console.
Having come into this hackathon with limited experience with data visualization and web design, this project gave us an opportunity to think more about these aspects. We learned that putting time and effort into the UX design helped bring out the full potential of our product.
This project also helped cement the importance of having an effective system of collaboration that allowed us to iterate sufficiently while making timely progress towards the deadline. The time and resource constraints forced us to prioritize and organize in ways that we were not used to in our solo projects.
What's next for Sentimeter
Given the time constraints of the hackathon, we focused our efforts on specifically Twitter and Reddit as these are some of the most widely-used social networks in the world today. However, we could onboard more social media websites to gain a more diverse pool of opinions -further accomplishing our original goal for Sentimeter. Besides new social media websites, we could also analyze news articles from different news websites to include the sentiment from more traditional sources as well.
We would also like to further optimize and improve our emotion categorization model. Given more time, we could train our model to identify more emotions and to a greater degree of accuracy, thus yielding better insights for our users.





Log in or sign up for Devpost to join the conversation.