-
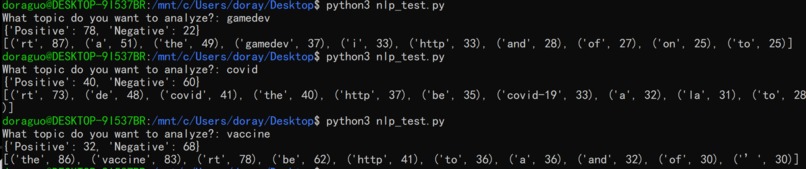
Ratio of attitudes and most common words
-

Individual results + Overall analysis


Inspiration
I'm interested in NLP, so I thought that MLH's LHD: Build "Leverage Sentiment Analysis" seemed really interesting.
What it does
I followed a tutorial (https://www.digitalocean.com/community/tutorials/how-to-perform-sentiment-analysis-in-python-3-using-the-natural-language-toolkit-nltk) to learn about and train/test a model for analyzing positive vs negative attitudes towards tweets. It also taught how to retrieve frequency data of tokens in all the tweets.
Following it, I am able to input a certain topic to search for the latest tweets. The script takes that collection of tweets to analyze a general ratio of positive vs negative attitude towards the whole collection. It also analyzes the most frequent words in the collection.
How we built it
I used Python and nltk, especially its lemmatizer, tokenizer, methods to find frequency distribution, data, and classifying methods to train the data.
I search and retrieve the tweets using python-twitter and the Twitter API.
Accomplishments that we're proud of
I learned a lot about the theoreticals and applications of sentiment analysis!
What we learned
The steps to being able to label an attitude on words (tokenizing, lemmatizing, etc) and the flaws that it has, such as analyzing sarcasm.
What's next for Sentiment Analysis Exploration
I'm thinking of incorporate mixed and neutrality as the attitudes or implementing an NLP API instead.

Log in or sign up for Devpost to join the conversation.