-
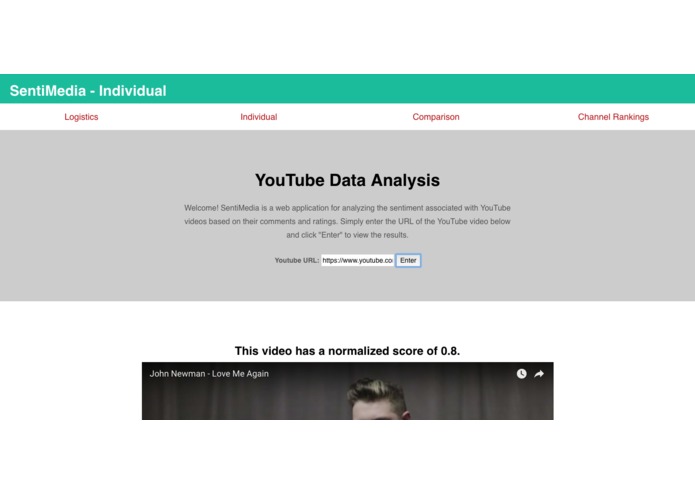
Checking the sentiment score of a video
Welcome! It took 4 hackers 2 sleepless night and lots of frustration, but the site finally came together, more or less. Here's how we did it.
We first got the initial idea for our project when we got our hands on the Twitter database of tweets intended for natural language processes. Using Python's nltk library, we trained a classifier on 1.5 million tweets and set it loose upon Youtube's infamous comment section. While this process doesn't sound very well, we believed that YouTube comments and tweets have enough in common that some overlap in learning should be possible. Of course, because YouTube comments can be much longer than 140 characters, YouTube comments generally have a lower success rate than with a test set of tweets. Nonetheless, we're all happy with our results, however unorthodox they are.
In order to prepare our program to complete these sentiment evaluations, we taught ourselves how to use certain machine learning libraries. Comment sentiment ratios differ from pure video ratings (thumbs up and down) because comments provide more insight into why the video did as well (or as bad) as it did. Future functionalities that we'd like to implement include pulling the most recurring key words, displaying graphs to better compare and visualize data, and pulling from sources other than YouTube comments. Future possible projects include identifiying variables that are much harder to detect, such as sarcasm or slang.
SentiMedia was created by Jacky Lee, Arkin Gupta, Terrence Ho, and Ryan Fong.



Log in or sign up for Devpost to join the conversation.