-
-
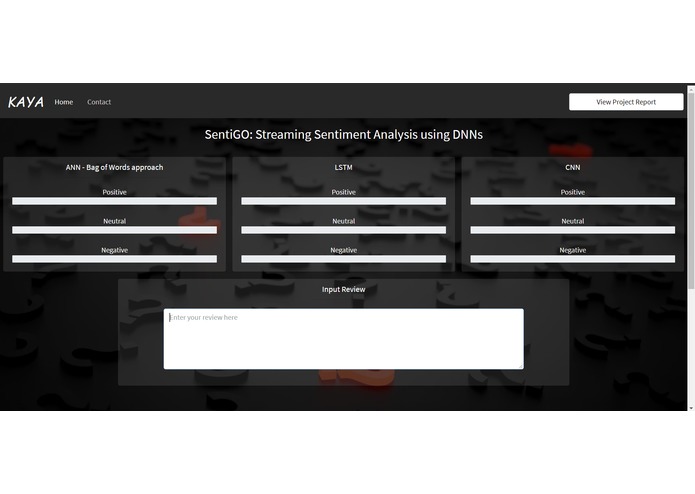
SentiGo Website in Initial Stage when no words seen
-
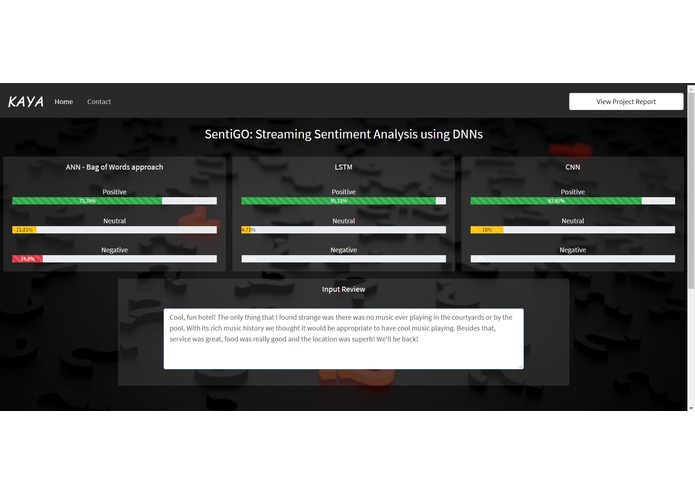
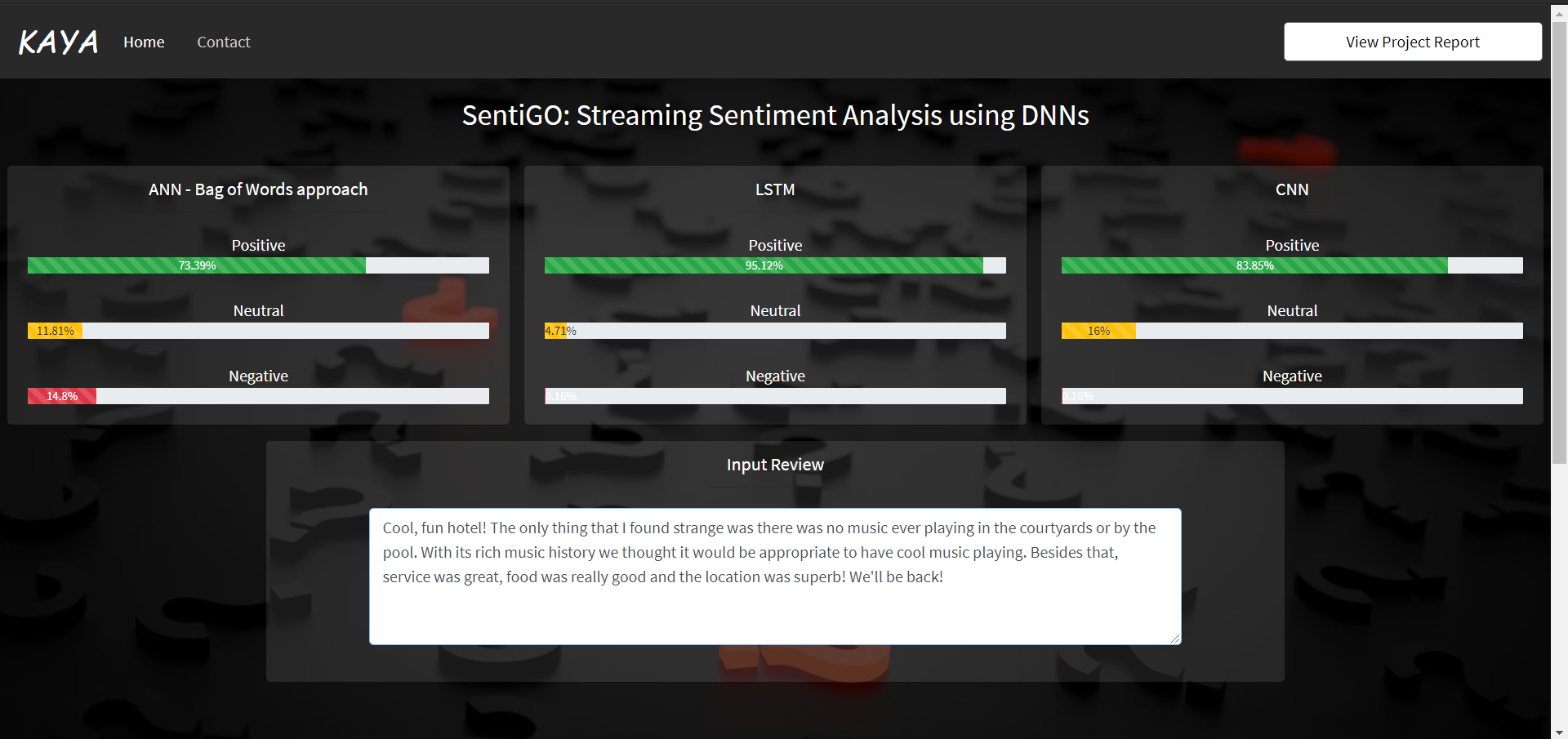
Streaming Sentiment Analysis for a positive review
-
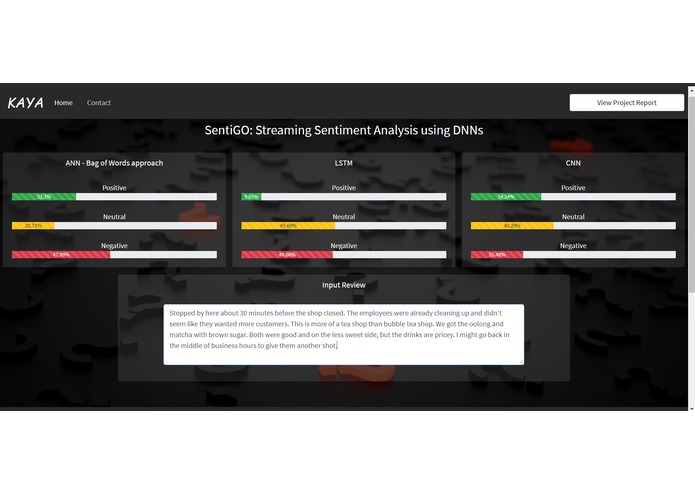
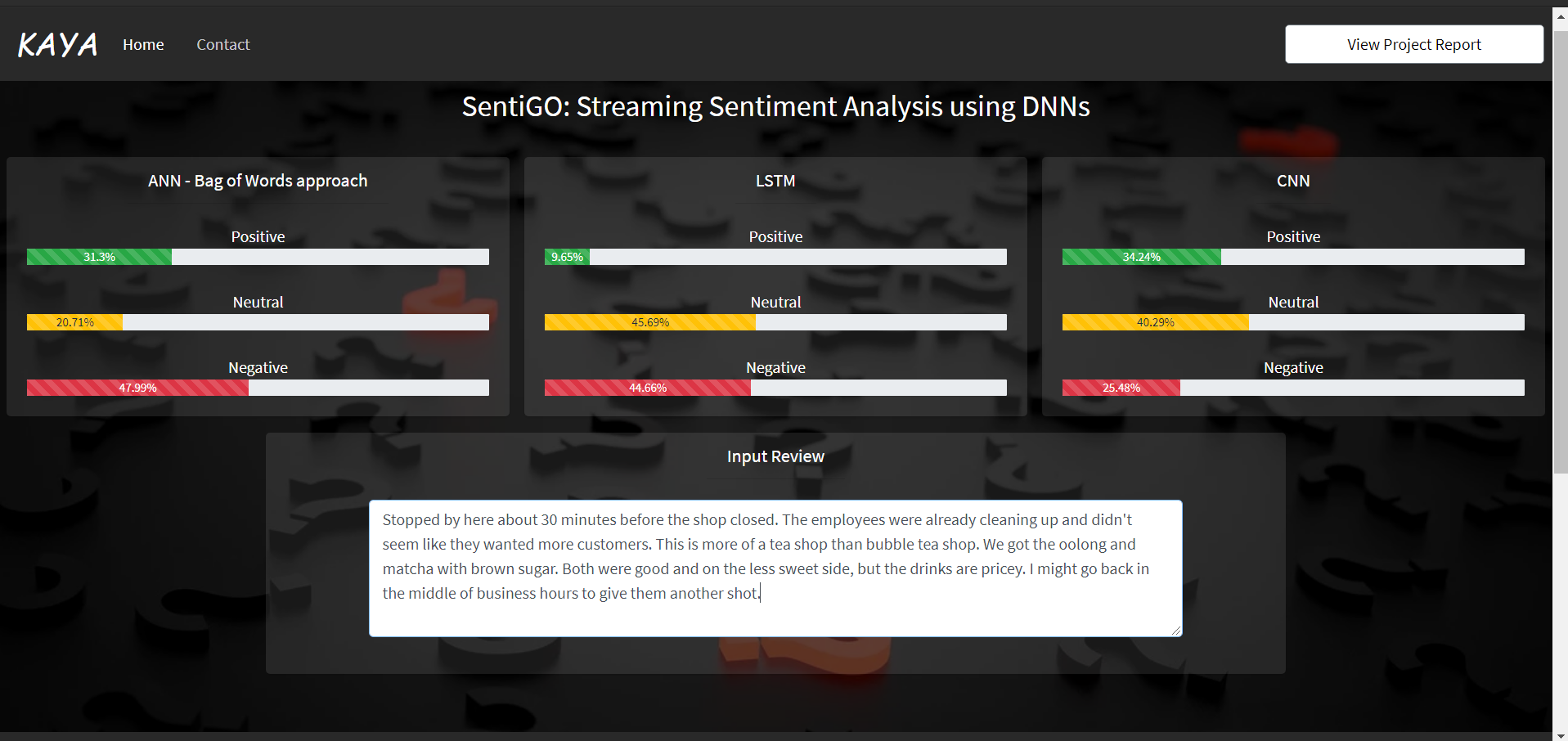
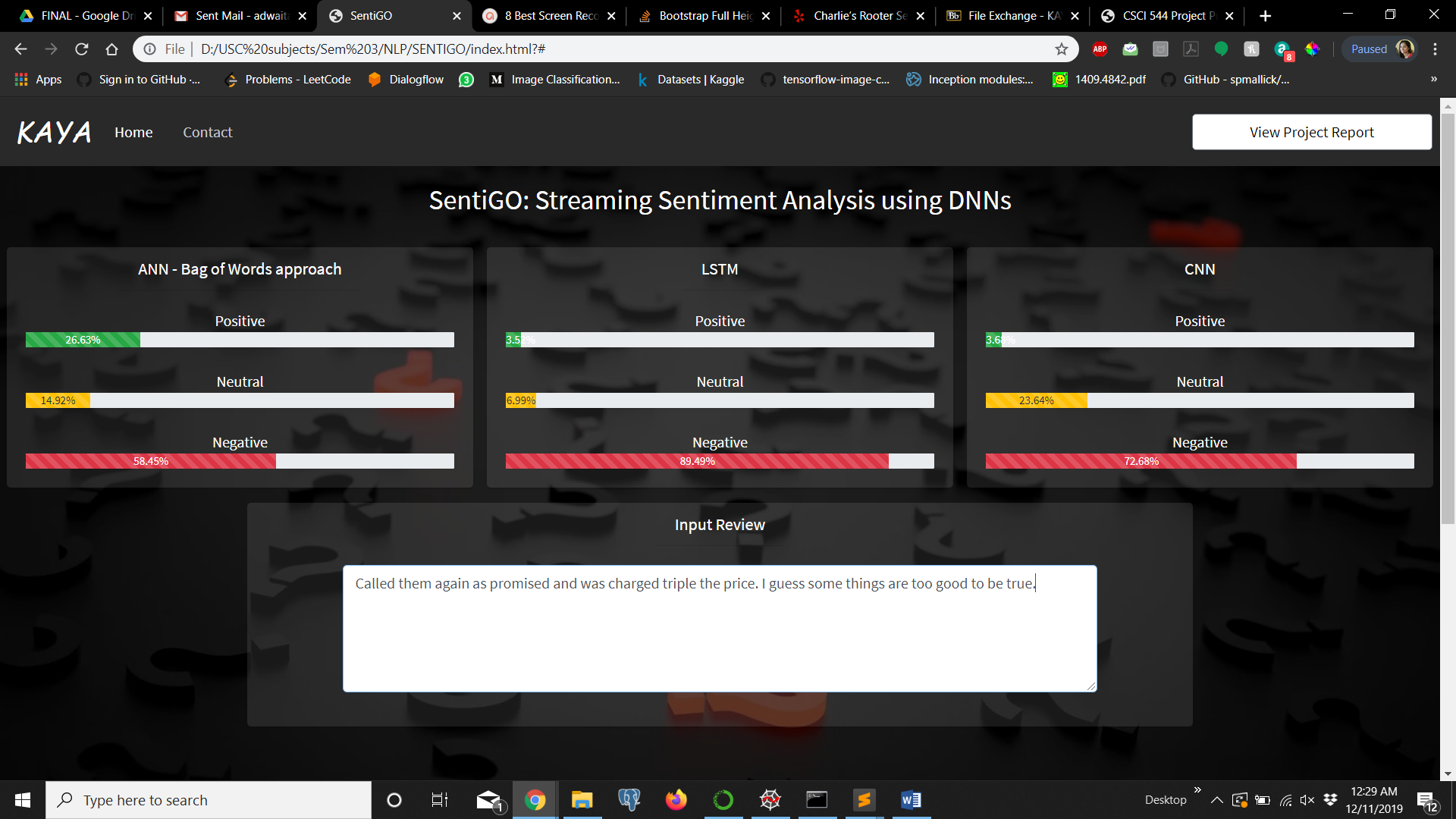
Streaming Sentiment Analysis for a review
-
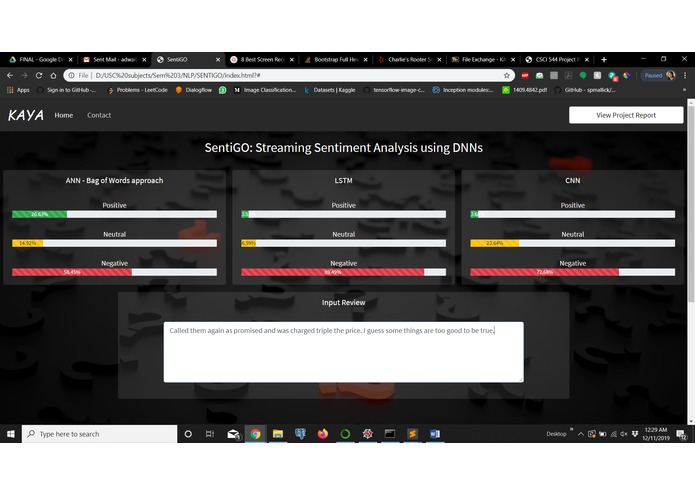
Streaming Sentiment Analysis for a negative review
-
Contact us section of our website
Inspiration
Yelp cumulatively has 192 million reviews on its website as of today. It is a cumbersome task for a customer to go through the expansive set of reviews to finally decide if he or she wants to go to a particular restaurant or call a brand to request for a service. Traditional approaches for feature reduction of the reviews typically involve text summarization or linear extrapolation of star ratings. There really is no on-the-go solution to this problem. Thus, we propose a realtime sentiment tracker of reviews. We dynamically analyse the sentiment conveyed by the words of the reviewer while he or she types it. Using this information, the user can modify the current text to delineate the intended emotion. Once the review is entered, the final sentiments are displayed through a static progress bar, to give a visual and intuitive representation of the review, for future readers.
What it does
SentiGo is a modern day solution to counteract the problem posed by having millions of relevant and irrelevant reviews found on websites such as Yelp. Today, with the advent of technology people have become very tech savvy. Reviewers write down reviews day in and day out. While helpful in some situations, customers are inundated with mind boggling, impertinent reviews about products and services in most other situations. There is a need in this fast paced world where time is of utmost importance, for accurate information to be conveyed in the least amount of time. This is where SentiGo steps in. We propose a tool that gives review writers a chance to critique their own review in real time. They will know if the right emotions are being conveyed while they simultaneously write the reviews. Readers of the reviews will be able to see if it is positive, negative or neutral even before they go on to read the whole of it.
How I built it
Data Preprocessing - We converted words into unique number tokens. We categorized the 5 ratings into 3 smaller sub categories- namely positive, neutral and negative. 4 and 5 star ratings would become positive, 3 would be neutral and 1 and 2 signify negative ratings. We use Tokenizer and padsequences functions from the keras.preprocessinglibrary. The Tokenizer method creates the vocabulary index based on word frequency. Every word gets a unique integer value. 0 is reserved for padding. So lower integer means more frequent word (often the first few are stop words because they appear a lot). The textstosequences function transforms each text in texts to a sequence of integers. So it basically takes each word in the text and replaces it with its corresponding integer value from the word index dictionary. The padsequences method is used to ensure that all sequences in a list have the same length. By default this is done by padding 0 in the beginning of each sequence until each sequence has the same length as the longest sequence. We gave our training set a validation split of 20%. A stellar approach we undertook was to train our model onGloVe embeddings on twitter data. GloVe is an unsupervised learning algorithm for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space. We are using a 50 dimensional glove embedding trained on Twitter data because it closely resembles online reviews on Yelp. In our case, it produced 1193514 word vectors. Further steps involved sub-sampling a smaller dataset from reviews.json of the Yelp dataset. We randomly extracted 1 million reviews and performed train-test split using 70% reviews for training.
LSTM - The LSTM model has an embedding layer. It is then followed by a Bidirectional LSTM layer with a dropout of 10% and a recurrent dropout also of 10%. It is then followed by a Global Max Pooling 1 dimensional layer. We then added a dense RELU activated layer with 50 output neurons, dropout of 10% and then a sigmoid activated dense layer with3 output neurons.
CNN - The CNN model starts with an embedding layer. We then create a convolutional layer. This layer creates a convolution kernel that is convolved with the layer input over a single spatial dimension to produce a tensor of outputs. We useRELU as the activation function. We create 5 filters of kernel sizes 2,3,4,5 and 6. Each of these filters is closely followed by a global max pooling layer. Again, we use a dropout of 10% and then a Dense RELU activated layer with 128output neurons. A 20% dropout layer comes in next and then the final dense 3 layered output layer. The model figure is omitted from this report due to formatting issues.
Accomplishments that I'm proud of
We implemented three different models, namely, ANN, LSTM and CNN to achieve the common task. We provided the same set of training and test data to all 3 models. We presented a comparative analysis of all models with respect to each other. Our website visually shows the polarity of the review as the user types it in. It serves as a check to know if the sentiments you want to convey are actually being perceived in the same way by an external reader. It is an interesting use case for Yelp. This would encourage the reviewer to frame their reviews congrously and lead them in the correct direction to frame their sentences properly.
What I learned
As expected the CNN model performed better than the other two. Obviously there is a trade-off when latencies are compared. CNN model takes the longest to train, followed by LSTM and then ANN. The prediction times for all 3 models are almost the same. This can be clearly observed while using our web interface. The ANN model surprisingly has a good accuracy of 78%. CNN and LSTM models still tower above it with a staggering accuracy of 86%. The prediction latencies of the models are quiet similar and it takes less than 1 second in most cases to predict the polarity of the word with the context.
What's next for SentiGO
In the future, we can improve the model by fine tuning parameters like the neurons in the output layers, or the Adams learning rate etc. We can also make the UI more friendly to encourage the reviewers to use the feature.
Built With
- cnn
- css
- flask
- glove
- html
- lstm
- natural-language-processing
- python
- tensorflow

Log in or sign up for Devpost to join the conversation.